03 | 大模型微调 | 从0学习到实战微调 | 玩转Hugging Face与Transformers框架
1. 学会安装transformers框架环境2. 学会使用hugging Face 平台3. 掌握transformers的核心模块4. 学会如何看源码5. 深入业务场景进行学习理解
一、导读
本系列文章将围绕《大模型微调》进行学习(也是我个人学习的笔记,所以会持续更新),最后以上手实操模型微调的目的。
(本文如若有错误的地方,欢迎批评指正)
(写作不易,方便的话点个赞,谢谢)
✅《大模型微调》往期系列文章
01 | 大模型微调 | 从0学习到实战微调 | AI发展与模型技术介绍
02 | 大模型微调 | 从0学习到实战微调 | 从数学概率到千亿参数大模型
1、本文摘要
本文内容很长,我不喜欢[ 碎片化信息 ],不想拆成几个文章,本文内容其实每一节都可以拆成很多文章发布
但是我觉得没意义,为了保证思路连贯性,所以全部写在一起了
- 学会安装transformers框架环境
- 学会使用hugging Face 平台
- 掌握transformers的核心模块
- 学会如何看源码
- 深入业务场景进行学习理解
2、往期文章推荐
你可以阅读我下列文章
1️⃣ 关于langchain的系列文章(相信我把Langchain全部学一遍,你能深入理解AI的开发)
01|LangChain | 从入门到实战-介绍
02|LangChain | 从入门到实战 -六大组件之Models IO
03|LangChain | 从入门到实战 -六大组件之Retrival
04|LangChain | 从入门到实战 -六大组件之Chain
05|LangChain | 从入门到实战 -六大组件之Memory
06|LangChain | 从入门到实战 -六大组件之Agent
2️⃣ 关于Langchain的实战案例(自认为本地问答机器人的案例写的很好,很好理解ReAct)
Langchain-实战篇-搭建本地问答机器人-01
都2024了,还在纠结图片识别?fastapi+streamlit+langchain给你答案!
3️⃣ 关于Agent智能体开发案例(MCP协议)
在dify构建mcp,结合fastapi接口,以实际业务场景理解MCP
4️⃣ 推荐阅读一下transformer 文章,以便能更好的理解大模型
Transformer模型详解(图解最完整版)
Attention Is All You Need (Transformer) 论文精读
5️⃣ 除了在 CSDN 分享这些技术内容,我还将在微信公众号持续输出优质文章,内容涵盖以下板块:
(当然我也希望能够跟你们学习探讨😀)
关注😄「稳稳C9」😄公众号
- 爬虫逆向:分享爬虫开发中的逆向技术与技巧,探索数据获取的更多可能。
- AI 前沿内容:紧跟 AI 发展潮流,解读大模型、算法等前沿技术动态。
- 骑行分享:工作之余,用骑行丈量世界,分享旅途中的所见所感。
二、Hugging Face Transformers 介绍
Hugging Face 通过开源社区与技术创新,重新定义了 NLP 的开发范式。
其核心价值在于 降低技术门槛、促进协作共享,并推动从学术研究到工业落地的全链条发展。
无论是个人开发者还是企业用户,均可通过其生态快速实现从原型验证到生产部署的跨越。
1、Hugging Face 地址
- 国内镜像地址:https://hf-mirror.com/

2、发展历史与技术组成
发展历史
Hugging Face 成立于2016年,最初以聊天机器人起家,后转型为 NLP 开源社区。其核心产品 Transformers 库于2019年发布,迅速成为 NLP 领域的事实标准。关键节点包括:
- 2018年:支持 BERT、GPT 等早期模型,推动预训练模型的普及。
- 2019年:推出
PipelineAPI,实现三行代码调用复杂 NLP 任务。 - 2020年:整合多模态模型,扩展至计算机视觉和语音领域。
- 2024年:中国智源研究院的 BGE 模型登顶 Hugging Face 月度下载榜,成为首个下载量破亿的国产模型。
技术组成
Hugging Face 生态由四大核心组件构成:
- 预训练模型库:涵盖 30+ 架构(如 BERT、GPT、T5)和 2000+ 预训练模型,支持 100+ 语言。
- Pipeline API:封装模型加载、预处理、推理全流程,支持情感分析、文本生成、翻译等任务。
- Model Hub:开源社区平台,支持模型托管、版本管理、在线演示(如
Write With Transformer)。 - 多框架兼容:无缝支持 PyTorch、TensorFlow、JAX,支持跨框架模型转换。
3、价值与作用
核心价值
- 开源共享:降低模型使用门槛,避免重复训练,减少碳排放。
- 技术普惠:通过简单 API 让非专业开发者也能调用 SOTA 模型。
- 社区驱动:全球开发者贡献模型与工具,形成良性生态循环(如国产 BGE 模型的成功)。
实际作用
- 加速研发:
- 研究者可基于预训练模型快速微调,如智源 BGE 通过社区反馈迭代优化。
- 企业利用
Infinity容器实现毫秒级推理延迟,降低生产环境成本。
- 多场景适配:
- 情感分析:3 行代码判断文本情感倾向(例:
pipeline("sentiment-analysis"))。 - 跨语言检索:BGE M3 支持 100+ 语言统一表征,提升 RAG 系统的多语言适配能力。
- 情感分析:3 行代码判断文本情感倾向(例:
- 教育与创新:
- 提供
Datasets和Tokenizer库,简化数据预处理与特征提取。 - 开发者可通过
Spaces快速部署交互式应用(如对话机器人、文本生成器)。
- 提供
三、Transformers介绍与安装

本章节讲解的内容为摘要方式,如果需要完全学习,可以去官网看完整的
如果没有空,其实也不影响后续达到微调的目的
1、Transformers库
github:https://github.com/huggingface/transformers
Transformers 是由 Hugging Face 开发的开源 Python 库,专注于提供先进的预训练模型和工具,支持自然语言处理(NLP)、计算机视觉(CV)、语音等多模态任务。
其核心理念是通过标准化接口,让开发者无需从零实现复杂模型,即可快速调用、微调和部署 SOTA(State-of-the-Art)模型,如 BERT、GPT、Stable Diffusion 等。
2、Transformers环境搭建
本次主要以windows,GPU安装为主,linux安装方案大同小异
(后面会讲解租用云服务器linux微调,不必担心)
2.1 安装python环境
conda create -n hf-env python=3.10.16 -y
conda activate hf-env
2.2 安装NVIDIA驱动及工具包
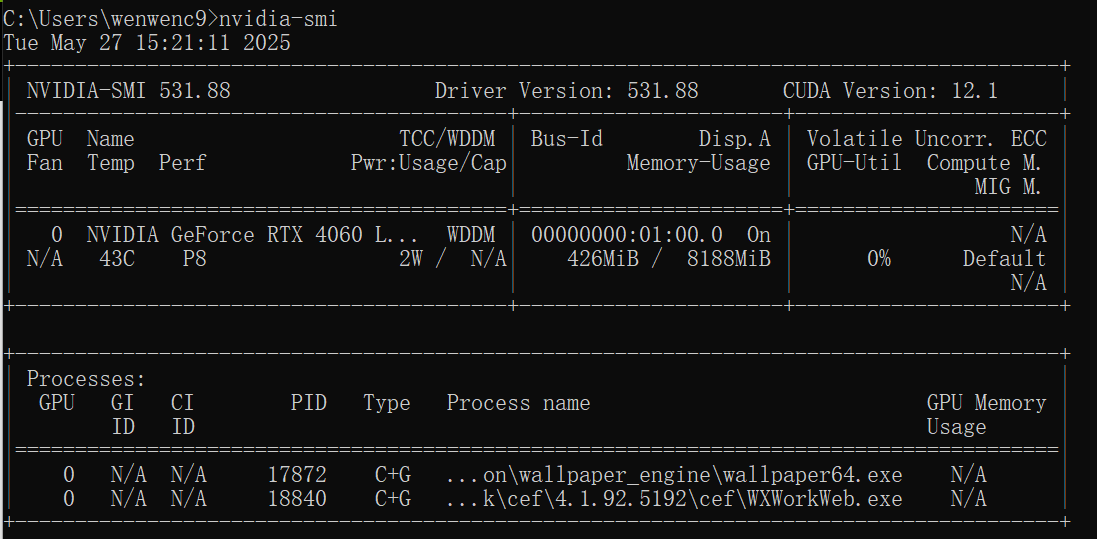
- GPU用户 已安装的可以跳过,可以输出下面命令检测
nvidia-smi
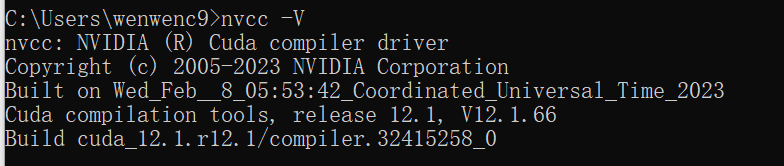
nvcc -V
2.2.1 安装显卡驱动
官方地址:https://www.nvidia.cn/drivers/lookup/
WIN+R 输入 dxdiag ,然后回车

在栏目中多点击选择一下,直到看到显卡参数

来到官网根据自己的显卡选择合适的参数


后面根据内容下载安装即可
2.2.2 安装CUDA工具包
官网网址:https://developer.nvidia.com/cuda-downloads
选择适合自己的安装即可,注意 nvidia-smi 有显示驱动版本,你要结合官方的实际情况下载CUDA 工具版本
官方说明:https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-major-component-versions__table-cuda-toolkit-driver-versions

