Houdini Learning Record
Houdini飞龙喷火免费教程Dragon Fire Breath_哔哩哔哩_bilibili

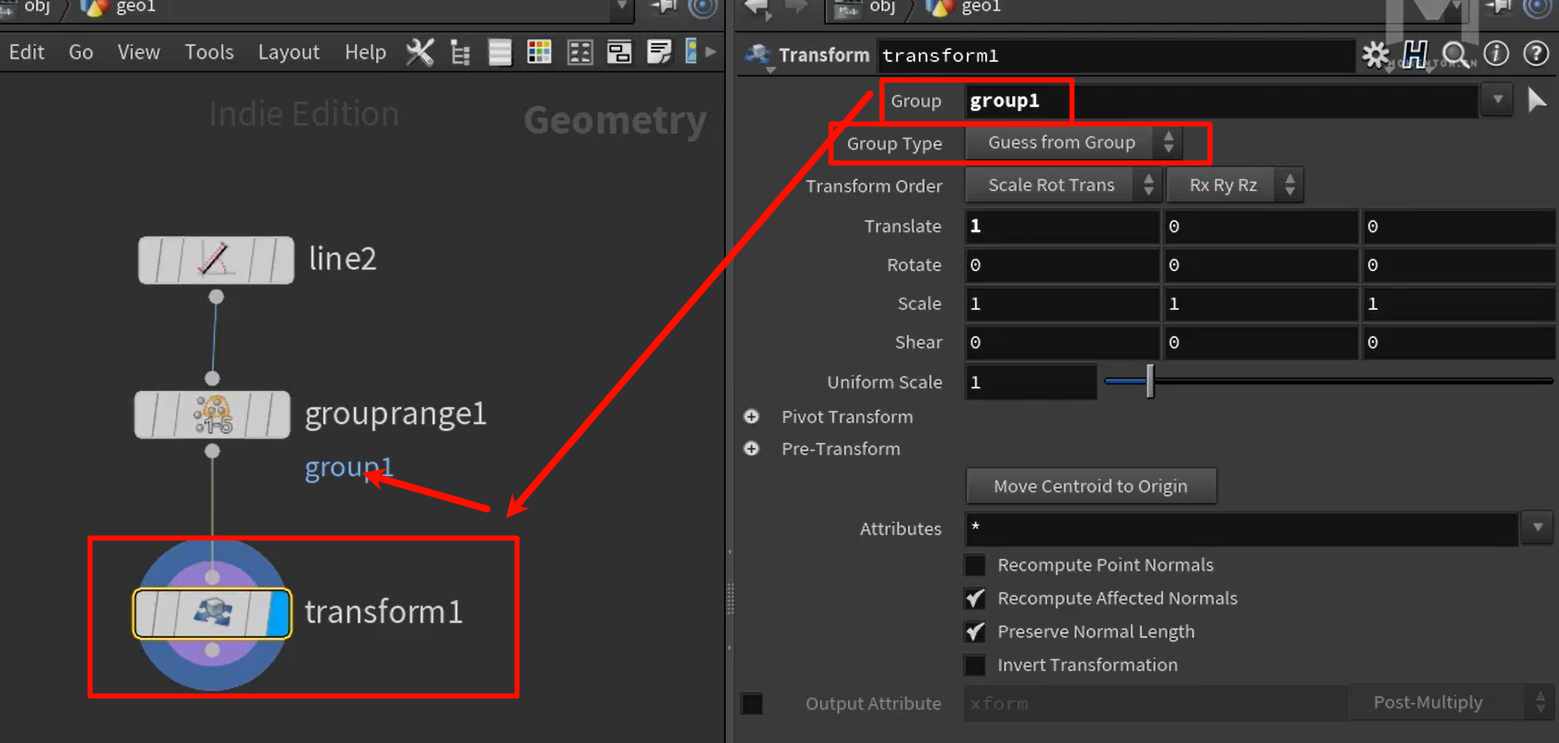
导入hip文件之后,显示
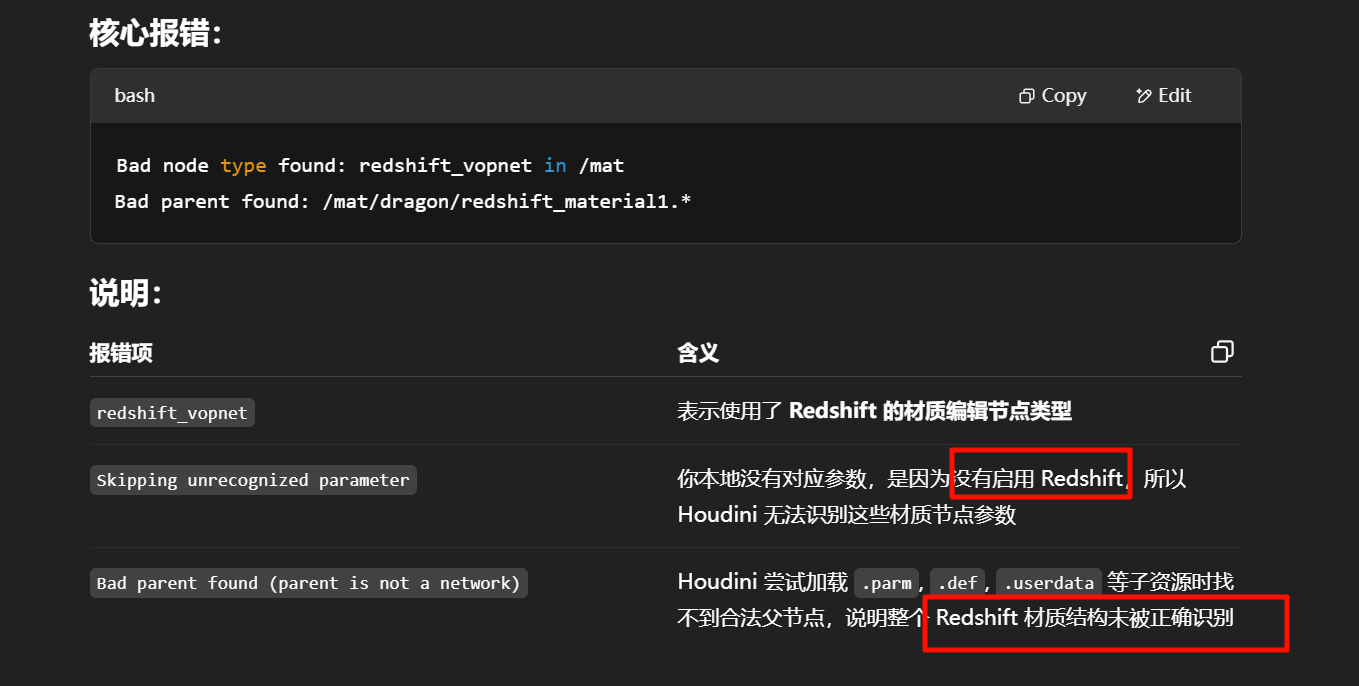
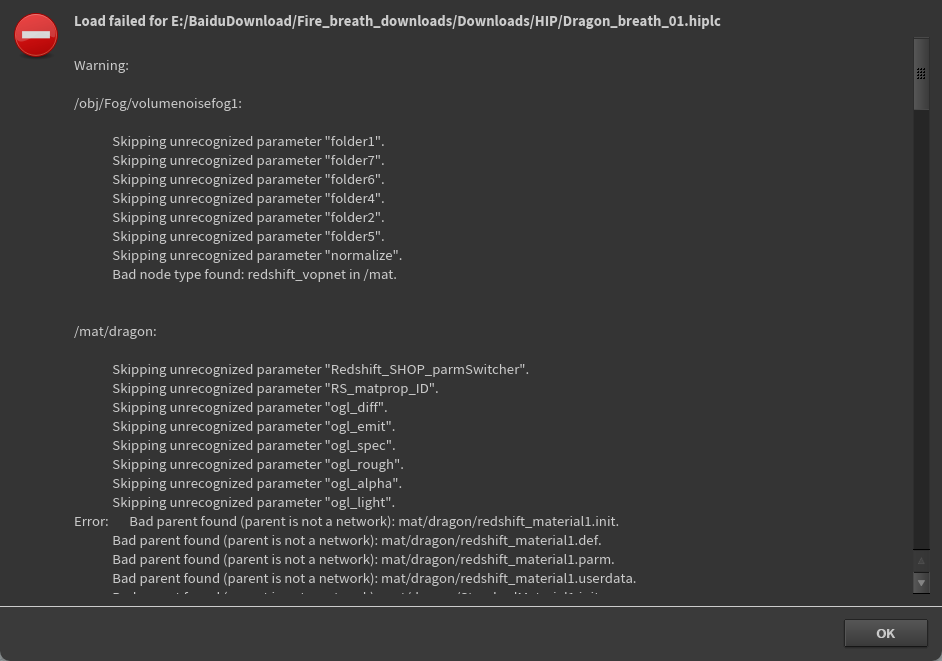
Redshift 是一个高性能的、基于 GPU 的偏差渲染器(biased renderer),被广泛用于电影、动画、游戏和建筑可视化等领域,特别是在 Houdini、Maya、Cinema 4D、3ds Max 等软件中都有插件支持。
它由 Redshift Rendering Technologies 开发,后被 Maxon(Cinema 4D 的母公司)收购。
xxxxxxxxx否
模型文件本身是支持动画的格式,比如 .fbx、.abc(Alembic)
直接将模型文件(通常是 .fbx)从资源管理器拖拽进 Houdini 的视口或 Network View 里,就会自动创建一个导入节点。
可以通过:
-
使用
Alembic Archive查看.abc内的结构 -
使用
explodedview、geometry spreadsheet查看数据组成 -
追踪材质路径、贴图引用是否断链
这些操作都会带来对这个模型的结构性掌控感。
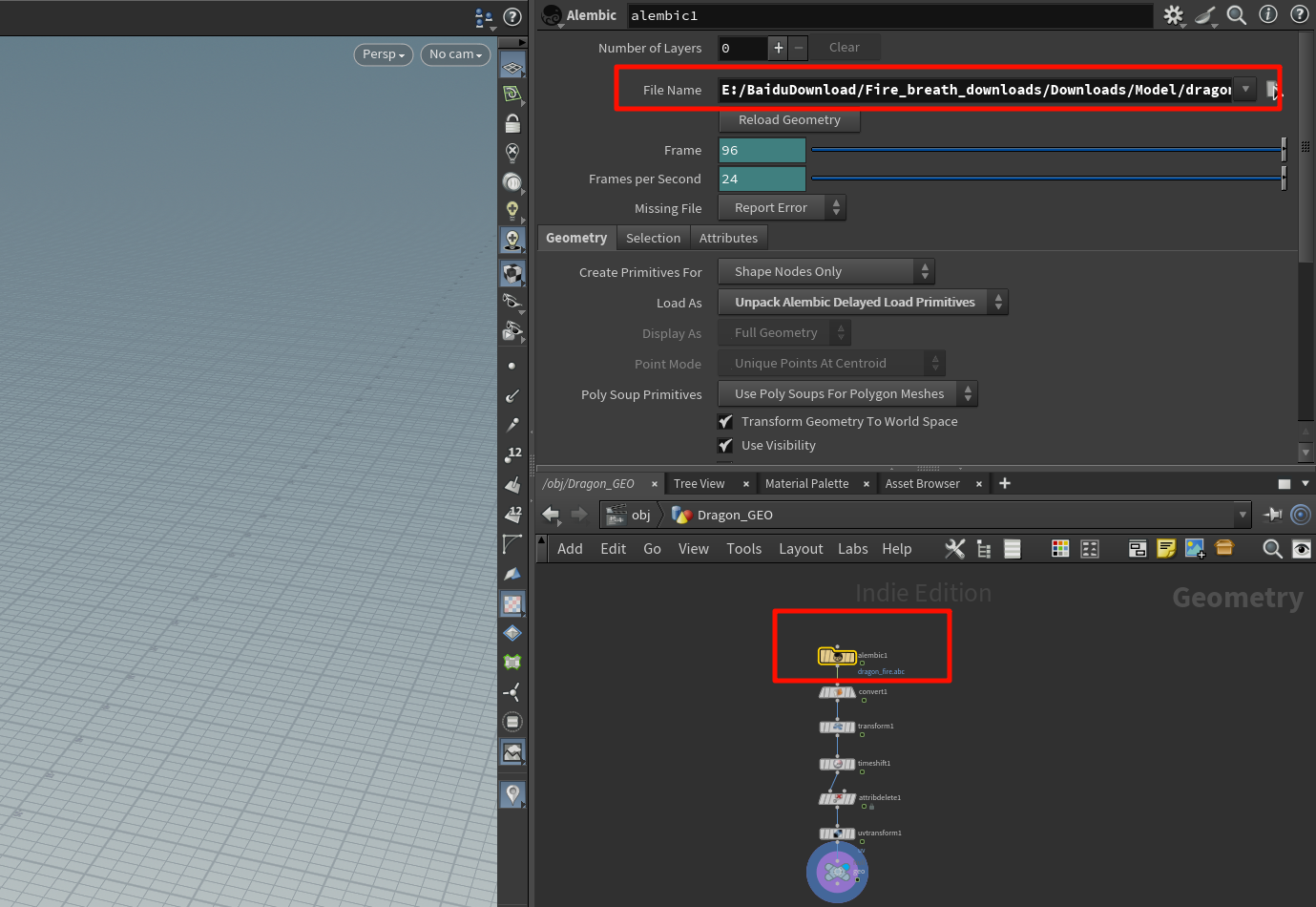
引用设置,修改路径
xxxxxxxxxxxxxxx跳

redshift 和nuke是单独的额外的软件
xxxxxxxxxxxx
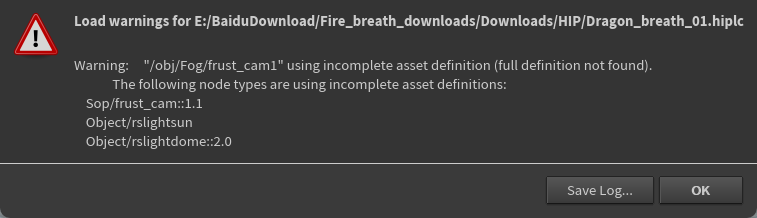
using incomplete asset definition (full definition not found)
表示 Houdini 在打开项目时,某些使用了“数字资产”(HDA)的节点找不到它们完整的定义文件,
项目引用了某些 HDA 资源,但这些资源的源文件 .hda 没有被一并加载或缺失了。
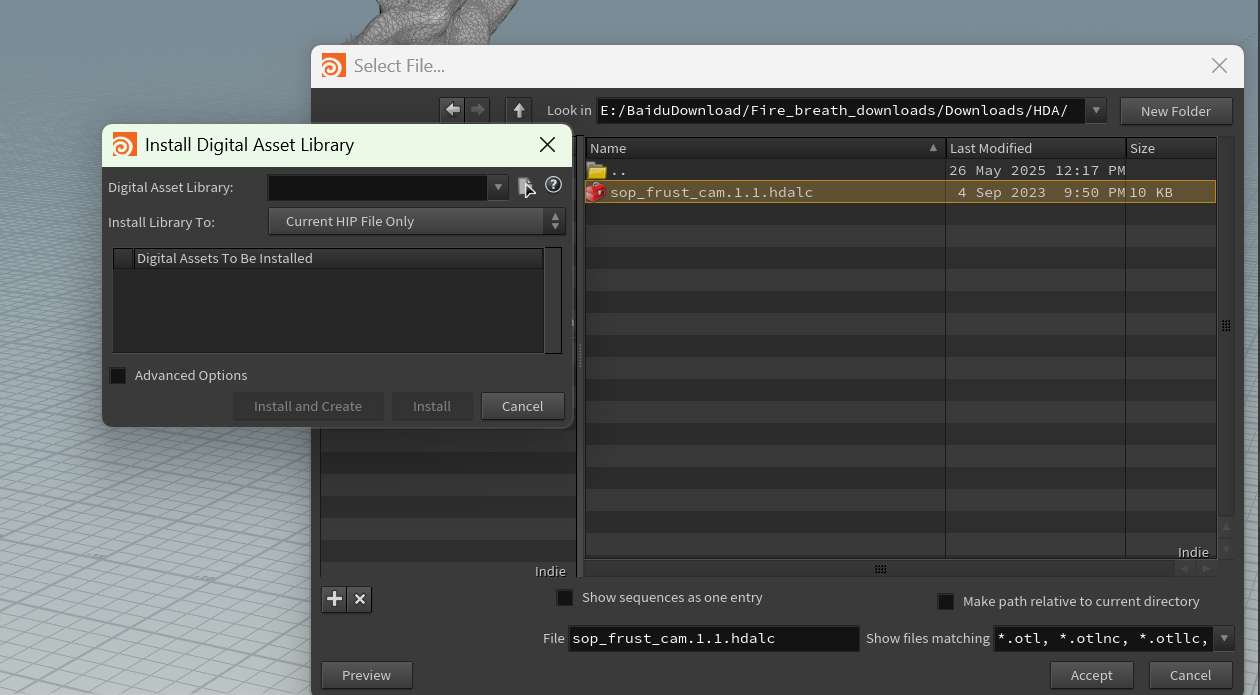
引用hda
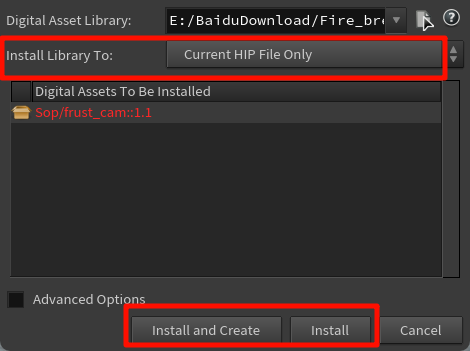
安装这个 .hda 文件之后,它是仅用于当前文件,还是能在以后其他工程中也用
| 按钮 | 含义 |
|---|---|
| Install | 安装这个 HDA 到你刚刚选的路径里,不会在场景里创建节点 |
| Install and Create | 安装并立刻在场景中创建一个节点实例(一般不需要这么做) |
xxxxxxxxxx
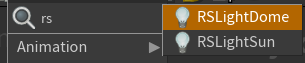

一开始这三个自带的灯泡
是项目原作者手动放进去的 Redshift 专用光源节点,用于模拟自然光照、HDR 环境光等
rslightdome
Redshift Dome Light
这是一个全景光源,通常用于加载 HDRI 环境贴图,模拟户外或特定空间氛围光照。
-
类似 Houdini 中的
Environment Light -
常用于体积渲染(烟雾/火焰)时提供背景和柔光照明
-
有两个实例 →
rslightdome1和rslightdome2,可能分别用于不同时间段或角度测试
rslightsun
Redshift Sun Light
这是一个定向光源(Directional Light),模拟太阳光效果。
-
可以搭配
rslightsky(天空环境)构成物理天空系统 -
通常控制太阳高度、角度、颜色温度
⚠️ 它旁边有黄色小叹号,说明当前你本地未安装 Redshift,所以该节点加载不完全或不工作。

