Coze+飞书+DeepSeek,爆火视频文案二创工作流,喂饭式教学!
大家好,跟着老黄学AI!这一期,我给大家分享一个比较简单,又很实用的工作流,作用是批量获取某音爆款视频的文案后,批量二创!!
大家好,跟着老黄学AI!
这一期,我给大家分享一个比较简单,又很实用的工作流,作用是批量获取某音爆款视频的文案后,批量二创!!
拆解思路
1.根据自己的关键词喜好,找到该关键词下的爆款视频。
2.解析视频,对视频进行音频转文字
3.文案保存到飞书上
4.利用飞书上的DeepSeek插件,一键改写
流程设计思路
整体流程如下
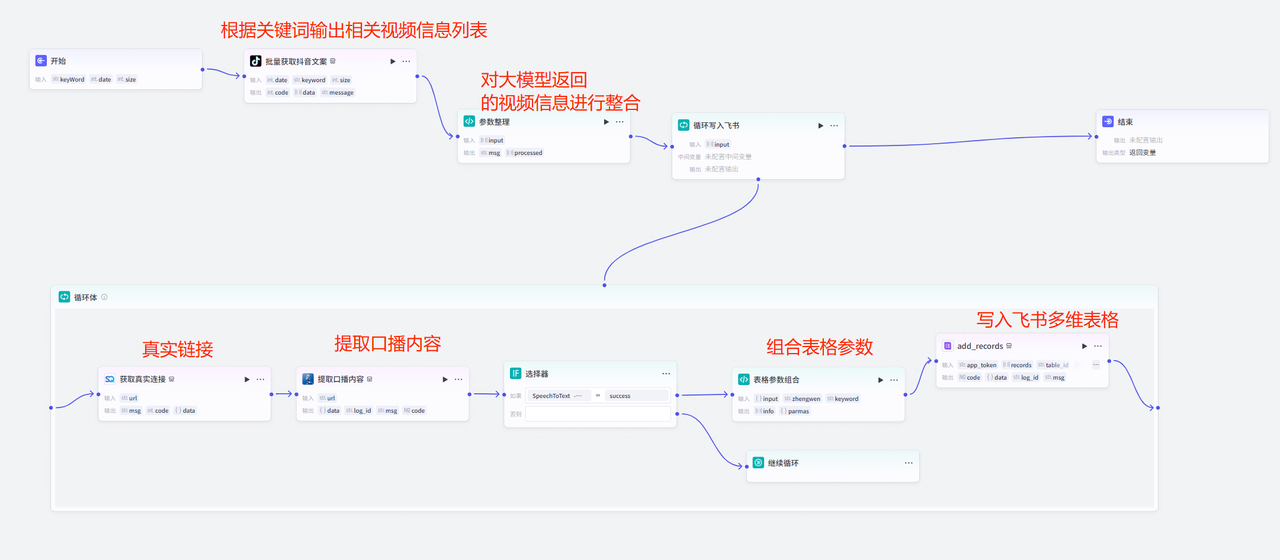
流程拆解
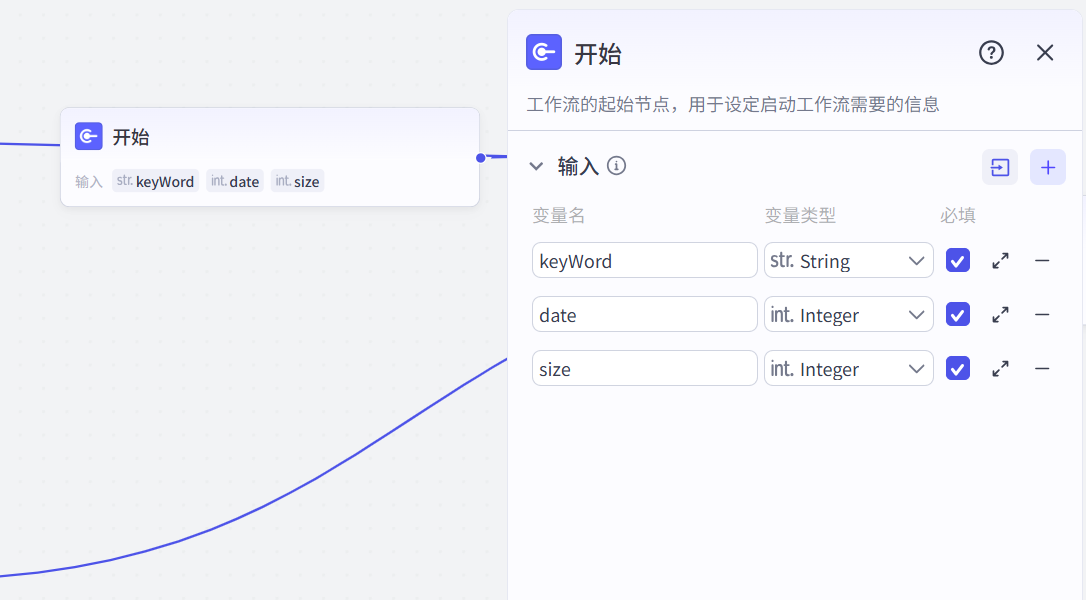
(1)开始节点,设置三个输入:关键字,视频发布期限(最多7天内),获取数量(最大50)
