TimeHF: Billion-Scale Time Series Models Guided by Human Feedback
《京东提出时间序列大模型PCLTM与TPO强化学习框架》研究针对现有时间序列模型在扩展性和泛化能力上的不足,提出创新解决方案。通过构建包含2100亿数据点的大型数据集并建立严格的质量控制标准,提出基于补丁卷积的PCLTM模型处理复杂时序依赖关系。首次设计Time-series Policy Optimization(TPO)强化学习框架,利用算法自动生成预测对比对代替人工标注,实现时间序列模型与专
单位:京东集团(JD.com)
作者:齐永志、胡浩
论文链接:arxiv.org
读前必看:本篇只是对论文进行简单介绍详细解刨可看飞书链接可以在有疑问的地方标注探讨:
Docs
https://h1sy0ntasum.feishu.cn/docx/XoaSdRXFIogEXHxMXvCcD20Fn3b?from=from_copylink
研究动机
-
时间序列模型的局限性:现有的时间序列神经网络在实际应用中表现良好,但存在扩展性有限、泛化能力差和零样本性能不佳等问题。
-
大型时间序列模型(LTM)的需求:受大型语言模型(LLM)成功的启发,研究者们渴望开发大规模的时间序列模型(LTM)来解决上述问题,但现有方法在训练复杂性、适应人类反馈和预测准确性方面存在困难。
-
人类反馈的重要性:在复杂任务和动态环境中,直接利用人类反馈优化模型行为的强化学习方法(如RLHF)展现出优越的性能,然而,将RLHF应用于时间序列预测模型还未有有效的方法。
创新点(贡献)
-
构建大规模时间序列数据集:提出了构建大型、高质量时间序列数据集的标准,包括数据增强、数据平衡、多样性排序等方法。基于此标准,构建了一个包含2100亿个数据点、具有复杂多样时间模式的大型时间序列数据集。
数据打标:为非公开数据集中的每个样本添加时序标签,如时序长度、销量日均、零销量占比等统计量,以多维度评估样本特征。
质量过滤:通过时序标签评估每条数据的质量,并剔除时序长度过短或销量数据过于离散的样本,提升整体数据质量。
去重:将数据随机分组并进行聚类,每组内只保留前N个样本,以减少冗余,保持数据多样性。
多样性排序:根据时序标签重新排序,确保每个批次的数据包含不同时序特征的样本。
