每日AIGC最新进展(84):清华大学提出高效视频理解FastVID、多伦多大学提出长时间视频理解模型Vamba、杭州电子科技大学提出反事实推理多模态大模型Bench COVER
FastVID: Dynamic Density Pruning for Fast Video Large Language Models

在视频大语言模型(Video LLMs)中,如何有效理解视频内容是一项挑战。尽管这些模型在视频理解方面表现出色,但高昂的推理成本限制了它们的实际应用,主要原因在于冗余视频令牌的存在。现有的剪枝技术未能充分利用视频数据中固有的时空冗余。为了解决这一问题,本文提出了一种名为FastVID的动态密度剪枝框架,旨在加速视频LLMs的推理速度。FastVID通过对视频进行系统分析,从时间和视觉两个方面探讨冗余,并提出动态时间分割和基于密度的令牌剪枝策略。这种方法显著降低了计算开销,同时保持了视频的时空完整性。实验结果表明,FastVID在多个短视频和长视频基准上达到了领先的性能,尤其是在保留98%的原始性能的情况下,成功剪除90%的视频令牌。
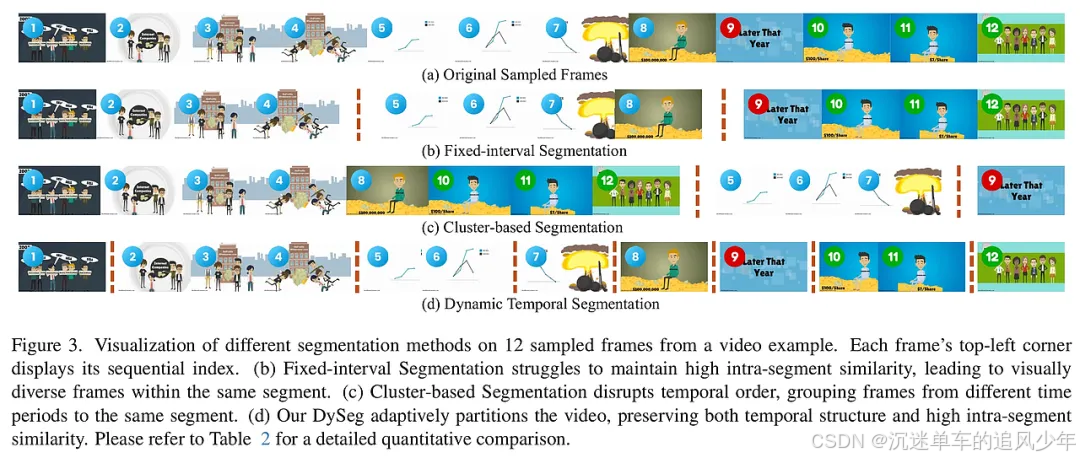
