OneRec: Unifying Retrieve and Rank with Generative Recommender and Preference Alignment
一个session指的是一次用户请求返回的一个batch的视频,通常是5个到10个,一个session内的视频通常会考虑到用户兴趣、连贯性和多样性等多种因素。我们将RQ-VAE的方法改进为使用一个多层的平衡的量化机制,用残差K-means量化算法来进行embedding的转换。然而过往的推荐系统采用召回-粗排-精排的级联结构,导致某一级的上限受到前面一级的限制。,然后为生成的每个session计算
原文地址:OneRec Technical Report
LLM4Rec的整合之作,虽然在一些细节的实现和评估上有可以质疑的点。相比传统推荐的改动主要有以下几点:
- MLLM多模态item表示 + embedding量化
- 超长历史行为序列的应用:聚类+相似检索
- 模型结构:encoder建模用户兴趣 + decoder自回归生成session维度的推荐序列
- 训练数据:优质session的选择
- 后训练:GRPO,多目标奖励模型的构建
由于这篇工作投稿的paper和技术报告两模两样的(强化学习那边用的算法都不一样),以下以技术报告为主
解决的问题
- 级联结构导致计算资源浪费在通信和存取上
- qps(>40w)和延迟(<500ms)要求导致无法应用大规模计算
- 多目标之间存在冲突,且各级之间的目标不统一
- 和主流AI架构脱节
方法
不包含item representation的模型架构如下: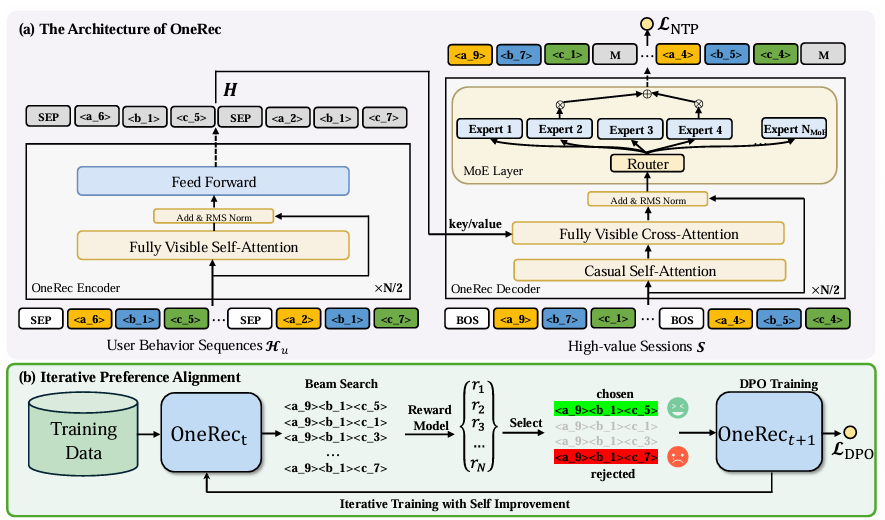
item表示(tokenize)
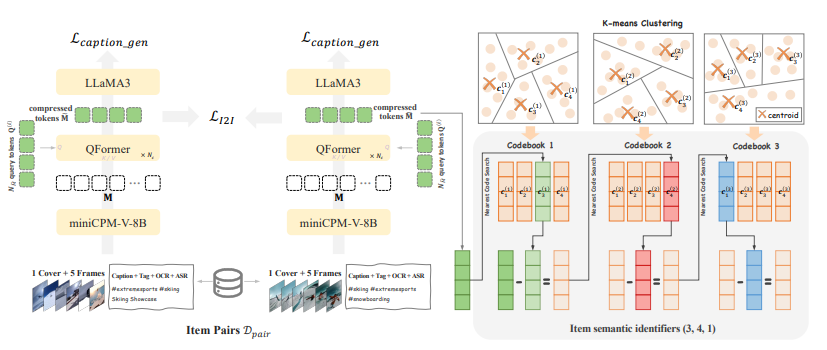
在训练生成式推荐模型之前需要把快手十亿量级的视频中的每个item用一个固定的且量级较小的词表表示出来。为此进行以下步骤:
- 生成item的多模态表示:对每个视频抽取摘要, tag, ASR, OCR, 封面图以及均匀采样的5帧图片,用一个 miniCPM-V-8B 生成一个1280个token向量的表示,然后用QFormer压缩到4个token向量
- 构建item pair: 1) U2I pair,对用户点击过的item,选择用户点击历史中跟它最相似的item组成pair; 2) I2I pair,(swing等)相似分最高的item pair
- 用构建好的item pair训练此模型:训练目标包括 1) item-to-item的对比loss,用于对齐相似item之间的表示;2)用LLaMA3做decoder进行next-token-prediction,为了防止模型产生幻觉
- 用RQ-Kmeans做tokenization(如图右),通过不断对残差进行K-means聚类,以一种粗粒度到细粒度的方式进行embedding量化,为每个item生成语义ID (我理解是每层残差以一个ID替代了之前生成的4个token的item embedding)
