小白想使用llama-factory微调大模型配置却不够?autodl来配合
《小白快速训练个性化大模型指南》本文介绍了在缺乏本地硬件条件下,如何利用AutoDL云平台和LLaMA-Factory框架快速训练个性化大模型。AutoDL提供高性能GPU租赁服务,按需付费;LLaMA-Factory则是低代码微调框架,支持多种模型。文章详细指导了从注册账号、租赁服务器到配置环境、下载模型的全流程,并演示了使用自定义数据集微调Qwen2.5模型的具体步骤。通过可视化界面完成模型训
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
在当今人工智能快速发展的时代,大型语言模型(LLMs)已成为自然语言处理(NLP)领域的核心工具。LLaMA-Factory作为一个开源的低代码大模型训练框架,专为大型语言模型的微调而设计,提供了高效且低成本的解决方案。它支持对多种模型进行微调,极大地简化了模型训练的过程。
然而,训练和微调这些庞大的模型需要强大的计算资源支持。AutoDL作为一个领先的GPU云平台,提供了灵活的资源租赁服务,支持弹性调度和秒级计费。通过AutoDL租赁服务器,用户可以高效地利用其强大的算力来加速模型训练。
因训练大模型需要一定的显卡等配置,对于大多数人而言没有足够支撑的硬件支撑
故此本文将详细介绍小白在没有硬件支持下想快速训练一版的属于自己的模型
一、AutoDL和LLaMA-Factory分别是什么?
1.AutoDL
