两步搞定docker部署DeepSeek
3、因国内原因,前端页面会调一些国外的域名,导致前端页面加载的很慢,需要修改下源代码。找到这个文件:backend/open_webui/utils/models.py。1、部署ollama---基于GPU;不使用GPU就去掉--gpus参数。容器启动后,进入容器拉取模型,模型根据GPU的能力来下载;如果1和2不部署在一台机器上,分离的时候使用。注释掉红框里的代码,这样前端页面会加载快的多。启动后
1、部署ollama---基于GPU;不使用GPU就去掉--gpus参数
docker run -itd --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama docker.1ms.run/ollama/ollama
容器启动后,进入容器拉取模型,模型根据GPU的能力来下载;
ollama run deepseek-r1:1.5b
2、部署前端页面Open WenUI
docker run -itd -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui ghcr.chenby.cn/open-webui/open-webui:main
启动后就可以:宿主机ip+3000端口访问
如果1和2不部署在一台机器上,分离的时候使用:
docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=http://192.168.1.100:11434 -v open-webui:/app/backend/data --name open-webui --restart always ghcr.chenby.cn/open-webui/open-webui:main
3、因国内原因,前端页面会调一些国外的域名,导致前端页面加载的很慢,需要修改下源代码
找到这个文件:backend/open_webui/utils/models.py
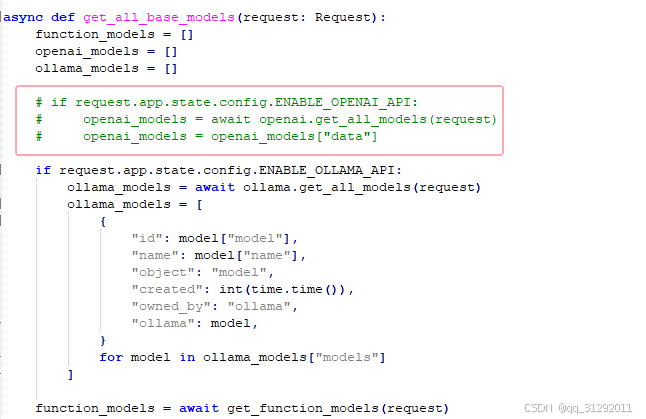
注释掉红框里的代码,这样前端页面会加载快的多

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)