RQ-Kmeans的过程如下,采取这种聚类方式的主要目的是为了平衡每个类别的item数:
算法的主要目的是平衡每个cluster的embedding数量。
特征
我们的特征主要分为四类:
- 静态用户特征:作为1个token输入模型,制作方法是把uid年龄性别embedding拼接在一起过2层Dense
- 短期行为特征:用户最近交互的20个item,把item embedding, tag, timestamp, 播放时间, 播放时长, 行为标签拼接起来过2层Dense,然后组成一个长度20的序列
- 正反馈特征:长度为256的正反馈item序列
- 用户生命周期行为特征:一个记录用户整个生命周期行为的超长序列,用一个两阶段的层级压缩方法加入模型特征
对超长序列的压缩做法:
- 对每个用户,将它们的lifelong序列用前面生成的item representation进行层级聚类,簇的数量限制在用户历史长度的三次方根
- 对序列中的每个item,它们的id类特征替换成离它所属的簇的中心最近的一个item特征,数值类特征替换成整个簇item数值的均值
- 每个item的特征拼接起来过2层Dense
- 对于这个超长的序列,用QFormer把它压缩成一个长度为128的短序列
模型结构
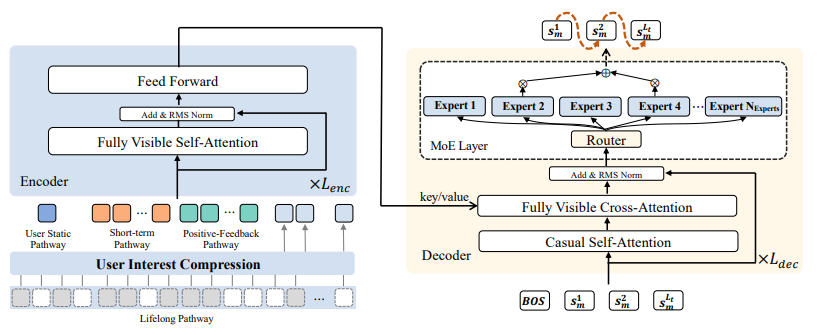
不同于其他很多LLM4Rec方法,本文的模型架构由一个encoder和一个decoder共同组成。encoder的输入为: z ( 1 ) = [ h u ; h s ; h p ; h l ] + e p o s z^{(1)} = [h_u;h_s;h_p;h_l] + e_{pos} z(1)=[hu;hs;hp;hl]+epos 每层transformer内的结构: z ( i + 1 ) = z ( i ) + S e l f A t t n ( R M S N o r m ( z ( i ) ) ) z^{(i+1)} = z^{(i)} + SelfAttn(RMSNorm(z^{(i)})) z(i+1)=z(i)+SelfAttn(RMSNorm(z(i))) z ( i + 1 ) = z ( i + 1 ) + F F N ( R M S N o r m ( z ( i + 1 ) ) ) z^{(i+1)} = z^{(i+1)} + FFN(RMSNorm(z^{(i+1)})) z(i+1)=z(i+1)+FFN(RMSNorm(z(i+1)))
decoder的输入从一个代表序列开始的可学习的token开始: S m = { s [ B O S ] , s m 1 , s m 2 , . . . , s m L t } S_m = \{s_{[BOS]}, s_m^1, s_m^2, ..., s_m^{L_t}\} Sm={s[BOS],sm1,sm2,...,smLt} d m ( 0 ) = E m b _ l o o k u p ( S m ) d_m^{(0)} = Emb\_lookup(S_m) dm(0)=Emb_lookup(Sm) 每层decoder的结构: d m ( i + 1 ) = d m ( i ) + C a u s a l S e l f A t t n ( d m ( i ) ) d_m^{(i+1)} = d_m^{(i)} + CausalSelfAttn(d_m^{(i)}) dm(i+1)=dm(i)+CausalSelfAttn(dm(i)) d m ( i + 1 ) = d m ( i + 1 ) + C r o s s A t t n ( d m ( i + 1 ) , Z e n c , Z e n c ) d_m^{(i+1)} = d_m^{(i+1)} + CrossAttn(d_m^{(i+1)}, Z_{enc}, Z_{enc}) dm(i+1)=dm(i+1)+CrossAttn(dm(i+1),Zenc,Zenc) d m ( i + 1 ) = d m ( i + 1 ) + M o E ( R M S N o r m ( d m ( i + 1 ) ) ) d_m^{(i+1)} = d_m^{(i+1)} + MoE(RMSNorm(d_m^{(i+1)})) dm(i+1)=dm(i+1)+MoE(RMSNorm(dm(i+1))) 在预训练阶段,模型用session层级的next-token prediction进行训练,使用交叉熵loss。
样本
相比于传统推荐方法里point-wise的推荐,我们使用session-wise生成的方式来进行视频推荐。一个session指的是一次用户请求返回的一个batch的视频,通常是5个到10个,一个session内的视频通常会考虑到用户兴趣、连贯性和多样性等多种因素。因此session-wise的输出和样本能够使模型习得视频之间的依赖。我们设置了一些规则来定义高质量session,包括:
- 用户在session内实际观看的视频数量大于等于5个
- 用户观看这一session内视频的总时长超过某个阈值
- 用户对这一session内的视频有显式的交互行为,例如点赞收藏或分享
在经过亿些轮次的训练之后我们得到了seed模型 M t M_t Mt
奖励模型
目前我们已经利用高质量session训练出了一个基础模型,保证了生成session的质量。在此基础上我们希望用GRPO算法进一步提升模型能力。在传统NLP领域,偏好数据很容易通过打标获得。然而在推荐领域由于user-item交互的稀疏性,我们需要一个奖励模型来进行打分。
奖励模型
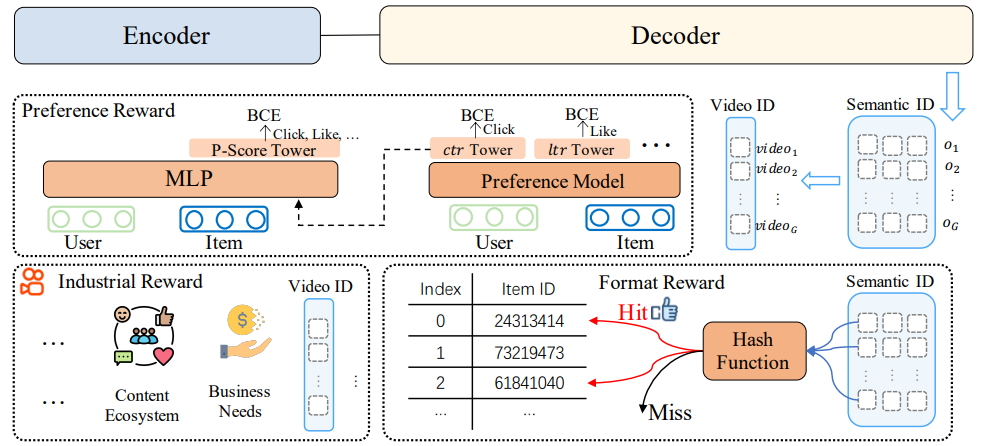
奖励模型的输入是用户representation和单个item的representation,模型主体部分是一个SIM模型,为了同时建模多个目标SIM的上层接了多个目标的塔,训练过程中这些塔的输出分别与各个目标求BCE loss作为奖励模型的辅助loss。模型的最终输出是一个综合得分P-Score,这个得分是将各个塔的隐藏层、user feature和item feature拼接起来过一个MLP得到的,模型最终的loss是用这一个分数与各个目标进行计算然后加权求和: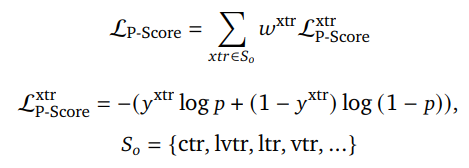