Houdini 中的相机节点(cam1)不只是为了观察,而是为了输出镜头、驱动渲染和特效视角定位,是正式作品的一部分。
在视口中直接切换相机
-
进入 Scene View(主视口)
-
在视口左上角的摄像机菜单(通常写着 “No cam” 或 “Perspective”)点击
-
选择你的相机节点名(如
cam1)
你会发现视口变成了蓝边框,并且视角固定在相机位置(不能自由飞行)。
xxxxxxxxxxxxxxx
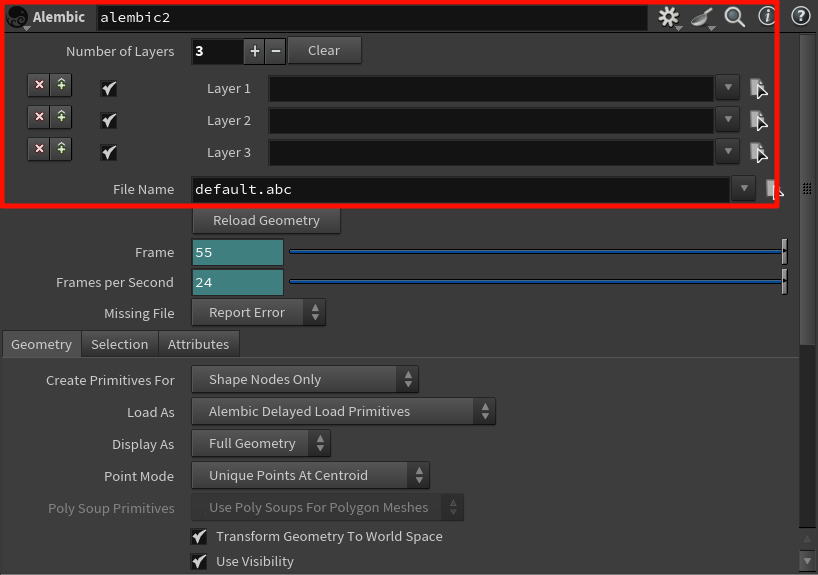
lembic Archive 是专用于读取 .abc 文件的结构入口。
-
它会读取 Alembic 文件中的 Scene Graph Tree(层级结构)
-
显示的是
.abc文件中保存的 节点路径(Object hierarchy) -
和
File节点不同,它是为 Alembic 设计的“浏览式入口”
| 文件格式 | 对应节点 |
|---|---|
.abc |
Alembic Archive |
.usd, .usda, .usdc |
USD Import, Stage, SOP Import(基于 USD 系统) |
.fbx |
没有 FBX Archive,但用 File 或 FBX Character Import |
.obj |
用 File 直接导入 |
模型文件本身(如
.abc,.fbx,.obj)是一个底层的数据容器,用于描述一个 3D 对象在某一格式下的“原始结构”;各个 3D 软件(如 Houdini、Blender、Maya)在导入后,会解析并转化为各自内部的模型数据结构,进行操作;
如果修改后再次导出,会被“重新打包回原格式的结构规则中”。
这个逻辑是完全成立的,而且正是现代 DCC(Digital Content Creation)软件的核心工作机制之一。
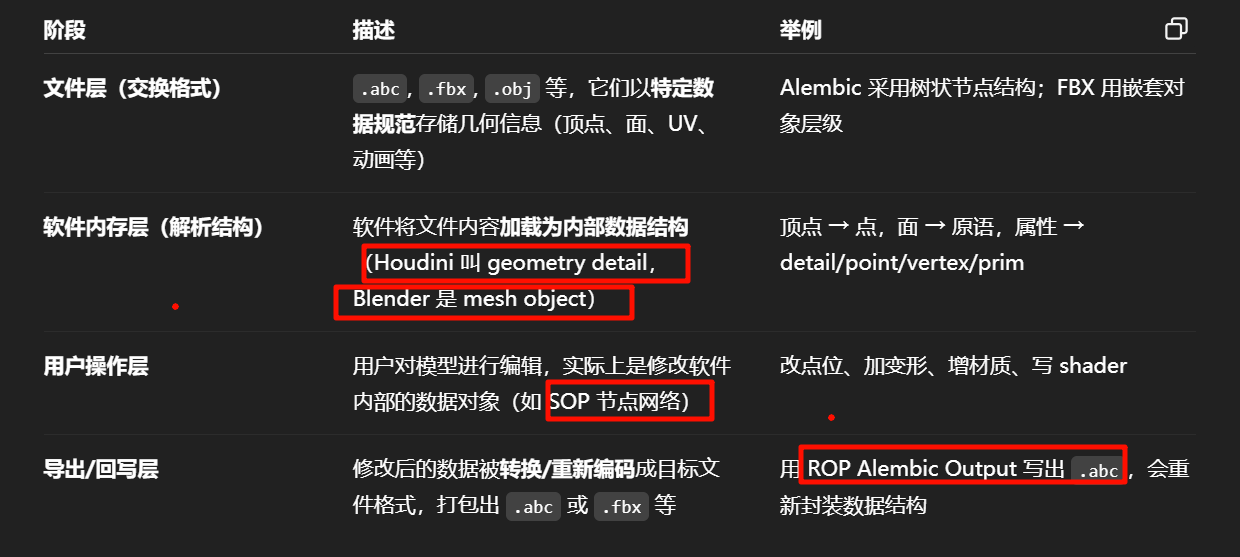
| 当你导出成 | 会发生的事情 |
|---|---|
.obj |
只能保留点、面、UV、法线(动画、材质都丢失) |
.fbx |
保留骨骼动画、材质引用,但可能丢失 procedural 信息 |
.abc |
保留顶点动画、体积结构,但不一定保留节点逻辑 |
导出的“底层格式”,实际上是对你所做内容的某种“近似投影”
这也是为什么在做资产准备时,要清楚:
-
哪些信息能被导出
-
哪些信息只能在 Houdini 保留
-
哪些必须 bake(烘焙)成显式结构再导出
xxxxxxxxxx
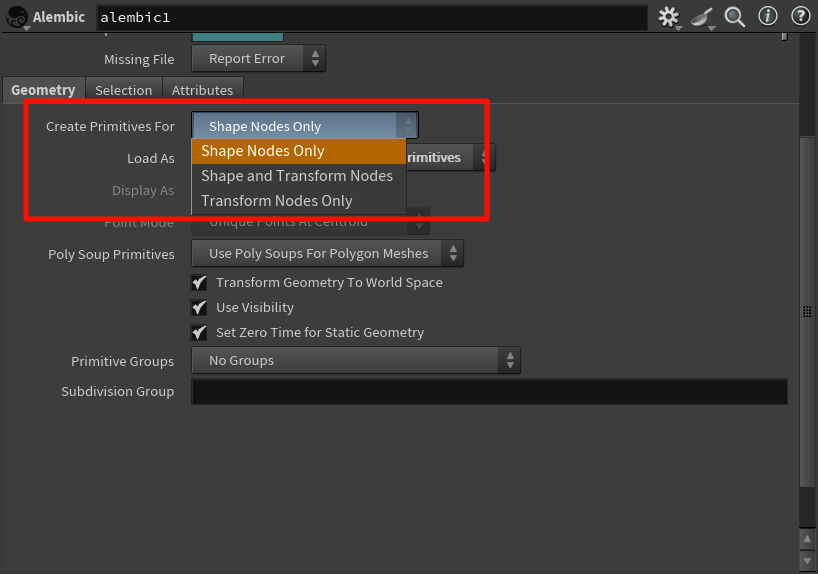
| 选项 | 含义 | 你会得到什么 |
|---|---|---|
| ✅ Shape Nodes Only | 只导入 .abc 文件中真正有几何体的节点(Shape Nodes) |
你能看到 mesh,但没有父子变换层级、空节点结构 |
| ✅ Shape and Transform Nodes | 导入几何体 + 空节点(Transform)结构,比如空组、控制节点等 | 保留原始层级结构,可用于还原动画层次或复杂约束 |
| ✅ Transform Nodes Only | 只导入 .abc 文件中的 Transform 层级(不含网格) |
没有任何 mesh,只留下 transform 结构,常用于驱动参考等 |
你加载 .abc 文件时,Houdini 如何在 SOP 中还原其中的结构信息(几何体 vs. 变换层级)
绝大多数初学和中等复杂项目,使用默认的
Shape Nodes Only即可,它干净、轻量、不会加载多余层级。
但当你需要:
-
对齐参考骨架
-
模拟原始控制结构
-
导出时保留原始层级
时,再切到Shape and Transform Nodes是最合适的。
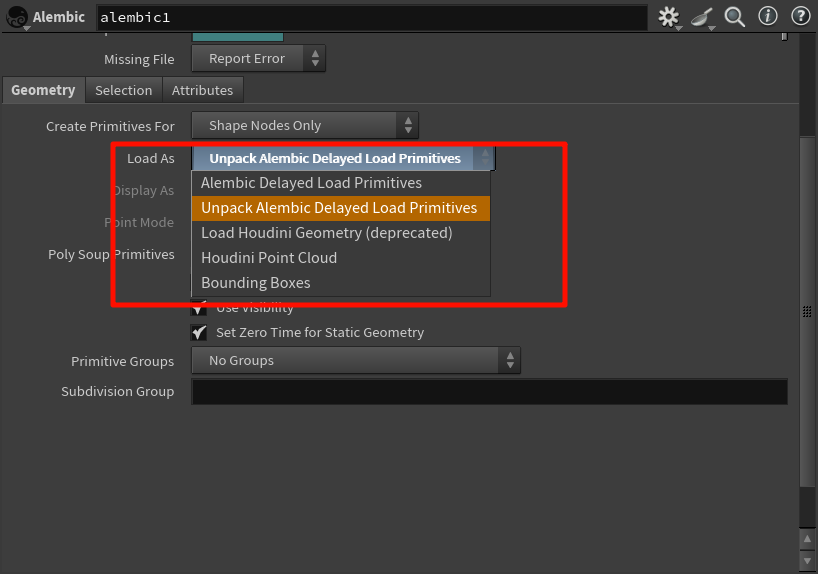
Alembic Delayed Load Primitives
-
表示:以最轻量方式挂载
.abc数据,只在真正渲染/查看时才从磁盘读取 -
优点:
-
非常省内存,尤其适合海量帧或大模型序列
-
打开
.hip文件非常快
-
-
缺点:
-
不能在 SOP 中编辑几何体(是黑盒结构)
-
✅ 适合:只用于渲染/合成时读入
.abc烘焙动画。
Unpack Alembic Delayed Load Primitives
-
表示:将延迟加载的内容真正转换为 Houdini 内部标准几何
-
优点:
-
可以编辑、变形、加材质、导出等
-
更直观地操作
-
-
缺点:
-
内存占用上升,首次加载会变慢
-
✅ 适合:需要操作模型、复制、FX 模拟等情况。
xxxxxxxx
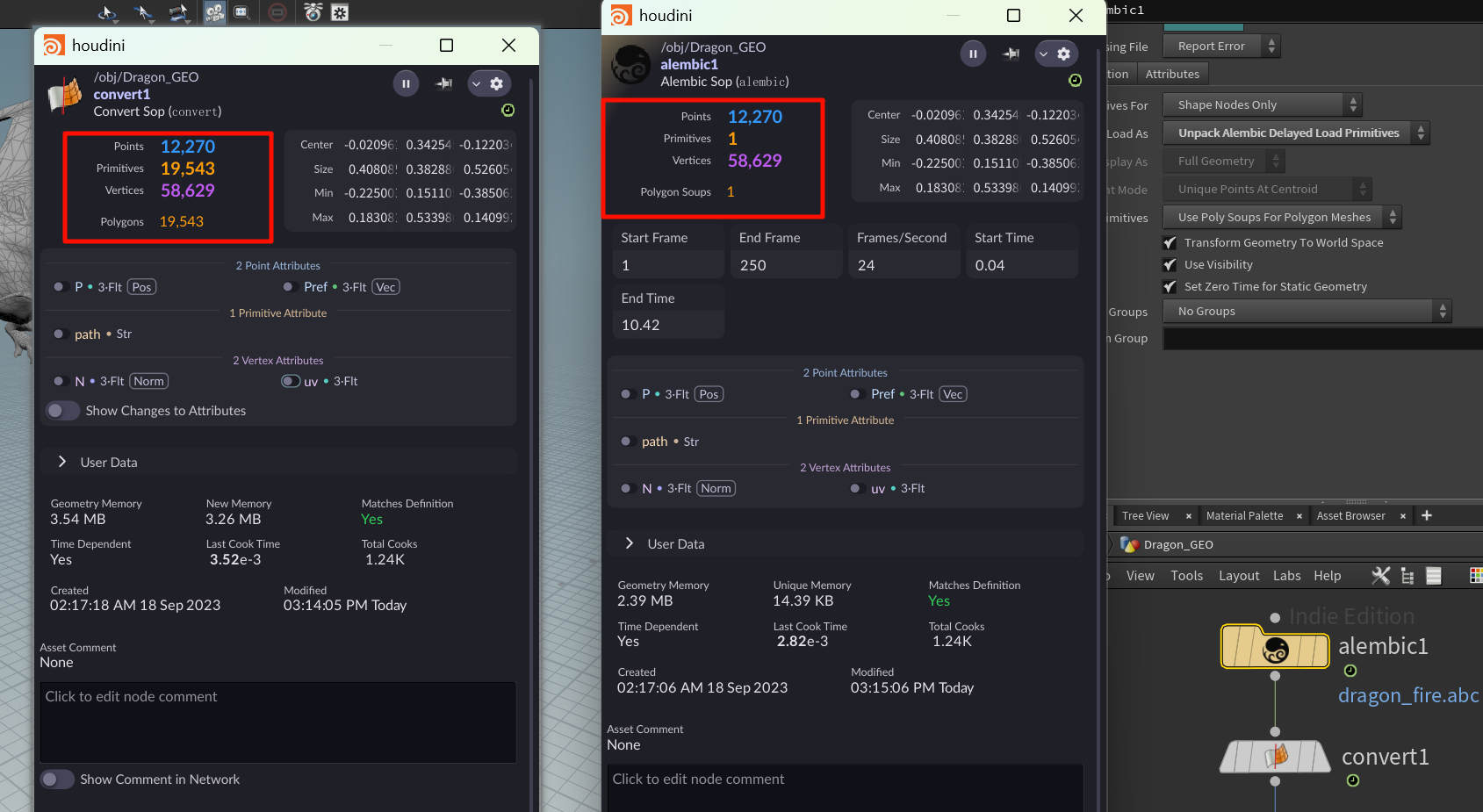
Convert 是一个万能格式转换节点,并不专门为 Alembic 而设计。所以它支持非常广的几何类型,包括:
-
曲线 ↔ 面
-
NURBS ↔ Polygon
-
Volume → Polygon(抽壳)
-
Packed Alembic → Polygon
-
Poly Soup → Polygon
但你只要明白:
👉 对 Alembic 导入数据来说,你最常用的是 Convert packed → Polygon,几乎不涉及其余设置。
“Packed”想表达的核心意思是:“我不关心这个东西里面的所有点和面,我只想把它当一个整体来移动/复制/渲染/打包。”
xxxxxxxxx
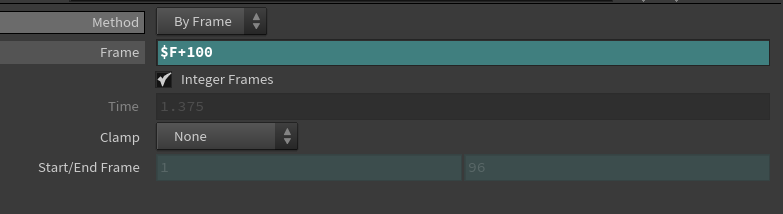
$F + 100,不是改变当前时间线的起点,而是:告诉这个 TimeShift 节点:无论当前时间是多少,都去从第 $F + 100 帧获取输入数据。
也就是说:
-
当前时间
$F= 1 ⇒ 实际采样帧是101 -
当前时间
$F= 10 ⇒ 实际采样帧是110 -
当前时间
$F= 80 ⇒ 实际采样帧是180
❌ 在 Houdini 中,"对象本身" 并没有“独立的时间线”。
✅ 但你可以通过节点控制、参数动画、时间节点(如 TimeShift, TimeWarp)等手段,让每个对象看起来像是“有自己的时间线”。
时间线 是全局的,所有节点都在当前帧 $F 下计算一次
物体反向播放 $FEND - $F
帧不是循环的。
Houdini 的时间线有明确的起点和终点帧(通常是 Frame 1 到 Frame 240、或者任意你设置的范围)
如果 Alembic 缓存只有 240 帧,我在 TimeShift 中设置 $F + 100,那到了帧数超出范围(比如 $F = 160 → 取帧 260)时,到底会发生什么?
-
超出帧范围时(例如
.abc只到 240,而你请求第 260 帧):-
Alembic 节点返回的是“空几何”
-
视口不显示东西
-
不报错(除非你用的是严格的 Alembic 解包+依赖)
-
渲染也不会有结果,等于透明帧
-
👉 就是一个空壳,你看到的是“没几何体”的状态。
xxxxxxxxxxx
$FF 是 Houdini 中表示“当前时间(以秒为单位)”的变量,不是“自动补帧”的意思。
它本身不会自动插值或补帧,但它可以导致节点在“非整数时间”被计算,从而触发 Houdini 的插值机制。
你有一个 Alembic 烘焙帧(1 ~ 100),每帧是静止 keyframe。
| 设置 | 结果 |
|---|---|
TimeShift → Frame = $F |
✅ 总是取整数帧,不插值 |
TimeShift → Frame = $FF * 24 |
❌ 有可能产生 1.5、2.75 等中间帧,会触发插值 |
这就是你所说的“自动补帧”现象的来源 —— 并不是 $FF 本身,而是你用浮点时间访问了中间状态。
xxxxxxxxxx
Houdini 中,当你在视口或 Geometry Spreadsheet 中选中一些点(或面、边、原语)然后按 Delete 键,不会修改原始模型的数据,而是自动创建一个 Blast 节点 来“非破坏性”地移除它们。
这是 Houdini 的核心设计哲学:
一切都是“节点驱动、非破坏”的过程化建模。
不像传统建模软件(比如 Blender、Maya 的直接编辑模式),Houdini 不会修改原始几何体,而是将所有操作以节点形式记录下来,方便你:
-
还原 / 撤回
-
动态修改范围
-
搭建完整流程链条
Blast 节点做了什么?
| 你做的操作 | Blast 节点参数 |
|---|---|
| 选中点并删除 | Group 类型设为 Points,Group 中填入点 ID |
| 选中面并删除 | Group 类型设为 Primitives,Group 中填入面编号 |
| 选中后保留 | Delete Non-selected 勾选 |
它实质上是对输入几何体做了一个条件过滤,不是真正删除了底层数据。
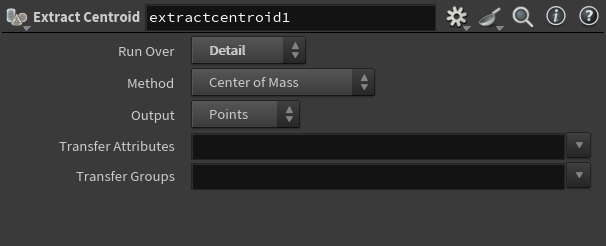
你要做什么 是否适合用 Extract Centroid
得到整个模型或碎片的中心点 ✅ 是,非常适合
做动画枢轴对齐、定位 ✅ 是,可以直接取位置
精确计算几何平衡中心 ✅ 是(Center of Mass)模式就很精确
只是想要包围盒范围 ❌ 不需要这个节点,用 Bounds 节点更快
方便了,,按p查看当前节点的parameter
xxxxxxxx
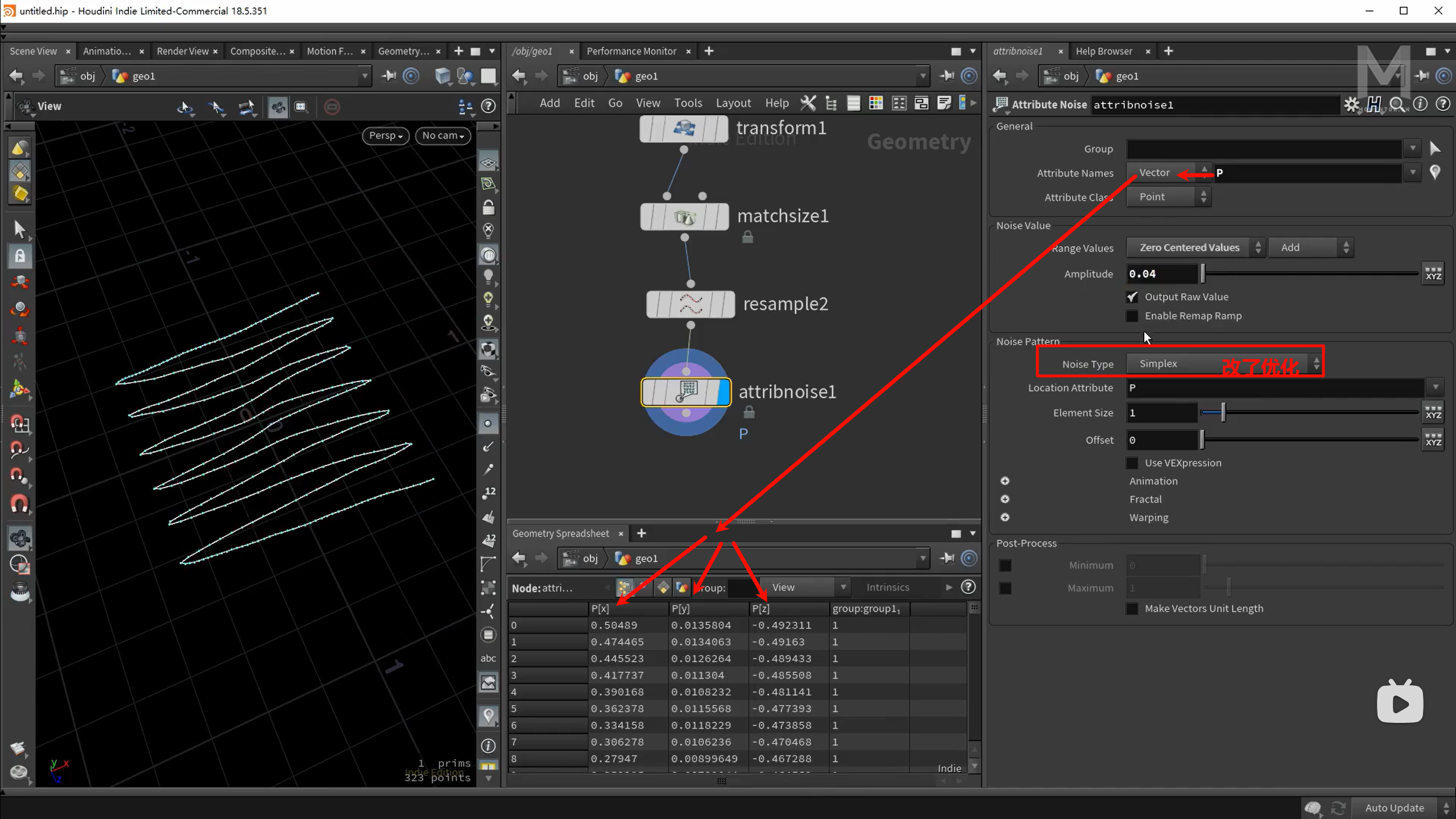
什么是 Attribute VOP?
一个节点,允许你用可视化方式(拖线连节点)去处理几何体上的属性(点、面、法线、颜色、uv 等)
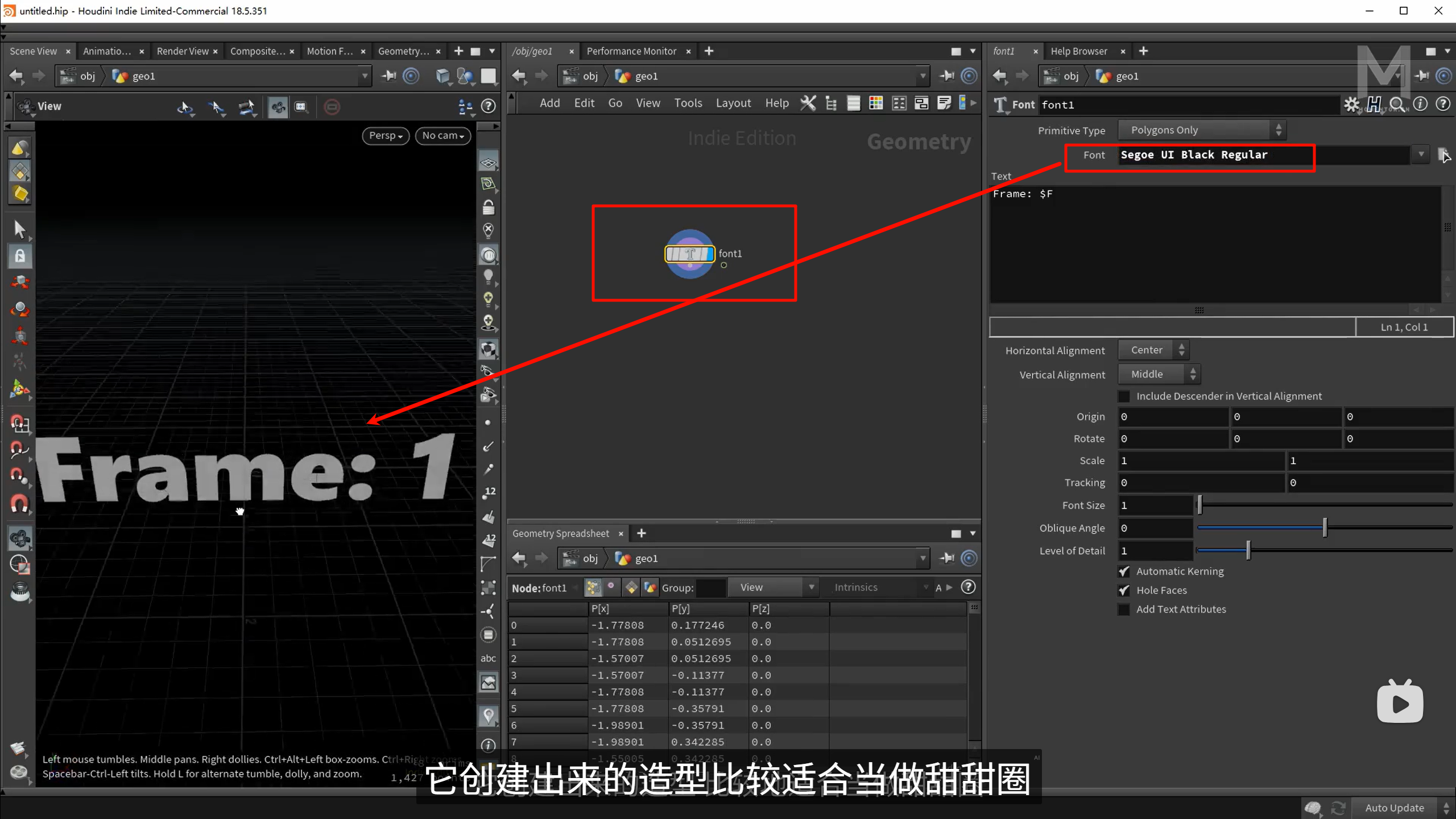
PolySoup 是 Houdini 用来压缩轻量几何的一种格式(合并重复点、减少数据体积)