选择自己合适的版本即可:
https://developer.nvidia.com/cuda-toolkit-archive
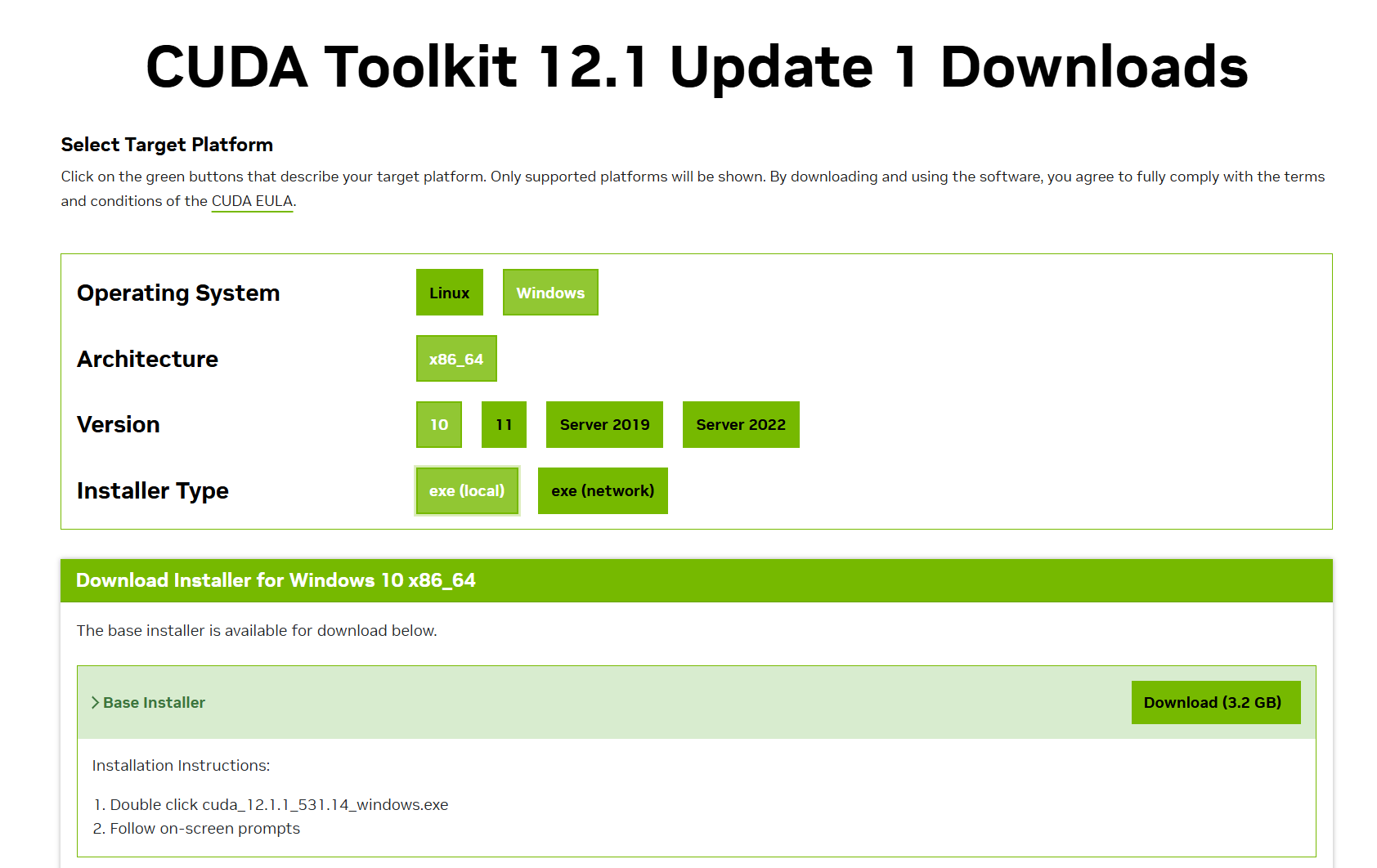
2.3 安装pytorch
GPU版本
| PyTorch版本 | 最低CUDA | Game Ready驱动版本 | Studio驱动版本 |
|---|---|---|---|
| 2.0+ | 11.7 | 525.85+ | R525 U2+ |
| 1.12 | 11.6 | 516.94+ | R516 U5+ |
| 1.10 | 11.3 | 471.96+ | R470 U3+ |
激活你的虚拟环境,开始准备安装!!!!!!!!!!!!!!!!!!!!!!
通过pip下载方式,你可以执行下面自动检测脚本来
import subprocess
import re
import sys
import os
def get_cuda_version():
"""通过多种方式检测系统CUDA版本"""
# 方式1: 通过nvcc编译器检测
try:
output = subprocess.check_output(["nvcc", "--version"], stderr=subprocess.STDOUT).decode()
if match := re.search(r"release (\d+\.\d+)", output):
return match.group(1)
except Exception:
pass
# 方式2: 通过CUDA安装目录检测
cuda_home = os.environ.get('CUDA_HOME', '') or os.environ.get('CUDA_PATH', '')
if cuda_home and os.path.isfile(ver_file := os.path.join(cuda_home, "version.txt")):
with open(ver_file) as f:
if match := re.search(r"CUDA Version (\d+\.\d+)", f.read()):
return match.group(1)
# 方式3: 通过NVIDIA驱动检测
try:
output = subprocess.check_output(["nvidia-smi", "--query-gpu=cuda_version", "--format=csv,noheader"],
stderr=subprocess.DEVNULL).decode()
if output.strip():
return output.strip().split('\n')[0]
except Exception:
pass
return None
def build_install_command():
"""构建安装命令"""
version_map = {
12: ("2.3.1+cu121", "0.18.1+cu121", "2.3.1+cu121", "cu121"),
11: ("2.3.1+cu118", "0.18.1+cu118", "2.3.1+cu118", "cu118")
}
if not (cuda_version := get_cuda_version()):
return "pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 --index-url https://pypi.tuna.tsinghua.edu.cn/simple"
try:
major_ver = int(cuda_version.split('.')[0])
except ValueError:
major_ver = 0
if major_ver not in version_map:
return "pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 --index-url https://pypi.tuna.tsinghua.edu.cn/simple"
torch_ver, vision_ver, audio_ver, cuda_tag = version_map[major_ver]
line_cont = "^" if sys.platform == "win32" else "\\"
return (
f"pip install torch=={torch_ver} torchvision=={vision_ver} torchaudio=={audio_ver} {line_cont}\n"
f"--extra-index-url https://download.pytorch.org/whl/{cuda_tag} {line_cont}\n"
f"--index-url https://pypi.tuna.tsinghua.edu.cn/simple"
)
if __name__ == "__main__":
print("自动生成的PyTorch安装命令:")
print(build_install_command())

pip install torch==2.3.1+cu121 torchvision==0.18.1+cu121 torchaudio==2.3.1+cu121 ^
--extra-index-url https://download.pytorch.org/whl/cu121 ^
--index-url https://pypi.tuna.tsinghua.edu.cn/simple
官网手动下载地址:https://download.pytorch.org/whl/cu121/torch_stable.html
如果你网络不好,可以选择手动安装whl方式
官网手动下载地址:https://download.pytorch.org/whl/cu121/torch_stable.html
pip install torch-2.3.1+cu121-cp310-cp310-win_amd64.whl
pip install torchvision-0.18.1+cu121-cp310-cp310-win_amd64.whl
pip install torchaudio-2.3.1+cu121-cp310-cp310-win_amd64.whl
CPU版本
虽然transformer部分模型支持CPU运行,但是还是建议大家搞个显卡吧,CPU版本不过讲解,跟上面流程一样
(未来微调模型必定要GPU的,第四章节的案例CPU本次可以运行起来部分)
pip install torch==2.3.1+cpu torchvision==0.18.1+cpu torchaudio==2.3.1+cpu
2.4 安装其它依赖
requirements.txt
# ------------------------
# Hugging Face 生态系统
# ------------------------
transformers==4.37.2 # 预训练语言模型库(BERT/GPT等)
datasets==2.16.1 # 超大规模数据集加载工具
accelerate==0.26.1 # 分布式训练加速框架
peft==0.7.1 # 参数高效微调工具(LoRA/Adalora)
trl==0.8.1 # 强化学习与人类反馈训练库
# ------------------------
# 模型量化与优化
# ------------------------
autoawq==0.2.2 # 4-bit 激活感知量化推理框架 依赖 triton(linux) windows安装: https://blog.csdn.net/Changxing_J/article/details/139785954
auto-gptq==0.6.0 # GPT模型量化工具(支持GPU推理加速)
# ------------------------
# 计算加速与量化支持
# ------------------------
bitsandbytes==0.41.3.post2 # 8-bit/4-bit CUDA量化核心库(需系统级CUDA支持) # https://pypi.org/project/bitsandbytes/#files
# ------------------------
# 数据处理与机器学习
# ------------------------
timm==0.9.12 # 前沿视觉模型库(ResNet/ViT等)
scikit-learn==1.3.2 # 经典机器学习算法库
pandas==2.1.1 # 结构化数据分析工具
# ------------------------
# 音频处理工具链
# ------------------------
ffmpeg==1.4 # 音视频编解码核心库(需通过conda安装)
ffmpeg-python==0.2.0 # FFmpeg 的 Python 接口
soundfile==0.12.1 # 音频文件读写库(支持WAV/FLAC等格式)
librosa==0.10.1 # 音频特征提取与处理
jiwer==3.0.3 # 语音识别评估工具(计算WER等指标)
# ------------------------
# 应用开发与部署
# ------------------------
gradio==4.13.0 # 快速构建AI演示界面(支持Web/API)
langchain==0.2.0 # 大语言模型应用开发框架(核心)
langchain-openai==0.1.7 # OpenAI 官方集成模块
langchain-core==0.2.1 # LangChain 核心依赖
langchain-community==0.2.0 # 社区贡献的扩展模块
openai==1.30.1 # OpenAI 官方SDK(GPT/DALL-E等接口)
jupyter # 安装 https://jupyter.org/install
2.5 验证环境
import torch
import bitsandbytes as bnb
print("\n=== 环境诊断报告 ===")
print(f"PyTorch 版本: {torch.__version__}")
print(f"CUDA 可用性: {torch.cuda.is_available()}")
print(f"GPU 设备: {torch.cuda.get_device_name(0)}")
print(f"bitsandbytes 版本: {bnb.__version__}")
# 新版获取CUDA版本方式
if hasattr(bnb, 'cuda_setup'):
print(f"CUDA 主版本: {bnb.cuda_setup.main_cuda_version()}")
else:
print("CUDA 版本检测接口已变更,请尝试以下方法验证:")
print(">>> 测试8-bit优化器:")
optimizer = bnb.optim.Adam8bit(torch.nn.Linear(1,1).parameters())
print("✅ bitsandbytes CUDA 支持正常")

四、Transformers库核心功能模块

-
统一接口设计:AutoClass体系实现模型无关编程
-
模块解耦:各组件可独立替换(如单独使用Tokenizer)
-
跨框架兼容:同时支持PyTorch/TensorFlow/JAX
-
生态集成:与Datasets/Accelerate等库深度整合
建议有空还是阅读一下官方文档的内容,本章节只采用深入浅出的方式
官方文档:https://hf-mirror.com/docs/transformers/v4.52.2/zh/index
transformers能做什么:https://hf-mirror.com/docs/transformers/v4.52.3/zh/task_summary

通过Hugging Face的Transformers库自动下载模型,会先缓存在默认路径:
Linux:~/.cache/huggingface/hub
Windows :C:\Users\<你的用户名>\.cache\huggingface\hub
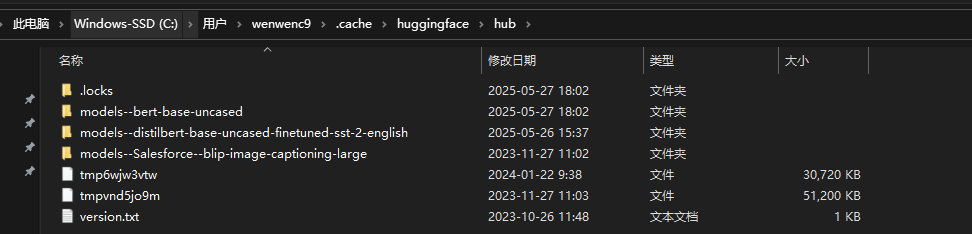
当然你可以,选择设置运行模块下载的模型放置别的目录
import os
os.environ['HF_HOME'] = '/mnt/new_volume/hf'
os.environ['HF_HUB_CACHE'] = '/mnt/new_volume/hf/hub'
1、模型配置文件
1.1 文件说明
1.1.1 常见文件说明
理解这些文件的作用后,就能更好地解决模型加载问题,调试错误,甚至创建自己的模型配置。
PS:仅列举经常见到的,不同模型还有其他类型文件!!!!!!看到新的,可以官方发布github查看相应文档说明
| 文件 | 用途 | 说明 |
|---|---|---|
config.json |
模型配置文件 | 定义模型架构参数(如隐藏层维度、注意力头数等),用于初始化模型 |
pytorch_model.bin |
模型权重文件(PyTorch) | 保存模型训练后的参数值 |
tf_model.h5 |
模型权重文件(TensorFlow) | 保存模型训练后的参数值(TensorFlow 格式) |
model.onnx |
模型权重文件(ONNX 格式) | 用于模型部署,支持跨平台推理 |
tokenizer_config.json |
分词器配置文件 | 定义分词器类型和参数(如最大长度、特殊标记等) |
vocab.json |
词汇表文件 | 存储分词器的词汇表(适用于 BPE 等分词方法) |
merges.txt |
合并规则文件 | 定义 BPE 分词中的合并规则 |
special_tokens_map.json |
特殊标记映射文件 | 定义特殊标记(如 [CLS]、[SEP])及其对应符号 |
training_args.bin |
训练参数文件 | 记录模型训练时的超参数(如学习率、批次大小等) |
tokenizer.json |
分词器完整配置文件 | 包含分词器的完整配置(可独立用于初始化分词器) |
added_tokens.json |
自定义标记文件 | 存储用户添加的自定义标记或词汇 |
比如:https://hf-mirror.com/google-bert/bert-base-chinese/tree/main

