Pytorch版本的FunASR适配华为昇腾910B(保姆级教程)
摘要:本文详细介绍了在华为昇腾平台上配置PyTorch训练环境的完整流程,包括驱动/固件安装、CANN工具包部署以及Python环境搭建。主要内容涵盖:1)从昇腾社区下载对应版本的驱动和固件;2)通过命令行安装NPU驱动、固件及CANN组件;3)配置Python3.10环境并安装torch-npu等依赖包;4)提供CPU/NPU两种模式下的语音识别性能测试代码,包含模型加载、推理执行和结果输出示例
华为环境的配置
可以参考链接手把手教你在昇腾平台上搭建PyTorch训练环境-云社区-华为云进行华为硬件环境的配置,也可参照以下步骤
首先去官网社区版-固件与驱动-昇腾社区下载你显卡相对应的驱动和固件版本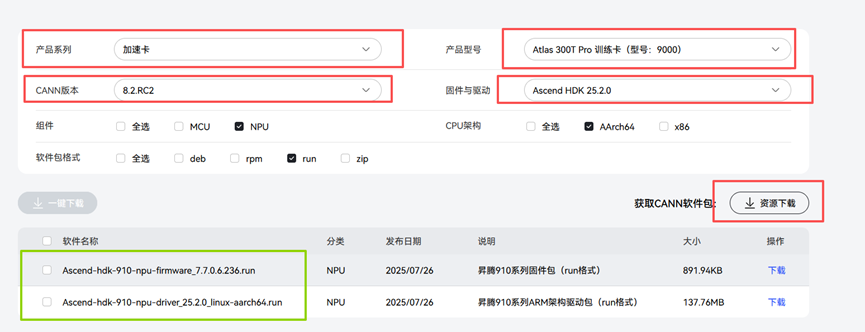
然后再点击资源下载,下载cann配套插件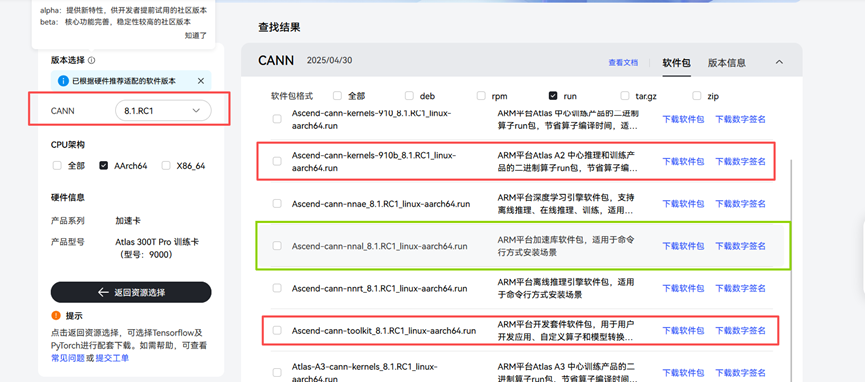
安装完toolkit之后还要再安装kernels, nnal可选择安装。
a.为软件包增加可执行权限。
chmod +x Ascend-hdk-910-npu-driver_25.2.0_linux-aarch64.run
chmod +x Ascend-hdk-910-npu-firmware_7.7.0.6.236.run
b.安装驱动。
./Ascend-hdk-910-npu-driver_25.2.0_linux-aarch64.run --full --install-for-all
默认安装路径为“/usr/local/Ascend”,出现类似如下回显信息,说明安装成功。
Driver package installed successfully!