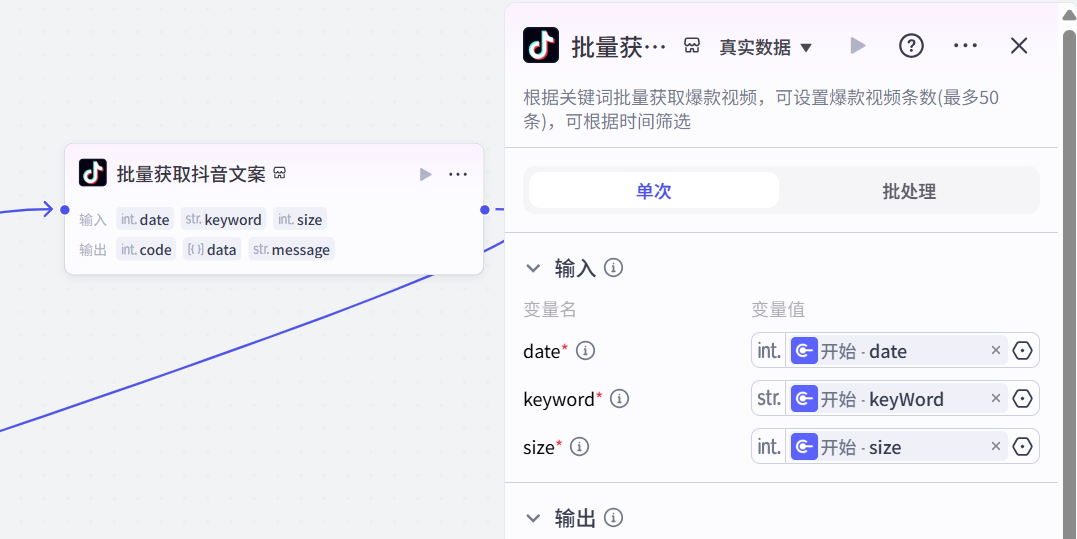
(2)利用插件,找出关键词下的爆火视频,用法就不介绍了,非常简单,看下参数就知道了。
(3)代码节点,主要作用是拼接的播放地址、时长单位改为秒取证、把发布时间的时间戳,改为正常的时间格式。
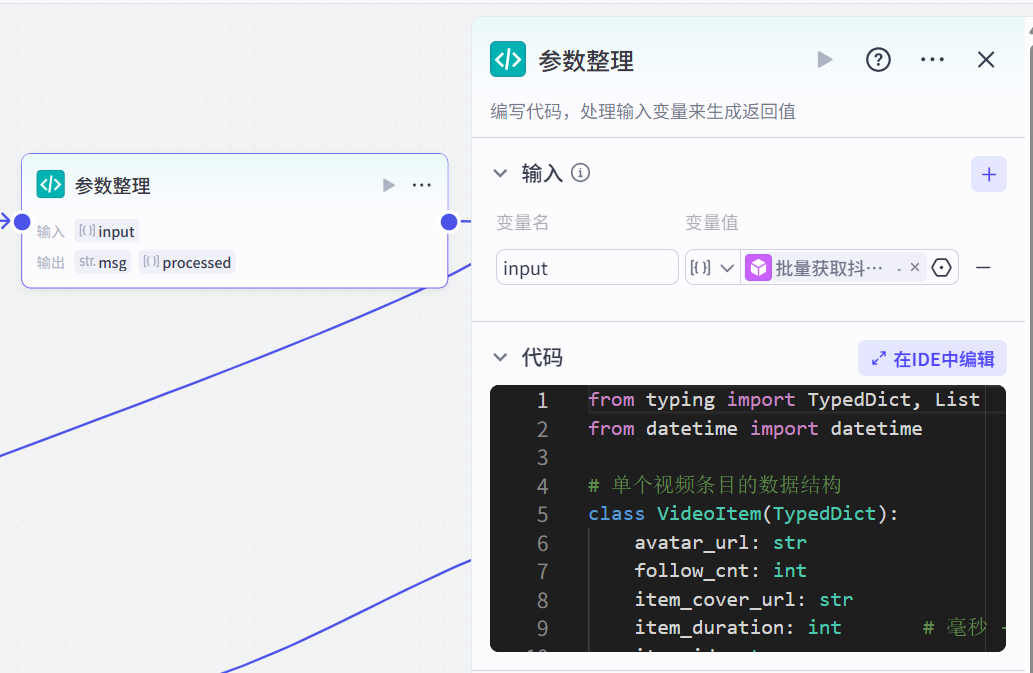
参考代码如下:
async def main(args: Args) -> Output:
params = args["params"]
videos = params["input"]
for video in videos:
# 构建 video_url
video["video_url"] = f"https://www.douyin.com/video/{video['item_id']}"