AutoDL是一个领先的AI算力租赁平台,致力于为用户提供稳定可靠且价格公道的GPU算力。它支持多种GPU型号,提供弹性调度和秒级计费服务,适合深度学习和大模型训练等高性能计算需求。用户可以通过网页或SSH远程访问服务器,并利用其预装的深度学习框架快速启动项目。
2.LLaMA-Factory
LLaMA-Factory是一个开源的低代码大模型微调框架,专为简化大型语言模型(LLM)的微调而设计。它支持多种预训练模型(如LLaMA、Mistral、Qwen等),并提供多种微调技术(如全参数微调、LoRA、QLoRA等)。此外,LLaMA-Factory还配备了零代码可视化的网页微调界面(LLaMA Board),方便用户快速上手。
二、准备流程
1.AutoDL
①登录平台
https://www.autodl.com/login
 在这里注册一个账号
在这里注册一个账号
充值(不用充很很多,租赁4090显卡一小时大概两块钱左右)
然后开始选择服务器(显卡可以自己选择)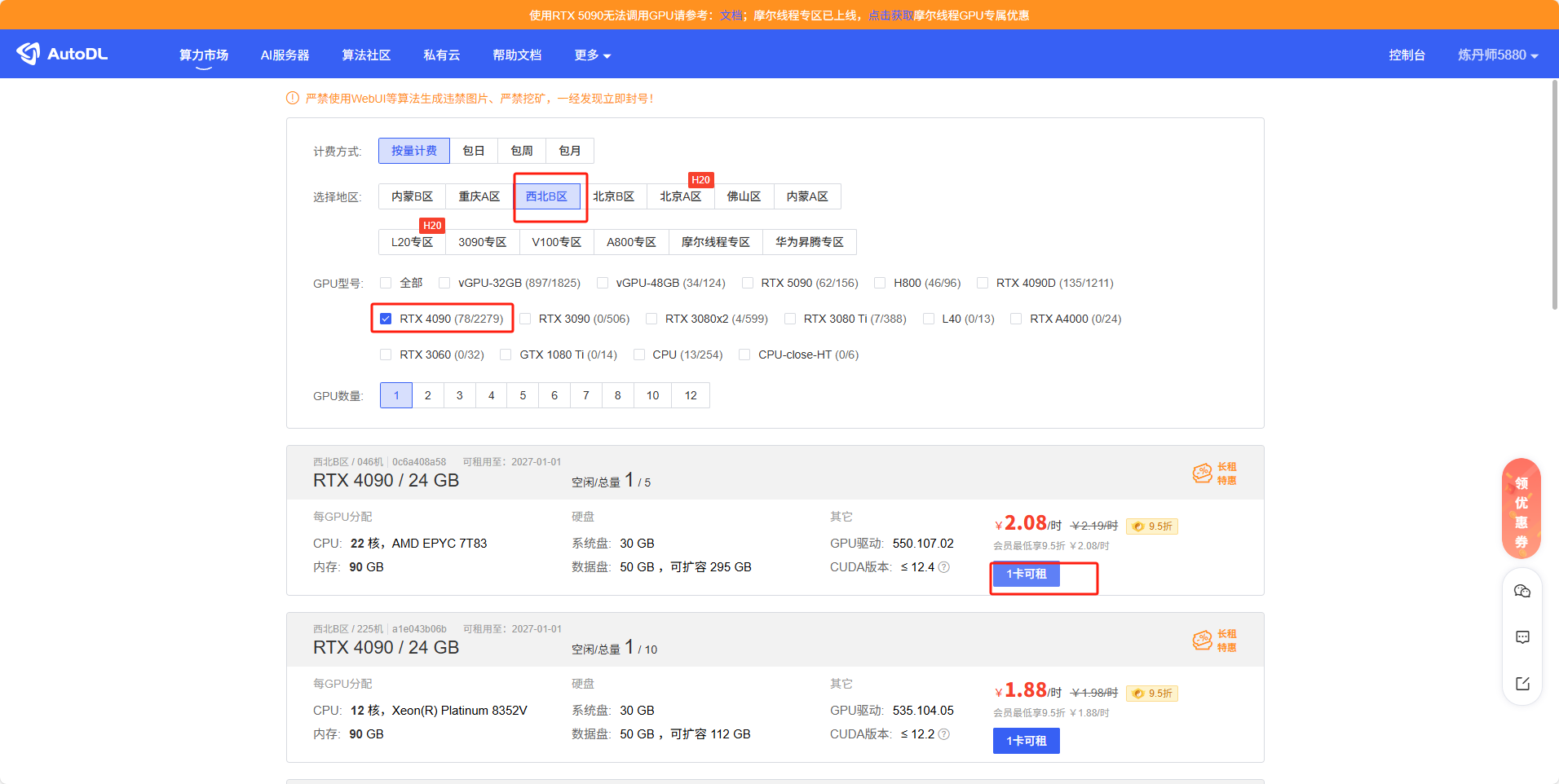
选PyTorch,后面选最新就可以(python等进去创建虚拟环境,所以这里多少都没问题)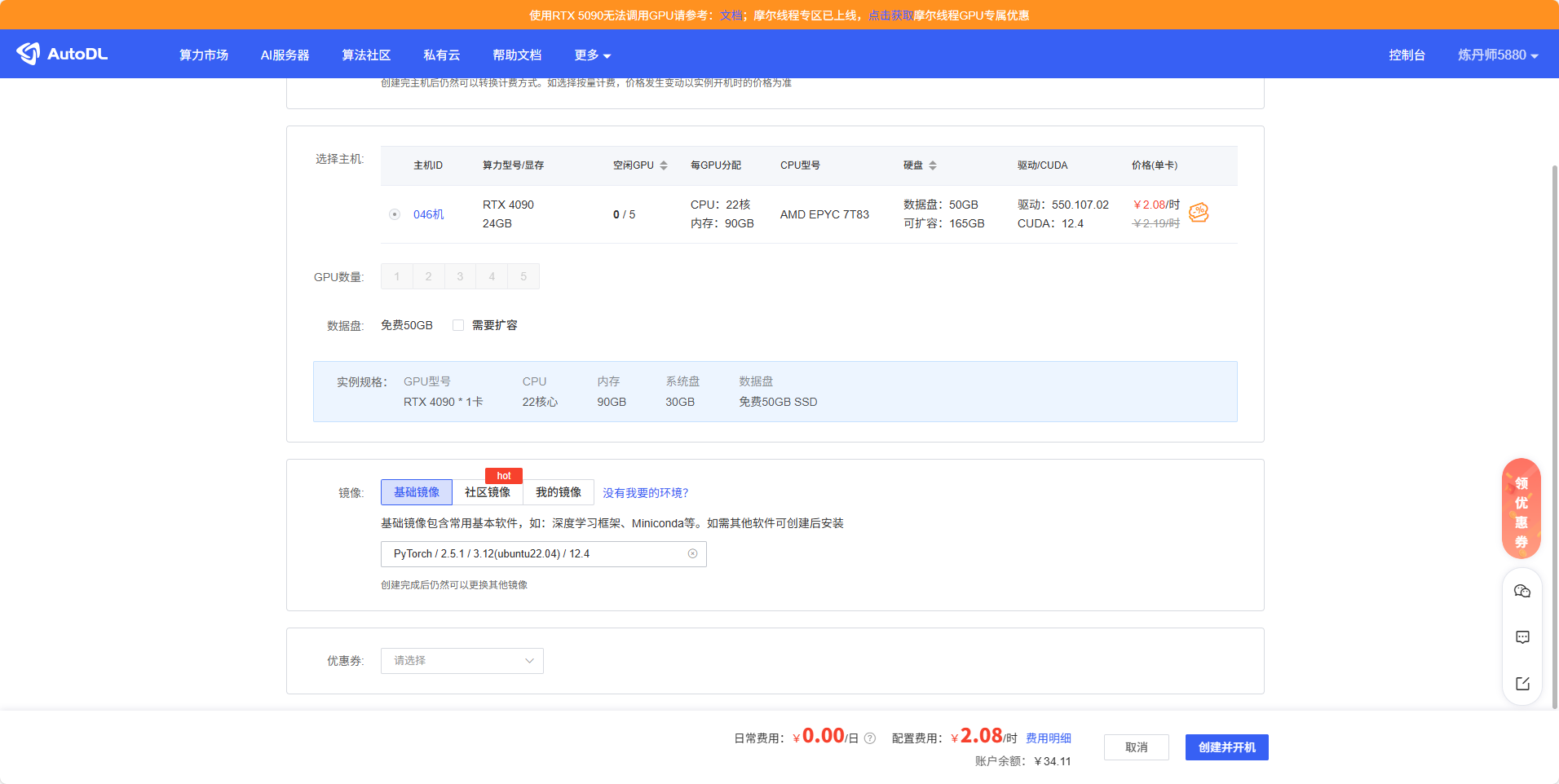
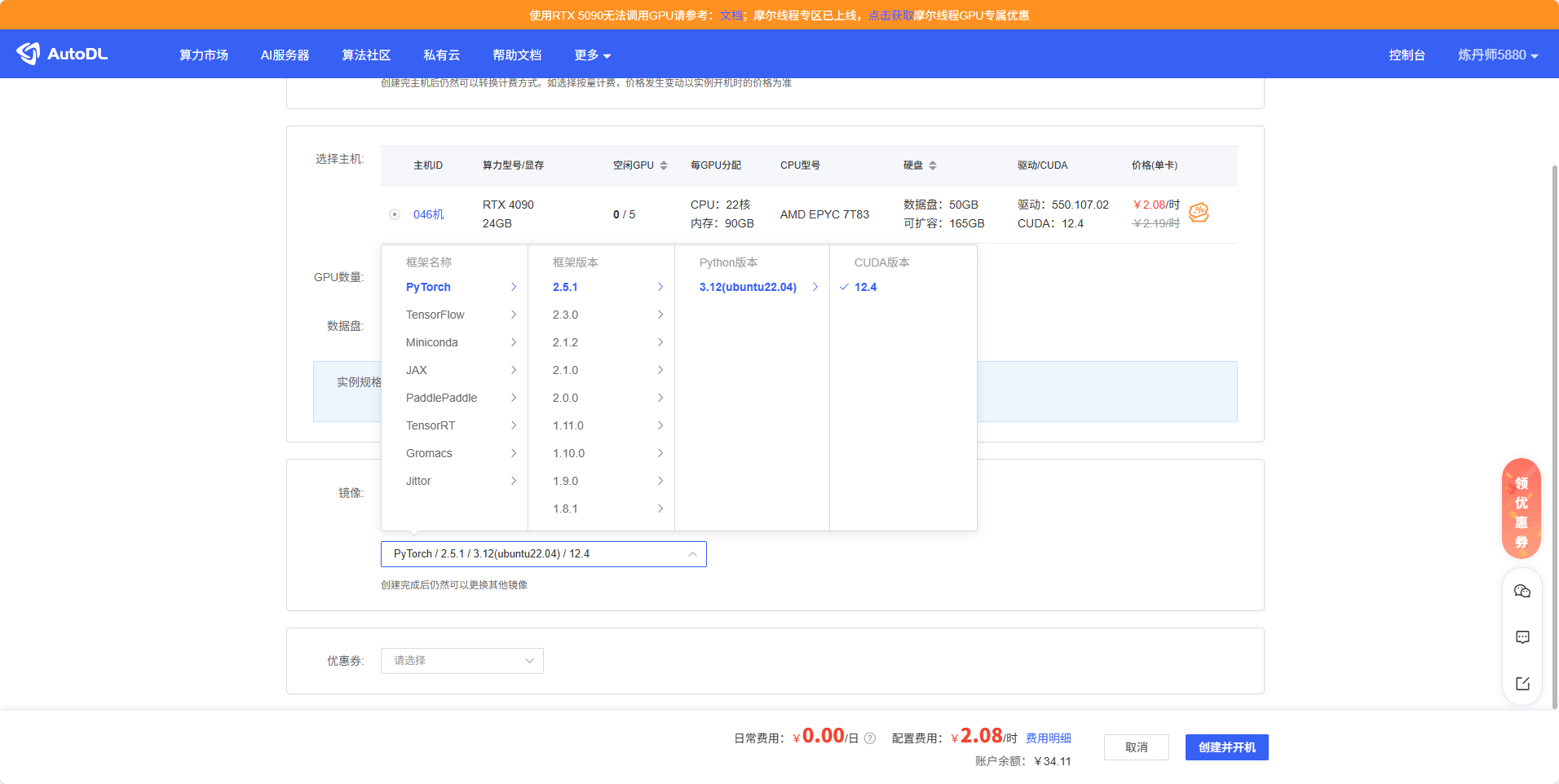
然后选择完开机,选择JupyterLab打开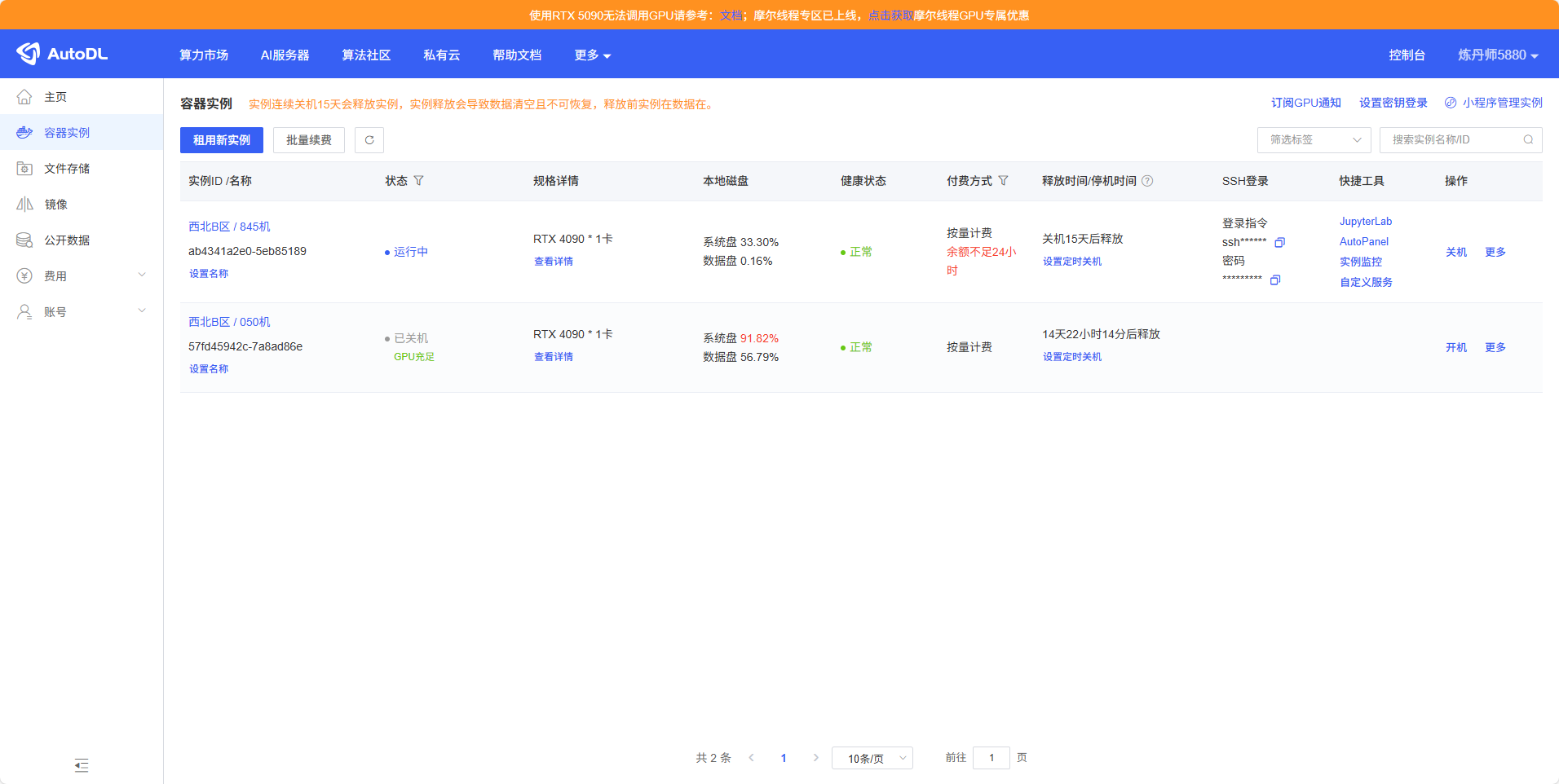