- 核心必需文件:
config.json+ 权重文件(pytorch_model.bin或model.safetensors或tf_model.h5) +tokenizer_config.json+special_tokens_map.json - 词表文件:根据模型类型选择:
vocab.txt(BERT)或merges.txt+vocab.json(GPT-2) - 安全权重:
model.safetensors是推荐的安全权重格式,尤其适合不信任的模型来源。 - Tokenizer 文件:
tokenizer_config.json:配置参数tokenizer.json:实际词汇表和规则(用于快速加载)- 若只有
vocab.txt也能工作,但加载速度可能慢
1.1.2 权重文件格式对比
| 权重格式 | 框架支持 | 安全 | 加载速度 | 大小 |
|---|---|---|---|---|
pytorch_model.bin |
PyTorch | ❌ | 快 | 中等 |
model.safetensors |
PyTorch/TF/JAX | ✅ | 快 | 中等 |
tf_model.h5 |
TensorFlow | ❌ | 慢 | 大(含优化器状态) |
1.1.3 如何加载模型
1.2 文件调用流程
PS:仅列举经常见到的,不同模型还有其他类型文件!!!!!!看到新的,可以官方发布github查看相应文档说明
from transformers import AutoConfig, AutoTokenizer, AutoModel
# 加载配置
config = AutoConfig.from_pretrained("bert-base-chinese")
# 加载分词器(会自动找到tokenizer_config.json和vocab.txt等)
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
# 加载模型(自动识别权重文件)
model = AutoModel.from_pretrained("bert-base-chinese")
1.2.1 深度解析
1. config.json:模型的DNA
from transformers import AutoConfig
# 加载配置
config = AutoConfig.from_pretrained("bert-base-chinese")
# 创建自定义配置
custom_config = AutoConfig.from_pretrained("bert-base-chinese")
custom_config.num_hidden_layers = 6 # 轻量版模型
# 无预训练权重建模
model = AutoModel.from_config(custom_config)
2. tokenizer 文件组:文本处理的流水线
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
# 查看组件关系
print("特殊Token:", tokenizer.special_tokens_map) # ← special_tokens_map.json
print("配置参数:", tokenizer.init_kwargs) # ← tokenizer_config.json
print("词汇大小:", tokenizer.vocab_size) # ← vocab.json
print("合并规则:", tokenizer.merge_file) # ← merges.txt (如存在)
3. 权重文件的跨框架支持
PS: 这里为手动调用模型框架,一定要看《 模型加载方法比对》加深理解
`PS: 这里为手动调用模型框架,一定要看《 模型加载方法比对》加深理解``
# PyTorch用户
from transformers import BertModel
model = BertModel.from_pretrained("bert-base-chinese")
# TensorFlow用户
from transformers import TFBertModel
model = TFBertModel.from_pretrained("bert-base-chinese") # 自动查找 tf_model.h5
4. 生成配置的使用
# 自定义生成参数
generation_config = {
"temperature": 0.8,
"top_p": 0.95,
"max_length": 200
}
# 保存为generation_config.json
with open("generation_config.json", "w") as f:
json.dump(generation_config, f)
# 加载模型时自动应用
pipe = pipeline("text-generation", model="path/to/model")
1.3 模型加载方法比对

| 特性 | 手动调用 | Auto Classes | Pipeline |
|---|---|---|---|
| 模型/框架指定 | 手动选择具体的模型类(如 BertModel) |
自动根据 config.json 选择模型架构 |
自动选择模型和框架 |
| Tokenizer 加载 | 手动加载分词器(如 BertTokenizer) |
自动加载匹配的分词器(AutoTokenizer) |
自动加载匹配的分词器 |
| 预处理 | 手动实现分词、编码、填充等 | 手动实现 | 自动处理 |
| 模型推理 | 手动调用模型,处理输入输出 | 手动调用模型,处理输入输出 | 自动处理 |
| 后处理 | 手动实现(如 softmax、实体聚合、标签映射) | 手动实现 | 自动处理(根据任务标准化输出) |
| 单行代码实现能力 | ❌ 需要多行代码 | ❌ 需要多行代码 | ✅ 一行代码启动 |
| 内置最佳实践 | ❌ 需用户自行实现 | ⚠️ 部分通过配置实现 | ✅ 自动应用行业最佳实践 |
| 自定义灵活性 | ✅ 完全控制(可修改任意中间过程) | ✅ 高灵活性(可访问模型各层) | ⚠️ 中等(通过参数调整,无法修改内部逻辑) |
| 项目启动速度 | ⚠️ 慢(需写大量代码) | ⚠️ 中等(需写部分代码) | ✅ 极快(开箱即用) |
| 适合人群 | 研究人员、框架开发者 | 进阶开发者、定制任务用户 | 初学者、应用工程师、快速原型 |
| 典型用例 | 模型架构修改、定制训练、调试 | 迁移学习、微调、模型分析 | 生产部署、API 服务、demo 演示 |
| 任务支持 | 所有任务(需自行实现) | 所有任务(需自行实现预处理和后处理) | 内置 60+ 任务(分类、NER、生成等) |
| 硬件优化 | 手动实现(如 fp16、设备放置) | 手动实现 | 自动优化(如设备切换、批处理) |
2、Pipeline(流程管道)
意义:
-
任何模型进行任何语言、计算机视觉、语音以及多模态任务的推理变得非常简单。
-
即使您对特定的模态没有经验,或者不熟悉模型的源码,您仍然可以使用pipeline()进行推理!
传统 NLP 开发 vs Pipeline