# 将 item_duration 从毫秒转为秒
video["item_duration"] = video["item_duration"] // 1000
# 格式化 publish_time(判断是否是毫秒时间戳)
ts = video["publish_time"]
if ts > 1e12: # 判断是否是毫秒
ts = ts / 1000
video["publish_time_fmt"] = datetime.fromtimestamp(ts).strftime('%Y-%m-%d %H:%M:%S')
ret: Output = {
"msg": "成功",
"processed": videos
}
return ret
这里要注意的是,这个代码节点输出的,跟获取抖音文案的输出基本一样,就是更改了代码里面的三个字段内容!
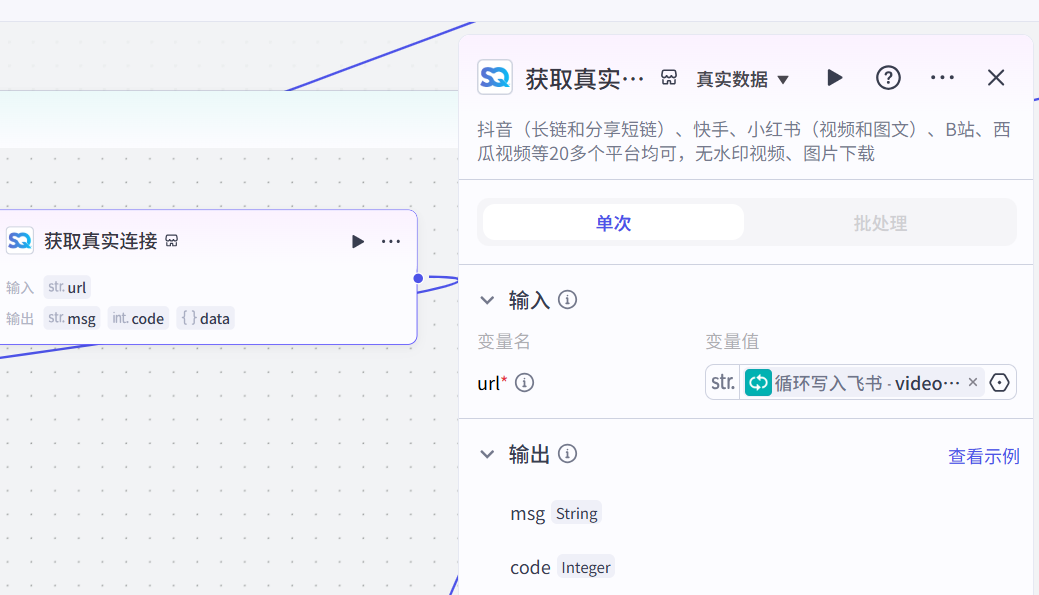