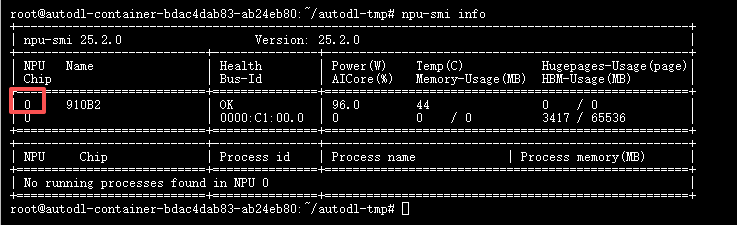
可以通过执行npu-smi info命令查看,出现显卡信息,说明驱动加载成功
c.安装固件。
./Ascend-hdk-910-npu-firmware_7.7.0.6.236.run --full
出现类型如下回显信息,说明安装成功。
Firmware package installed successfully! Reboot now or after driver installation for the installation/upgrade to take effect
驱动固件安装完成后,重启系统。
reboot
d.安装cann-toolkit
添加可执行权限
chmod +x Ascend-cann-toolkit 8.1.RC1 linux-aarch64.run
校验软件包的一致性和完整性
./Ascend-cann-toolkit 8.1.RC1 linux-aarch64.run --check
执行安装命令
./Ascend-cann-toolkit 8.1.RC1 linux-aarch64.run --install --install-for-all
e.安装cann-kernels
chmod +x Ascend-cann-kernels-910b_8.1.RC1_linux-aarch64.run
./Ascend-cann-kernels-910b_8.1.RC1_linux-aarch64.run –-install
最后执行下:
source /usr/local/Ascend/ascend-toolkit/set_env.sh
toolkit安装之后路径在/usr/local/Ascend/ascend-toolkit/
kernels安装后会多一个文件夹/usr/local/Ascend/ascend-toolkit/8.1.RC1/opp_kernel,但是实际文件在opp文件夹里

nsnal安装后路径在/usr/local/Ascend/naals

在bashrc中添加
source /usr/local/Ascend/ascend-toolkit/set_env.sh
source /usr/local/Ascend/ascend-toolkit/set_env.sh
source /usr/local/Ascend/nnal/atb/set_env.sh --cxx_abi=1
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/Ascend/nnal/atb/latest/atb/cxx_abi_0/lib:/usr/local/Ascend/nnal/atb/latest/atb/cxx_abi_0/examples:/usr/local/Ascend/nnal/atb/latest/atb/cxx_abi_0/tests/atbopstest:/usr/local/Ascend/ascend-toolkit/latest/tools/aml/lib64:/usr/local/Ascend/ascend-toolkit/latest/tools/aml/lib64/plugin:/usr/local/Ascend/ascend-toolkit/latest/lib64:/usr/local/Ascend/ascend-toolkit/latest/lib64/plugin/opskernel:/usr/local/Ascend/ascend-toolkit/latest/lib64/plugin/nnengine:/usr/local/Ascend/ascend-toolkit/latest/opp/built-in/op_impl/ai_core/tbe/op_tiling:/usr/local/Ascend/driver/lib64/common/:/usr/local/Ascend/driver/lib64/driver/
或者
source /usr/local/Ascend/ascend-toolkit/set_env.sh
export ASCEND_BASE=/usr/local/Ascend
export LD_LIBRARY_PATH=$ASCEND_BASE/driver/lib64:\
$ASCEND_BASE/driver/lib64/common:\
$ASCEND_BASE/driver/lib64/driver:\
$ASCEND_BASE/driver/tools/hccn_tool/:/lib64:\
$LD_LIBRARY_PATH
python环境的配置
python版本为3.10
torch 2.5.1
torch-npu 2.5.1
torchaudio 2.5.1
torchvision 0.20.1
funasr 1.2.6
pip install torch==2.5.1
pip install torch_npu==2.5.1
pip install torchaudio==2.5.1
pip install funasr==1.2.6
可以使用以下命令查看环境
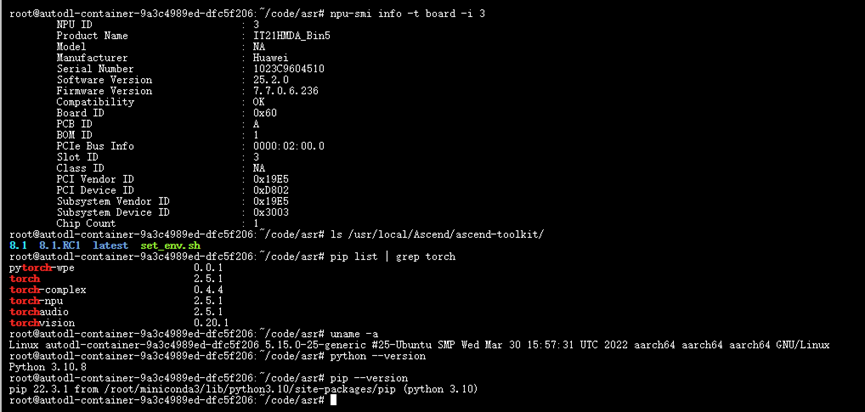
npu-smi info -t board -i 0 #0还是1、2或者3取决于执行npu-smi info后npu Chip的值
测试torch_npu是否可用
import torch
import torch_npu
print(f"npu is {torch_npu.npu.is_available()}")
print(f"npu num is {torch_npu.npu.device_count()}")
a=torch.ones(3,4).npu()
print(a+a)
输出
npu is True
npu num is 1
tensor([[2., 2., 2., 2.],
[2., 2., 2., 2.],
[2., 2., 2., 2.]], device='npu:0')
性能测试
cpu性能测试代码
import os
import re
import argparse
from funasr import AutoModel
import time
# 解析参数
parser = argparse.ArgumentParser()
parser.add_argument('audio_file', type=str)
args = parser.parse_args()
load_start_time = time.time()