打开终端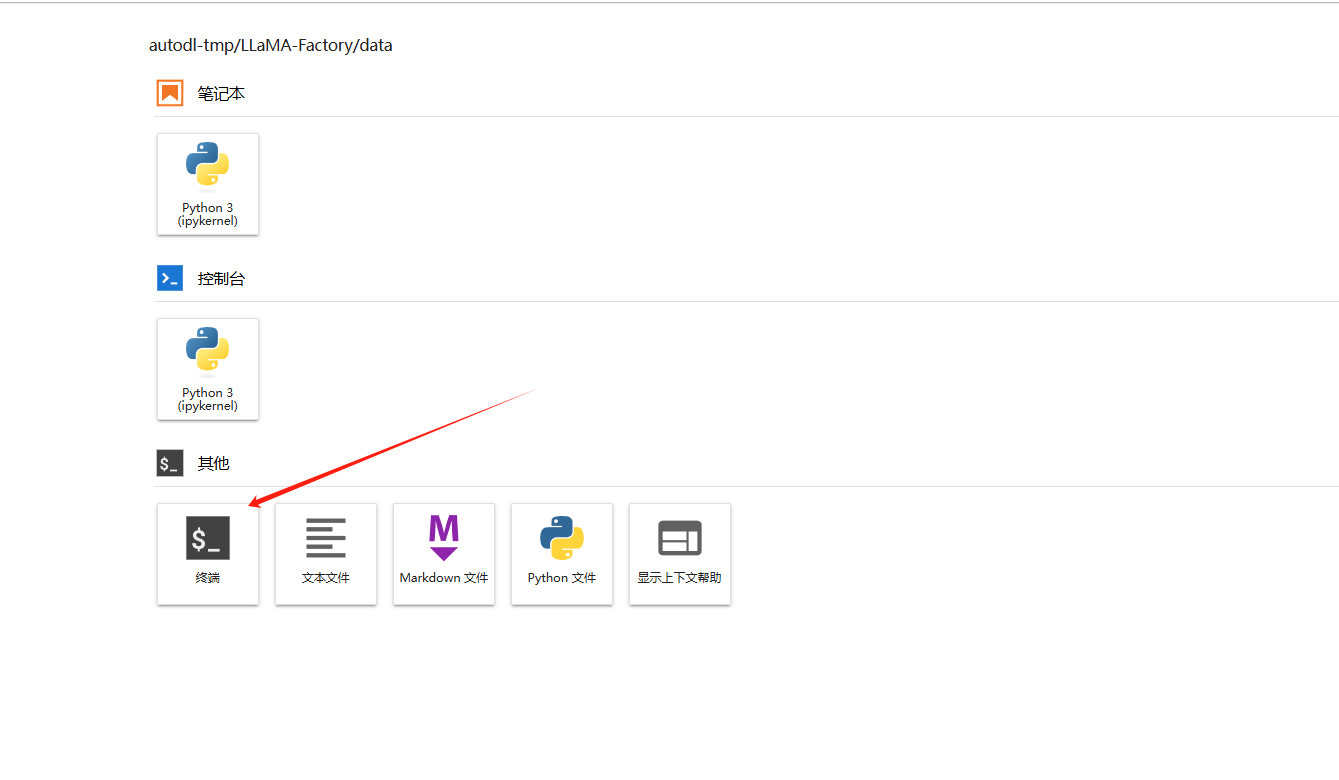
2.LLaMA-Factory
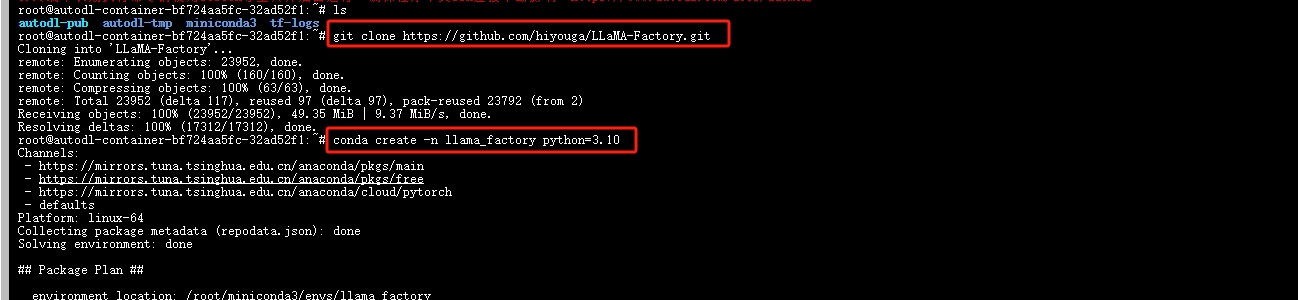
克隆项目
git clone https://github.com/hiyouga/LLaMA-Factory.git
进入项目目录
cd LLaMA-Factory
创建虚拟环境
conda create -n llama_factory python=3.10
进入虚拟环境(若虚拟环境没有进去执行conda init,然后重新打开终端在进一次虚拟环境)
conda activate llama_factory
