DualSG:双流显式语义引导的多变量时间序列预测框架
多变量时间序列预测在诸多应用中发挥着关键作用。近年来,已有研究探索将大型语言模型(LLMs)应用于多变量时间序列预测,以利用其推理能力。然而,许多方法将大型语言模型视为端到端预测器,这往往会导致数值精度损失,且迫使大型语言模型处理超出其设计初衷的模式。另一种思路是尝试在潜在空间中对齐文本模态与时间序列模态,但这类方法常面临对齐困难的问题。在本文中,我们提出不将大型语言模型视为独立预测器,而是将其作
Github: https://github.com/BenchCouncil/DualSG
摘要:多变量时间序列预测在诸多应用中发挥着关键作用。近年来,已有研究探索将大型语言模型(LLMs)应用于多变量时间序列预测,以利用其推理能力。然而,许多方法将大型语言模型视为端到端预测器,这往往会导致数值精度损失,且迫使大型语言模型处理超出其设计初衷的模式。另一种思路是尝试在潜在空间中对齐文本模态与时间序列模态,但这类方法常面临对齐困难的问题。 在本文中,我们提出不将大型语言模型视为独立预测器,而是将其作为双流框架中的语义引导模块。我们提出了DualSG——一种具有显式语义引导的双流框架,其中大型语言模型充当语义引导器,用于优化而非替代传统预测。 作为DualSG的一部分,我们引入了“时序描述”(Time Series Caption)——一种显式提示格式,它用自然语言总结趋势模式,为大型语言模型提供可解释的上下文,而非依赖文本与时间序列在潜在空间中的隐式对齐。我们还设计了一个描述引导的融合模块,该模块在显式建模变量间关系的同时,减少了噪声和计算量。 在来自不同领域的真实数据集上的实验表明,DualSG持续优于15个最先进的基线模型,证明了将数值预测与语义引导显式结合的价值。相关代码已公开于https://github.com/BenchCouncil/DualSG。
PART 1:研究背景与意义
1. 研究背景
-
多变量时间序列预测(MTSF)的重要性:是健康监测、天气预测、金融决策等领域的核心技术,需同时建模多个变量的时序动态与相互依赖。
-
传统方法局限:依赖单一数值模态(如ARIMA、Transformer、MLP),缺乏语义层面的全局趋势感知,对非平稳数据适应性差、可解释性低。
-
LLM 应用趋势:近年尝试用大型语言模型(LLM)提升MTSF推理能力,但现有范式存在根本性缺陷,未能充分发挥LLM价值。
2. 研究意义
-
解决“LLM用于MTSF”的核心痛点(数值精度损失、模态对齐困难),填补“数值建模”与“语义推理”的鸿沟。
-
提供可解释、鲁棒的长 horizon 预测方案,为跨领域MTSF(如能源、交通)提供新范式。
PART 2:当前研究综述
核心分类:LLM-based MTSF 两大范式
|
范式类型 |
核心思路 |
代表方法 |
关键缺陷 |
|
LLM-only 范式 |
将时序数据转文本(如数值序列),用LLM端到端预测 |
GPT4TS、AutoTimes |
1. 数值精度损失(连续值离散化);2. 任务不匹配(LLM设计用于NLP,非时序建模);3. 预测 horizon 受限(token预算有限) |
|
LLM-align 范式 |
在 latent space 对齐文本与时序模态(token级) |
TimeLLM、TimeCMA |
1. 模态对齐困难(扭曲时序关键特性);2. 隐式对齐缺乏可解释性;3. 易丢失预测核心信号 |
其他相关研究
-
传统MTSF:统计方法(ARIMA、STL)、深度学习(TimesNet、PatchTST),仅关注数值建模,泛化性与抗干扰能力弱。
-
时序描述(TSC):此前用于时序解释(如TRUCE、TSLM),未用于MTSF的语义引导。
PART 3:研究现存挑战
1. 数值精度与任务匹配问题
-
LLM-only 范式需将连续时序值转文本,导致精度丢失;LLM本质是NLP模型,强行用于时序预测存在“任务错配”。