# 1. 初始化模型 (关键:download_model=True 自动下载)
model = AutoModel(
model="damo/SenseVoiceSmall",
vad_model="iic/speech_fsmn_vad_zh-cn-16k-common-pytorch",
punc_model="iic/punc_ct-transformer_cn-en-common-vocab471067-large",
device="cpu",
disable_update=True,
download_model=True # 自动下载模型
)
load_spend_time = time.time() - load_start_time
print(f"load model end------- spend time = {load_spend_time:.2f}S")
#模型预热
#model.generate(input="asr_example_zh.wav")[0]["text"]
# 2. 执行识别
start_time = time.time()
print("start----------")
result = model.generate(input=args.audio_file)[0]["text"]
spend_time = time.time() - start_time
print(f"end------- spend time = {spend_time:.2f}S")
result = re.sub(r'<\s*\|\s*.*?\s*\|\s*>', '', result).lstrip()
# 3. 输出结果
print("识别结果:", result)
执行测试
python test.py asr_example_zh.wav
模型下载后的默认存储路径为:/root/.cache/modelscope/hub/models
下载完成后可将模型移动到当前目录下,指定绝对路径,并设置download_model=False,可提升模型加载速度。
model = AutoModel(
model="/usr/local/shh/code/asr/models/damo/SenseVoiceSmall",
vad_model="/usr/local/shh/code/asr/models/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch",
punc_model="/usr/local/shh/code/asr/models/iic/punc_ct-transformer_cn-en-common-vocab471067-large",
device="cpu",
disable_update=True,
download_model=False # 自动下载模型
)
npu性能测试代码
关于torch由GPU迁移到NPU可参考华为官方链接(推荐)自动迁移-Ascend Extension for PyTorch7.2.0-昇腾社区
import os
import re
import argparse
from funasr import AutoModel
import torch
import torch_npu # 导入昇腾插件
# 自动迁移:将cuda API映射为npu API
from torch_npu.contrib import transfer_to_npu
import time
print("PyTorch版本:", torch.__version__)
print("PyTorch版本", torch.__file__)
print("NPU设备数量:", torch_npu.npu.device_count())
print("当前NPU设备:", torch_npu.npu.get_device_name(0))
print("Cuda available:", torch.cuda.is_available())
# 解析参数
parser = argparse.ArgumentParser()
parser.add_argument('audio_file', type=str)
args = parser.parse_args()
load_start_time = time.time()
print("load start----------")
# 1. 初始化模型 (关键:download_model=True 自动下载)
model = AutoModel(
model="/usr/local/shh/code/asr/models/damo/SenseVoiceSmall",
vad_model="/usr/local/shh/code/asr/models/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch",
punc_model="/usr/local/shh/code/asr/models/iic/punc_ct-transformer_cn-en-common-vocab471067-large",
device="npu:0",
disable_update=True,
download_model=False # 自动下载模型
)
load_spend_time = time.time() - load_start_time
print(f"load model end------- spend time = {load_spend_time:.2f}S")
#模型预热
model.generate(input="asr_example_zh.wav")[0]["text"]
# 2. 执行识别
start_time = time.time()
print("start----------")
result = model.generate(input=args.audio_file)[0]["text"]
spend_time = time.time() - start_time
print(f"end------- spend time = {spend_time:.2f}S")
result = re.sub(r'<\s*\|\s*.*?\s*\|\s*>', '', result).lstrip()
# 3. 输出结果
print("识别结果:", result)
执行测试
python nputest.py asr_example_zh.wav

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)