FastVID的核心方法包括两个主要部分:动态时间分割(DySeg)和密度时空剪枝(STPrune)。首先,DySeg将视频划分为时间顺序的高冗余段落,确保相似帧被分组在一起,从而保持时间结构。具体步骤如下:
-
时间分段:通过分析帧之间的相似性,动态调整分段边界,确保每个段落内的帧高度相似。
-
密度剪枝:在每个段落内,采用密度基令牌合并(DTM)和注意力基令牌选择(ATS)来保留重要的视觉信息。DTM根据令牌的局部密度合并冗余令牌,而ATS则通过[CLS]注意力分数选择显著视觉细节。
-
令牌压缩:经过以上步骤,保留适量的令牌供后续处理,确保在降低计算复杂度的同时,尽可能保留关键信息。
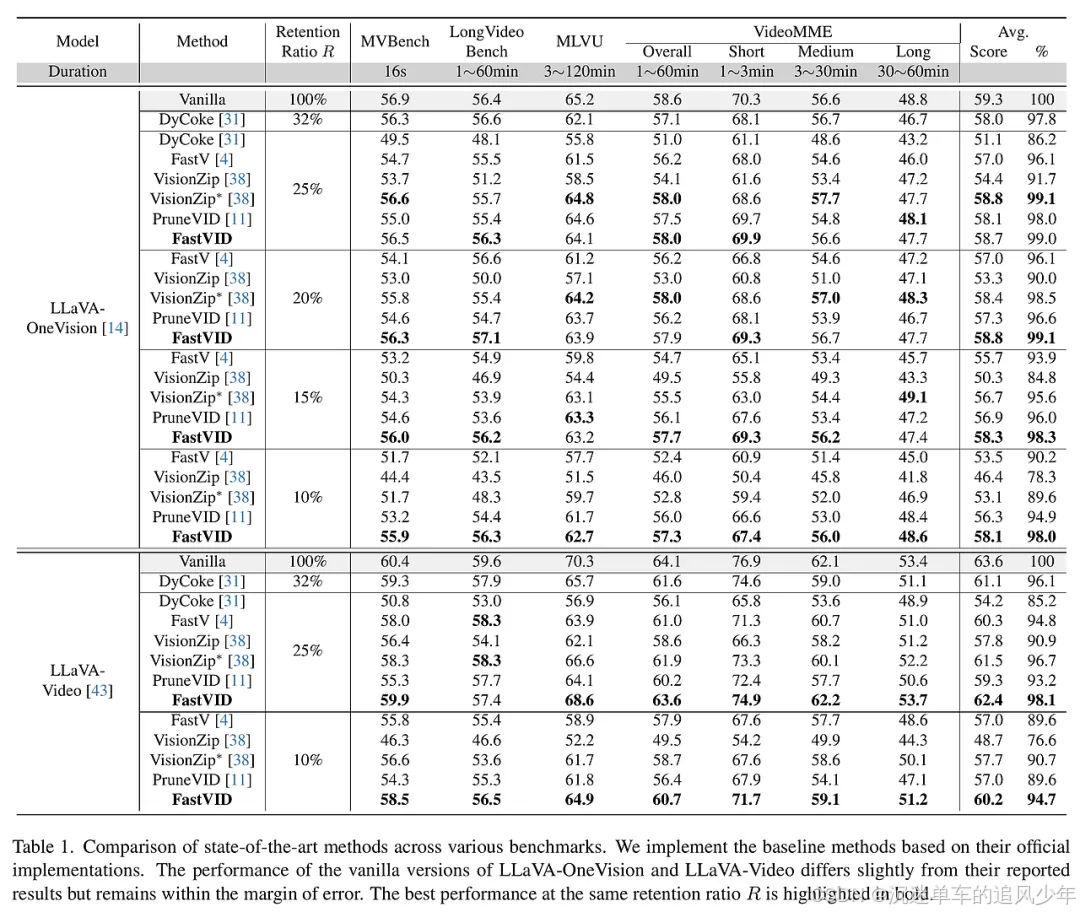
为了评估FastVID的有效性,研究团队在多个视频理解基准上进行了广泛的实验,包括MVBench、LongVideoBench、MLVU和VideoMME。这些基准涵盖了不同复杂度和时长的视频,确保对FastVID的全面评估。实验结果显示,FastVID在保留高达98.0%原始模型性能的同时,能够剪除高达90%的视频令牌。此外,FastVID在与其他最先进的方法(如DyCoke和PruneVID)进行比较时,表现出显著的优势,尤其是在推理速度和准确性方面。通过对不同视频长度和复杂度的评估,FastVID展现出良好的通用性和适应性,证明其在视频理解任务中的潜力。