在安装库
pip install -e '.[torch,metrics]'
安装库比较多,比较耗费时间
如图conda activate llama_factory进入环境时提示Run ‘conda init’ before ‘conda activate’
那么先conda init,关闭终端,再次打开输入conda activate llama_factory,
之后cd LLaMA-Factory/进入目录下
先conda init----关闭终端------打开终端-------输入环境conda activate llama_factory```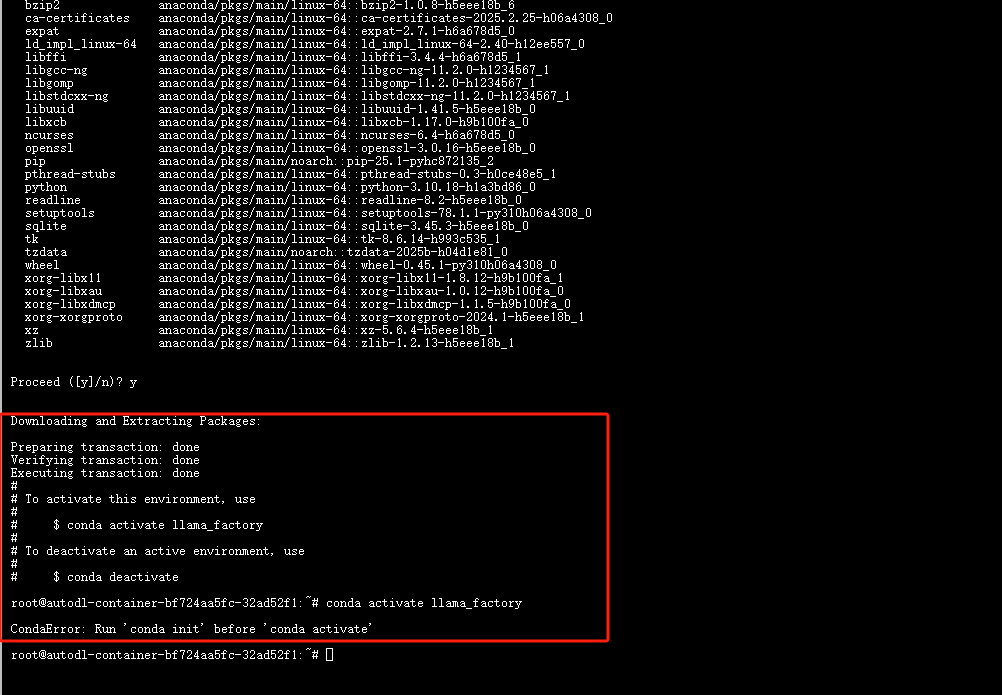
