Qwen3-VL 评测结果合并对比
·
论文:Qwen3-VL Technical Report
地址:https://arxiv.org/pdf/2511.21631
本文将 Table 2/3/4(大中小三种尺寸模型)的评测结果合成一个,便于个人和社区对比不同尺寸的 Qwen3-VL 系列模型。
- 思考/非思考模型最佳得分,分别以粗体和 下划线 标注
- 标 * 的结果来自各自模型官方技术报告
- 标 + 的结果表示评测时用了 tool use
注:小模型系列没有测 We-Math,中小模型系列没有测 Multi-Modal Coding 任务,因此有几处是空白的。
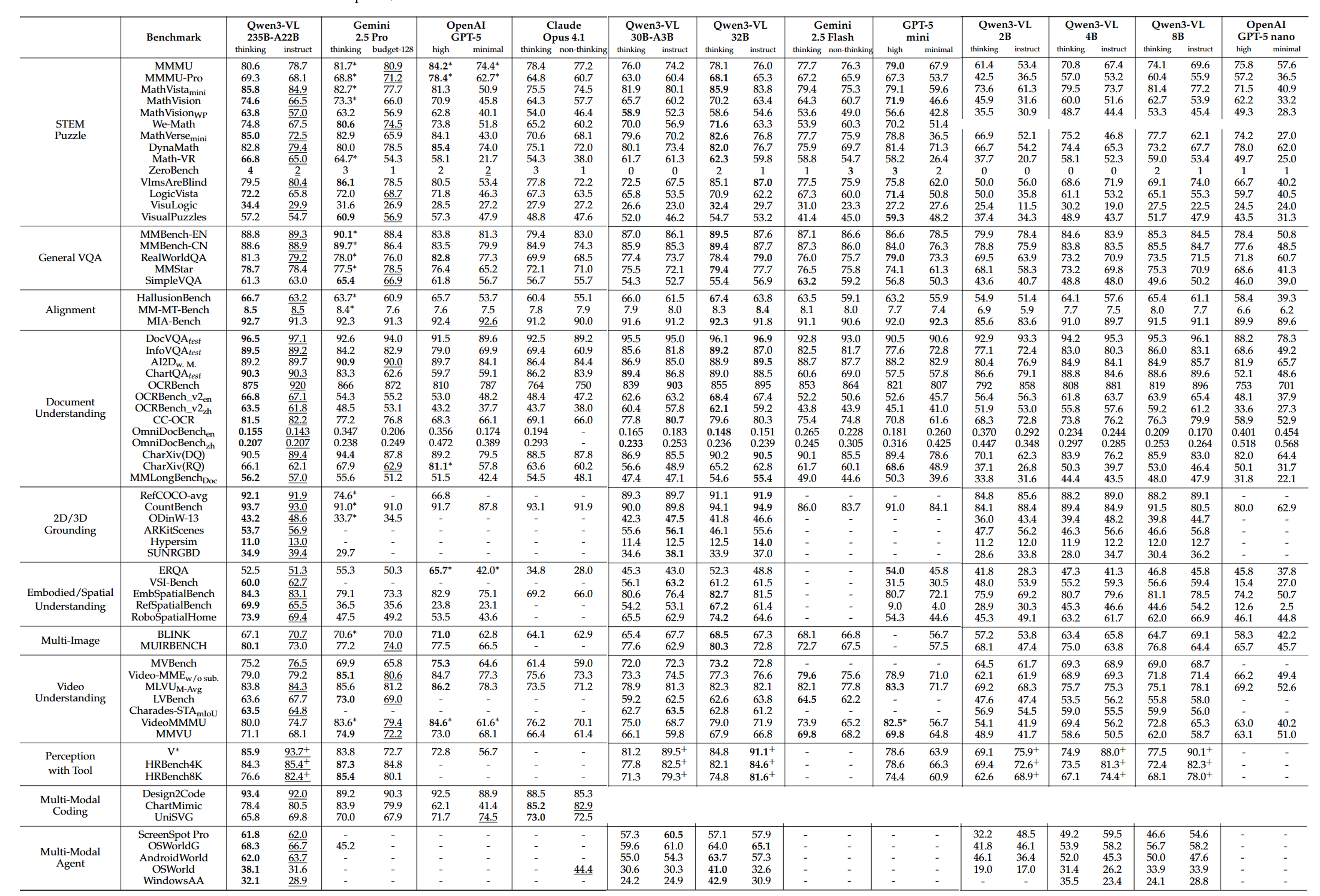
记录几个结论(仅供个人参考):
- 思考还是非思考?think 模型大部分评测集下优于非 think 模型,数学推理、复杂VQA优势显著,而且235B的thinking模式优势更大;非思考模型文档理解、工具感知方面更有优势;
- 30B选哪个?中等规模模型中,32b稠密模型优于30b-a3b moe模型;
- 大中号怎么选?235b moe 和 32b 模型对比。235B在复杂推理、视频理解、工具感知任务上优势明显;文档理解、多模态智能体性能接近,32B在OCR任务上甚至略有优势。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)