2. 模态对齐困难
-
LLM-align 范式在 latent space 隐式对齐文本与时序,易扭曲时序的趋势、周期性等核心特性,破坏预测信号完整性。
3. 变量间依赖建模低效
现有通道融合方法(全注意力、静态聚类)在“扩展性(scalability)、表达性(expressiveness)、适应性(adaptability)”间难以权衡,且缺乏语义层面的依赖筛选(易拟合虚假关联)。
4. 长 horizon 预测一致性差
-
纯数值模型擅长短期细节建模,但缺乏全局趋势感知,长 horizon 预测易出现“趋势漂移”。
PART 4:文章主旨与主要内容
1. 核心主旨
提出 DualSG(双流显式语义引导框架),将LLM定位为“语义引导模块”而非“独立预测器”,通过“数值流+文本流”双轨协作,解决现有LLM-based MTSF的缺陷。
2. 主要内容(框架三大核心模块)
(1)数值预测流:抓细粒度时序信号
-
核心组件:多尺度自适应补丁(MAP)机制,通过“时间分区→多尺度patch生成→自适应重要性掩码”,编码不同分辨率的时序特征,保证数值精度。
(2)文本推理流:补粗粒度语义趋势
-
核心组件:时序描述生成(TSCG)模块,用Transformer编码器提取时序特征,结合文本模板生成TSC(如“序列从开始到结束逐渐下降,末端平稳”),再通过LLM编码为语义向量,提供趋势引导。
(3)双流融合模块:显式协同优化
-
SemFuse:基于TSC的语义相关性,筛选关键通道依赖,减少噪声;
-
STAM:时空注意力矩阵,动态平衡数值流(细节)与文本流(趋势)的贡献。
PART 5:文章创新点
创新点1:双流框架设计——解耦数值与语义,突破传统范式
-
首次将MTSF拆解为“数值建模(抓细节)”与“语义推理(补趋势)”,避免LLM直接参与预测,解决“数值精度损失”与“任务错配”问题。
创新点2:时序描述(TSC)——显式语义对齐,提升可解释性
-
提出结构化TSC(含方向、强度、时间过渡),替代 latent space 隐式对齐,实现“文本-时序”显式语义匹配;
-
TSC兼具“引导预测”与“可解释性”,用户可通过TSC理解模型趋势判断逻辑。
创新点3:语义感知融合模块——高效建模变量依赖与双流协同
-
SemFuse:用TSC语义相似度筛选通道,实现稀疏、可解释的通道融合(复杂度O(N),远低于全注意力O(N²));
-
STAM:随“时间+变量”动态调整双流权重(如长 horizon 预测更多依赖文本流),适应不同预测场景。
PART 6:技术路线与实验程序
1. 技术路线(流程图)
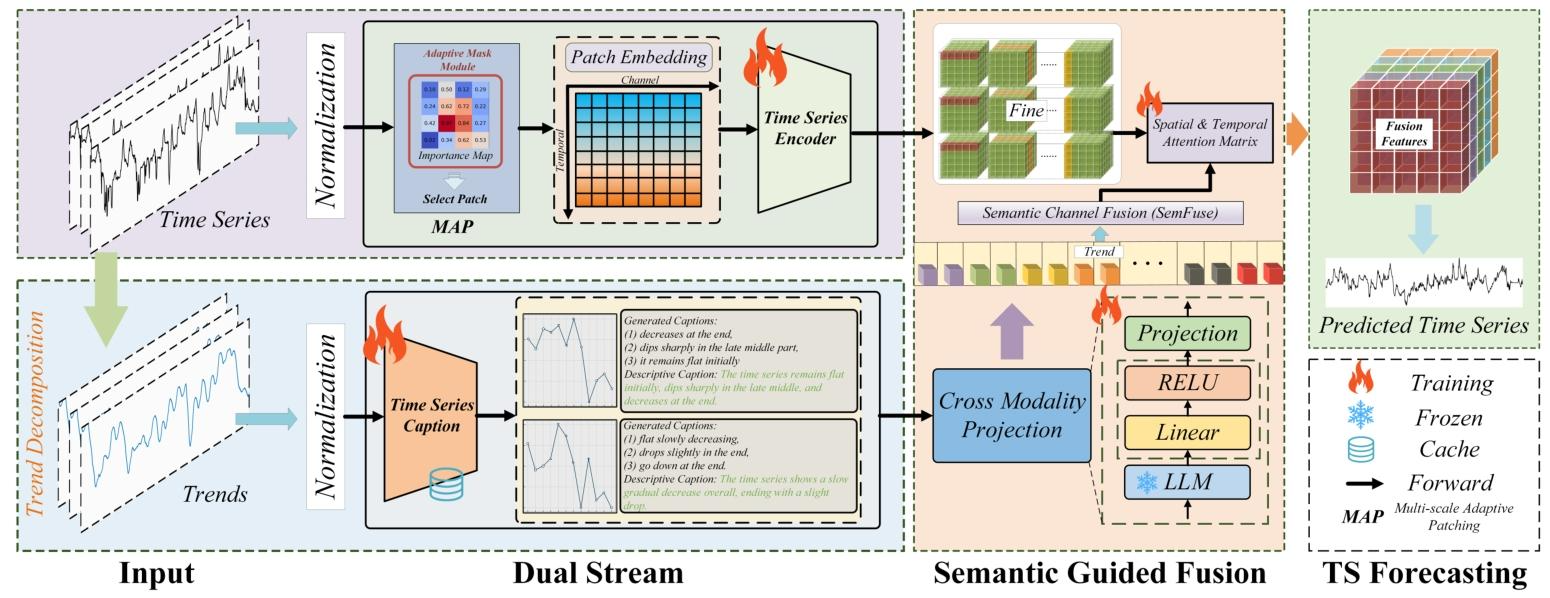
-
Input层
-
处理对象:原始时间序列(Time Series)和经趋势分解(Trend Decomposition)后的趋势序列(Trends)。
-
操作:均通过“Normalization”完成数据尺度统一,为后续建模奠定基础。
-
-
Dual Stream层(双流核心)
-
数值预测流(上半部分)
-
核心模块:MAP(多尺度自适应补丁),包含“Adaptive Mask Module”(自适应掩码,筛选关键时序补丁)和“Patch Embedding”(补丁嵌入,对时间、通道维度特征编码)。
-
后续流程:经“Time Series Encoder”提取数值层面的细粒度时序特征。
-
-
文本推理流(下半部分)
-
核心模块:“Time Series Caption”,生成时序语义描述(如“序列末端下降,中后段骤降,初始平稳”),为语义引导提供文本载体。
-
-
-
Semantic Guided Fusion层(语义引导融合)
-