Vamba: Understanding Hour-Long Videos with Hybrid Mamba-Transformers
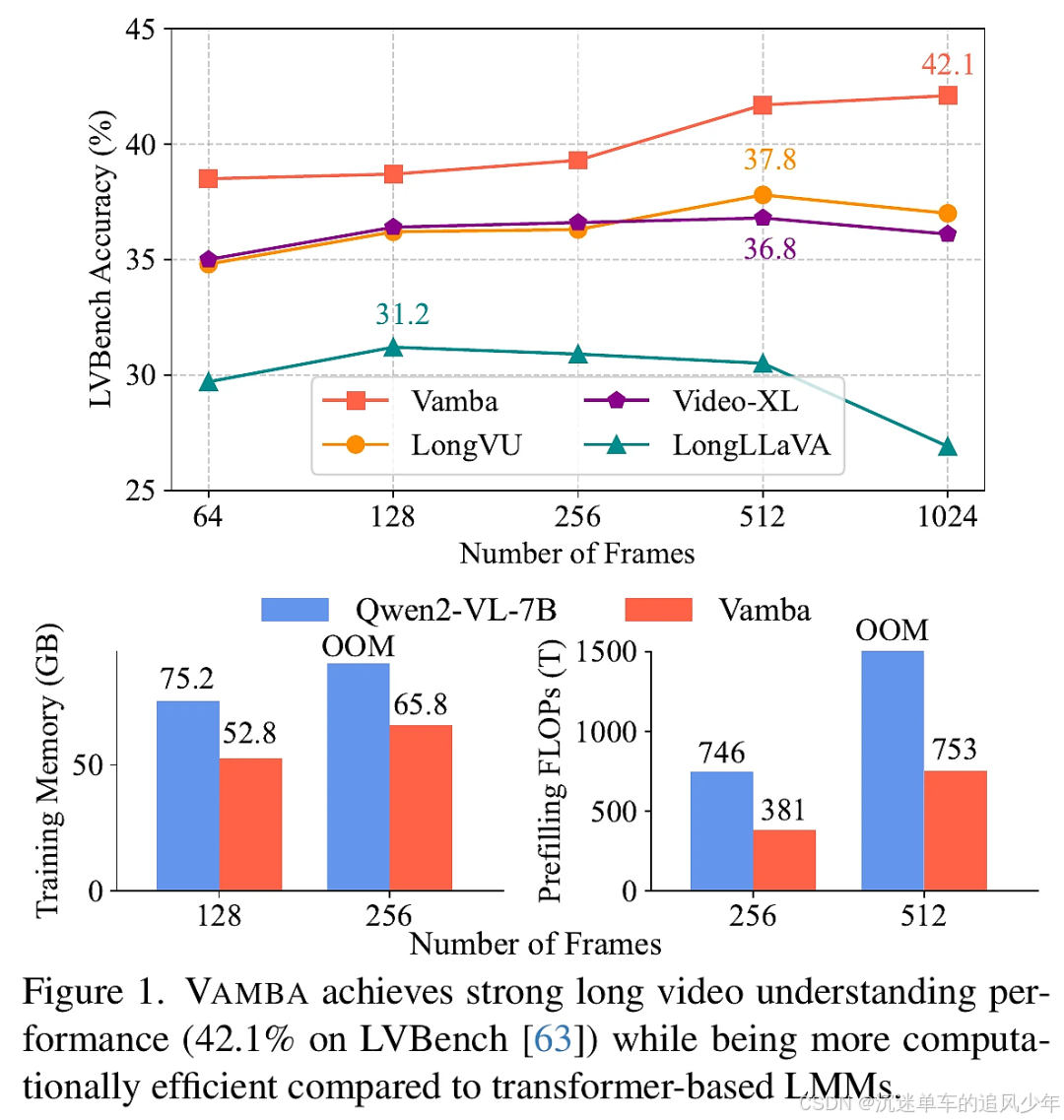
VAMBA(Hybrid Mamba-Transformer Model)是一个新提出的模型,旨在高效处理长达一小时的视频理解任务。传统的基于变压器的大型多模态模型(LMMs)在处理长视频输入时面临着计算复杂度高和内存消耗大的问题,尤其是在自注意力机制中存在的二次复杂性。尽管现有的令牌压缩方法可以减少视频令牌的数量,但往往会导致信息损失,并且在极长序列中仍然表现不佳。VAMBA通过采用Mamba-2块以线性复杂度编码视频令牌,避免了令牌的减少,能够在单个GPU上编码超过1024帧的视频。与传统模型相比,VAMBA在训练和推理过程中至少减少了50%的GPU内存使用,并且在每个训练步骤的速度几乎加倍。实验结果表明,VAMBA在长视频理解基准数据集LVBench上比之前的高效视频LMMs提高了4.3%的准确性,并在多种长短视频理解任务中保持了强大的性能。
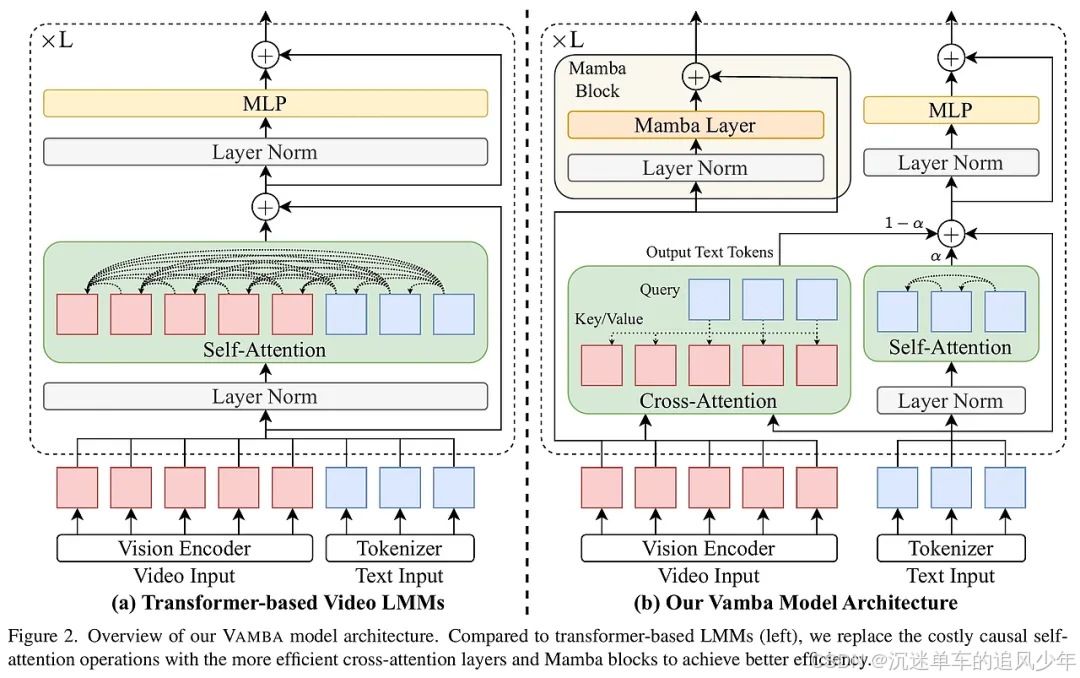