已支持的任务和可用参数的完整列表
https://hf-mirror.com/docs/transformers/v4.52.3/zh/main_classes/pipelines#transformers.pipeline
| 模块/功能 | 参数/方法 | 说明 | 示例 |
|---|---|---|---|
| 创建Pipeline | pipeline() |
核心创建函数,自动选择模型和配置 | pipe = pipeline("text-classification") |
| task (str) | 指定任务类型(必需参数) | task="sentiment-analysis" |
|
| model (str) | 指定预训练模型 | model="distilbert-base-uncased" |
|
| framework (str) | 指定框架(“pt”=PyTorch, “tf”=TensorFlow) | framework="pt" |
|
| 参数配置 | device (int) | 指定设备(-1=CPU, 0=第一块GPU) | device=0 |
| batch_size (int) | 批处理大小 | batch_size=32 |
|
| num_workers (int) | 数据加载线程数 | num_workers=4 |
|
| 音频任务 | audio-classification | 音频分类 | pipe = pipeline("audio-classification", model="speechbrain/spkrec-xvect") |
| automatic-speech-recognition | 语音识别 | pipe = pipeline("automatic-speech-recognition", model="openai/whisper-small") |
|
| 视觉任务 | image-classification | 图像分类 | pipe = pipeline("image-classification", model="google/vit-base-patch16-224") |
| object-detection | 目标检测 | pipe = pipeline("object-detection", model="facebook/detr-resnet-50") |
|
| 文本任务 | text-classification | 文本分类/情感分析 | pipe("I love transformers!") |
| token-classification | 命名实体识别 | pipe("My name is Sarah and I live in London") |
|
| question-answering | 问答系统 | pipe(question="Why?", context="Transformers are...") |
|
| text-generation | 文本生成 | pipe("The future of AI is", max_length=50) |
|
| 多模态任务 | visual-question-answering | 视觉问答 | pipe(image=image, question="What is in this picture?") |
| 功能方法 | .save_pretrained() |
保存Pipeline到本地 | pipe.save_pretrained("my_pipeline") |
from_pretrained() |
加载保存的Pipeline | pipe = pipeline.from_pretrained("my_pipeline") |
|
.__call__() |
执行推理的核心调用方法 | pipe(输入数据) |
|
| 高级特性 | PipelineRegistry | 注册自定义Pipeline(高级功能) | PipelineRegistry.register_pipeline() |
| 自定义后处理 | 覆盖后处理方法 | 继承Pipeline类并重写postprocess方法 |
|
| 输入参数 | kwargs | 任务特定参数(如max_length, temperature等) |
小技巧-玩转Hugging Face
我们可以点击这些板块,找到开源模型,跟数据集使用
小技巧-读源码,定位方法的使用
QA小技巧,学习的过程中没必要记住所有的方法,以创建了piplines怎么确认传参为例子
Pipline 源代码位置 https://github.com/huggingface/transformers/blob/main/src/transformers/pipelines/init.py
我在这里演示,指定了QA任务,传入什么参数的查找过程,可以看到为传去 question context
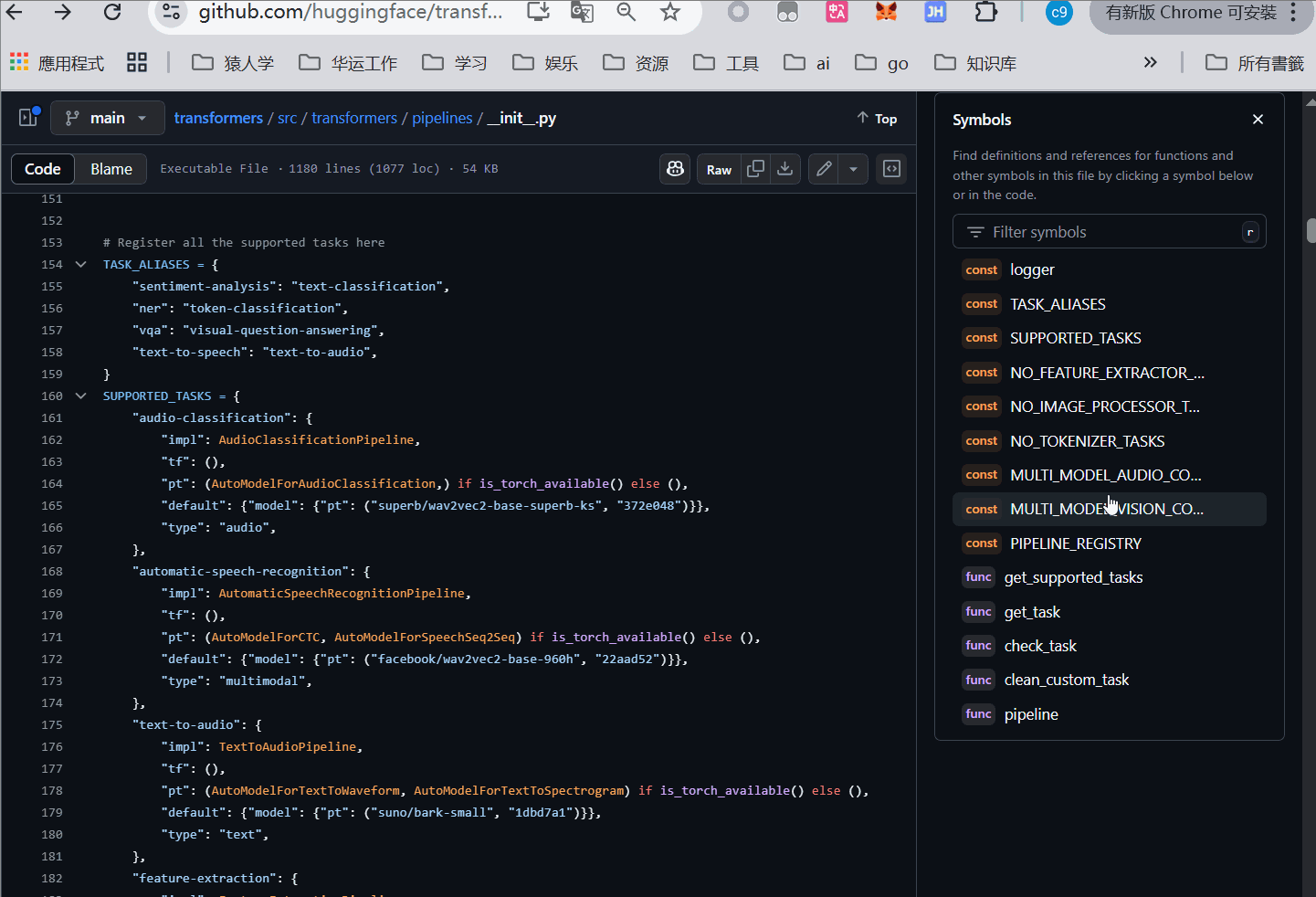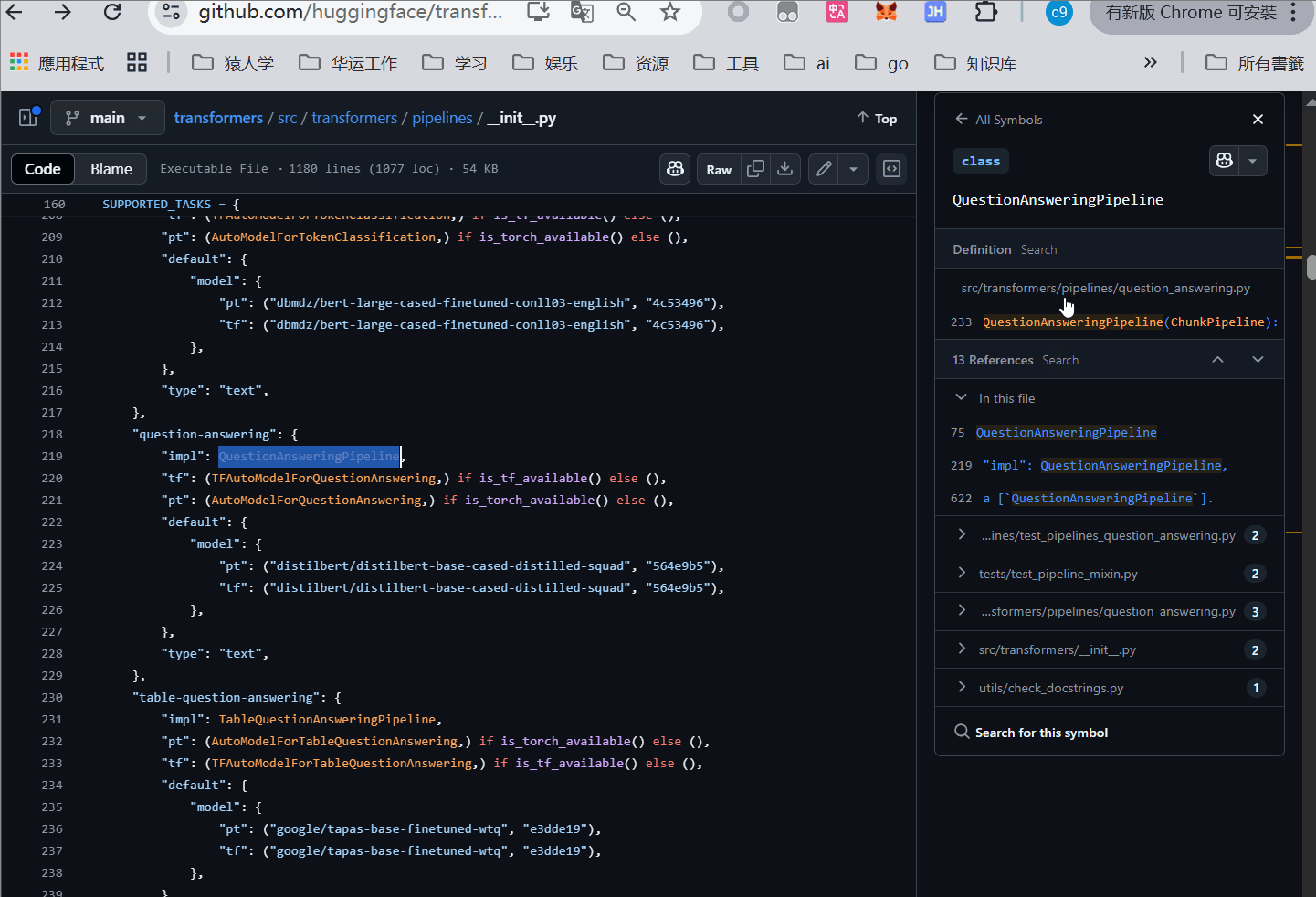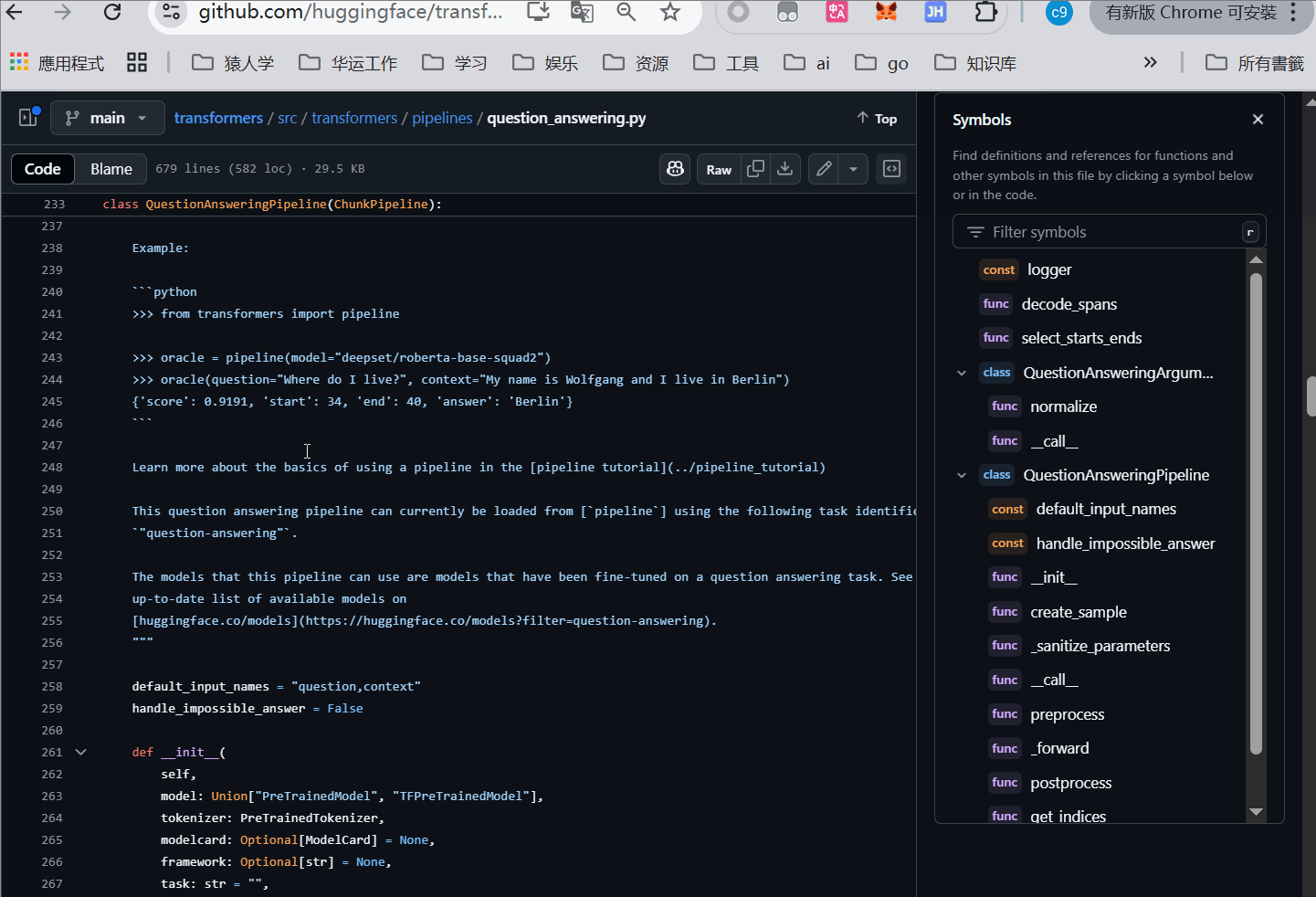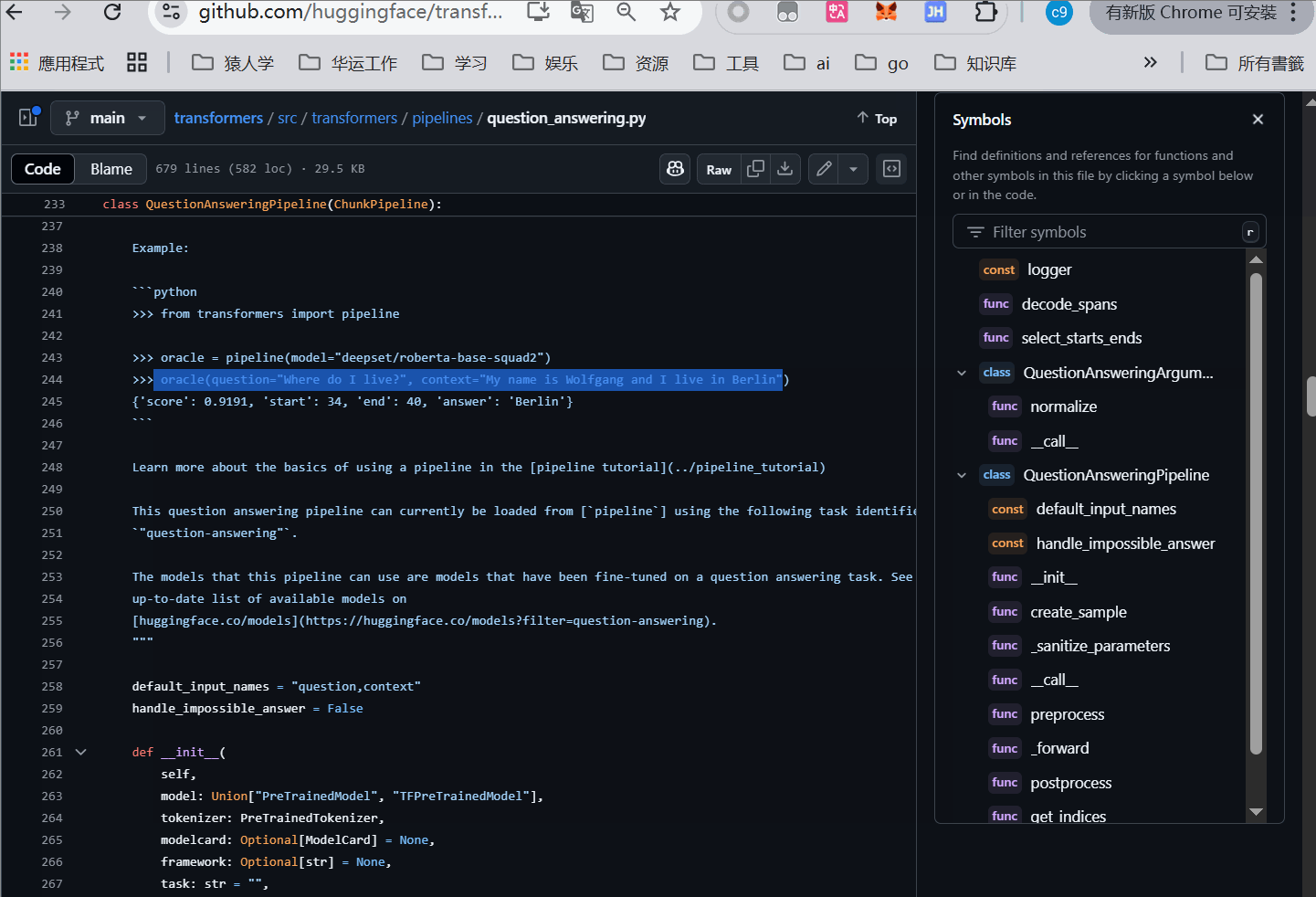
2.1 自然语言处理