前面变成llama_factory说明正确进入环境了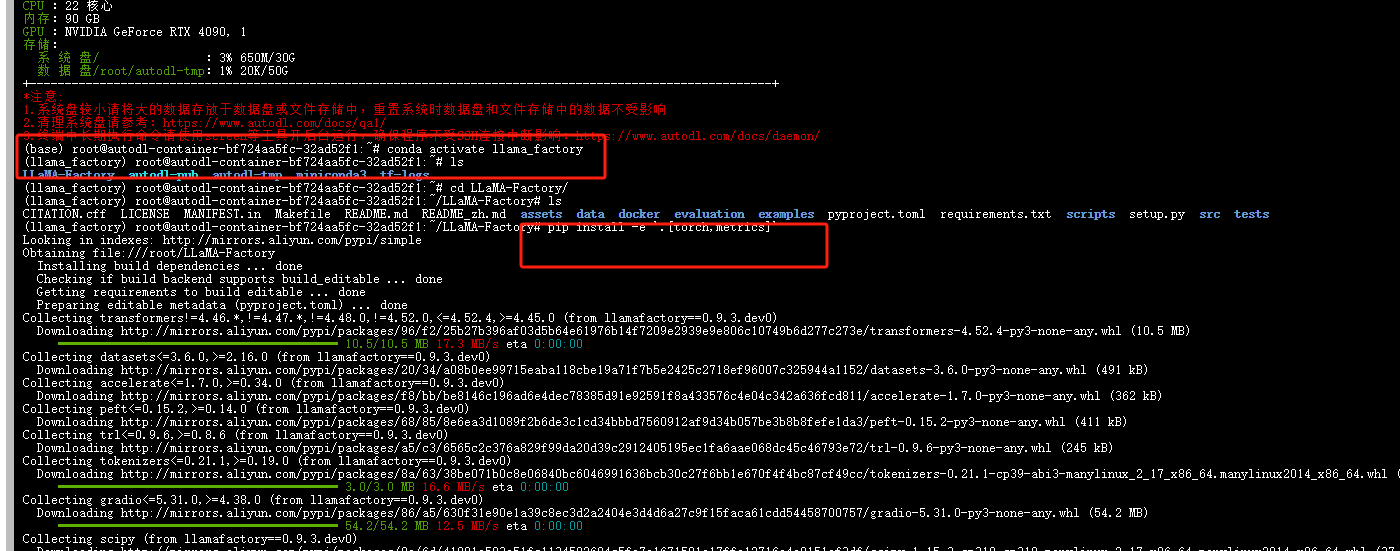
安装完校验一下,可以看此链接(https://zhuanlan.zhihu.com/p/695287607)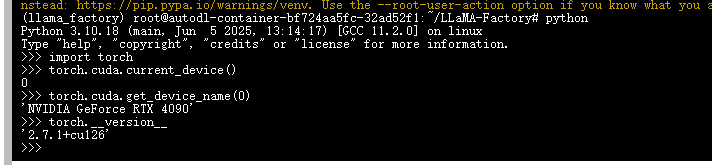
接下来我们简单改一个数据集,用官方的就可以
右击identity.json----打开方式----编辑器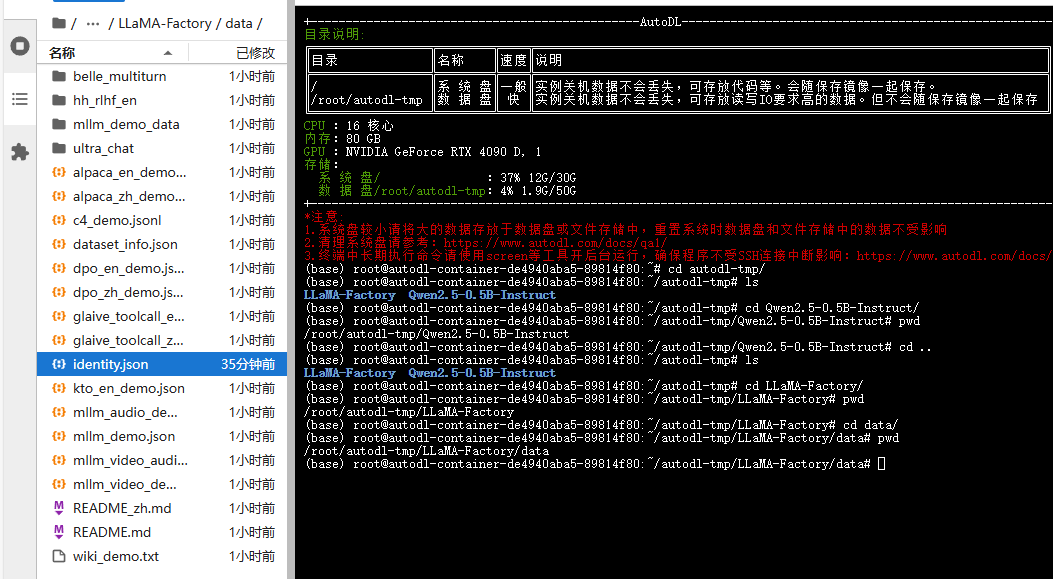
可以使用ctrl+f快速替换{{name}}换成你想要的,{{author}}是也换成想改的字段,最后一定要ctrl+s保存!!