(4)循环体(获取真实链接-提取口播文案-判断是否有文案,有就写入飞书,没有就继续循环)
获取真实链接:
提取口播文案:
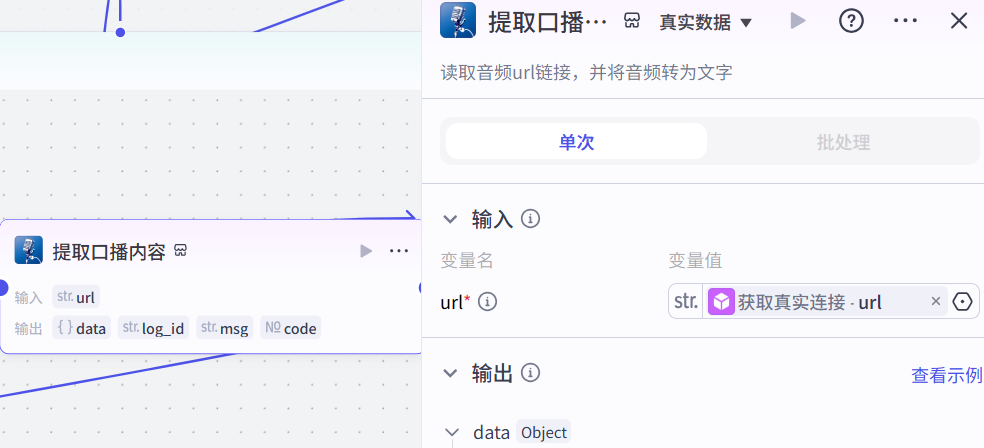
注意,如果视频有文案,提取成功,msg返回是sucess;文案在data里面的text
表格参数整合:
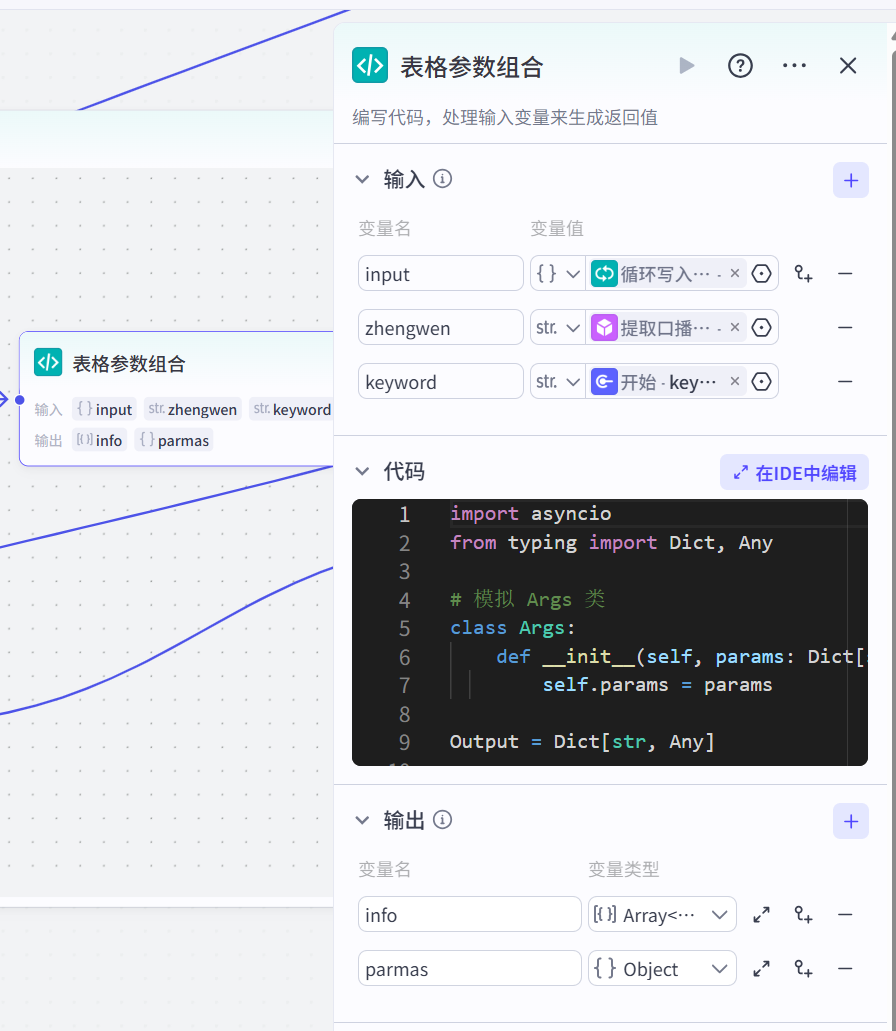
参考代码:
# 自动适配结构的主函数
async def main(args: Args) -> Output:
try:
# 自动判断是否多包一层 params
if "input" in args.params:
params = args.params
elif "params" in args.params and "input" in args.params["params"]:
params = args.params["params"]
else:
raise KeyError("input")
input_data = params["input"]
converted_list = [{
"fields": {
"视频标题": input_data.get("item_title", ""),
"视频正文": params.get("zhengwen", ""),
"视频链接": input_data.get("video_url", ""),
"播放量": input_data.get("play_cnt", 0),
"关键词": params.get("keyword", ""),
"点赞数": input_data.get("like_cnt", 0),
"粉丝数": input_data.get("follow_cnt", 0),
"视频时长": input_data.get("item_duration", 0),
"视频编号": input_data.get("item_id", ""),
"博主": input_data.get("nick_name", ""),
"发布时间": input_data.get("publish_time_fmt", "")
}
}]
return {
"info": converted_list,
"message": "转换成功",
"code": 0
}
except Exception as e:
return {
"info": [],
"message": f"Error in main: {str(e)}",
"code": -1
}写入飞书多维表格:
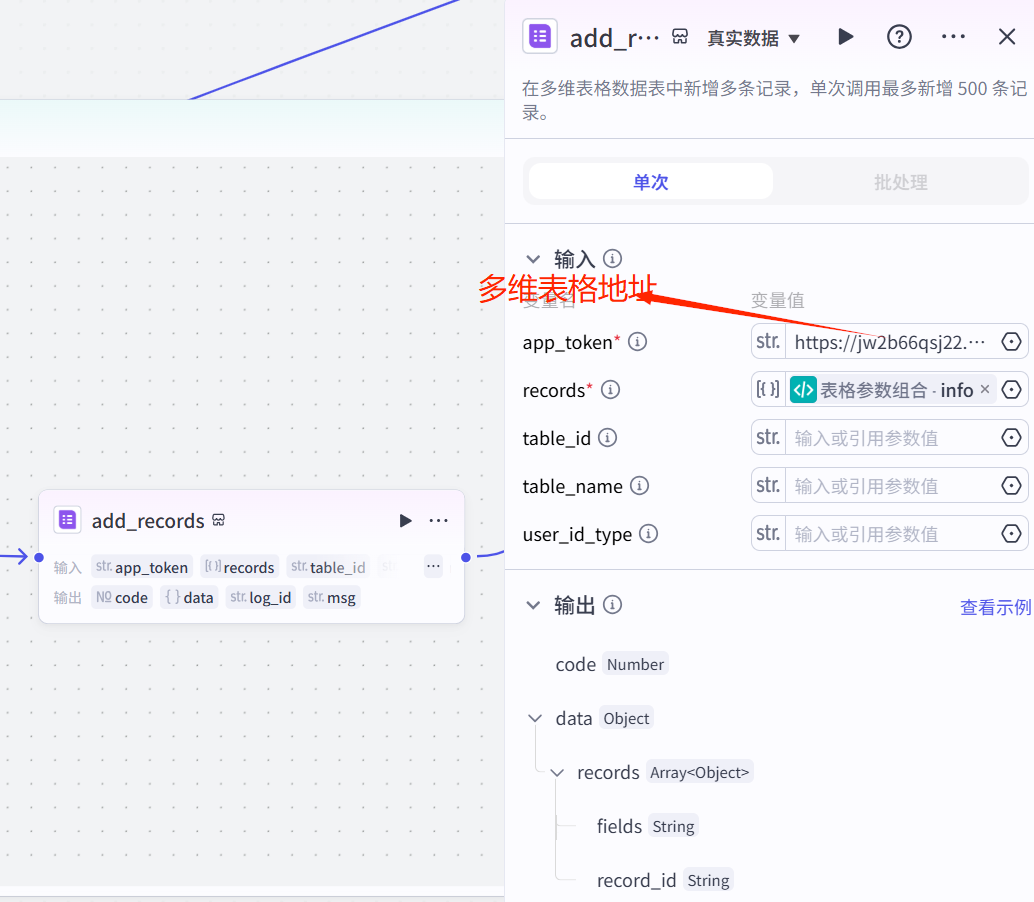