| 任务类型 | 任务描述 | 常见应用场景 | 代表性模型/方法 |
|---|---|---|---|
| 文本分类 | 将文本划分到预定义的类别中 | 垃圾邮件识别、新闻分类、情感分析等 | 传统机器学习(如SVM、朴素贝叶斯)+TF-IDF特征;深度学习(如BERT、TextCNN) |
| Token分类 | 对文本中的每个Token(如单词、字符等)进行分类标注 | 命名实体识别(NER)、词性标注等 | BERT+CRF、BiLSTM+CRF |
| 问答 | 根据给定问题生成对应的答案 | 智能客服、知识问答系统等 | T5、GPT系列、BERT-based问答模型 |
| 摘要 | 从长文本中提取关键信息生成简短摘要 | 新闻摘要、学术文献摘要等 | BART、PEGASUS、Transformer-based编码器-解码器架构 |
| 翻译 | 将一种语言的文本转换为另一种语言的文本 | 跨语言交流、多语言文档处理等 | Transformer、 MarianMT、百度翻译模型等 |
| 语言模型 | 预测文本序列中下一个Token的概率分布 | 文本生成、自动补全、语言理解等 | GPT系列、Transformer-XL、XLNet |
自然语言处理案例有很多,我就不按照案例讲解,以串联过程,讲解重点功能
2.1.1 Text classification(文本分类)
1. 默认模型
在这里,我指定了任务类型为情感分类,model参数没有指定
默认使用的模型为:distilbert-base-uncased-finetuned-sst-2-english
task 优先原则:当指定任务而不指定模型时,Pipeline 会自动选择最适合该任务的默认模型
from transformers import pipeline
# 仅指定任务时,使用默认模型(不推荐)
pipe = pipeline(task="sentiment-analysis", device='cuda')
print(pipe("小明是好人"))
print(pipe("小红是坏人"))
print(pipe("This restaurant is awesome"))
print(pipe("This restaurant is bad"))
可以看到中文的score置信度很低,英文的却很高
[{'label': 'NEGATIVE', 'score': 0.5197433233261108}]
[{'label': 'NEGATIVE', 'score': 0.774127721786499}]
[{'label': 'POSITIVE', 'score': 0.9998743534088135}] # 积极的
[{'label': 'NEGATIVE', 'score': 0.9998098015785217}] # 消极的
2.指定模型
在这里我替换一下模型使用,再来看看中文的效果
https://hf-mirror.com/lxyuan/distilbert-base-multilingual-cased-sentiments-student
from transformers import pipeline
pipe = pipeline(task="sentiment-analysis", model="lxyuan/distilbert-base-multilingual-cased-sentiments-student",device='cuda')
print(pipe("小明是好人"))
print(pipe("小红是坏人"))
print(pipe("This restaurant is awesome"))
print(pipe("This restaurant is bad"))
可以看到对于中文置信度很高了
[{'label': 'positive', 'score': 0.9678574204444885}]
[{'label': 'negative', 'score': 0.9101658463478088}]
[{'label': 'positive', 'score': 0.9811712503433228}]
[{'label': 'negative', 'score': 0.9343340396881104}]
3.批量调用模型推理
from transformers import pipeline
pipe = pipeline(task="sentiment-analysis", model="lxyuan/distilbert-base-multilingual-cased-sentiments-student",device='cuda')
print(pipe(["小明是好人","小明是坏人"]))
输出
[{'label': 'positive', 'score': 0.9678574204444885},
{'label': 'negative', 'score': 0.911962628364563}]
2.1.2 Token Classification (token分类)
在任何NLP任务中,文本都经过预处理,将文本序列分成单个单词或子词。这些被称为tokens。
Token Classification(Token分类)将每个token分配一个来自预定义类别集的标签。
两种常见的 Token 分类是:
命名实体识别(NER):根据实体类别(如组织、人员、位置或日期)对token进行标记。NER在生物医学设置中特别受欢迎,可以标记基因、蛋白质和药物名称。词性标注(POS):根据其词性(如名词、动词或形容词)对标记进行标记。
POS对于帮助翻译系统了解两个相同的单词如何在语法上不同很有用(作为名词的银行与作为动词的银行)。
1.命名实体识别(NER)
下面我们调用一个命名实体ner模型
模型主页:https://hf-mirror.com/ckiplab/bert-base-chinese-ner
在模型的files,config.json 有说明标签
https://hf-mirror.com/ckiplab/bert-base-chinese-ner/blob/main/config.json
每个标签是对归属的简写,比如"30": "I-ORG", ORG 代表的是组织
import os
# 设置镜像源(推荐国内源)
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com' # 国内镜像源
from transformers import pipeline
# 创建NER管道(使用中文预训练模型)
ner = pipeline(
# grouped_entities=True,
task="token-classification",
model="ckiplab/bert-base-chinese-ner",
device='cuda' # 使用GPU加速,
)
# 待分析文本
text = "小红是中国人,在上海大学读书"
# 进行实体识别
entities = ner(text)
# 打印原始结果
print("===== 原始识别结果 =====")
for entity in entities:
print(f"{entity['word']} → {entity['entity']} (置信度: {entity['score']:.3f})")
输出
===== 原始识别结果 =====
小 → B-PERSON (置信度: 1.000)
红 → E-PERSON (置信度: 1.000)
中 → B-NORP (置信度: 1.000)
国 → I-NORP (置信度: 1.000)
人 → E-NORP (置信度: 1.000)
上 → B-ORG (置信度: 1.000)
海 → I-ORG (置信度: 1.000)
大 → I-ORG (置信度: 1.000)
学 → E-ORG (置信度: 1.000)
上面效果看起来不是很好看,我们可以加以合并更修饰
2.实体合并
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from transformers import pipeline
# 创建NER管道(使用聚合策略)
ner = pipeline(
task="token-classification",
model="ckiplab/bert-base-chinese-ner",
aggregation_strategy="simple", # 关键设置
device='cuda'
)
text = "小红是中国人,在上海大学读书"
entities = ner(text)
# 打印结果
print("===== 完整实体识别结果 =====")
for entity in entities:
print(f"{entity['word']} → {entity['entity_group']} (置信度: {entity['score']:.3f})")
# 补充:理解实体类型
print("\n===== 实体类型解释 =====")
entity_types = {
'PERSON': '人名',
'ORG': '组织机构',
'NORP': '民族/宗教团体',
'LOC': '地点',
'GPE': '国家/城市',
'MISC': '其他',
'FAC': '设施',
'PRODUCT': '产品'
}
for entity in entities:
print(f"{entity['word']}: {entity_types.get(entity['entity_group'], '未知类型')}")
输出
可以看到效果还是挺好的,输出内容不再单个割裂,国家也能组合出来 “中国”
===== 完整实体识别结果 =====
小 → PERSON (置信度: 1.000)
红 → PERSON (置信度: 1.000)
中 国 → NORP (置信度: 1.000)
人 → NORP (置信度: 1.000)
上 海 大 → ORG (置信度: 1.000)
学 → ORG (置信度: 1.000)
===== 实体类型解释 =====
小: 人名
红: 人名
中 国: 民族/宗教团体
人: 民族/宗教团体
上 海 大: 组织机构
学: 组织机构
2.1.3 Question Answering(问答)
| 问答类型 | 核心特点 | 典型模型 | 适用场景 | 优势 | 局限性 |
|---|---|---|---|---|---|
| 抽取式问答 (Extractive QA) | 从上下文直接抽取答案文本片段 | BERT, RoBERTa, XLNet | 阅读理解、文档问答 | 准确度高、支持事实性回答 | 答案必须在原文中 |
| 生成式问答 (Generative QA) | 生成自然语言答案文本 | T5, BART, GPT系列 | 开放域问答、解释性回答 | 答案不受原文限制 | 可能产生事实错误 |
| 开放域问答 (Open-Domain QA) | 不依赖给定上下文 | DPR (Dense Passage Retrieval), REALM | 百科问答、智能助手 | 无需预设知识库 | 依赖外部知识检索 |
| 基于知识的问答 (KBQA) | 利用知识图谱推理 | DrQA, UNIK-QA | 专业领域问答 | 支持复杂推理 | 依赖预构建知识库 |
| 多跳问答 (Multi-Hop QA) | 跨多文档/段落推理 | HotpotQA, PathNet | 复杂问题回答 | 支持深层次推理 | 计算复杂度高 |
| 视觉问答 (VQA) | 结合图像理解 | ViLBERT, LXMERT | 图文混合问答 | 多模态融合 | 依赖视觉识别能力 |
问答的模型有很多,本文不做过多展示,下面就展示传统的抽取式问答
模型地址:https://hf-mirror.com/uer/roberta-base-chinese-extractive-qa
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from transformers import pipeline
model = pipeline(
task="question-answering",
model="uer/roberta-base-chinese-extractive-qa",
device='cuda'
)
# res = model(
# {'question': "稳稳C9是谁",
# 'context': "稳稳C9是CSDN一名博主,处理爬虫,以及前沿AI\n 小明是小红的男朋友"}
#
# )
res = model(question="稳稳C9是谁", context="稳稳C9是CSDN一名博主,处理爬虫,以及前沿AI\n 小明是小红的男朋友")
print(res)
输出
还是挺不错的,我输入了1个干扰内容
{'score': 0.07943948358297348, 'start': 11, 'end': 13, 'answer': '博主'}
2.1.4 Summarization(文本摘要)
| 摘要类型 | 核心特点 | 典型模型 | 适用场景 | 优势 | 局限性 |
|---|---|---|---|---|---|
| 抽取式摘要 | 从原文中直接抽取关键句子或片段 | BERT, TextRank, BM25+ | 新闻摘要、长文档概览 | 保留原文准确性,避免事实错误 | 摘要不够流畅,无法生成新词 |
| 生成式摘要 | 理解原文后重新生成简洁摘要 | T5, BART, PEGASUS, GPT系列 | 生成流畅摘要、个性化摘要 | 摘要更自然、简洁 | 可能偏离原意,存在幻觉风险 |
| 多文档摘要 | 从多个相关文档中生成统一摘要 | MultiDoc, HMNet | 舆情分析、跨文档信息整合 | 支持跨文档信息融合 | 整合难度大,需要处理冗余信息 |
| 引导式摘要 | 根据用户指定的关键词或主题生成摘要 | CTRLSum, Concept-guided Summarization | 个性化摘要生成、领域聚焦摘要 | 定制化摘要内容 | 依赖引导信息的质量 |
| 对话摘要 | 提取和整合对话中的核心信息 | TODSum, DialoGPT | 会议记录、客服对话总结 | 处理多轮对话结构 | 对话信息分散,主题不连贯 |
| 长文档摘要 | 处理超长文本(10K token以上) | LED, PRIMERA | 学术论文摘要、长篇小说概览 | 支持长上下文建模 | 资源消耗大,复杂度高 |
本小节,演示抽取式摘要模型
模型地址:https://hf-mirror.com/utrobinmv/t5_summary_en_ru_zh_base_2048
这里多说一下,该模型还有挺多用法,可以往下浏览
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from transformers import pipeline
model = pipeline(
task="summarization",
model="utrobinmv/t5_summary_en_ru_zh_base_2048",
device='cuda',
)
res = model("""summary: 央广网北京6月10日消息(总台中国之声记者韩雪莹 朱宏源)据中央广播电视总台中国之声报道,一群看上去只有十几岁的少年,骑着山地自行车,
不戴护具、无视人流,在城市的商圈楼宇、公园广场,从台阶、高坡等数米高的位置急速俯冲而下,
过往行人不得不紧急避让……近期,一些未成年人在公共场所骑速降自行车炫技的短视频广泛传播,引发市民担忧。
其中,部分“速降少年”因操作失误引发危险伤及自身,更有甚者,自行车失控撞倒路人。看似炫酷的极限运动,存在哪些安全隐患?
速降山地自行车运动又该如何规范发展、不负热爱
""")
print(res)
输出
[{'summary_text': '一群看上去只有十几岁的少年,骑着山地自行车,不戴护具、无视人流,在城市的商圈楼宇、公园广场,从台阶、高坡等数米高的位置急速俯冲而下。'}]
2.2 音频处理
音频处理有很多好玩的,比如识别音频中多少人,等等
本小节演示,音频的情感分类
在 huggingface上面有很多数据集可以公开使用,这里我们要找一个音频,你也可以自己找
(我在下面代码里面已经准备了一个)
2.1 环境安装
安装windows FFmpeg
访问 FFmpeg 官方网站:https://ffmpeg.org/download.html
下载 Windows 版本(推荐:https://github.com/BtbN/FFmpeg-Builds/releases)
- 解压下载的 ZIP 文件(例如到 C:\ffmpeg)
- 将 FFmpeg 添加到系统环境变量:
- 打开 “系统属性” > “高级” > “环境变量”
- 在 “系统变量” 中找到Path,点击编辑
- 添加 FFmpeg 的 bin 目录路径(例如 C:\ffmpeg\bin)点击确定保存
记得重启IDE
验证环境
ffmpeg -version
2.2 音频情感分类
本次使用模型:https://hf-mirror.com/firdhokk/speech-emotion-recognition-with-openai-whisper-large-v3