e跳粉
 r跳为选中,蓝
r跳为选中,蓝

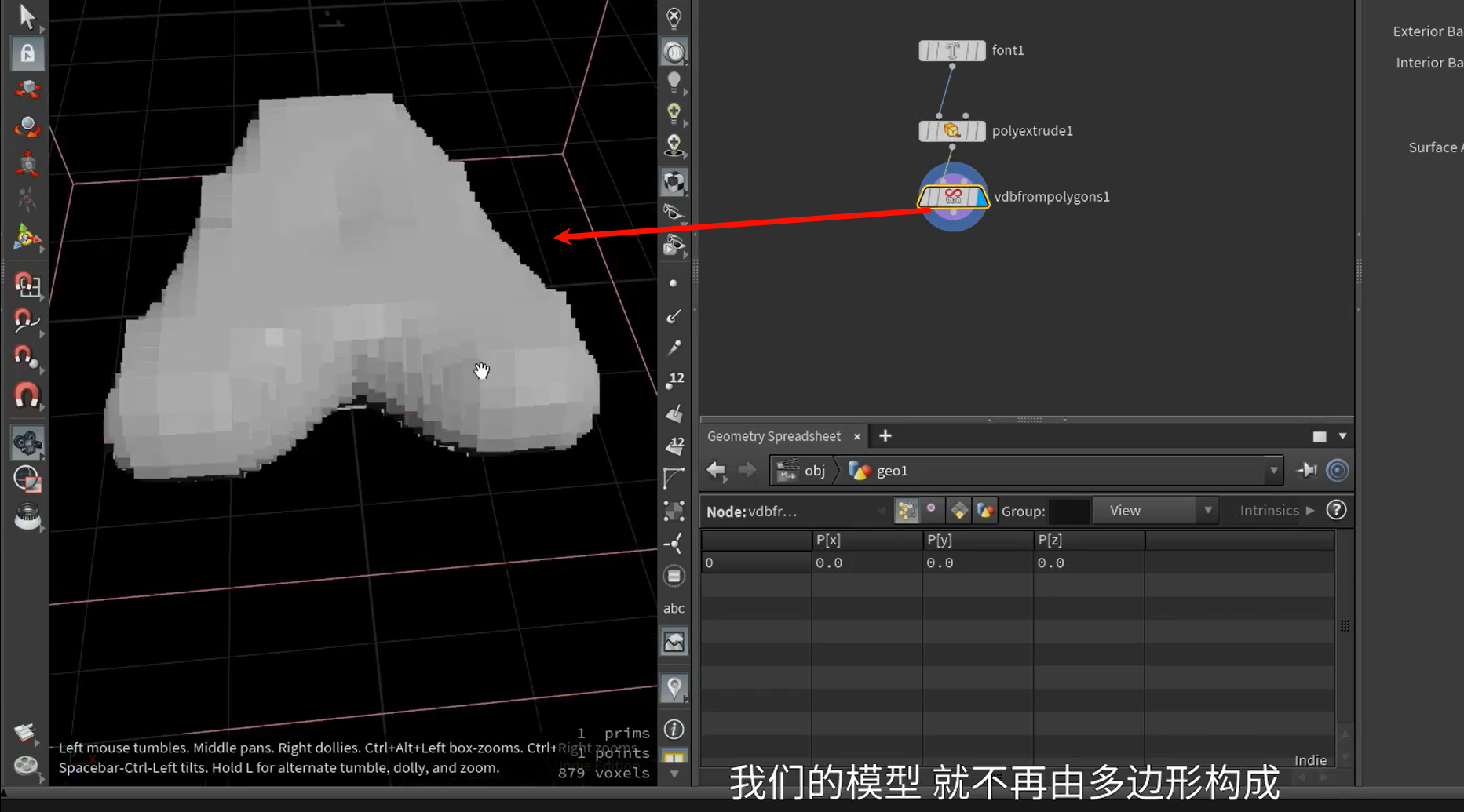
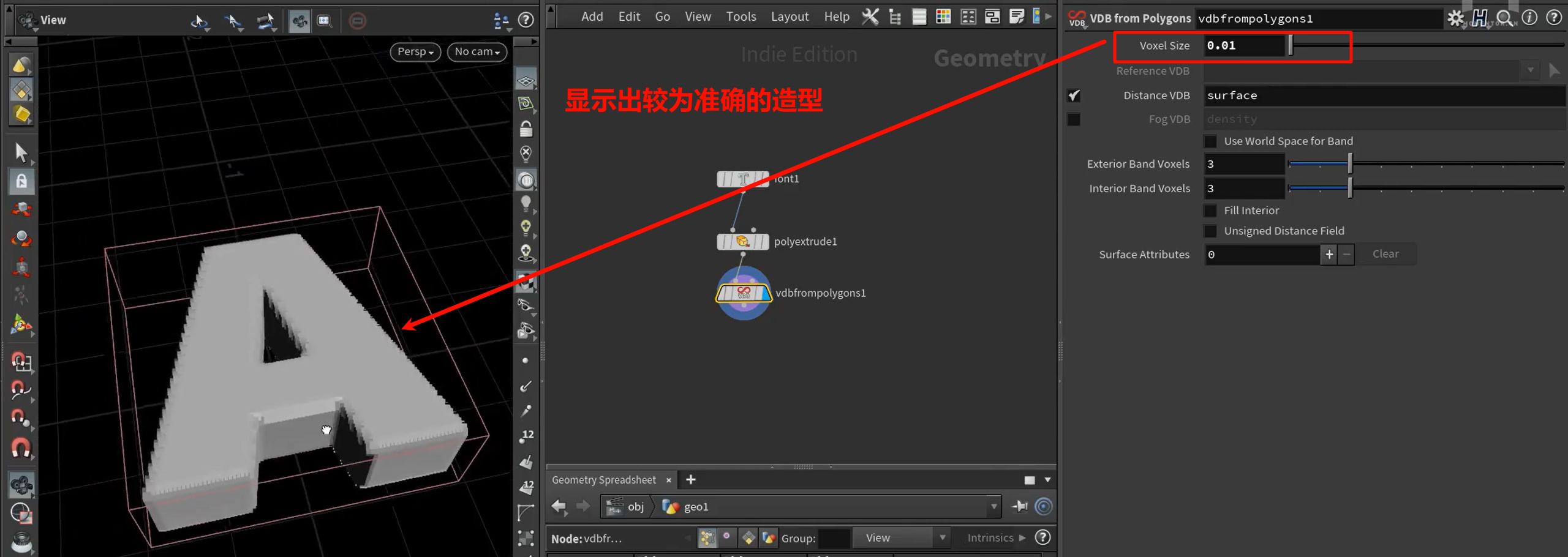
 接着使用vdbsmooth节点,把结果进行处理
接着使用vdbsmooth节点,把结果进行处理
此时的需要先convert
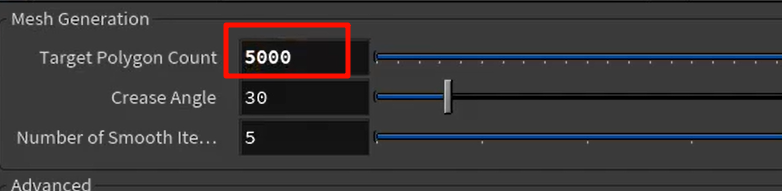
默认的1000改成了5000,整个模型的表面mesh数大幅增加
选定范围,并添加mask点属性
最符合的为1,不符合的为0
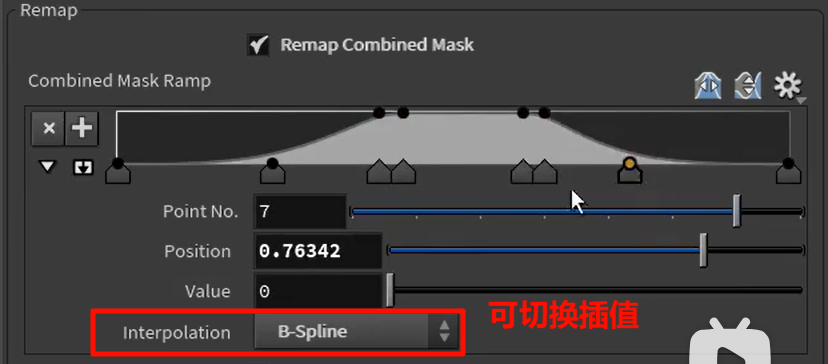
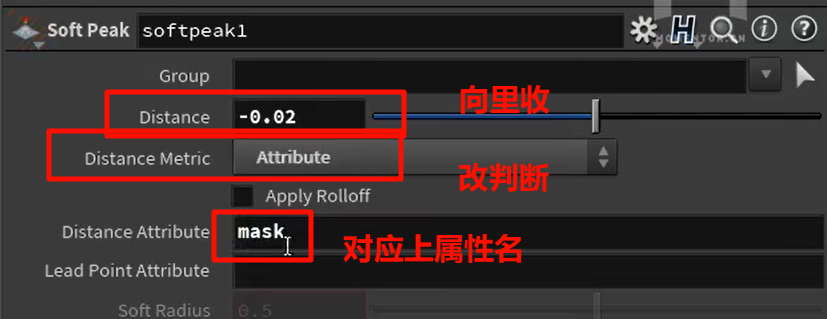
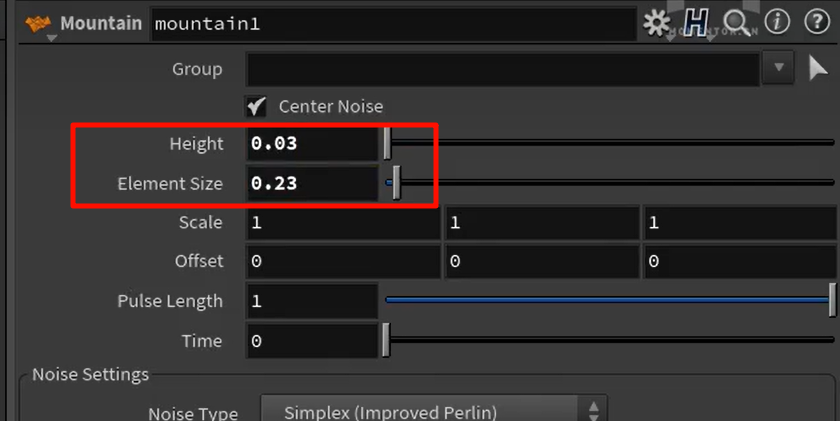
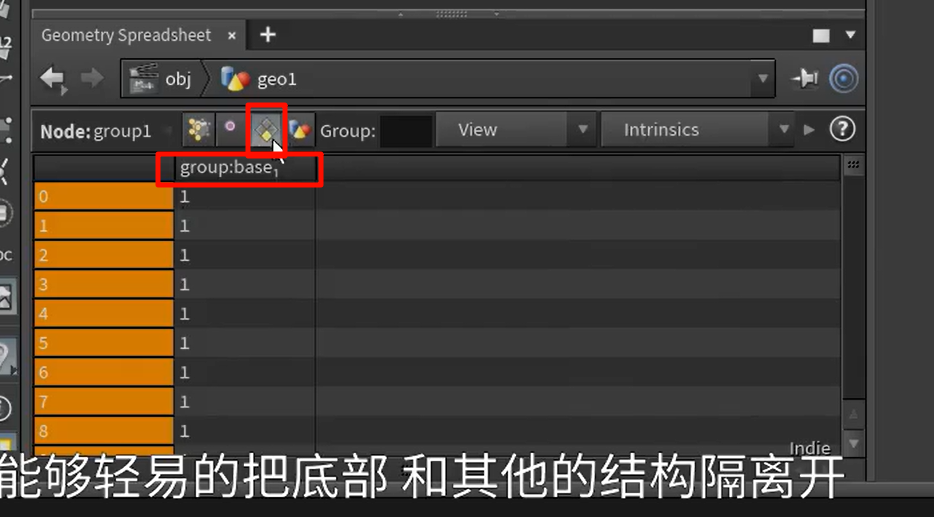
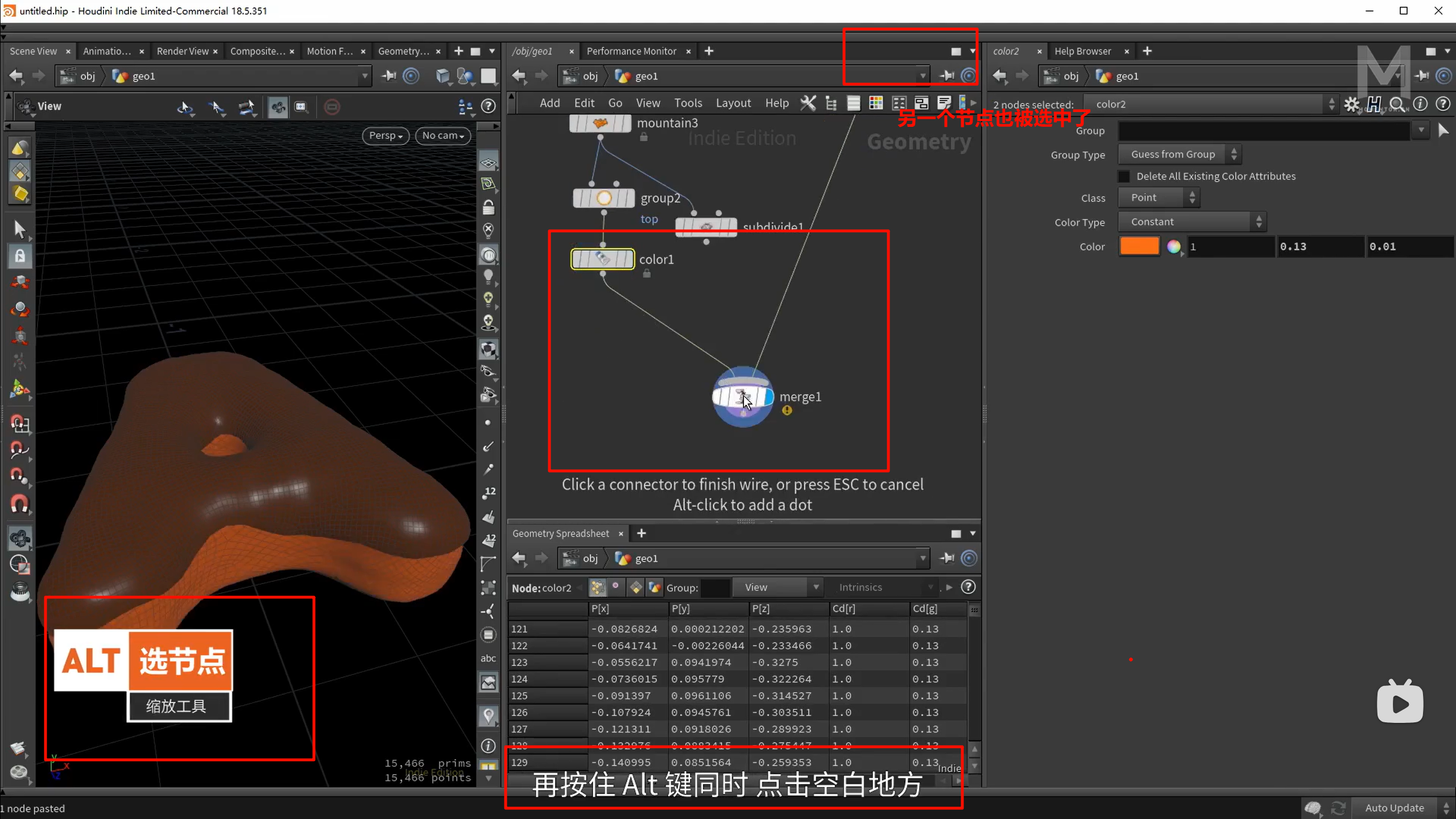
merge的方法