(5)在飞书增加文案改写列,增加的时候,选择"探索字段捷径",然后选择DeepSeek,然后写提示词
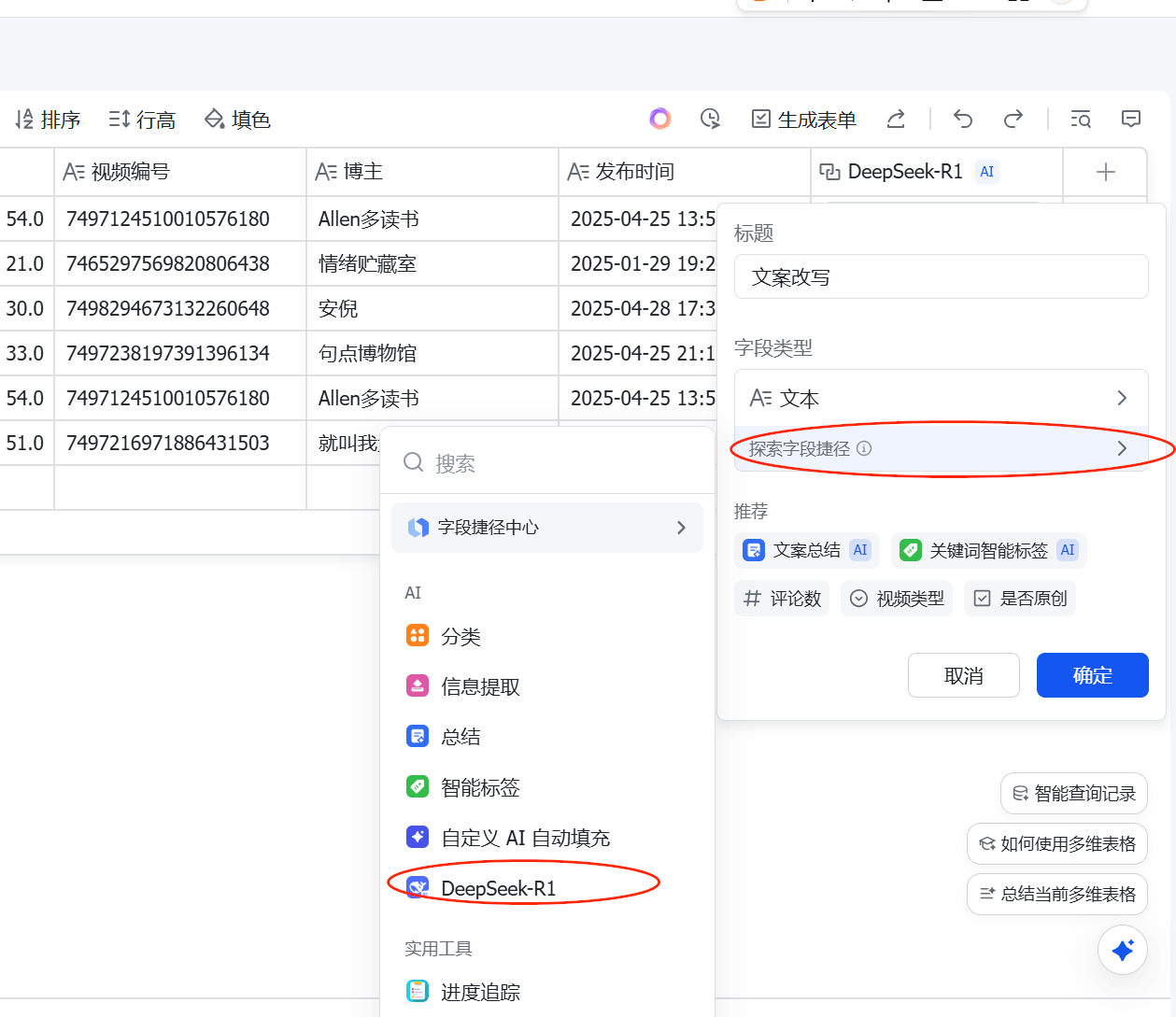
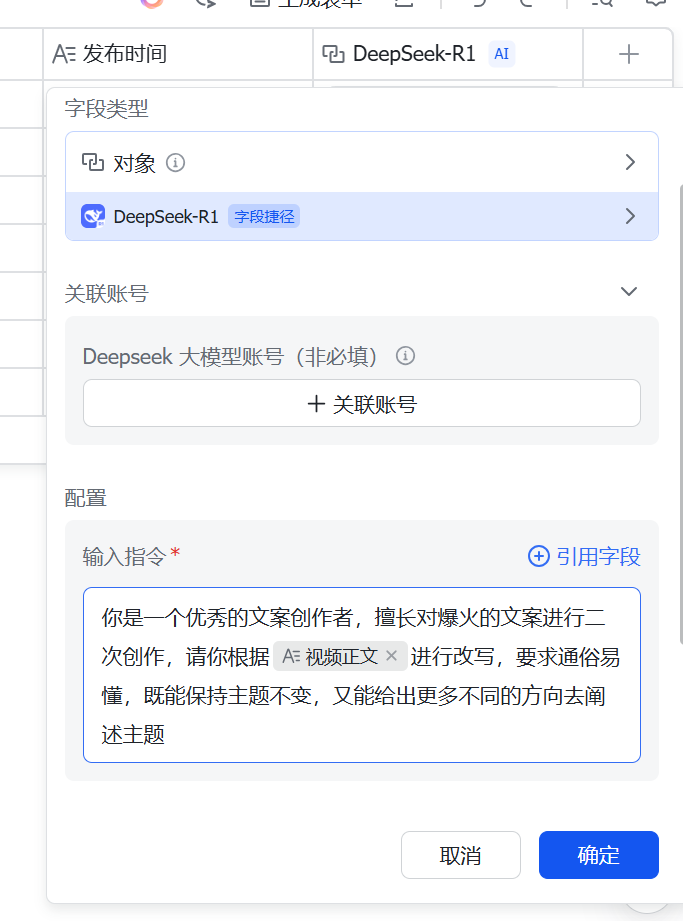
点击确定之后,DeepSeek就会开始工作了
到了这里了,这个流程的拆解基本基本就结束了。
其实细心又想复刻的同学,应该已经发现了,工作流至少有两处可以优化的地方:
1.飞书的链接应该作为开始的输入参数
2.关键词可以通过读取飞书,然后通过智能体的定时功能,每天定时读取关键词,产出文案,这样就更方便了
以上就是本期的全部内容!小伙伴如果想要复刻,欢迎关注我的同名小绿书,找我一起交流讨论,等你喔!
更多案例试用:扣子

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)