这是一段语气激昂的一段录音,听起来有点生气
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from transformers import pipeline
model = pipeline(
task="audio-classification",
model="firdhokk/speech-emotion-recognition-with-openai-whisper-large-v3",
device='cuda',
)
res = model("https://hf-mirror.com/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
print(res)
输出
[{'score': 0.9832255244255066, 'label': 'angry'}, # 可以看到置信度很高
{'score': 0.014977349899709225, 'label': 'happy'},
{'score': 0.0007455425802618265, 'label': 'fearful'},
{'score': 0.0005094102816656232, 'label': 'neutral'},
{'score': 0.00019644349231384695, 'label': 'sad'}]
2.3 图片处理

模型地址: https://hf-mirror.com/google/vit-base-patch16-224
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from transformers import pipeline
model = pipeline(
task="image-classification",
model="google/vit-base-patch16-224",
device='cuda',
)
res = model("https://img0.baidu.com/it/u=2156020984,3145770830&fm=253&fmt=auto&app=138&f=JPEG")
print(res)
输出
[{'label': 'Pomeranian', 'score': 0.5816799402236938},
{'label': 'Eskimo dog, husky', 'score': 0.10331527143716812},
{'label': 'Chihuahua', 'score': 0.09424787759780884},
{'label': 'Japanese spaniel', 'score': 0.018894687294960022},
{'label': 'Pembroke, Pembroke Welsh corgi', 'score': 0.01833692565560341}]
可以看到输出了博美犬
其余标签请查看
https://hf-mirror.com/google/vit-base-patch16-224/blob/main/config.json
2.3 视频处理
视频处理的模型很多,比如暴力,颜色检测,等等

模型地址:https://hf-mirror.com/MCG-NJU/videomae-large-finetuned-kinetics
安装一个包
pip install decord
数据集地址:
https://hf-mirror.com/datasets/sayakpaul/ucf101-subset/blob/main/v_BasketballDunk_g14_c06.avi


这是一段NBA,篮球比赛的视频
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from transformers import pipeline
model = pipeline(
task="video-classification",
model="MCG-NJU/videomae-large-finetuned-kinetics",
device='cuda',
)
res = model("https://hf-mirror.com/datasets/sayakpaul/ucf101-subset/resolve/main/v_BasketballDunk_g14_c06.avi?download=true")
print(res)
输出
[{'score': 0.44488775730133057, 'label': 'dunking basketball'},
{'score': 0.12890341877937317, 'label': 'playing basketball'},
{'score': 0.04511522129178047, 'label': 'dribbling basketball'},
{'score': 0.03531673923134804, 'label': 'shooting basketball'},
{'score': 0.0020291220862418413, 'label': 'ski jumping'}]
3、Datasets & Tokenizers(数据预处理)
在 Hugging Face 生态中,Datasets 和 Tokenizers 是数据预处理的核心组件,它们共同构成了高效数据处理的基石。
3.1 Datasets

核心特点:
- 海量数据集 & 简单加载: 提供对成千上万公开数据集(涵盖 NLP、CV、音频等)的一键式访问 (
load_dataset)。 - 高性能处理: 底层使用 Apache Arrow 内存格式和零拷贝读取,处理速度极快,特别适合处理大规模数据集。
- 内存映射 (Memory-Mapping): 数据集只在访问时加载到内存,极大节省内存开销,轻松处理超大数据集(超过内存大小)。
- 流式处理 (Streaming): 支持数据集流式读取(
load_dataset(..., streaming=True)),无需下载整个数据集到本地,即可逐条或小批量处理,极大加速处理超大、远程数据集的开局速度。 - 灵活的转换 (Transforms): 提供类似
map和filter的转换方法,可以轻松地对数据集进行清洗、分词、格式转换等操作。转换通常是惰性执行的。 - 版本管理与缓存: 自动缓存处理过的数据集和加载的数据集,避免重复加载和转换。支持数据集版本管理。
- 与框架集成: 方便地转换为 PyTorch
DataLoader(to_torch_dataset/DataLoader(dataset, ...)) 或 TensorFlowtf.data.Dataset(to_tf_dataset)。
官方文档
https://hf-mirror.com/docs/datasets/v2.16.1/en/loading
官方文档写的很详细,所以本小节主要还是以经常使用的场景进行分享即可,深入了解,我觉得根据实际需求
去到官方文档找对应的内容即可,无需纠结

3.1.1 加载数据
- load_dataset_builder 检查数据不下载本地
- load_dataset 完全下载到本地
如果不想下载完整数据,想预览一下数据集可以到hub查看,或者通过load_dataset_builder确认
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from datasets import load_dataset_builder
ds_builder = load_dataset_builder("stanfordnlp/imdb")
print(ds_builder.info.description)
print(ds_builder.info.features)
输出
Downloading readme: 7.81kB [00:00, ?B/s]
{'text': Value(dtype='string', id=None), 'label': ClassLabel(names=['neg', 'pos'], id=None)}
利用 load_dataset 下载数据到本地
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from datasets import load_dataset
# 加载 电影数据集
dataset = load_dataset("stanfordnlp/imdb")
print(dataset)
输出
Downloading data: 100%|██████████| 21.0M/21.0M [00:04<00:00, 4.56MB/s]
Downloading data: 100%|██████████| 20.5M/20.5M [00:04<00:00, 4.92MB/s]
Downloading data: 100%|██████████| 42.0M/42.0M [00:08<00:00, 5.01MB/s]
Generating train split: 100%|██████████| 25000/25000 [00:00<00:00, 431023.20 examples/s]
Generating test split: 100%|██████████| 25000/25000 [00:00<00:00, 625022.95 examples/s]
Generating unsupervised split: 100%|██████████| 50000/50000 [00:00<00:00, 617288.72 examples/s]
DatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
test: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
unsupervised: Dataset({
features: ['text', 'label'],
num_rows: 50000
})
})
windows默认加载路径

- Datasets 库支持从
本地加载数据集,支持多种格式(如 CSV、JSON、文本文件等)
dataset = load_dataset("csv", data_files="path/to/file.csv")
- 查看加载后的数据信息

load_dataset 还有很多常用属性,这里提及一下split可以只加载训练集,这块是根据开源数据标签区分的
并不是所有数据集的都有 train
dataset_train = load_dataset("stanfordnlp/imdb",split="train")
- 更多方法可以查看源码
https://github.com/huggingface/datasets/blob/2.16.1/src/datasets/load.py#L2251

3.1.2 访问数据
-
查看数据相关信息
data_train = dataset['train']data_train.infodata_train.features
-
索引访问某一行
data_train[0] -
根据列名访问
data_train.column_names # ['text', 'label'] data_train['text'] -
还有很多聚合复杂访问,请看开头官方文档
3.1.3 操作数据
-
过滤数据
data_train.filter(lambda x:x['label'] == 1)
-
排序数据
使用 sort() 根据其数值对列值进行排序。提供的列必须是 NumPy 兼容的’
https://hf-mirror.com/docs/datasets/v2.16.1/en/process#sortdata_train.sort('text') -
拆分数据
https://hf-mirror.com/docs/datasets/v2.16.1/en/process#split
将部分数据拆成为测试数据data_train.train_test_split(test_size=0.1)DatasetDict({ train: Dataset({ features: ['text', 'label'], num_rows: 22500 }) test: Dataset({ features: ['text', 'label'], num_rows: 2500 }) }) -
分片数据
https://hf-mirror.com/docs/datasets/v2.16.1/en/process#shard
原本数据有25000行,分成4等份,从第0位开始data_train.shard(num_shards=4, index=0)
-
数据映射
https://hf-mirror.com/docs/datasets/v2.16.1/en/process#map
通过map方法,将原本里面内容全部大写def preprocess_function(example): example['text'] = example['text'].upper() return example data_train2 = data_train.map(preprocess_function)
当然支持批量处理,减少map时间data_train3 = data_train.map(preprocess_function,batched=True,batch_size=100)
3.1.4 导出数据
这个没有什么好说的,自己看一下就好了
https://hf-mirror.com/docs/datasets/v2.16.1/en/process#save
https://hf-mirror.com/docs/datasets/v2.16.1/en/process#export
3.2 Tokenizers