Early Clipped GRPO
我们的GRPO优化目标为: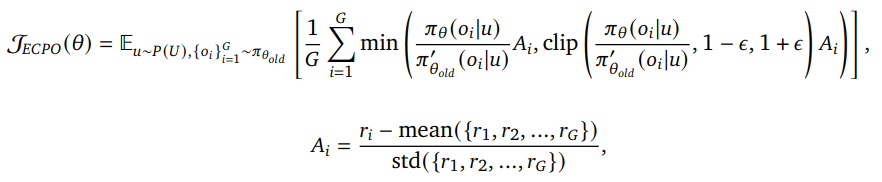
其中G为主体模型为一个用户一次性生成的item数, r i r_i ri表示第i个item过奖励模型输出的P-Score。
为防止梯度爆炸,对于负的奖励我们进行了loss的截断。
生成格式规范
为了规范模型生成的item,避免生成token无法组合成合法item ID,我们另外加了一个强化学习训练。在为每个用户生成G个item的时候从中采样出K个样本判断它们是否能组成合法ID,奖励如下: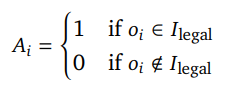
工业场景对齐
在实际推荐场景中不仅要考虑用户偏好,也要考虑到社区生态、商业化、冷启和长尾内容保量等等方面。过往方法中通常通过各种策略完成这些要求,我们只需要在奖励系统中加入这些因素,对强化学习的优化目标进行改造即可。例如如果生成的item是有害的我们会按比例降低reward: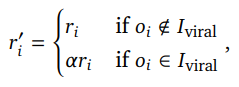
训练Infra
硬件配置:90台服务器,每台8旗舰GPU+2CPU
训练加速:
- embedding加速:自研的SKAI framework,提供GPU unified embedding table,embedding缓存和prefetch pipe
- 并行训练:数据并行、ZERO1 (Zero: Memory optimizations toward training trillion parameter models. )和梯度加速
- 多精度计算:MLP层使用BFloat16精度,目的是提升性能
- attention的编译优化
这些优化共提升模型训练MFU ? -> 23.7%
样本量:OneRec-0.935B在大约1000亿样本后拟合,每个target item被拆成3个semantic token
关键参数:
后训练
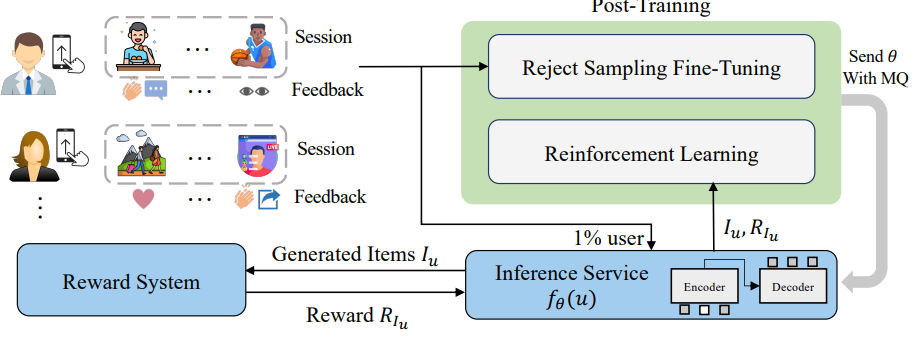
后训练分成RSFT (Reject Sampling Fine-Tuning) 和 RL两步:
- RSFT: 按播放时长对所有用户session排序,过滤掉后50%再做一轮NTP训练
- RL: 从RSFT数据集中采样1%的数据,每个用户生成512个item,利用这512个样本过奖励模型进行训练,每1000步后将更新后的参数用一个MQ传给推理模型进行更新。
评估
评估指标
- NTP阶段的交叉熵
- P-Score
- XTR

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)