数据配比:设定不同数据类型的配比,如合成数据、公开数据集和京东数据的比例,以及不同维度数据的比例。
-
提出Patch Convolutional Large Timeseries Model (PCLTM):为了处理复杂、长序列中的交叉依赖关系,设计了基于补丁的卷积大型时间序列模型(PCLTM),采用补丁划分方法处理输入数据,并利用卷积层捕获不同通道间的交叉补丁信息。
-
首次提出Time-series Policy Optimization (TPO):这是一个专门针对纯时间序列模型的RLHF框架,通过利用人类专家构建的专用预测模型生成反映人类偏好的预测对比对,指导模型学习,解决了传统强化学习方法难以直接应用于时间序列预测模型的问题。
模型执行流程
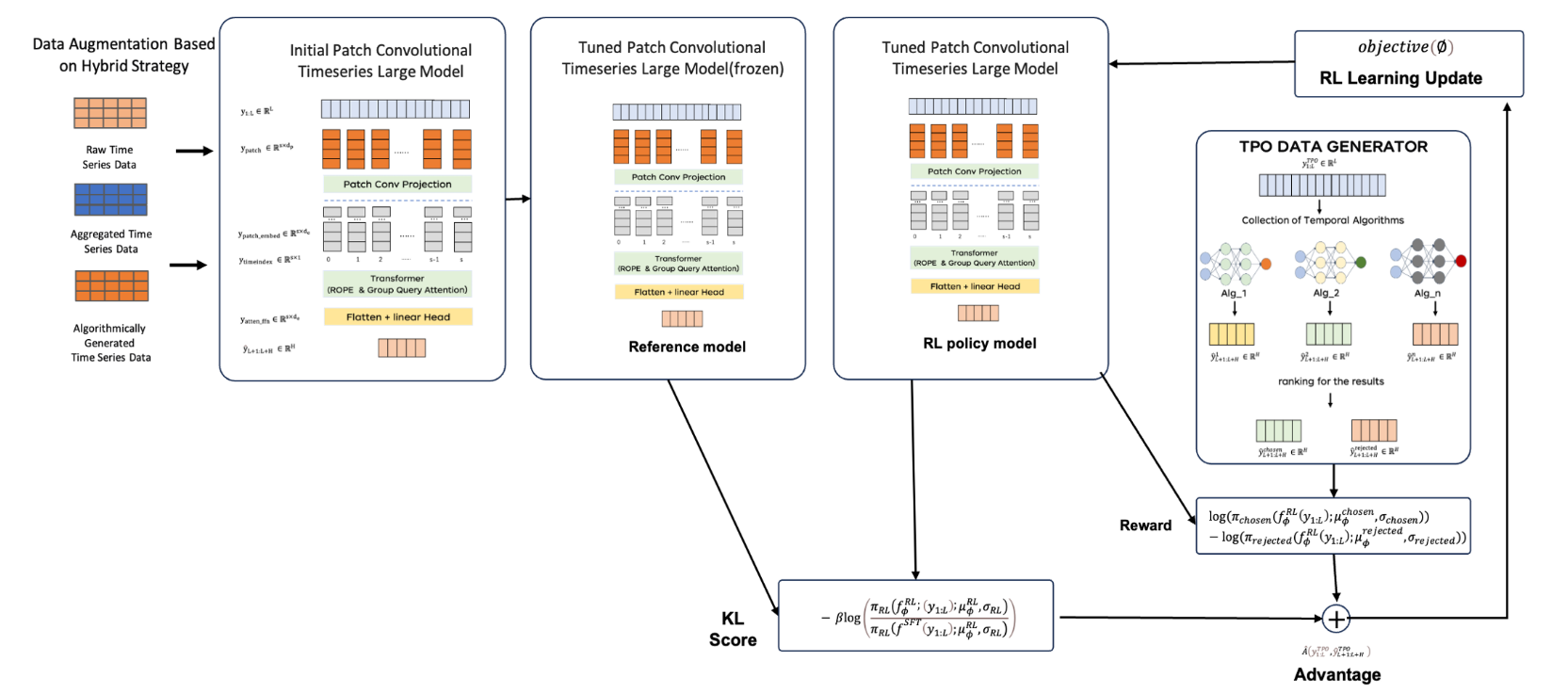







核心逻辑总结
整个框架通过 “数据增强→预训练→强化学习对齐专家知识” 的流程,让时间序列大模型既保留基础预测能力,又融入行业专家的隐性偏好(通过对比预测对和强化学习优化实现 )。关键创新在于用 TPO DATA GENERATOR 替代传统 RLHF 的人工标注,用算法生成的 “好 / 坏预测” 规模化提供反馈,适配时间序列场景的落地需求。
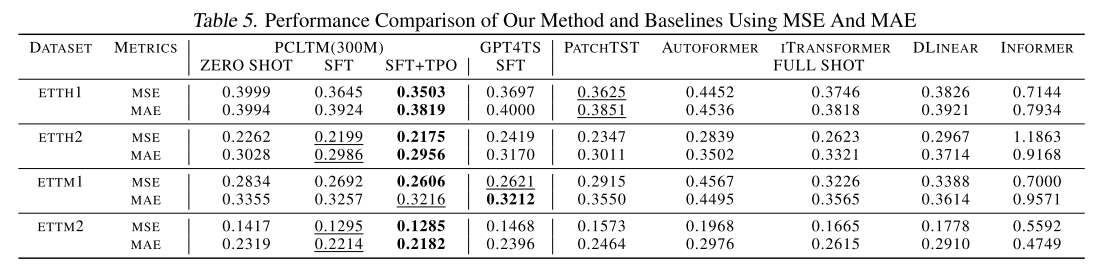
实验
构建大规模、高质量时间序列数据集
-
重要性:扩大数据集规模已被证明是提高大型时间序列模型性能和泛化能力的有效策略。时间序列数据的复杂性各不相同,高维数据通常包含趋势和季节性等模式,而低维数据则易受促销活动等随机因素影响。
-
数据集构建标准:提出了构建大规模、高质量时间序列数据集的标准,数据集分为三个部分:
-
预训练数据:结合京东自有销售数据、公开数据集和合成数据,形成一个包含2100亿个数据点、具有复杂时间模式的大型数据集。
-
监督微调(SFT)数据:为使预训练模型适应下游任务,构建特定场景的微调数据集。
-
强化学习与人类反馈(RLHF)数据:由反馈对比对组成,每个样本包含一个好预测和一个坏预测。
-

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)