VAMBA的方法主要包括以下几个核心设计要素:
-
Mamba-2块:该模型使用Mamba-2块来处理视频令牌,通过线性复杂度的方式减少计算开销,避免了传统变压器模型中自注意力的二次复杂性。
-
交叉注意力层:在更新文本令牌时,VAMBA采用交叉注意力机制,利用视频令牌作为键和值,而文本令牌作为查询,这样可以有效地减少计算复杂度。
-
两阶段训练策略:VAMBA采用两阶段的训练策略,首先进行预训练,然后进行指令调优。在预训练阶段,模型初始化自预训练的变压器模型,并冻结部分组件,仅训练新引入的交叉注意力和Mamba层。
-
信息蒸馏:在预训练阶段使用信息蒸馏损失,以确保模型能够恢复其视觉理解能力。
-
复杂度分析:通过将自注意力和交叉注意力的复杂度分开,VAMBA的复杂度从O(d(M + N)²)降低到O(dMN + d²M),在处理长视频时显著提升了效率。

在实验部分,研究者进行了全面的消融研究,以评估VAMBA的设计选择。首先,比较了不同的Mamba块设计,结果显示Mamba和Mamba-2块均能提高模型性能,后者表现更优。其次,研究了交叉注意力层的初始化策略,发现将交叉注意力层权重初始化为自注意力层的权重对提升模型性能至关重要。接着,模型在长视频理解基准LVBench、HourVideo和HourEval上进行了评估,VAMBA在这些基准测试中均表现优异,超越了多个高效视频LMMs。