从训练到部署:基于 Qwen2.5 和 LoRA 的轻量化中文问答系统全流程实战
《基于LoRA技术的轻量级中文问答系统构建方案》介绍了一套完整的轻量级大语言模型解决方案。采用阿里云Qwen2.5系列模型结合LoRA微调技术,实现了从多GPU分布式训练到Web部署的全流程。方案包含三大核心模块:分布式训练脚本、LoRA模型合并工具,以及基于Gradio的Web交互界面。通过LoRA技术显著降低训练成本,合并后的模型简化了部署流程,Gradio界面支持流式响应和多轮对话。该方案具
近年来,大语言模型(LLM)迅速发展,但其训练与部署的高成本仍是门槛。为了解决这一问题,我们采用阿里云开源的 Qwen2.5 系列模型,结合 LoRA(Low-Rank Adaptation)技术 实现了一套从训练、模型合并到 Web 部署的完整流程,适用于轻量中文问答系统的构建。
本文将详细介绍整个过程,包括分布式训练、LoRA 微调模型合并,以及使用 Gradio 搭建 Web 界面部署模型。
🧠 项目结构概览
-
train_distributed.py: 多 GPU 分布式训练脚本(LoRA 微调) -
merge_model.py: 合并微调后的 LoRA adapter 与基座模型 -
gradio_app.py: Web 聊天机器人界面,支持多轮对话与流式响应
🎓 一、使用 LoRA 进行多 GPU 分布式训练
我们首先采用 torchrun 启动多卡训练,利用 Hugging Face 的 transformers 框架与 peft 实现 LoRA 微调。
✅ 自动获取 GPU 数量
NUM_GPUS=$(nvidia-smi --query-gpu=gpu_name --format=csv,noheader | wc -l)
✅ 启动训练命令
torchrun --nproc_per_node=$NUM_GPUS --nnodes=1 --node_rank=0 train_distributed.py \
--model_path "./Qwen/Qwen2.5-1.5B-Instruct" \
--json_file_path "./data/medicalQA_top1k.json" \
--output_dir "./output_20250604" \
--batch_size 2 \
--train_epochs 10 \
--fp16 True \
--gradient_accumulation_steps 8 \
--learning_rate 5e-5 \
--lora_alpha 16 \
--lora_dropout 0.05 \
--rank 8
✅ 参数说明
| 参数 | 含义 |
|---|---|
--model_path |
使用的 Qwen2.5 模型 |
--json_file_path |
医学问答 JSON 数据路径 |
--output_dir |
LoRA adapter 输出目录 |
--fp16 |
启用混合精度训练 |
--rank、lora_alpha 等 |
LoRA 超参数配置 |
训练完成后,LoRA adapter 将保存在 output_dir 中的指定路径下。
🔗 二、合并 LoRA adapter 与基座模型
为了部署时简化依赖,我们将训练得到的 adapter 合并回基座模型中,得到完整权重。
✅ merge_model.py 核心流程
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
# 加载基座模型
base_model = AutoModelForCausalLM.from_pretrained("/path/to/Qwen2.5-0.5B-Instruct")
# 加载微调后的 adapter
adapter = PeftModel.from_pretrained(base_model, "output_xxx/final_model/")
# 保存融合模型和 tokenizer
adapter.save_pretrained("merge_model/xxx")
tokenizer = AutoTokenizer.from_pretrained(base_model_path)
tokenizer.save_pretrained("merge_model/xxx")
如需彻底合并 LoRA 参数(适配部分 peft 版本),可以使用 merge_and_unload(adapter)。
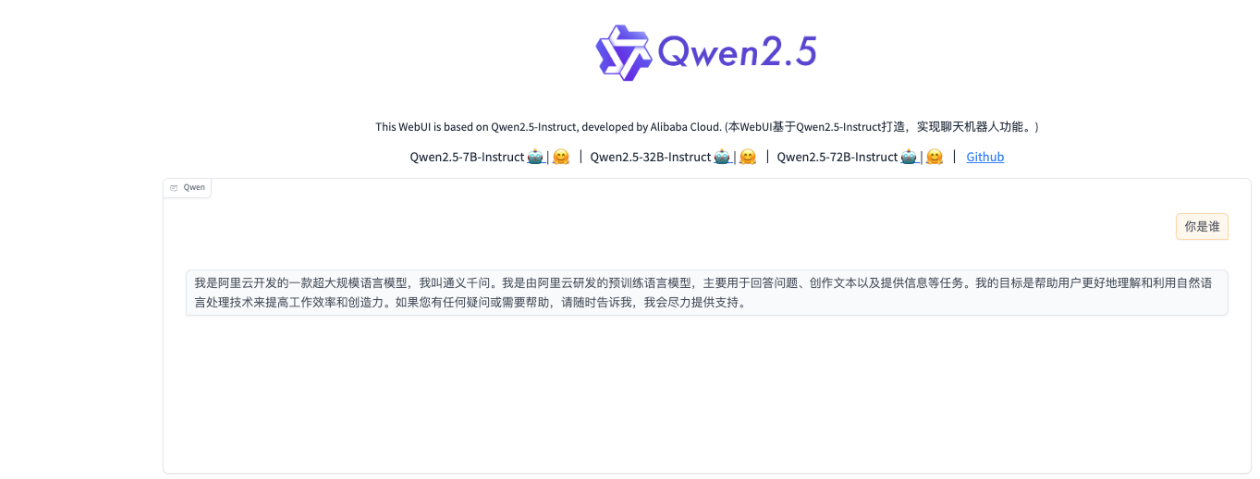
🌐 三、构建基于 Gradio 的 Web 聊天机器人
训练好的模型需要一个交互界面,我们使用 Gradio 快速搭建 Web UI,实现中文问答与对话功能。
✅ 核心功能
-
加载融合后的模型和 tokenizer
-
使用
TextIteratorStreamer实现 响应式流式输出 -
保持对话历史上下文,支持多轮交互
-
清空历史、重试、端口设置等功能
✅ 启动方式
python gradio_app.py --checkpoint-path "merge_model/xxx" --server-port 8000
浏览器访问 http://localhost:8000 即可开始使用问答机器人。
代码获取:https://pan.quark.cn/s/570693419ae5
✅ 总结与亮点
-
🎯 轻量训练:通过 LoRA 技术,仅训练少量参数,适用于个人与中小企业场景
-
⚡ 高效部署:合并模型后,推理无需额外依赖 adapter
-
💬 交互便捷:Gradio 构建用户友好界面,部署无需额外 Web 框架
-
📈 模块化结构:训练、合并、部署解耦,适合迭代开发和复用

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)