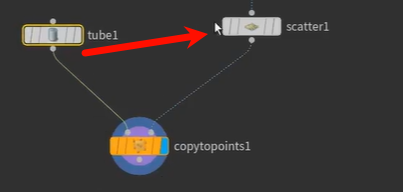 创建到每一个点上
创建到每一个点上
copytopoint(只能针对点的)
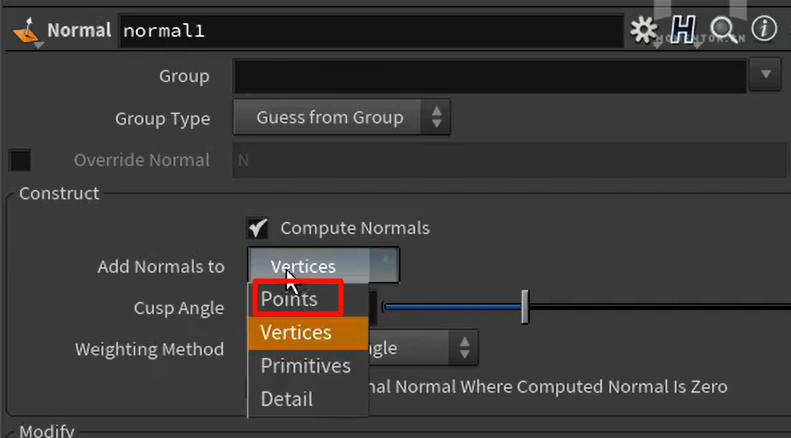
默认情况下,normal创建的法线属性,是基于vertex的
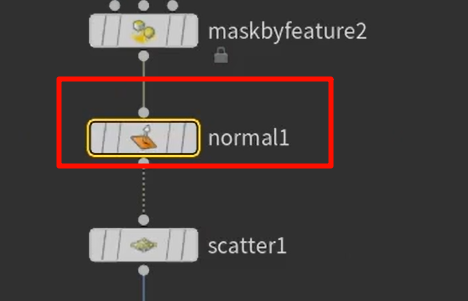
所以要把法线改
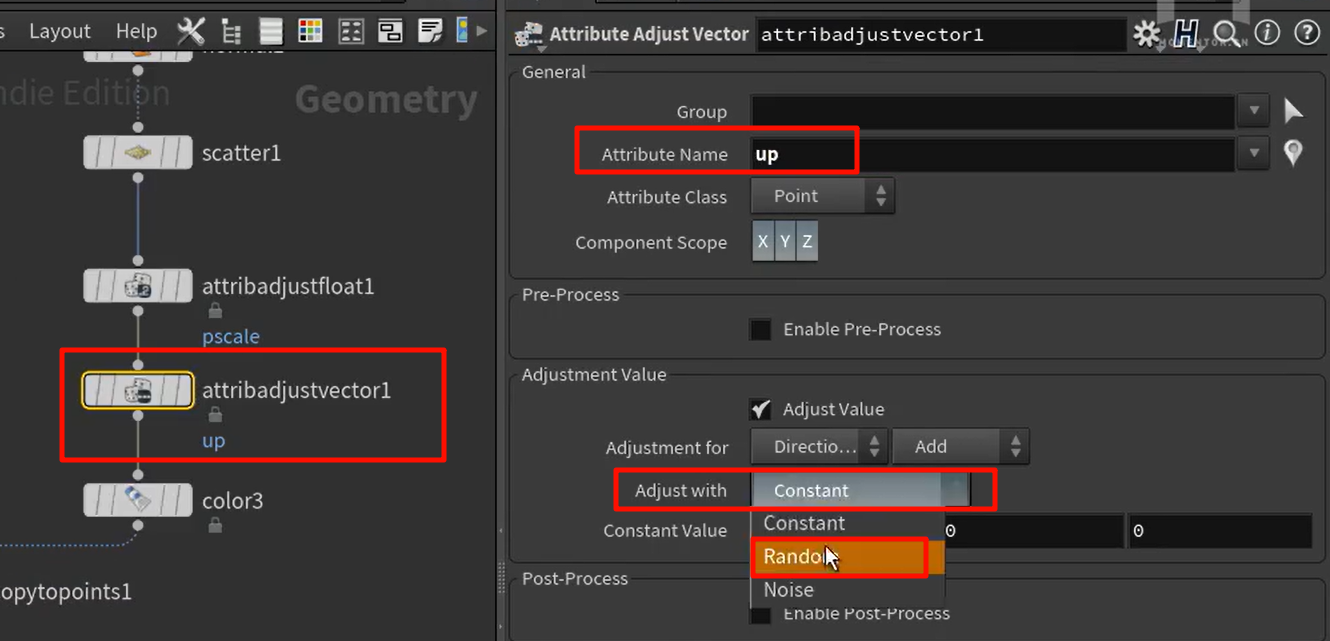
copy to points节点会使用N和up两个向量来确定完整的空间旋转方向
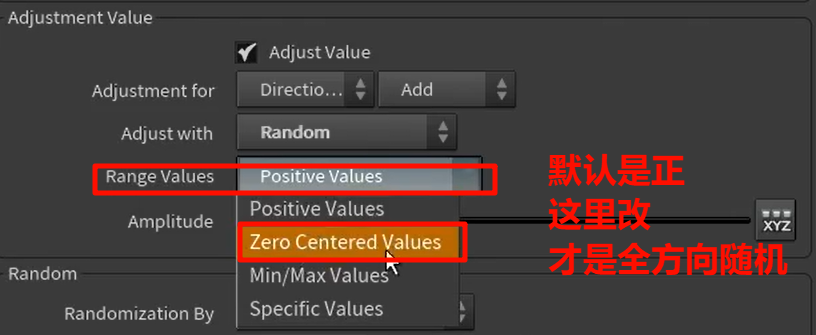
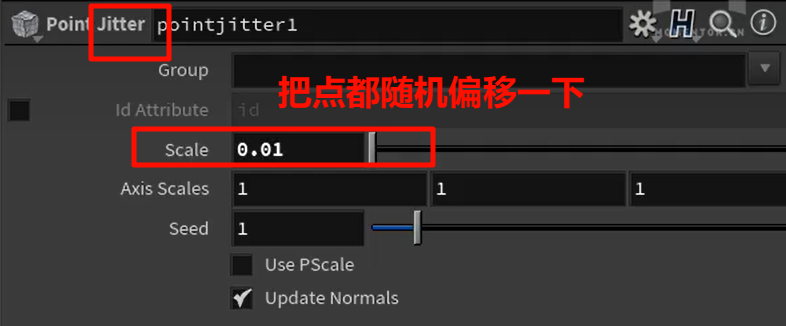

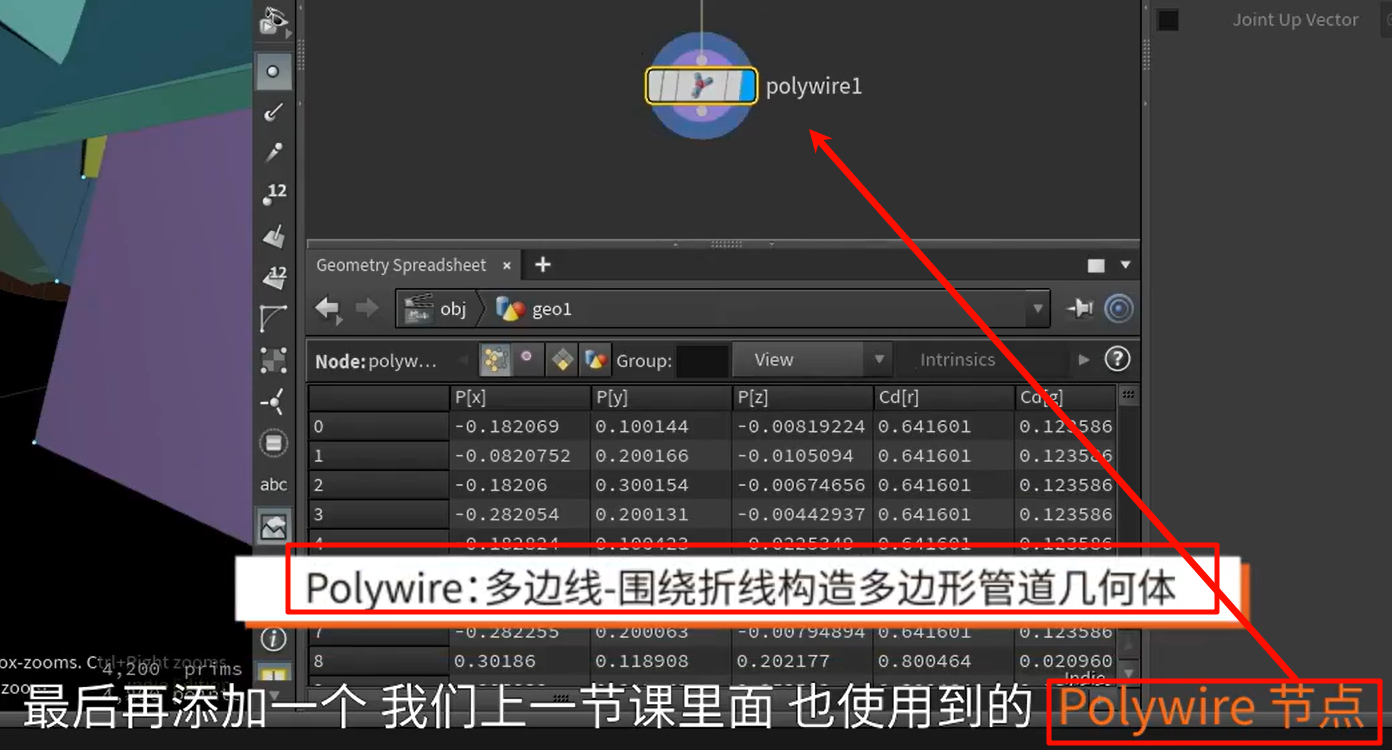
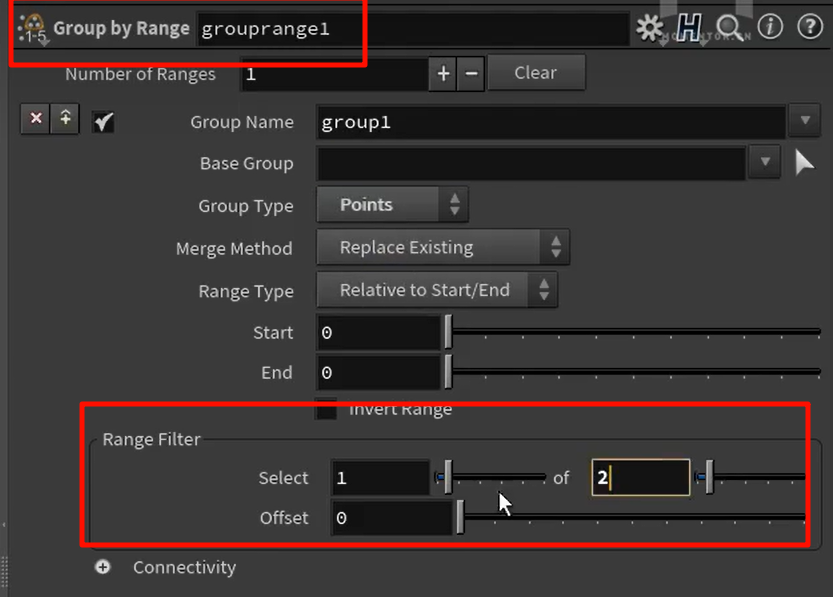
 往世界中心归位
往世界中心归位
Ray:投射-将一个表面投影到另一个表面上