关键组件:“Semantic Channel Fusion(SemFuse)”(基于语义的通道融合,减少噪声依赖)、“Spatial & Temporal Attention Matrix”(时空注意力,动态权衡特征权重)、“Cross Modality Projection + LLM”(跨模态投影结合大型语言模型,实现数值与语义特征的模态对齐)。
-
-
TS Forecasting层(时间序列预测输出)
-
流程:融合特征(Fusion Features)经处理后输出“Predicted Time Series”;同时标注“Training(训练)”“Frozen(冻结)”“Cache(缓存)”等流程细节,明确模块运行机制。
-
该架构通过“数值流建模细粒度时序细节 + 文本流补充粗粒度语义趋势”的双流协同,解决了传统LLM应用于时间序列预测时的数值精度损失、模态对齐困难、长周期预测趋势漂移等痛点,同时提升了预测的可解释性与鲁棒性,适用于健康监测、金融、能源等多领域的多变量时间序列预测场景。
2. 实验程序
(1)数据集
-
12个跨领域真实数据集:ETT系列(ETTh1/2、ETTm1/2)、Weather、Traffic、Electricity、Solar-Energy等。
(2)基线模型
-
LLM-based:CALF、TimeLLM、GPT4TS;
-
Transformer-based:PatchTST、iTransformer、FEDformer、DUET;
-
CNN/MLP-based:TimesNet、MICN、DLinear、TimeMixer。
(3)实现细节
-
框架:PyTorch 2.0.1;优化器:Adam(余弦退火学习率);损失函数:L1损失;
-
硬件:4×NVIDIA A800 GPU(80GB);评价指标:MSE(均方误差)、MAE(平均绝对误差)。
PART 7:实验结果与讨论
1. 主结果:超SOTA性能
-
跨所有数据集击败15个基线:比LLM-based最佳基线CALF平均降MSE 11.3%、MAE 9.8%;在Solar-Energy数据集降MSE 40.7%(0.192 vs 0.324);
-
非平稳数据优势显著:比FEDformer(非平稳时序专用模型)在Traffic降MSE 35.1%、Weather降26.2%。
2. 消融实验(验证模块必要性)
|
模型变体 |
ETTm2(MSE) |
Weather(MAE) |
结论 |
|
DualSG(全量) |
0.254 |
0.260 |
基准性能 |
|
w/o TSCG |
0.264 |
0.268 |
TSC语义引导可提升非平稳数据鲁棒性 |
|
w/o MAP |
0.279 |
0.276 |
多尺度自适应补丁保证高频数据精度 |
|
w/o SemFuse |
0.258 |
0.263 |
语义通道融合减少噪声干扰 |
3. 关键分析
-
Prompt对比:TSC(本方法)在MSE和最佳结果次数上均优于Domain、Timestamp等其他Prompt类型;
-
STAM可视化:预测长度越长(如720步),STAM越关注高信息通道,且文本流权重提升(弥补数值流趋势漂移)。
PART 8:文章结论
1. 核心结论
-
DualSG通过“双流框架+显式语义引导”,有效解决了LLM-based MTSF的“数值精度损失”与“模态对齐困难”问题,在12个跨领域数据集上超越SOTA;
-
时序描述(TSC)与语义融合模块(SemFuse、STAM)是性能提升的关键,验证了“数值细节+语义趋势”协同的价值。
2. 局限性
-
双流设计增加少量计算开销;
-
TSCG的自回归生成机制可能降低推理速度(需轻量化优化)。
3. 未来方向
-
扩展至更复杂的多模态时序数据(如结合图像、传感器文本的时序预测);
-
优化TSCG生成效率,进一步提升长 horizon 预测的实时性。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)