最后,模型的运行效率分析显示,VAMBA在训练和推理阶段均显著降低了GPU内存使用和计算需求,能够在单个GPU上处理更多帧的视。
Reasoning is All You Need for Video Generalization: A Counterfactual Benchmark with Sub-question Evaluation

本研究提出了COVER(COunterfactual VidEo Reasoning),这是一个全新的多维度多模态基准,旨在系统评估多模态大语言模型(MLLMs)在视频理解中的反事实推理能力。以往的多模态基准往往忽视了反事实推理的重要性,而COVER通过将复杂查询分解为结构化的子问题,促进了更细致的推理分析。研究表明,子问题的准确性与反事实推理能力之间存在显著关联,强调了结构化推理在视频理解中的关键作用。此外,COVER为评估MLLMs在动态环境中的逻辑推理能力设定了新标准,揭示了增强模型推理能力对于提升视频理解的鲁棒性至关重要。
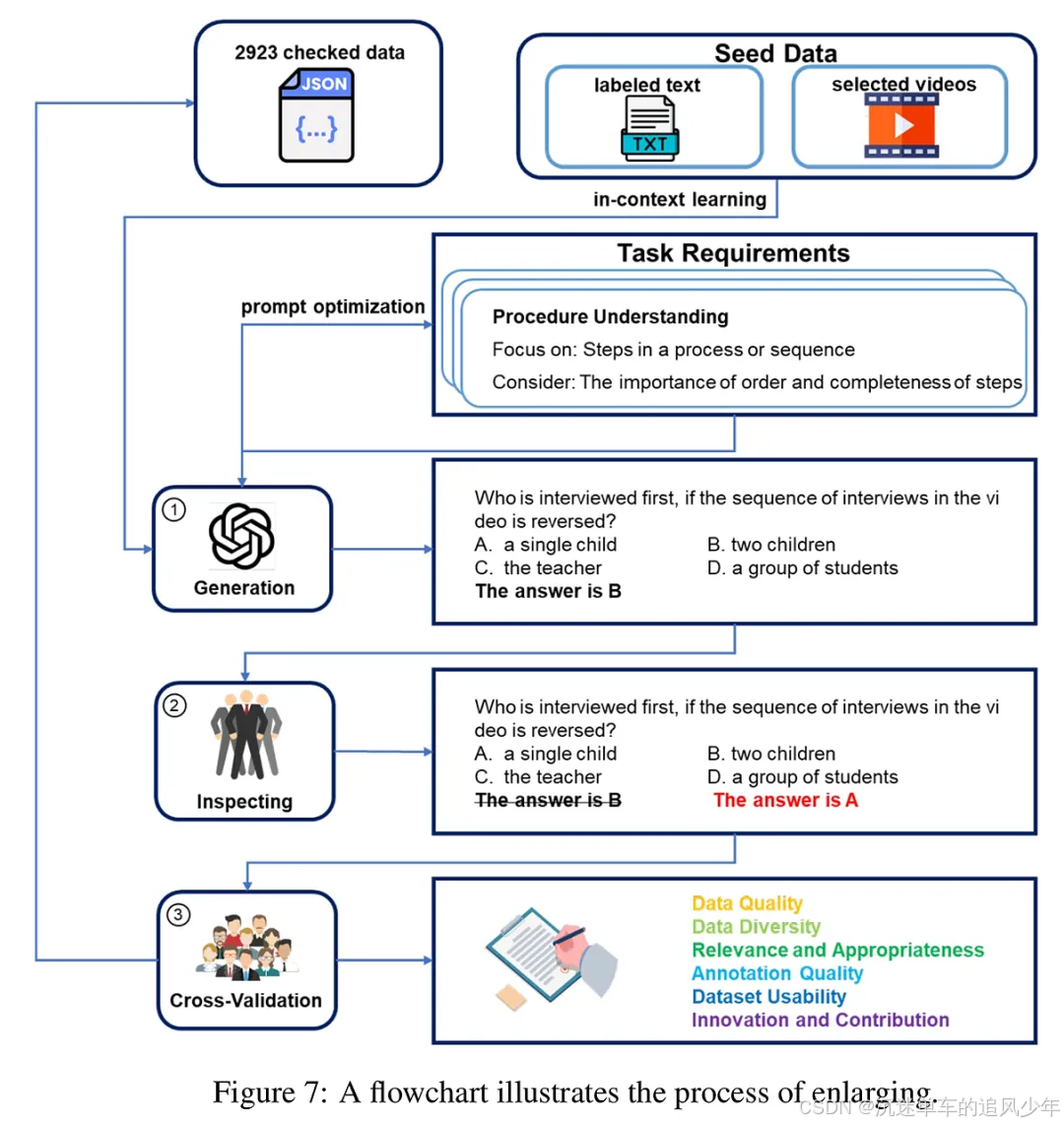