blast反选,得到具体的group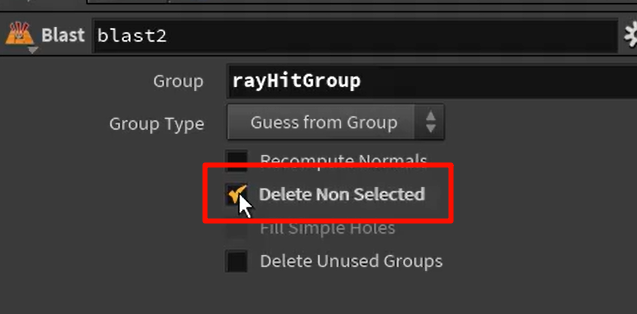
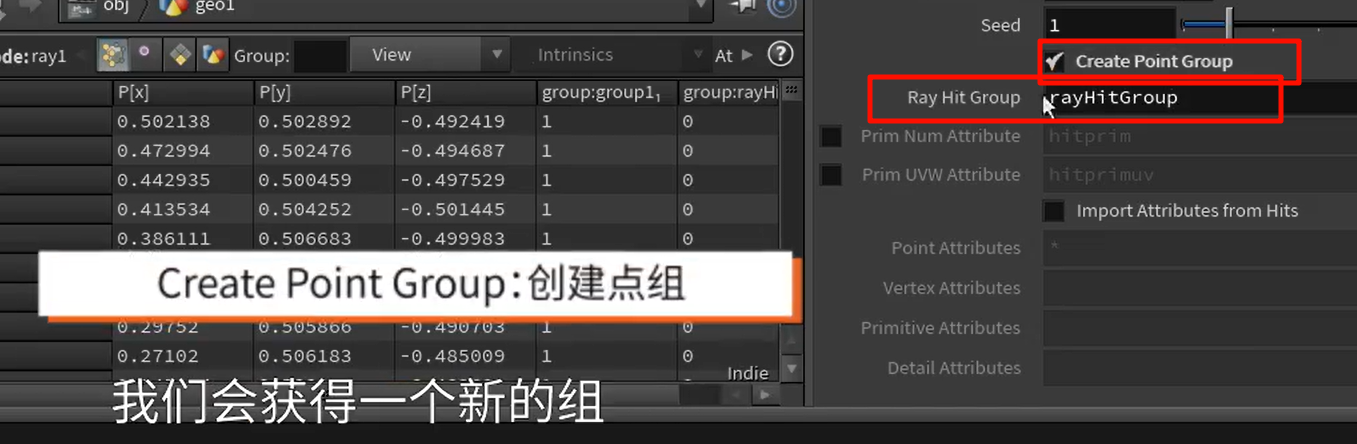
xxxxxxxxxx
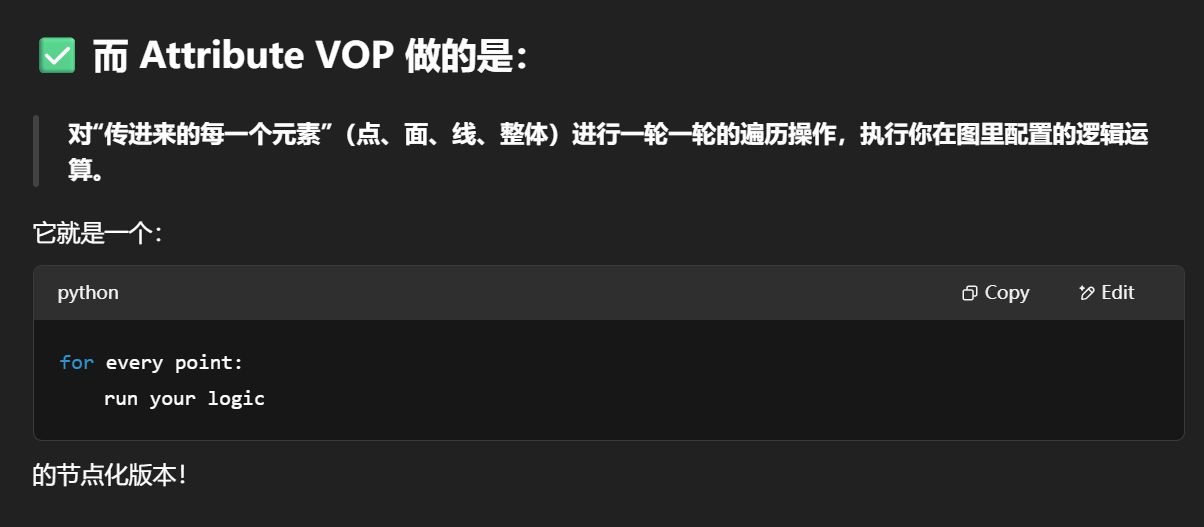
Attribute VOP 是一个用于“以可视化节点方式修改几何属性(Attribute)”的工具。
它的本质就是一个 点/面/线/整体级别的循环器,在其中你可以对每一个点、每一个面,执行 VEX 程序逻辑,但是不用写代码,而是拖线连图来表达逻辑。
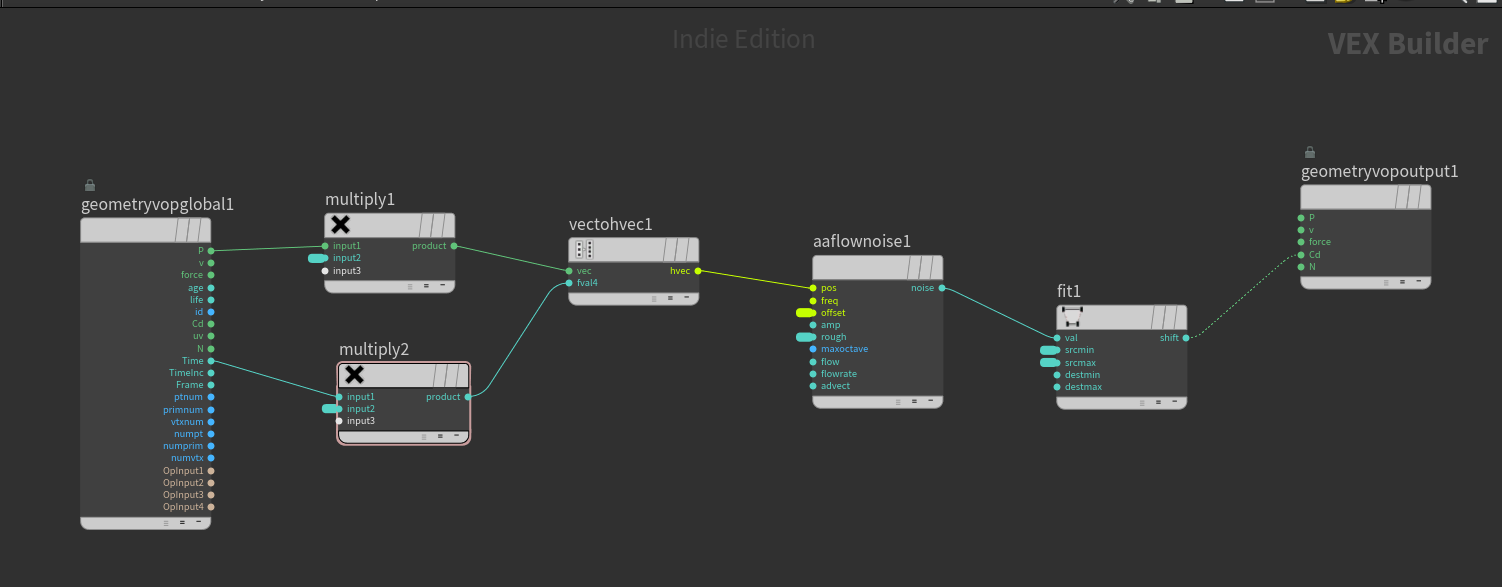 Attribute VOP(你命名为
Attribute VOP(你命名为 Cd_noise1)的内部 VOP 网络,而你所看到的 Cd.r, Cd.g, Cd.b 三个点属性,就是这个网络计算出来并写入的结果。
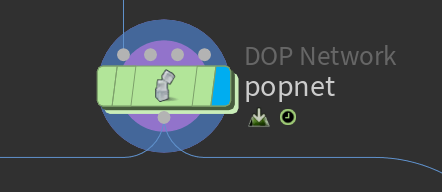
popnet(Particle Operator Network)
它是一个 DOP Network 类型的节点,主要用来驱动粒子系统(POP,Particle Operator)模拟。
它和 Attribute VOP 的关系不大,属于不同层级,不过你确实可以在 POP 中使用 VOP 来控制粒子行为
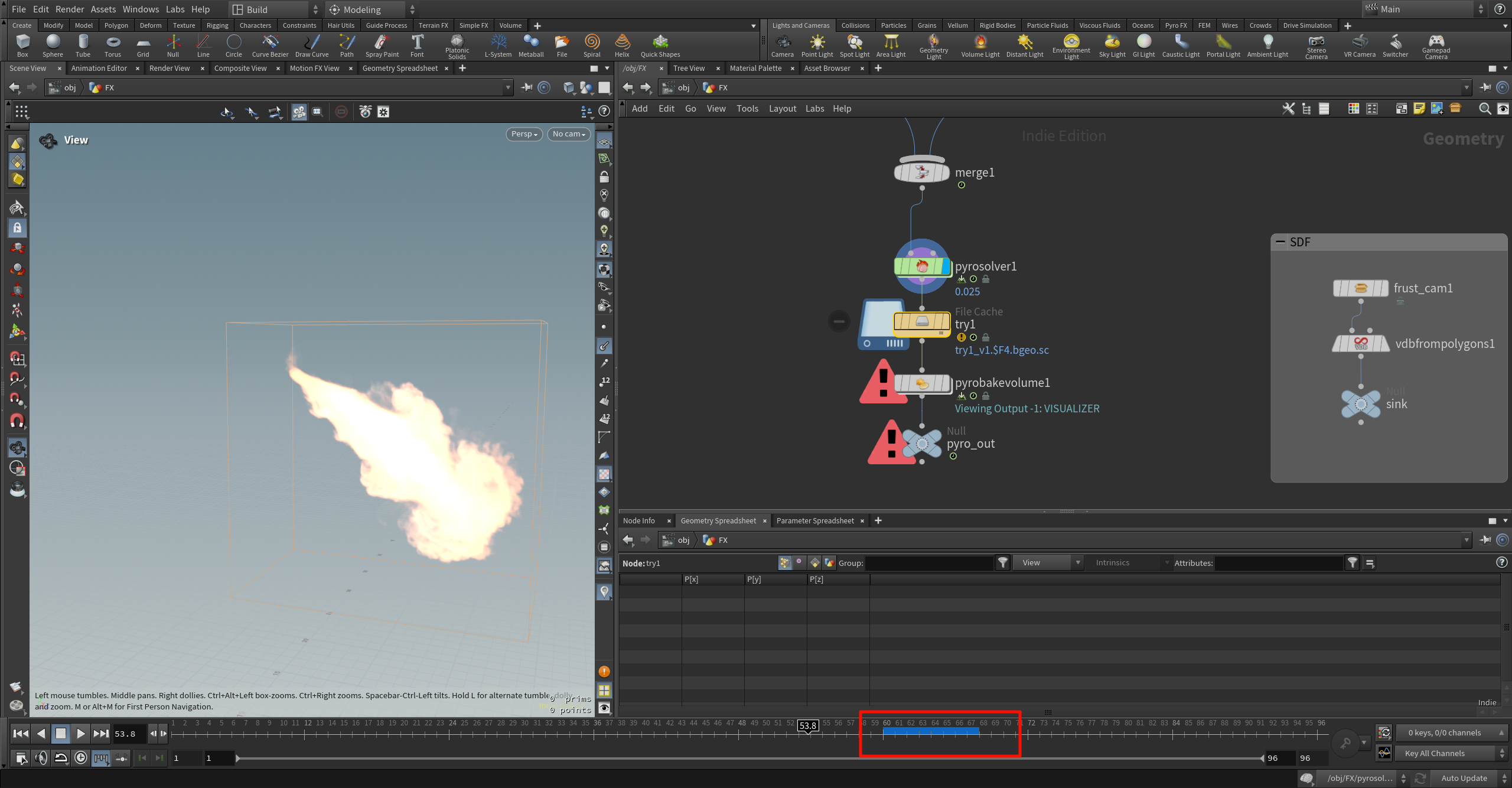
蓝色时间轴条(Timeline Blue Bar)到底是什么?
👉 它代表的是:
当前节点(尤其是 DOP 或 File Cache)已缓存的帧范围。
换句话说:
蓝色部分 = Houdini 内部或磁盘中已经计算过并存储下来的帧。
灰色/空白部分 = 还没有计算,等你播放到那一帧才会“现算”。
想进行 Pyro Bake Volume 或后期渲染:
你必须让你想要渲染的所有帧都完成了模拟,也就是说——蓝条要覆盖这些帧范围。
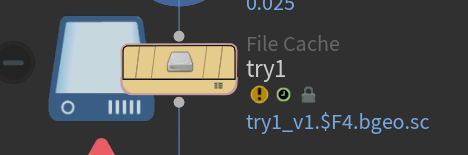
图中这个节点是:File Cache
它的核心作用就是:
把当前节点的数据缓存为
.bgeo.sc文件,保存到磁盘上,供后续读取
✅ 同时也会让 Timeline 上的蓝条成立 —— 表示这一段帧已经被写入或加载成功。
| 功能 | 作用 |
|---|---|
🟢 写出 .bgeo.sc |
把帧数据从内存保存到硬盘,支持重新打开时复用 |
| 🔵 生成蓝条 | 显示哪些帧已被缓存(写出或从磁盘读取) |
| 🔒 上锁 | 防止节点自动重新计算,强制用缓存数据 |
-
try1_v1.$F4.bgeo.sc
表示输出文件名为try1_v1_0001.bgeo.sc,try1_v1_0002.bgeo.sc… 按帧号命名保存。 -
黄色背景 → 表示当前状态为「只读取缓存,不再计算输入」
-
圆圈叹号(!)→ 表示当前帧文件找不到(比如
try1_v1_0054.bgeo.sc没写出来)
xxxxxxxxxx
File Cache 节点到底是缓存到“内存”还是“磁盘”?内存会不会爆?
File Cache 节点的作用就是:将数据写入磁盘(不是内存)!
它不是用来“临时缓存”的,而是用来生成 持久存储的 .bgeo.sc 文件,保存在你设置的 $JOB 文件夹路径中。

xxxxxxxx
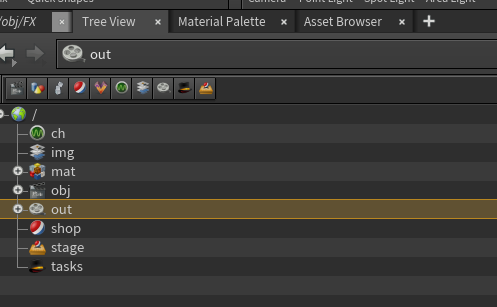
图中这些 /obj, /out, /img 是虚拟空间路径,不是实际文件夹
这些是 Houdini 中的“网络容器(Network Context)”,你可以把它理解为:
| Houdini 结构名 | 作用 | 实际磁盘路径? |
|---|---|---|
/obj |
所有几何体、模拟、相机等场景对象的主容器 | ❌ 否 |
/out |
输出渲染器(Mantra、Karma)、ROP网络 | ❌ 否 |
/img |
合成网络(COP2)、贴图处理 | ❌ 否 |
/mat |
材质节点网络(Material Network) | ❌ 否 |
/shop |
旧版材质系统(已废弃) | ❌ 否 |
/stage |
Solaris / USD 场景描述系统 | ❌ 否 |
/ch |
通道数据、动画关键帧 | ❌ 否 |
✅ 它们只是 Houdini 内部的“功能模块分区”,不会自动对应硬盘中的任何文件夹。
实际的项目数据(缓存、贴图、输出)放在哪儿?
这就取决于你怎么设置你的 项目路径变量。
Houdini 提供了两种核心变量:
| 变量名 | 含义 | 示例 |
|---|---|---|
$HIP |
当前 .hip 文件所在的路径 |
D:/Projects/fireball_project/ |
$JOB |
当前项目目录(你自己设置的) | D:/Projects/fireball_project/(可自定义) |
Houdini默认打开的时候不属于任何一个Project状态
-
你打开的是一个临时的新场景
-
并没有绑定到任何
$JOB项目目录 -
Houdini 不会自动调用你上次的 Project 文件夹
-
也不会自动设置
$JOB路径,除非你手动设置过
hip 文件本身保存在哪里?
.hip 或 .hiplc 是你的 Houdini 工程文件,保存路径就是你点击 File > Save As 时指定的位置。
你可以通过 $HIP 自动获取这个路径,例如:
echo $HIP
# 返回:D:/Projects/fireball_project/
怎么创建标准项目结构(推荐操作)
fireball_project/
├── geo/ ← 缓存 .bgeo.sc
├── render/ ← 输出图像序列
├── tex/ ← 材质贴图
├── scenes/ ← .hip 文件
├── scripts/ ← 脚本
然后 $JOB 会自动指向这个根目录,你以后路径只用写:
$JOB/geo/fireblast_v1_$F4.bgeo.sc
就不需要死记硬编码路径了。
当你打开任何 .hip 或 .hiplc 文件时:
$HIP永远指向这个文件所在的实际磁盘目录。
⚠️ $JOB 是用户可配置的,不会自动更新
当你打开别人的 .hip 文件时:
🔥
$JOB默认不会跟随.hip自动变化,仍然保持你上一次打开 Houdini 时设置的项目路径。
如果这个 .hip 文件中用到了 $JOB 路径,比如:
$JOB/cache/pyro/dragon_fire_0001.bgeo.sc
但你的 $JOB 当前还指向你自己的旧项目路径:
E:/MyProject/
就会导致路径解析错误,提示找不到文件。
🧭 如何检查/重设 $JOB?
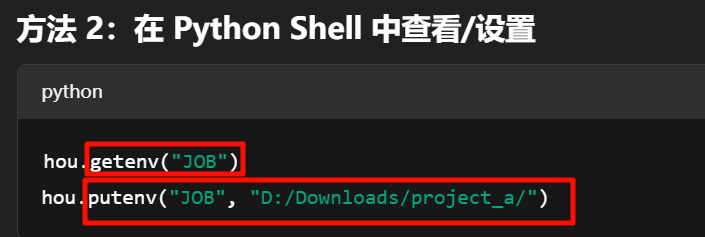
xxxxxxxxxxxxxxxx
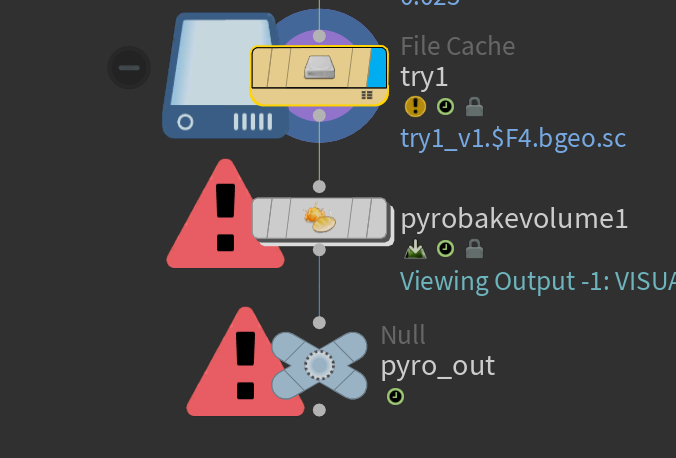
只要你把 File Cache(try1)中的帧全部 Save to Disk 成功,后面的 pyrobakevolume1 就能正常读取体积数据,不再报错。
红色警告三角标志会消失,Bake Volume 会开始处理 .bgeo.sc 文件中包含的 VDB 字段(density、flame、temperature 等)。
Pyro Bake Volume 是不是算“后处理”?是否基于 File Cache 做的?
非常准确 ✅:
Pyro Bake Volume 是 Houdini 的体积后处理系统**(Volume Post-processing)
它是专门设计来作用在已缓存完成的模拟结果上的,不会也不应该参与模拟本身。
| 功能 | 说明 |
|---|---|
| 着色 | 给 density、flame 等体积场绑定颜色,用于渲染前的视觉增强 |
| 显示 | 支持 Viewport 中的实时预览,不必先渲染 |
| 控制视觉密度、光散射 | 如 Smoke Color、Fire Brightness、Shadow Density 等 |
| 分离体积通道 | 可用于输出多个不同视觉 pass(volumeLight、flameScatter、temperature 等) |
可以看别人的hip效果了,但是问题是卡顿,真的很卡,
这是硬件原因,
xxxxxxxxxxxxx
渲染农场到底“帮你做的是什么”?
✅ 本质上,渲染农场帮你批量计算每一帧最终画面的“像素图”。
它的工作原理其实很直接:
✅ 你上传的不是视频,也不是模型,而是:
| 上传内容 | 内容类型 |
|---|---|
.hip 文件(或 .blend / .ma / .max) |
包含了所有模型、特效、材质、动画、摄像机 |
所依赖的贴图、缓存(如 .bgeo.sc、.vdb) |
模型贴图、FX缓存、模拟结果 |
| 指定一个摄像机、分辨率、帧范围 | 如 Camera1,1920x1080,帧 1–120 |
| 渲染器设置(如 Redshift、Arnold 等) | 光照采样、GI、抗锯齿等参数 |
然后农场将:
✅ 每一帧 单独启动一台机器,在固定摄像机和光照条件下,进行像素级别计算(即渲染)
最终你会得到:
-
img_0001.exr -
img_0002.exr -
...
-
img_0120.exr
这些图像连起来就是动画视频的每一帧。
那为什么叫“农场”?
因为这件事可以被完美拆成帧并行处理:
| 一台机器 | 负责渲染第 1 帧 |
|---|---|
| 第二台机器 | 渲染第 2 帧 |
| …… | …… |
| 第 100 台机器 | 渲染第 100 帧 |
⚡ 成百上千台机器并行渲染,几分钟就完成你本地几小时都跑不出的结果。
File Cache 是不是也叫“渲染”?
你的理解对了一半。
| 动作 | 实质内容 | 是否 GPU 渲染 |
|---|---|---|
File Cache |
将模拟/动画的几何信息输出为 .bgeo.sc |
❌ 否,是 CPU 写缓存 |
渲染器(Mantra/Redshift) |
将场景+材质+灯光 转化为图像 | ✅ 是,算像素,需要 GPU |
❗所以你 File Cache 花了 20 分钟,其实还没开始真正的“图像渲染”
这只是:
-
烟雾模拟写出
.bgeo.sc -
或粒子位置写出
.bgeo -
或物体动画 Bake 成关键帧
为什么我 File Cache 后 Houdini 播放仍然很卡?
这也完全正常。
因为 Houdini 的 Viewport:
-
不是预览视频播放器
-
它是实时读取磁盘、重建体积、渲染 OpenGL,尤其是 Pyro 烟雾或粒子,会非常吃内存 + CPU
💡 这和高端机器关系不大 —— 无论多贵的机器,Houdini Viewport 都不是用来“流畅播放缓存视频”的工具。
渲染农场生成的文件是干嘛用的?
生成的是:
| 文件 | 用途 |
|---|---|
.exr .png .jpg |
每帧渲染出的图像 |
.mp4 或 .mov |
(可选)农场帮你压成视频,或者你回本地用 PR/AE 拼成视频 |
✅ 农场“最终交付”的其实就是一个完整的帧序列(图片)
你可以:
-
放入 After Effects 做合成
-
放入 Premiere 做剪辑
-
用 ffmpeg 转码成
.mp4
把 .hip 丢进农场就能直接算,不担心路径错误或资源丢失。只需告诉我你用哪种渲染器(Redshift?Mantra?Arnold?)我可以帮你自动生成一套打包结构。
最少只需要这 3 样:
| 文件/信息 | 说明 |
|---|---|
hip 文件 |
你的 Houdini 工程文件,包含所有节点、动画、相机 |
| 渲染器信息 | 比如是使用 Mantra / Redshift / Arnold / Karma,农场要知道用哪个算 |
| 相机 + 帧范围 | 你要渲染的角度和时长,比如 Camera1,帧数 1–96 |
s三个主要模块