Tokenizers原生
官方代码:https://github.com/huggingface/tokenizers/tree/v0.15.2
官方文档:https://hf-mirror.com/docs/tokenizers/main/en/index
transformers的集成API文档
https://hf-mirror.com/docs/transformers/v4.37.2/en/main_classes/tokenizer
调用方式
-
from transformers import AutoTokenizer- 这是Hugging Face Transformers库提供的高级API,它封装了底层的tokenizers库,并提供了与Transformers模型的无缝集成。
- 使用
AutoTokenizer可以自动根据模型名称加载对应的分词器(如’bert-base-uncased’),并且返回的是transformers.PreTrainedTokenizer(或其子类)的实例,这类分词器可以直接用于Transformers模型的输入处理。
-
from tokenizers import Tokenizer- 这是直接使用Hugging Face的tokenizers库,这是一个用Rust编写的快速分词库。它提供了构建和使用分词器的底层接口。
- 这里的
Tokenizer类是一个通用的分词器,可以通过配置文件或者代码来构建分词器(如BPE、WordPiece等),然后进行训练和使用。
关系
-
transformers库中的分词器(如BertTokenizer)通常使用tokenizers库作为后端引擎(特别是新版的Transformers库)。例如,当你调用AutoTokenizer.from_pretrained加载一个分词器时,对于许多模型,它实际上是在内部使用了tokenizers库的Tokenizer类。 -
但是,
transformers库的分词器类(PreTrainedTokenizer)提供了额外的功能,比如与模型类对齐的特殊标记(如[CLS]、[SEP])的自动处理,以及提供与模型输入格式一致的方法(如返回attention_mask、token_type_ids等)。
总结
-
如果你使用的是Transformers库中的模型,那么推荐使用
transformers中的分词器(如AutoTokenizer),因为这样能确保分词方式与模型预训练时一致,并且可以方便地处理模型输入所需的各种字段。 -
如果你需要训练一个新的分词器,或者想要直接使用底层分词库的高性能特性,那么你可以使用
tokenizers库。然后,你也可以通过transformers库的PreTrainedTokenizerFast将这个分词器包装成Transformers库可以使用的格式。
| 特性维度 | tokenizers 库 (原生) | transformers.AugTokenizer (集成) |
|---|---|---|
| 开发定位 | 独立高性能分词引擎 | Transformers 模型的配套组件 |
| 主要语言 | Rust (核心) + Python 绑定 | Python |
| 性能特点 | 优化极致速度 (比transformers快5-10倍) | 接口友好但速度较慢 |
| 使用复杂度 | 需要构建训练管道 (中高级) | 一行代码加载预训练 (入门友好) |
| 适用场景 | 定制化分词器训练/高性能需求 | 直接使用预训练模型 |
PS:本节内容基本以transformers框架的 分词器讲解
3.2.1 为什么需要分词器?
假设现在我们要处理一个文本
text = "📌@稳稳C9 最爱🚴骑行,不喜欢钓鱼,#技术分享时! 说:'关注我的博客!' 网址https://blog.csdn.net/weixin_44238683"
-
传统方案
直接字符串切割处理字符列表 = [📌, @, 稳, 稳, C, 9, , 最, 爱, 🚴, ...]问题产生
- URL 被拆成碎片:长 URL 变成无意义字符序列
- 无法识别专业平台:博客地址包含 “csdn” 技术社区名却被拆分
- 用户名处理不当:“@稳稳 C9” 中的用户名关联被破坏
- 关键符号丢失:博客 URL 中的下划线 (_) 和点 (.) 被忽略
-
Tokenizer 方案tokens = [ "📌", "@", "稳稳", "C9", "最爱", "🚴骑行", ",", "不喜欢", "钓鱼", ",", "#", "技术分享", "时", "!", "说", ":", "'", "关注", "我的", "博客", "!", "'", "网址", "https://blog.csdn.net/weixin_44238683" ] -
分析比对问题类型 Tokenizer 解决方案 案例体现 平台识别 保留完整URL 完整保留CSDN博客地址 技术内容处理 识别技术社区名称"csdn" 保护技术专有名词 用户标识 保护用户名关联 "@稳稳C9"保持整体关联 符号保护 保留URL中的特殊字符 下划线和点号完整保留
3.2.2 以工作流程来理解分词器
预清洗
可以看到文本有个特殊符号 "hello,how are you? ❌"
预清洗:就像是为分词器打扫 “工作台”,只有干净的环境,才能实现精准的分词结果!
- 防止噪声干扰:去除多余的空白、不可见字符和非语义符号,确保分词器专注于有意义内容
- 统一格式标准:将所有文本转换为统一编码(如 UTF-8),避免特殊字符错误
- 信息安全保护:处理敏感信息(如完整 URL),避免隐私泄露
- 规范化表达:将变体表达(如不同形式的引号)转换为标准形式
- 提高模型鲁棒性:为后续处理准备干净的输入源,降低错误传递风险
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
input_text = "hello,how are you? ❌"
def clean_text(text):
# 替换特殊符号
text = text.replace("❌", "")
return text.strip()
cleaned_text = clean_text(input_text)
print(cleaned_text)
执行分词器
模型地址:https://hf-mirror.com/google-bert/bert-base-chinese
官方文档:https://hf-mirror.com/docs/transformers/v4.37.2/en/main_classes/tokenizer
from transformers import AutoTokenizer
# 加载预训练的分词器
tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-chinese")
tokens_1 = tokenizer(input_text) # 没进行清洗的输入
print(tokens_1)
tokens_2 = tokenizer(cleaned_text) # 清洗后的输入
print(tokens_2)
输出
{'input_ids': [101, 8701, 117, 9510, 8995, 8357, 136, 100, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
{'input_ids': [101, 8701, 117, 9510, 8995, 8357, 136, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1]}
键值对说明
-
input_ids:token 对应的 ID 列表。
https://hf-mirror.com/docs/transformers/v4.37.2/en/glossary#input-ids -
attention_mask:注意力掩码,1 实际内容,0 填充内容 。
https://hf-mirror.com/docs/transformers/v4.37.2/en/glossary#attention-mask -
token_type_ids(可选):用于区分句子对的任务(如 BERT)。
https://hf-mirror.com/docs/transformers/v4.37.2/en/glossary#token-type-ids
[101, 8701, 117, 9510, 8995, 8357, 136, 100, 102] 说明
获取完整词汇表,其实就是内容键值关系,你可以查看
vocab_dict = tokenizer.get_vocab()

为什么2个,清洗前后开头都是 101,跟102?
在BERT分词器中,有固定的特殊标记系统
| 特殊标记 | ID | 功能 | 在序列中的位置 |
|---|---|---|---|
[CLS] |
101 | 分类标记(Classification) | 序列开头 |
[SEP] |
102 | 分隔标记(Separator) | 序列结尾或句子间 |
[PAD] |
0 | 填充标记(Padding) | 填充位置 |
[UNK] |
100 | 未知标记(Unknown) | 未知词位置 |
[MASK] |
103 | 掩码标记(Masked ) | 掩码语言 |
其实从堆栈也能看到

解码
在前面,我们编码了两个内容,现在编码查看效果
tokenizer.decode(tokens_1['input_ids'])
tokenizer.decode(tokens_2['input_ids'])
可以看到我们的解码后的,没有进《清洗的数据》出现了[UNK]代表未知标记

当然为了更形象,你也可以运行如下代码
# 解码演示
def decode_demo(ids):
"""解码并显示差异"""
text = tokenizer.decode(ids)
print(f"IDs: {ids}")
print(f"解码: {text}")
print("="*50)
# 原始文本解码
decode_demo(tokens_1['input_ids'])
# 清洗后解码
decode_demo(tokens_2['input_ids'])
输出
IDs: [101, 8701, 117, 9510, 8995, 8357, 136, 100, 102]
解码: [CLS] hello, how are you? [UNK] [SEP]
==================================================
IDs: [101, 8701, 117, 9510, 8995, 8357, 136, 102]
解码: [CLS] hello, how are you? [SEP]
==================================================
3.2.3 分词器深入理解
PS:这章节最好!最好是动手操作,理解一下这个参数意义
源代码位置: https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/tokenization_utils_base.py
from transformers import AutoTokenizer
# 加载预训练的分词器
tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-chinese")
tokens_1 = tokenizer(input_text) # 没进行清洗的输入
运行这段代码在tokens_1 单步调试DEBUG进去(本文文章开头GIF 里面有跳转路径)
BERT 模型都是继承 PreTrainedTokenizerBase

其实我们可以看一下这个基类的所有子类方法,点击红色
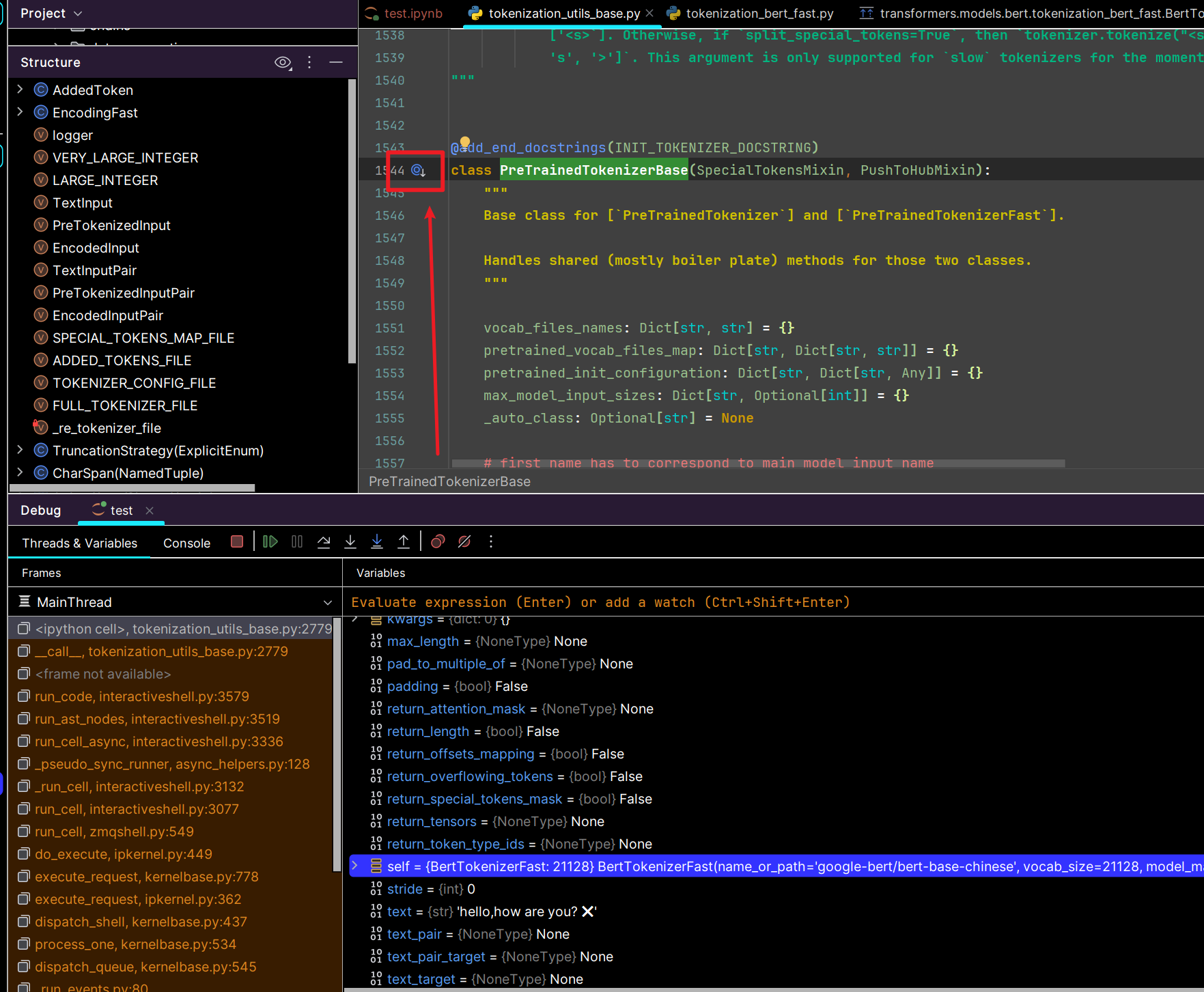
可以看到很多子类分词器,都是继承于他
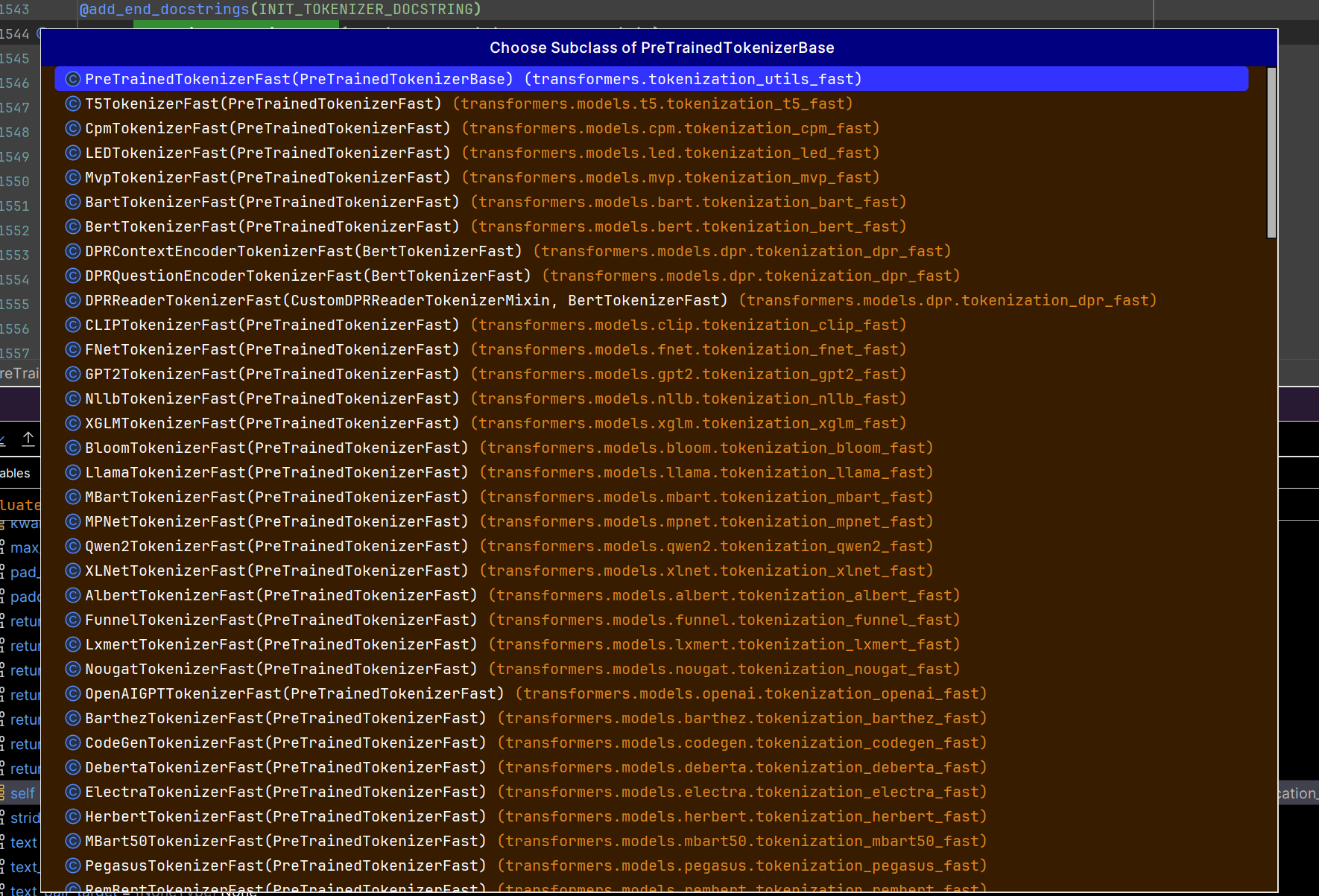