COVER基准通过以下几个步骤构建:首先,基于抽象-具体和感知-认知的维度,将任务分为四个象限,每个象限对应不同的推理能力评估。然后,设计了13个具体任务,以评估模型在复杂视频场景下的多样推理能力。接着,COVER引入了子问题推理机制,允许将复杂问题分解为多个必要条件,从而进行更深入的性能评估。最后,通过严格的数据验证过程,确保了数据的高质量和可靠性。通过这种方式,COVER不仅能够评估模型在反事实推理中的表现,还能揭示模型在应对动态变化时的优势和不足。
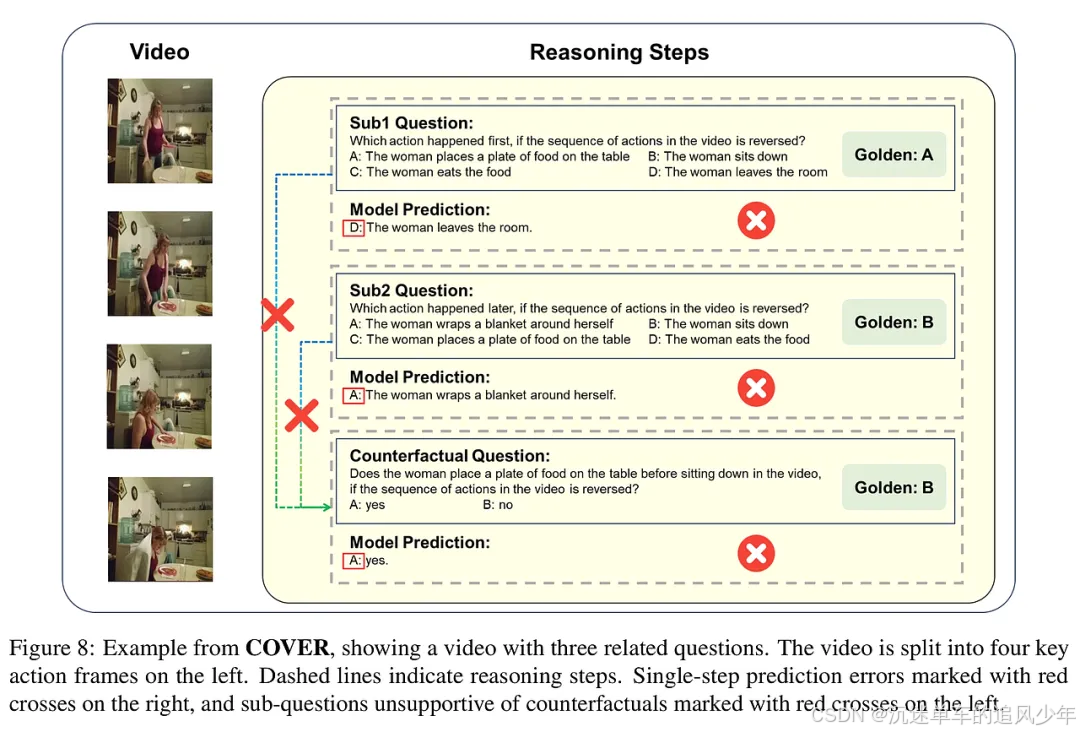
在实验部分,研究团队对多种规模的MLLMs进行了全面评估,重点分析了它们在COVER数据集上的表现。实验结果显示,模型在子问题的准确性与反事实推理和视频理解的鲁棒性之间存在强正相关。通过比较开源和商业模型的性能,发现大模型在处理复杂推理任务时的表现显著优于小模型。此外,研究还探讨了自动生成的子问题与人工设计的子问题对模型推理能力的影响,结果表明,手动设计的子问题在某些情况下并未显著提升模型性能。实验结果为未来的模型优化和推理能力提升提供了重要的见解。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 20
20 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)