VOP – VEX Operators
以节点方式书写逻辑,构建 VEX 编程图形网络,实现自定义控制、噪声、颜色处理等。

-
挤出(Extrude):从已有面或边拉出新几何体,是创建厚度、延伸结构的基础。
-
倒角(Bevel):增加边缘细节,制造圆滑过渡。
-
桥接(Bridge):连接两个开口,生成中间面。
-
切边(Knife/Cut):引入新的拓扑、分段控制面数。
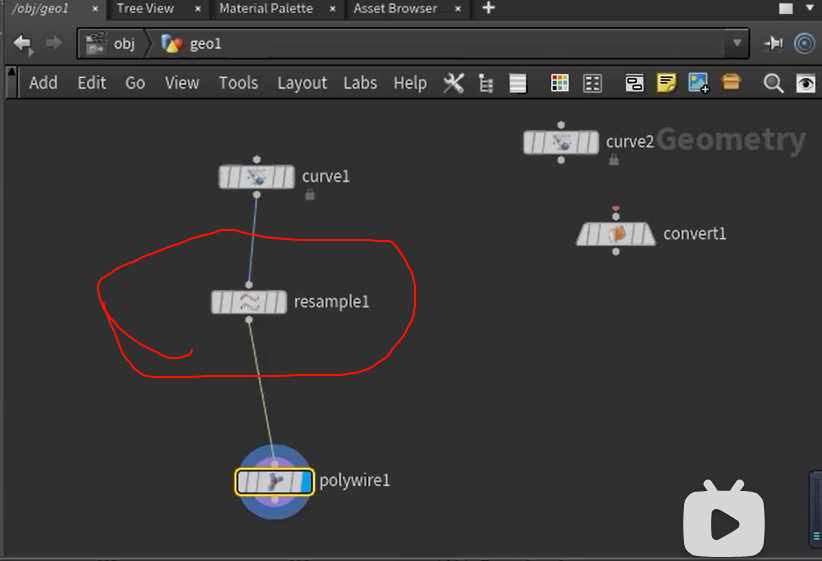
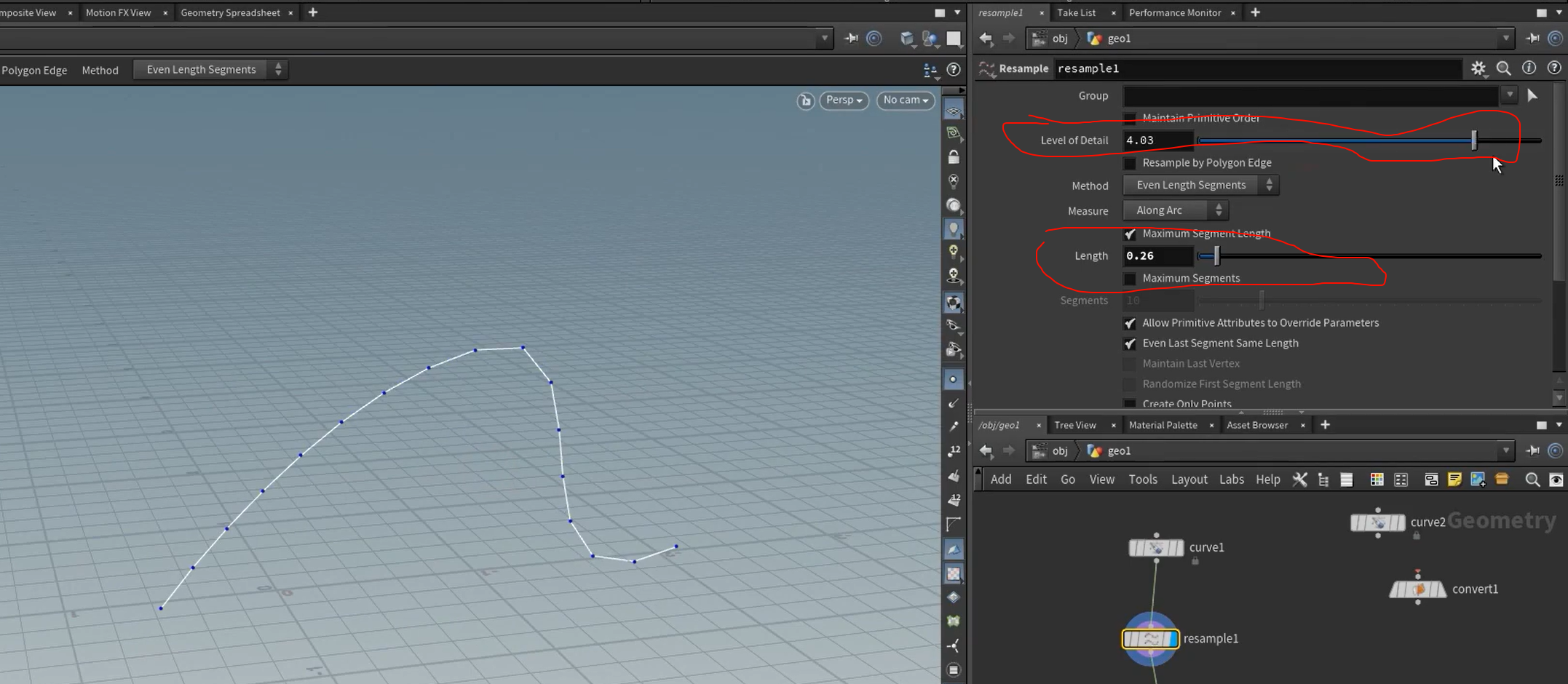
this ,is resample ,dud
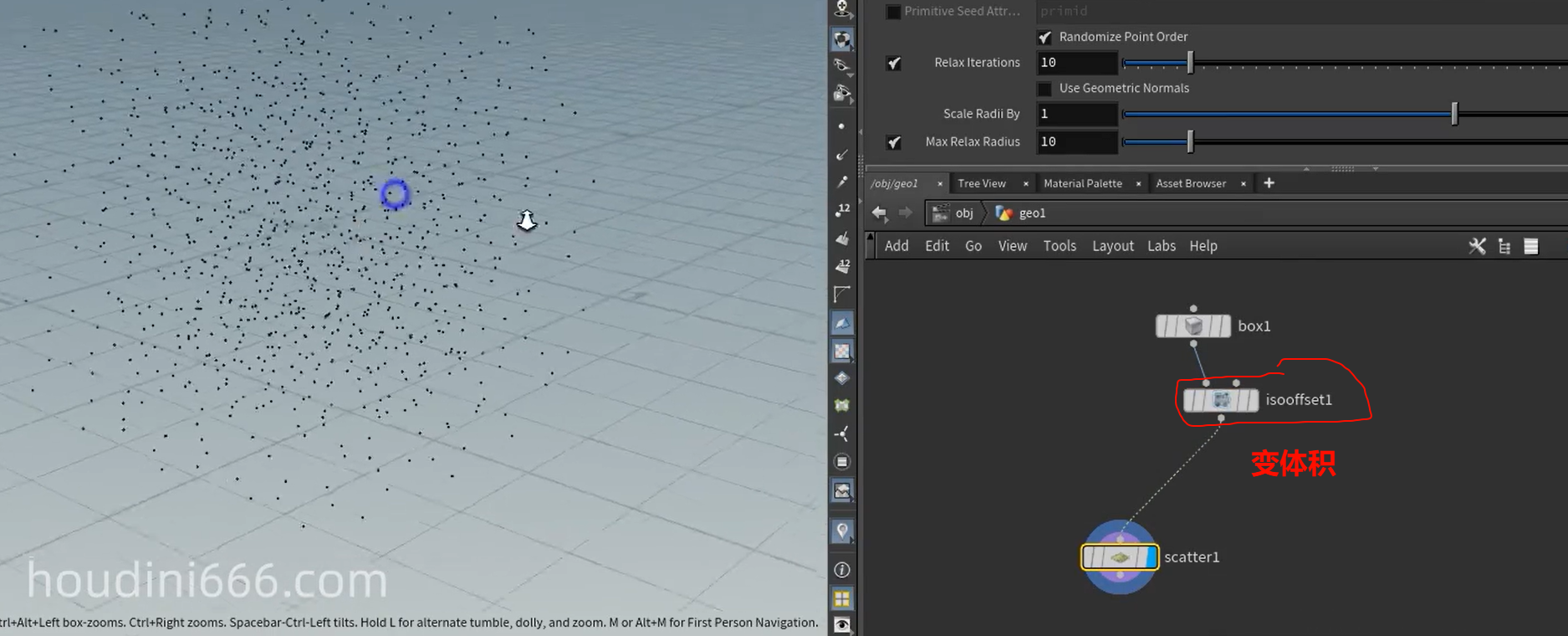
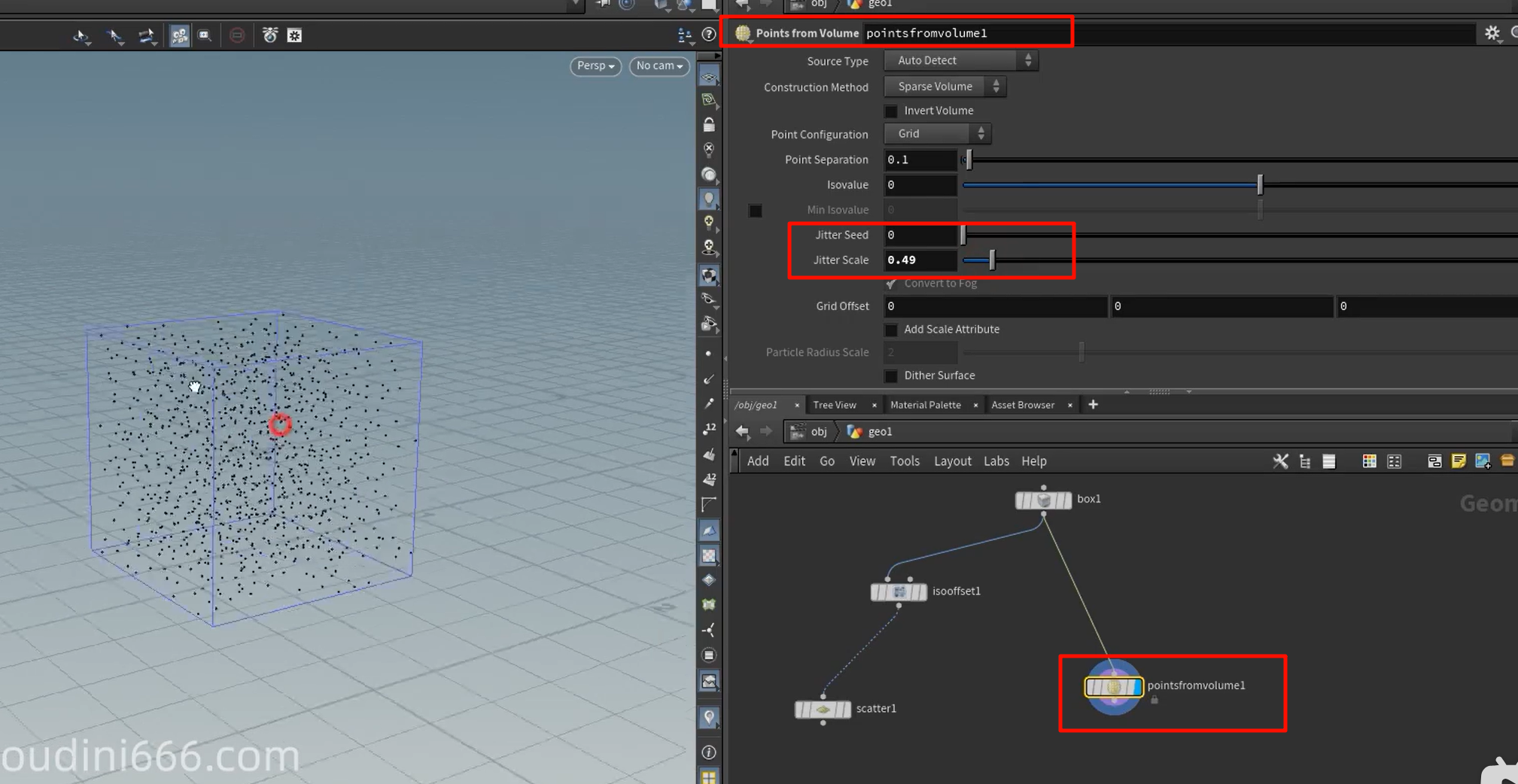
在内部撒点


 add ,删面留点
add ,删面留点
xxxxxxxxxxx
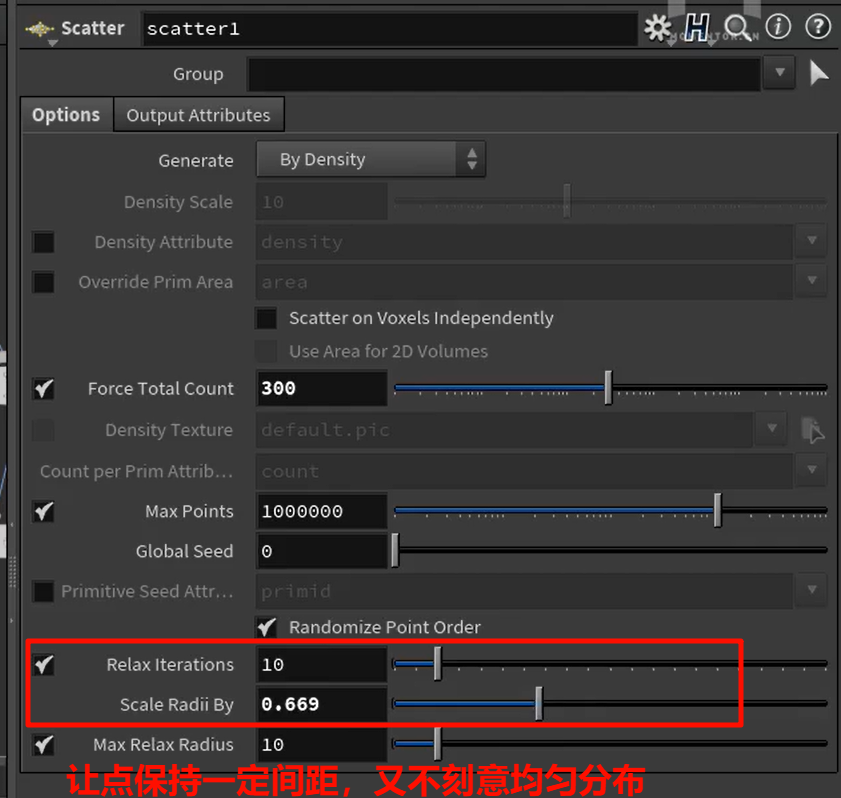
 现有点的基础上半径距离里随机复制生成点
现有点的基础上半径距离里随机复制生成点