官方源码文档
https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/tokenization_utils_base.py#L1544
transformer文档
https://hf-mirror.com/docs/transformers/v4.37.2/zh/internal/tokenization_utils#transformers.PreTrainedTokenizerBase.call
1.核心参数详解
基本文本输入
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
text |
str/list[str] | None | 要分词的文本(单条或多条) |
text_pair |
str/list[str] | None | 用于句子对任务(如NLI)的第二个句子 |
is_split_into_words |
bool | False | 输入是否已预处理为单词列表 |
特殊标记控制
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
add_special_tokens |
bool | True | 是否添加模型特定的特殊标记([CLS]/[SEP]等) |
return_special_tokens_mask |
bool | False | 是否返回标记特殊token位置的掩码 |
长度控制
| 参数名 | 类型 | 默认值 | 说明 | 推荐值 |
|---|---|---|---|---|
padding |
bool/str | False | 填充策略:True/‘longest’(批内最长),‘max_length’(指定长度) | ‘max_length’ |
truncation |
bool/str | False | 截断策略:True(使用max_length),‘longest_first’(优先截较长句) | True |
max_length |
int | None | 最大长度(截断/填充依据) | 512 |
stride |
int | 0 | 当截断返回所有片段时,连续片段间的重叠token数 | 128(长文档处理) |
pad_to_multiple_of |
int | None | 填充至该数的倍数(优化GPU计算) | 8(GPU高效) |
返回值控制
| 参数名 | 类型 | 默认值 | 说明 | 常用场景 |
|---|---|---|---|---|
return_tensors |
str | None | 返回张量格式:‘pt’(PyTorch), ‘tf’(TensorFlow), ‘np’(NumPy) | ‘pt’ |
return_token_type_ids |
bool | None | 是否返回token_type_ids(句子A/B标识) | BERT类模型设为True |
return_attention_mask |
bool | None | 是否返回attention_mask(实词/填充区分) | 使用填充时设为True |
return_overflowing_tokens |
bool | False | 是否返回所有截断片段(用于处理长文档) | 处理长文本 |
return_offsets_mapping |
bool | False | 是否返回每个token在原始文本中的位置(起始和结束索引) | NER任务 |
return_length |
bool | False | 是否返回每个序列的长度 | 调试 |
2. 完整参数使用示例
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
# 处理句子对(如问答)
inputs = tokenizer(
text="Where is Paris located?", # 问题
text_pair="Paris is the capital of France.", # 上下文
add_special_tokens=True, # 添加[CLS]和[SEP]
padding="max_length", # 填充至最大长度
truncation="longest_first", # 优先截断较长序列
max_length=512, # 最大长度限制
return_tensors="pt", # 返回PyTorch张量
return_token_type_ids=True, # 返回句子类型ID
return_attention_mask=True # 返回注意力掩码
)
print("input_ids:", inputs["input_ids"].shape)
print("token_type_ids:", inputs["token_type_ids"][0, :20].tolist())
print("attention_mask:", inputs["attention_mask"][0, :20].tolist())
3.2.4 特殊标签进一步理解
我们现在这节着重讲一下,这些特殊标记,的意义,更使用场景
-
利用
tokenizer.tokenize分词,以及token编码,可以看到出现[UNK]from transformers import AutoTokenizer # 加载预训练的分词器 tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-chinese") input_text = "hello,how are you? ❌" print(tokenizer.tokenize(input_text)) print(tokenizer(input_text)['input_ids']) ['hello', ',', 'how', 'are', 'you', '?', '[UNK]'] [101, 8701, 117, 9510, 8995, 8357, 136, 100, 102]如果大量的出现的 未知标记,对于模型理解来说是一个灾难,不明白输入,无法反馈输出
- 大量未知不影响用户语义,可以清洗掉
- 也可以创建特定标标签
我们用一个实际的场景来比喻:
想象你开了一家"洗车店"
-
原始车辆进店(原始文本输入)
input_text = "联系客服:support@company.com 了解详情 ❌"这辆"数据车"脏兮兮的:
- 车身沾满泥点(特殊符号
❌) - 车窗贴着联系电话的便签(邮箱
support@company.com) - 后备箱贴着公司网址贴纸(但我们还看不到网址)
- 车身沾满泥点(特殊符号
-
预清洗工位(Clean)
def clean_text(text): text = text.replace("❌", "") # 洗掉车身泥点 text = re.sub(r"\S+@\S+", "[EMAIL]", text) # 用统一贴纸覆盖联系方式 return text.strip() cleaned_text = "联系客服:[EMAIL] 了解详情"现在车辆焕然一新:
- 车身干净无泥点
- 联系方式被统一标识覆盖
- 保持核心信息完整(联系客服了解详情) -
贴标工位(Tokenizer)
from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-chinese") tokens = tokenizer(cleaned_text) print(tokens)洗车店为车辆贴上统一标识贴纸:
- 101: 🚗 洗车店入场贴纸 (CLS)
- 1234: “联系”
- 5678: “客服”
- 9999: [EMAIL] 特殊贴纸
- 2345: “了解详情”
- 102: 🛣️ 洗车店出场贴纸 (SEP)
-
转运至工厂(模型处理)
model_input = { 'input_ids': [101, 1234, 5678, 9999, 2345, 102], 'attention_mask': [1,1,1,1,1,1] }洗干净的车辆被送至不同工厂:
- 客服机器人工厂:看到 [EMAIL] 标识,会换成真实的客服邮箱
- 数据分析工厂:保留 [EMAIL] 标识,用于统计客服咨询数量
- 审计部门:看到统一标识知道这里有私人信息,加强安全措施
3.2.4 常用功能总结
1. 基础分词 (tokenize)
input_text = "hello,how are you? ❌"
cleaned_text = input_text.replace("❌", "").strip()
# 基础分词
print("原始文本分词:", tokenizer.tokenize(input_text))
print("清洗后分词:", tokenizer.tokenize(cleaned_text))
输出结果:
原始文本分词: ['hello', ',', 'how', 'are', 'you', '?', '[UNK]']
清洗后分词: ['hello', ',', 'how', 'are', 'you', '?']
功能说明:
- 基础文字拆分:将文本拆分为最小语义单元
- 特殊符号处理:
[UNK]标记表示不可识别内容 - 使用场景:快速查看分词效果,无需生成模型输入
2. 完整分词处理 (__call__)
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-chinese")
input_text = "hello,how are you? ❌"
cleaned_text = input_text.replace("❌", "").strip()
inputs = tokenizer(
cleaned_text,
padding="max_length", # 自动填充到设置的max_length为10的长度
truncation=True, # 自动截断
max_length=10, # 最大长度
return_tensors="pt" # 返回PyTorch张量
)
pprint(inputs)
输出结构: 可以看到attention_mask 最后出现0为,为填充的内容
{
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0]]),
'input_ids': tensor([[ 101, 8701, 117, 9510, 8995, 8357, 136, 102, 0, 0]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
}
功能特点:
- 自动化处理:一键完成分词、填充、特殊标记添加等
- 框架支持:通过
return_tensors指定TensorFlow/PyTorch格式 - 批处理优化:支持多文本同时处理
在这里重点讲一下
3. 编码与解码
文本 → ID (encode)
# 单条文本编码
input_ids = tokenizer.encode(cleaned_text)
print(f"编码结果: {input_ids}")
# 批量编码(性能提升10倍)
texts = [cleaned_text, "你好世界", "NLP很有趣"]
batch_ids = tokenizer.batch_encode_plus(
texts,
padding=True,
return_tensors="pt"
)
print("批量编码:", batch_ids)
输出结果
编码结果: [101, 8701, 117, 9510, 8995, 8357, 136, 102]
批量编码: {'input_ids': tensor([[ 101, 8701, 117, 9510, 8995, 8357, 136, 102],
[ 101, 872, 1962, 686, 4518, 102, 0, 0],
[ 101, 100, 2523, 3300, 6637, 102, 0, 0]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 0, 0]])}
ID → 文本 (decode)
# 基本解码
decoded_text = tokenizer.decode(input_ids)
print("解码结果:", decoded_text)
# 去特殊标记解码
clean_decoded = tokenizer.decode(input_ids, skip_special_tokens=True)
print("干净解码:", clean_decoded)
# 保留特殊标记
full_decoded = tokenizer.decode(input_ids, skip_special_tokens=False)
print("完整解码:", full_decoded)
输出结果
解码结果: [CLS] hello, how are you? [SEP]
干净解码: hello, how are you?
完整解码: [CLS] hello, how are you? [SEP]
4. 词汇表操作
词汇表查询
# 查看词汇量
print(f"词汇表大小: {len(tokenizer)}")
# 查看特定token信息
print("hello的ID:", tokenizer.convert_tokens_to_ids("hello"))
print("ID 102对应的token:", tokenizer.convert_ids_to_tokens(102))
# 特殊标记信息
print(f"[CLS]标记: {tokenizer.cls_token} (ID: {tokenizer.cls_token_id})")
输出结果
词汇表大小: 21128
hello的ID: 8701
ID 102对应的token: [SEP]
[CLS]标记: [CLS] (ID: 101)
扩展词汇表
# 添加新词汇
new_tokens = ["稳扎稳打", "C++", "❌", "transformers"]
num_added = tokenizer.add_tokens(new_tokens)
print(f"添加了{num_added}个新词汇")
# 验证添加效果
for token in new_tokens:
print(f"{token}的ID:", tokenizer.convert_tokens_to_ids(token))
# 获取所有特殊标记
print("特殊标记映射:", tokenizer.special_tokens_map)
咱可以看看效果
# 查看编码后的
tokens = tokenizer("hello,how are you? ❌")
pprint(tokens)
# 查看分词后的
res = tokenizer.tokenize("hello,how are you? ❌")
pprint(res)
# 查看ID解码
print(tokenizer.decode(tokens["input_ids"]))
输出,可以看到没有 [UNK] 未知标签
{'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1],
'input_ids': [101, 8701, 117, 9510, 8995, 8357, 136, 21130, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0]}
['hello', ',', 'how', 'are', 'you', '?', '❌']
[CLS] hello, how are you? ❌ [SEP]
扩展词汇表场景:
- 领域专业术语(医疗、法律等)
- 新出现词汇(网络用语、新兴技术)
- 特殊符号(表情、公式符号)
五、相关阅读

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)