xxxxxxxxxx
transfer变形器
bend
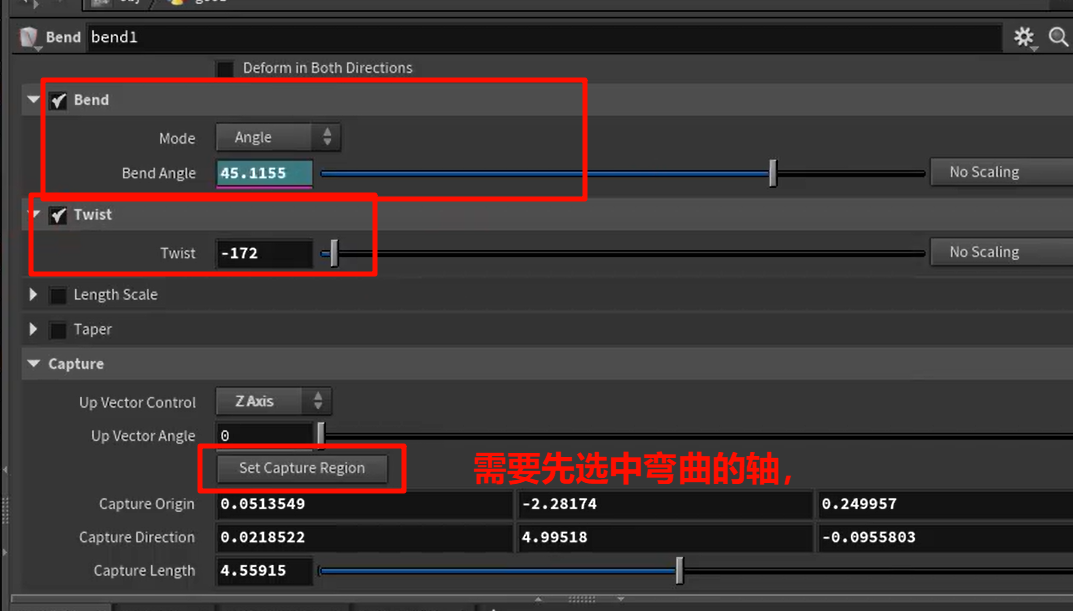

xxxxxxxxxx
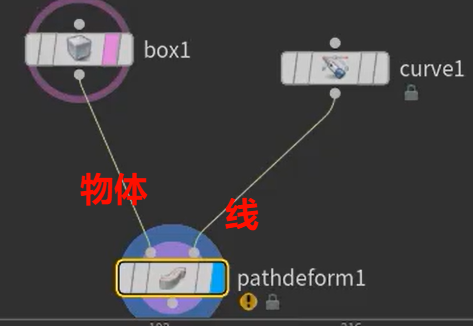
沿着曲线形变物体
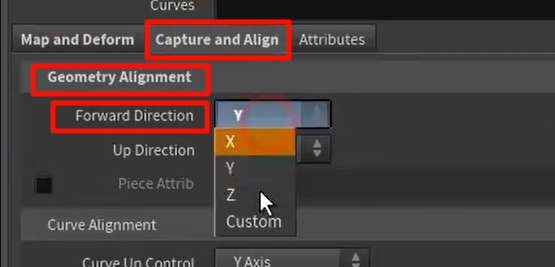

xxxxxxxx
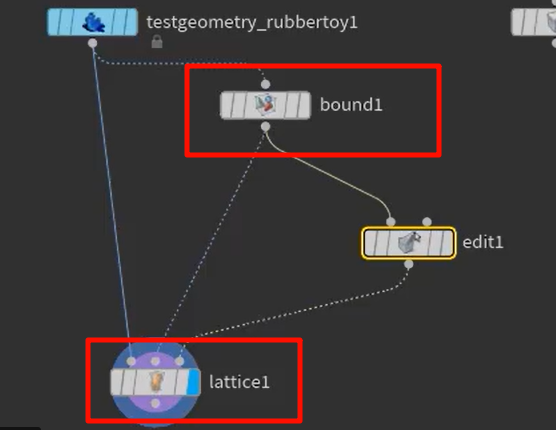
lattice,让a上的点的整体移动绑定到bound(产生最小的包围盒包住模型,可以在内部再细分点数)上

xxxx
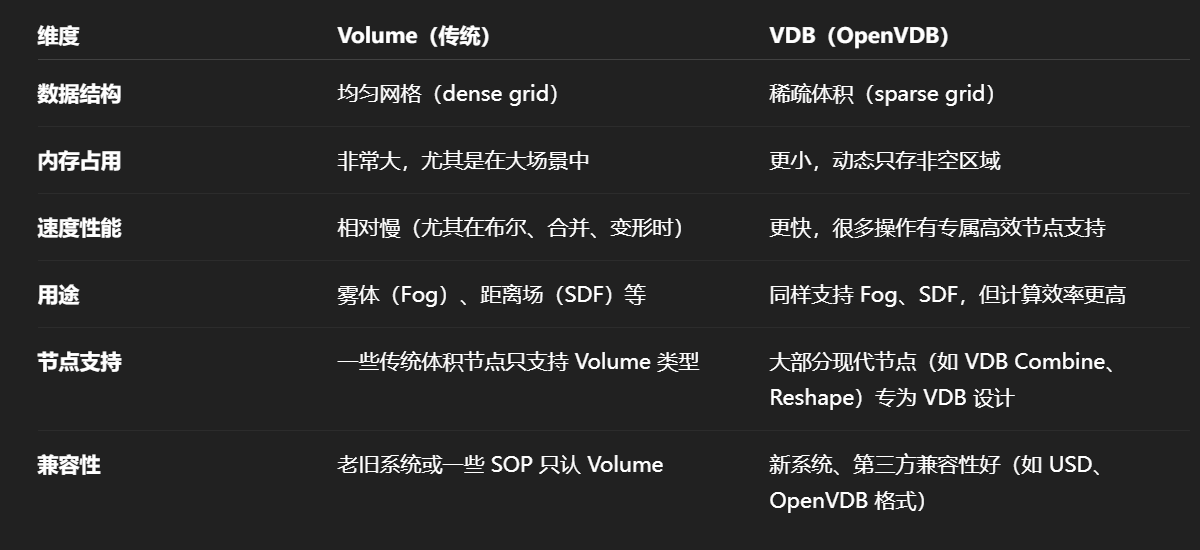
Volume(传统)----均匀网格(dense grid)
VDB(OpenVDB)----稀疏体积(sparse grid)
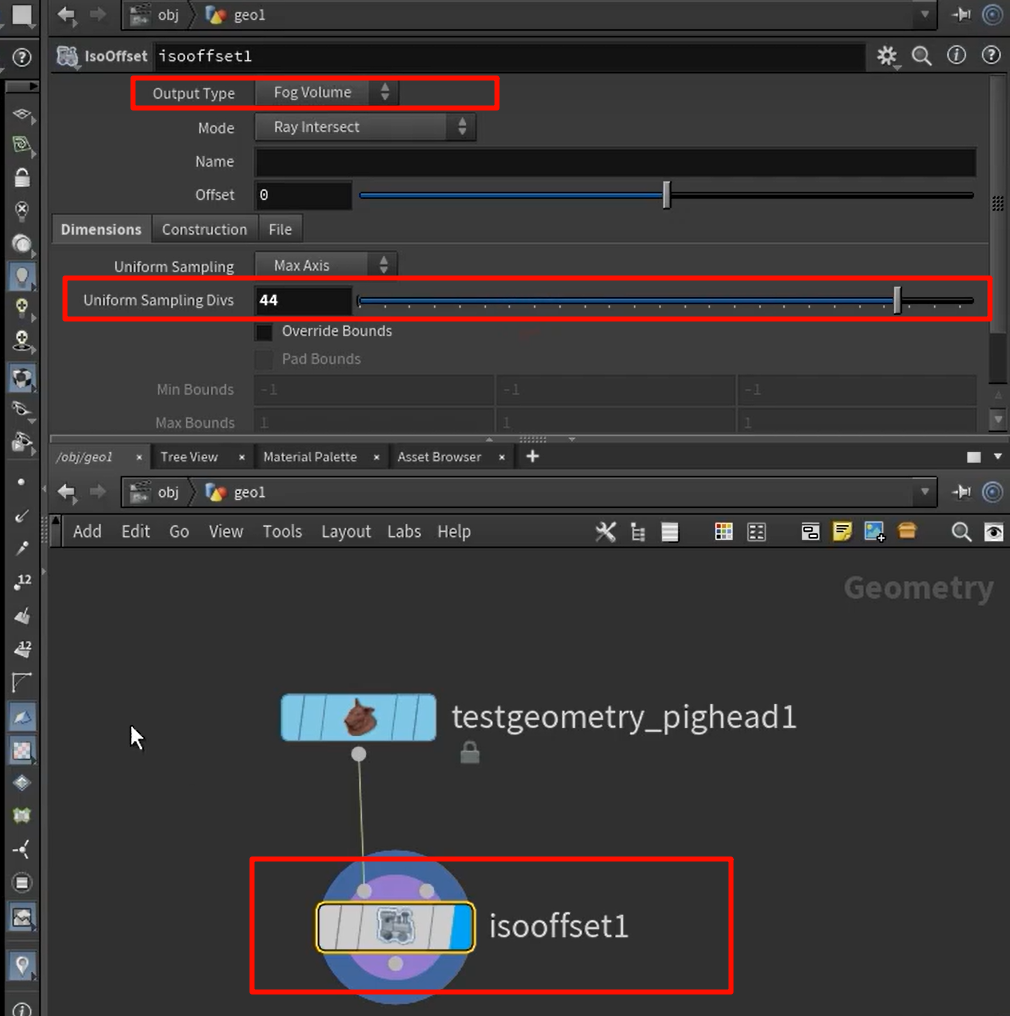
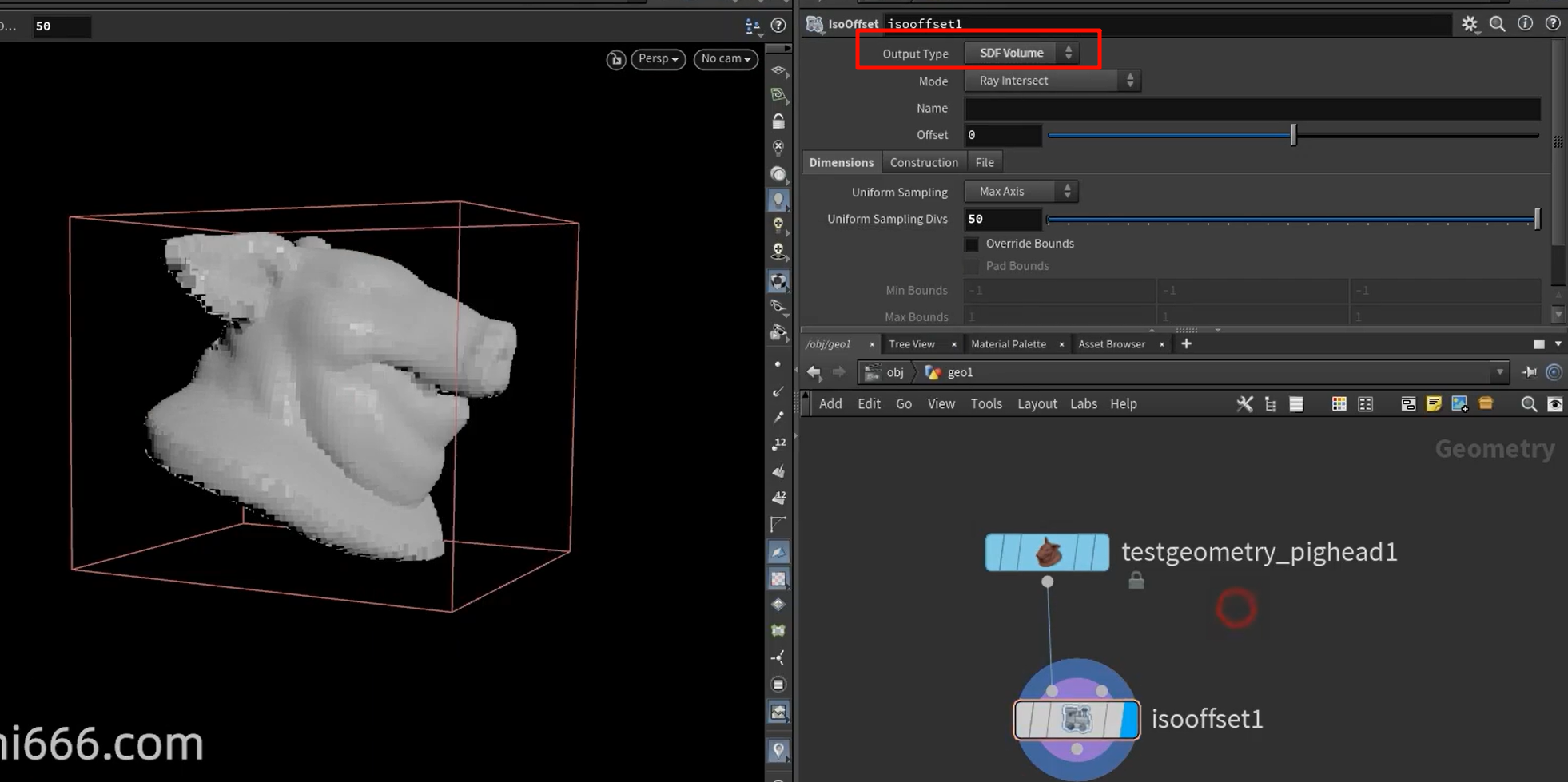
Houdini 中,点云常用于:
-
烟火粒子模拟输出;
-
流体模拟(Flip)中的粒子;
-
实例化参考;
-
粒子渲染等。
它没有面、没有拓扑,只是一堆带属性的点,可以很稀疏。
它不是点、也不是网格,而是一个稀疏 3D 网格结构(Sparse Volume Grid),常用于存:
-
密度场(Fog Volume);
-
SDF(Signed Distance Field);
-
速度场(Velocity Volume);
-
温度、燃料、力场等任意 float 或 vector 类型的 volume 属性。
✅ VDB 的特性:
-
占内存极小(仅存非零部分);
-
支持超大分辨率(如 2048³ voxel);
-
非常适合做体积布尔、光线穿透计算、模拟缓存等。
attribute 为什么分 float 和 vector?
在 Houdini 和 VDB 系统中,每个点或每个体素都可以带有属性,而属性有“类型”:
| 属性类型 | 表示内容 | 示例 |
|---|---|---|
| float | 单值(例如密度、温度) | @density, @temperature |
| vector | 三维向量(如速度、方向、颜色) | @v, @Cd, @force |
在 VDB 中:
-
一个 float 属性 会变成一个 标量体积(scalar field):每个 voxel 只有一个值;
-
一个 vector 属性 会变成 三通道体积(vector field):每个 voxel 有
x/y/z三个值(即 3 个 VDB)。
比如你要渲染 motion blur,@v(velocity)必须以 vector VDB 的形式提供给 renderer。
🔧 Volume Rasterize Attributes 的作用:
它把“点云 + 属性”转成“VDB + 体积属性”,你可以:
-
把粒子的密度
@density转为 Fog VDB → 用来做烟雾; -
把粒子的
@v转为 Vector VDB → 做速度场; -
把
@heat转成体积场 → 做温度控制。
“场”是一个数学/物理概念,简单定义如下:
一个场是一个函数,它定义了空间中每一点的某种属性值。
例如:
| 场类型 | 解释 |
|---|---|
| 标量场(Scalar Field) | 每个点上一个数值(温度、密度、压力) |
| 向量场(Vector Field) | 每个点上一个三维向量(风速、力、速度) |
| 张量场(Tensor Field) | 每个点上的高阶信息(惯性张量、应力) |
从这个角度来说,“场”并不局限于 Houdini、图形学,而是一个数学结构。
✅ VDB 是一种场的“离散化存储表达”方式。
它把连续空间离散为格点(voxel),并存储每个体素位置对应的场值。由于它是稀疏存储的,因此只保存非空(非零)的部分区域,节省内存。
“场是不是就是从点上统一取出某种属性?”
可以这么理解,但要加上一点 —— “空间插值”。
点云只有离散位置,而场的特点是:
-
定义在整个空间(理论上是连续的);
-
可以“在任意空间点”估算值(插值);
-
具有平滑性、连续性(可导、可计算梯度等);
所以,如果你用点云+插值函数(如高斯核、SPH、trilinear interpolation)来估算空间中的某个值,你实际上是在“重建一个场”。
SDF(Signed Distance Field)
Fog(雾场)适合表达“有无”、“浓淡”的概念 → 用于渲染烟火;
SDF(有符号距离场)适合表达“几何边界”、“内外关系” → 用于碰撞检测与形变控制。
SDF 是什么?
-
SDF 是一种 有符号的标量场;
-
每个 voxel 表示该点到表面的最短距离;
-
内部为负,外部为正,表面距离为零;
-
-
能直接用于 判定“是否在某物体内部”,以及 计算法线方向(∇SDF)。
✅ 碰撞检测的核心问题:
我们常需要判断:
-
粒子是否进入了某个区域(例如角色的身体);
-
一个物体是否和另一个发生了接触;
-
需要一个能高效、连续、近似地表达“物体边界”的结构。
SDF 的优点:
-
不依赖拓扑(不像 mesh);
-
计算接触、滑动、反弹方向非常自然(通过梯度);
-
可以用于物体变形、约束场、粘附等复杂交互。
所以:
SDF 是几何表达和交互计算中的黄金标准,非常适合碰撞、布尔、变形等任务。
假设你在做一个火球砸到地面后爆炸的效果:
| 作用 | 使用类型 | 原因 |
|---|---|---|
| 火球内部的密度变化 | Fog | 烟雾渲染依赖密度 |
| 火球碰到地面时的反弹/破碎判断 | SDF | SDF 可直接算出 penetration 和法线 |
| 烟雾渲染和体积光散射 | Fog | 密度 → 灯光穿透计算 |
| 粒子沿地形滑动 | SDF | 方向 = ∇SDF,接触面自然流动 |
同时用 Fog 和 SDF 混合控制视觉和物理,,SDF 计算法线和滑动,,把 mesh 转成 SDF

VDB 的“稀疏”结构意味着:
✅ 它并不是在 3D 空间中为每个体素都分配内存(dense grid),而是:
-
将整个 3D 空间划分为多个小块(通常是 8×8×8 的体素立方体);
-
只有你显式填入数据的块才会被真正“分配出来”;
-
没有值(为零或默认)的地方,完全不占用内存。
就像你说的,“只是包裹在表面或局部的那部分数据是真正存在的,其它地方是空的”。
想象你有一张地图要记录全国温度:
-
Dense Volume 是你每隔 1 米采样全国所有地方,无论有没有人;
-
VDB(稀疏 Volume) 是你只记录有城市的地方,其他都默认温度为 0。
❗但请注意一点:
⚠️ VDB 本身的结构并不是“只贴在表面上的网格”,而是:
✅ 它可以覆盖整个体积,但只在有数据的地方真正分配内存。
所以:
-
Fog VDB:虽然你看到的是烟雾“浮在表面”,其实它背后存的是稀疏分布在空间中的密度体素;
-
SDF VDB:在靠近模型表面区域才有值(比如距离在 ±10 内),其余区域全是默认值,没被写入;
-
渲染和碰撞时只需要那些“非空心”区域的数据就够了。


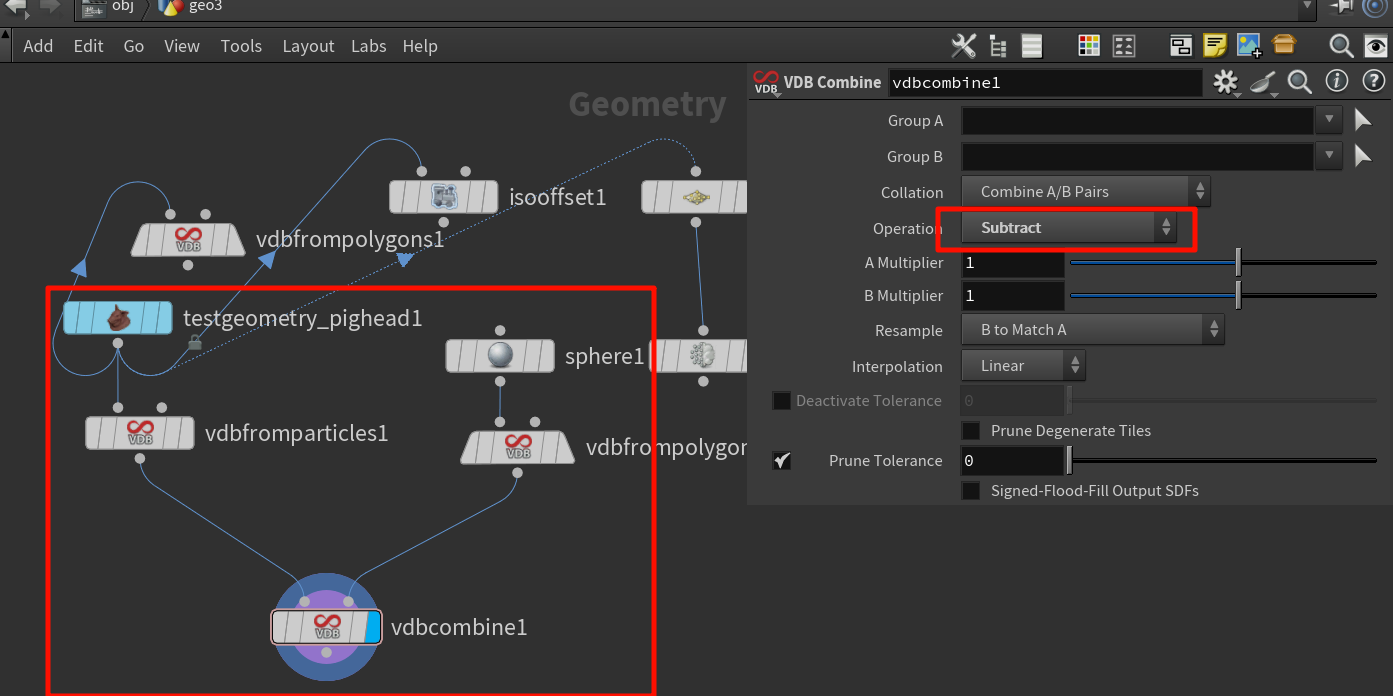
VDB Combine 节点中的 “域乘”、“域减”,其实是 volume field(体积场)之间的数学运算 —— 也可以叫做 field-wise multiply / subtract,它们的本质是:
对每个 voxel(体素)位置上两个场的值进行数学运算,形成新的场。
“域乘”(Multiply)是什么意思?
对两个 VDB 的每一个相同位置上的 voxel 值进行相乘。
假设有两个体积场:
-
A:密度场,值可能在 0~1;
-
B:mask 场,某区域为 1,其它地方为 0。
执行 A × B 得到的新 VDB 就是:
-
保留 B 为 1 的区域的 A 值;
-
B 为 0 的区域被清除(乘以 0)。
✅ 典型用途:
-
用体积遮罩裁剪另一个场;
-
用一个体积控制另一个体积的影响范围;
-
构建局部模拟区、限制范围。
对两个 VDB 在每一个 voxel 上做减法:
A - B
-
如果 A 是某个 SDF 场(比如角色的距离场);
-
B 是另一个 SDF 场(比如地板、障碍物);
-
那么
A - B的意思是:把 B 的区域从 A 中挖掉,也就是一个体积布尔减法(Boolean Subtraction)。
✅ 典型用途:
-
从一个 SDF 里挖空另一个物体(布尔差集);
-
做碰撞体积切割;
-
模拟凹痕、融合等几何效果。
-
VDB Merge就像是把多个图层“拼在一起”,重叠部分叠加; -
VDB Combine像 Photoshop 的图层“混合模式”中的Add,你可以控制行为逻辑与结果更细致。
| 对比维度 | VDB Merge |
VDB Combine |
|---|---|---|
| 📦 工作层级 | 数据级合并:直接并入 voxel block | 函数级操作:逐 voxel 数学运算(field-wise) |
| 🧠 使用语义 | “把这些 volume 合并到一起” | “将两个场通过某种数学关系计算新场” |
| ⚙️ 非重叠区域处理 | 自动保留/合并 | 可控制(默认是零、也可设定保留主场值等) |
| 🧪 操作灵活性 | 少(几种基本合并) | 强(加、乘、布尔、最小最大、SDF运算、Clamp 等几十种模式) |
| 🚫 SDF 操作支持 | 不适用于 SDF Union、Subtract 等布尔逻辑 | 专为 SDF 布尔而设计,有 union, intersection, subtract 等选项 |
| 🧩 可读性和维护性 | 更像是拼积木:结果不透明 | 操作逻辑更明确,可构建复杂 field 网络 |
| 如果你... | 用这个 |
|---|---|
| 只是把几个密度场结果合并输出 | VDB Merge |
| 想在某个 VDB 上进行数学调制(如加权、乘遮罩) | VDB Combine |
| 构建复杂体积控制逻辑(如 SDF 布尔) | VDB Combine |
| 快速拼接多个 volume,不关心内部值逻辑 | VDB Merge |
Attribute Transfer 节点(Houdini)
Attribute Transfer 本质是从 source 中“找样本”给 destination 的每个元素(点/面)
-
最终控制“传递效果”的,是 destination 的密度,而不是 source 的密度。
-
grid上只有 10 个点; -
sphere上有 1000 个点,带@Cd。
发生的事情是:
-
grid 上的每个点会在附近 10 或 1000 个 sphere 点中“找最近”;
-
找到了,就 transfer 属性;
-
因为 grid 点很少 → 整体看起来“效果粗糙”,分辨率低。
✅ 结论:
-
属性依然会传递,但受方分辨率太低,最终效果“稀疏”、“块状”;
-
不是损失信息,而是表达信息的能力太弱。
-
grid 上有 10000 个点;
-
sphere 上只有几个点,带
@Cd。
发生的事情是:
-
每个 grid 点会在稀少的 sphere 点中寻找“最近点”,如果设置了距离阈值(
Distance Threshold),远了就不传; -
多个 grid 点可能找到的是同一个 sphere 点;
-
这样会造成“扩散”效果 —— 一个 sphere 点影响周围很大一块区域。
✅ 结论:
-
会出现“模糊/扩散”效果,特别如果你开启了 Blend;
-
若 sample count 太小(如 1),容易产生边界断裂;
-
可以调整 kernel radius + blend width 让它更平滑。
以线的方式
Alpha注意是大写的A
ctrl加鼠标中键
点击单个parameter,把属性复原初始
Houdini 默认不会显示所有系统属性,而是显示以下这类:
| 类型 | 示例 | 显示条件 |
|---|---|---|
| Point Attributes | @P, @Cd, @v, @N, @id |
常见,可见 |
| Primitive Attributes | @name, @material, @shop_materialpath |
若存在,会显示 |
| Vertex Attributes | @uv, @tangentu, @tangentv |
如有贴图、UV,显示 |
| Detail Attributes | @time, @frame, @density_max 等 |
全局单值属性,常用于控制 |
你添加新属性后,会立即出现在这里。
Pack 节点通过创建一个轻量级的引用几何对象(Packed Primitive),将复杂几何变为一个“包裹引用+变换”的单元,实现内存节省与实例化可能性。
-
Pack 节点会将输入几何体封装成一个特殊类型的 primitive —— Packed Geometry Primitive
-
它本质上是:
-
一个指向原始几何体的数据引用(不是复制);
-
一个 4x4 的变换矩阵(transform matrix);
-
一些额外的 attribute(如 name、bounding box、type);
-
-
你可以认为是“以组件形式”组织几何体的一种机制。
不管你打不打包,最终 GPU 仍然需要知道顶点位置、法线、UV 等信息才能在 viewport 或 renderer 中正确绘制;
-
所以,从渲染输出结果的角度看,打包与否不会改变最终的视觉效果;
-
而且 Houdini 在 viewport 里确实能“显示出完整的几何”。
❗但关键是:“什么时候”去解包出这些信息,决定了性能的差异。
真正省性能的地方是 “延迟解算 + 内存共享 + 绘制代理”。
✅ 1. 延迟展开(deferred unpack)
-
Pack 的几何内容在 Houdini 内部不会立即展开(解算);
-
它只是存了一个引用 + transform,只有在真正“需要访问点数据”的时候(如你写
@P += 1,或 Boolean 操作)才会解包; -
这意味着 Houdini 的节点 cook(运行)时间极大减少;
-
尤其是在复杂网络中避免了每一帧重复读取/复制庞大几何数据。
➡️ 不是不渲染,而是“在真正渲染前最后一刻才准备好数据”。
GPU 端实例化
-
在 viewport 中,如果多个 packed primitive 引用同一 geometry,Houdini 直接使用 GPU instancing 技术:
-
把一个模型的 mesh 只上传一次;
-
然后通过不同的 transform matrix 来画出多个版本;
-
-
这和你“复制 1000 次几何体再渲染”完全不同,是 1 draw call → N instance;
-
这种方式极度节省 GPU 内存带宽与 draw call 开销。
➡️ 你看到的是完整模型,但背后只“渲染了 transform 指令 + 一份数据”。
GPU 端实例化
-
在 viewport 中,如果多个 packed primitive 引用同一 geometry,Houdini 直接使用 GPU instancing 技术:
-
把一个模型的 mesh 只上传一次;
-
然后通过不同的 transform matrix 来画出多个版本;
-
-
这和你“复制 1000 次几何体再渲染”完全不同,是 1 draw call → N instance;
-
这种方式极度节省 GPU 内存带宽与 draw call 开销。
➡️ 你看到的是完整模型,但背后只“渲染了 transform 指令 + 一份数据”。
绘制代理(display proxy)
-
Viewport 显示的 packed geometry 默认是 bounding box(或简化 mesh);
-
除非你设置
Display As = Full Geometry,否则 Houdini 会用更轻量的数据替代显示; -
这也是为什么 packed 模型数量成百上千时 viewport 仍然流畅的根本原因。
➡️ 你看到的是“看起来像完整的模型”,但实际上是优化后的可视代理。
只是不能改 @P 之类的属性好像意义不大?
❌ 不止,真正性能优化是来自解包时机 + 多实例复用 + 显示代理
so
❓ “我把一个 cube 用 pack 打包之后,它和原始的 cube 到底有什么区别?”
打包之后,这个模型不再是点、边、面构成的网格结构(detail),而是变成了一个“引用 + 变换”的包装体(packed primitive)。
| 维度 | 原始 cube(未 pack) | pack 之后的 cube |
|---|---|---|
| 类型 | 多个 polygon primitives | 1 个 packed primitive |
| 结构 | 8 点 + 6 面 + 24 顶点 | 1 个包裹对象,内部引用完整结构 |
| 可以访问点吗? | 可以:@P, @Cd, @N 等 |
❌ 不能直接访问点,需先 unpack |
primintrinsic 支持 |
❌ | ✅ 可以访问 transform、bounds 等 intrinsic |
| Copy to Points 表现 | 每次都复制整个 mesh | ✅ 实例化共享引用 |
| Viewport 绘制方式 | 每个点逐一绘制 | 可绘制为 bbox / full geometry / 点云 |
| 是否可变形 | ✅ 可以变形、编辑拓扑 | ❌ 不可直接编辑,需 unpack 才能操作 |
| 渲染性能 | 每次都上传全数据 | ✅ 支持实例化,减少 draw call |
| 内存占用 | 每个 cube 占一份数据 | 多个 pack 可共享同一几何引用 |
✅ 原始 cube:
-
是一个
GU_Detail对象,包含:-
点表(points)
-
面(polygon primitives)
-
顶点属性、法线、UV 等;
-
-
所有数据是展开的,每一个面都是独立可操作的。
✅ Pack 之后:
-
会被变为一个
GU_PrimPacked:-
存一个指向原始 cube 数据的指针(detail handle);
-
存一个本地变换矩阵(matrix4);
-
存 bounding box、name、material path 等附加信息;
-
-
外观还是 cube,但内部结构完全换了。
长按A,可以单独选中一个节点,整理上面的其他节点
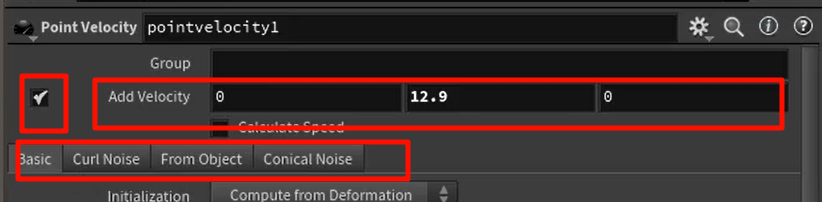
点进去,里面也有一个trail节点
Houdini 中默认创建的 Box(Cube)节点 —— box1 —— 是没有 UV 的
没有 uv 或 uv[0] 属性,因为它没有展开 UV、也没有贴图坐标。
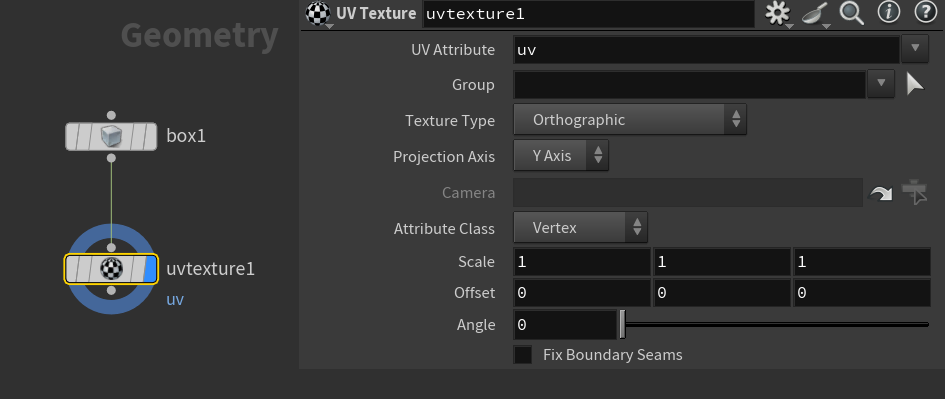
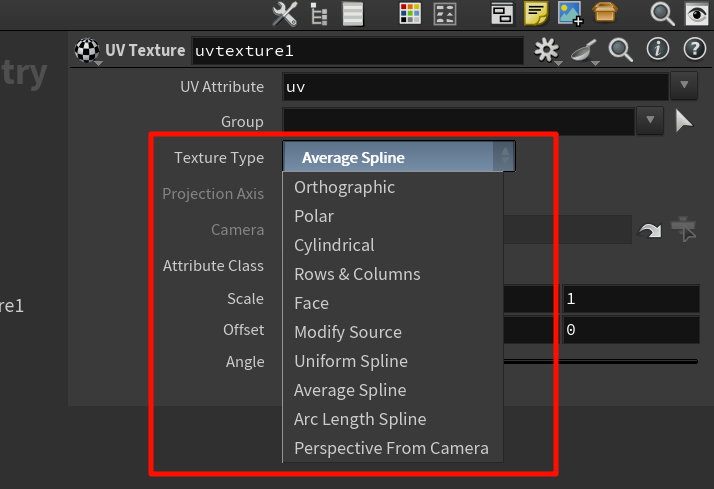
UV Texture 节点的本质作用:按某种规则(投影方式)在几何体上分布 2D UV 坐标,作为 vertex attribute uv 写入几何。
UV Texture 节点是:
为输入的几何体创建一套新的 UV 坐标(
uv属性)。
它不是用来加载或加工已有贴图,也不会“读取图像”。

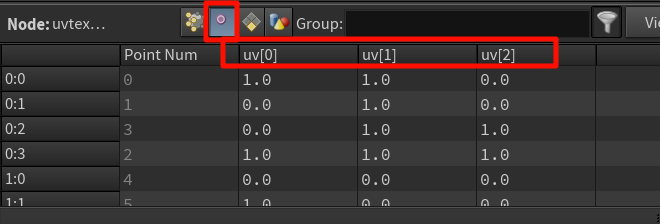
给vertex添加uv坐标
(在 point 或 vertex 上),供下游使用,例如渲染、UV 可视化、贴图绘制等
贴图的加载、应用,是材质(Shader)或 UV Quick Shade 负责的。
就像你画地图,UV Texture 是“把地球摊成地图”的过程,贴图是“在地图上画颜色”。
UV Texture 是赋予模型“坐标系统”的节点,
而贴图图像的使用是在之后的材质或视觉节点中完成的。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 20
20 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)