下载模型以Qwen2.5-0.5B-Instruct为例(https://www.modelscope.cn/models/Qwen/Qwen2.5-0.5B-Instruct/files)这是官网
首先需要安装 lfs(目的为例下载完整的模型,我之前没有安装导致训练一直出错)
运行下面的安装lfs
sudo apt-get update
sudo apt-get install git-lfs
命令初始化 Git LFS
git lfs install
验证安装
git lfs version
接下来安装模型(这个模型比较小,大概1g左右)
git clone https://www.modelscope.cn/Qwen/Qwen2.5-0.5B-Instruct.git
在LLaMA-Factory目录下运行(一定要在LLaMA-Factory下)
llamafactory-cli webui
下载ssh隧道
第一个autodl.exe,打开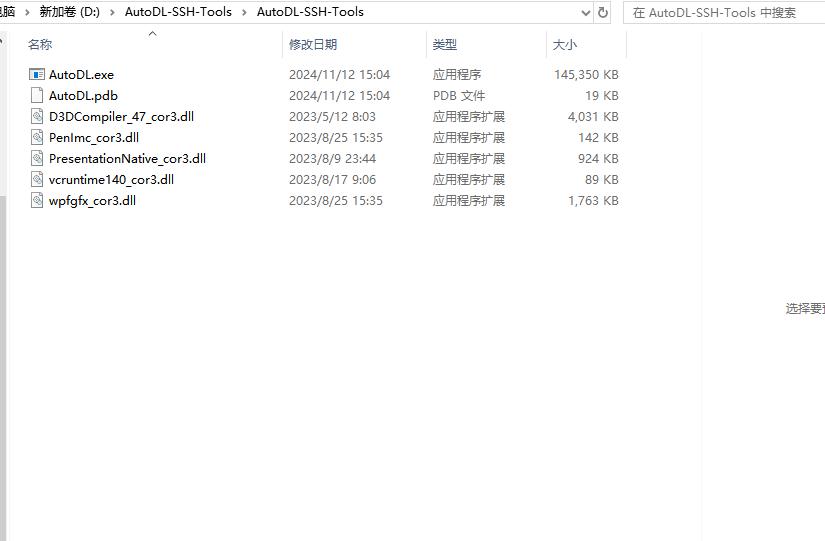
打开的界面时这样的;
代理到本地端口这里加上7860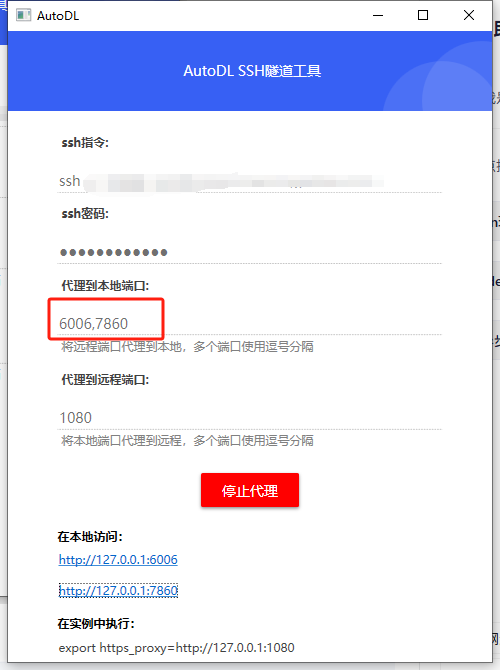
复制指令就可以,在点击http://127.0.0.1:7860本地访问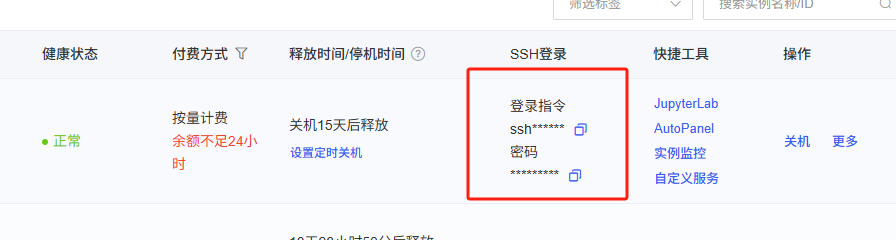
模型名称写:Qwen2.5-0.5B-Instruct ;
数据集名称:identity;
数据集训练轮数:100条数据集:建议迭代20轮;1000条数据集:建议迭代10轮;10000条数据集:建议迭代2轮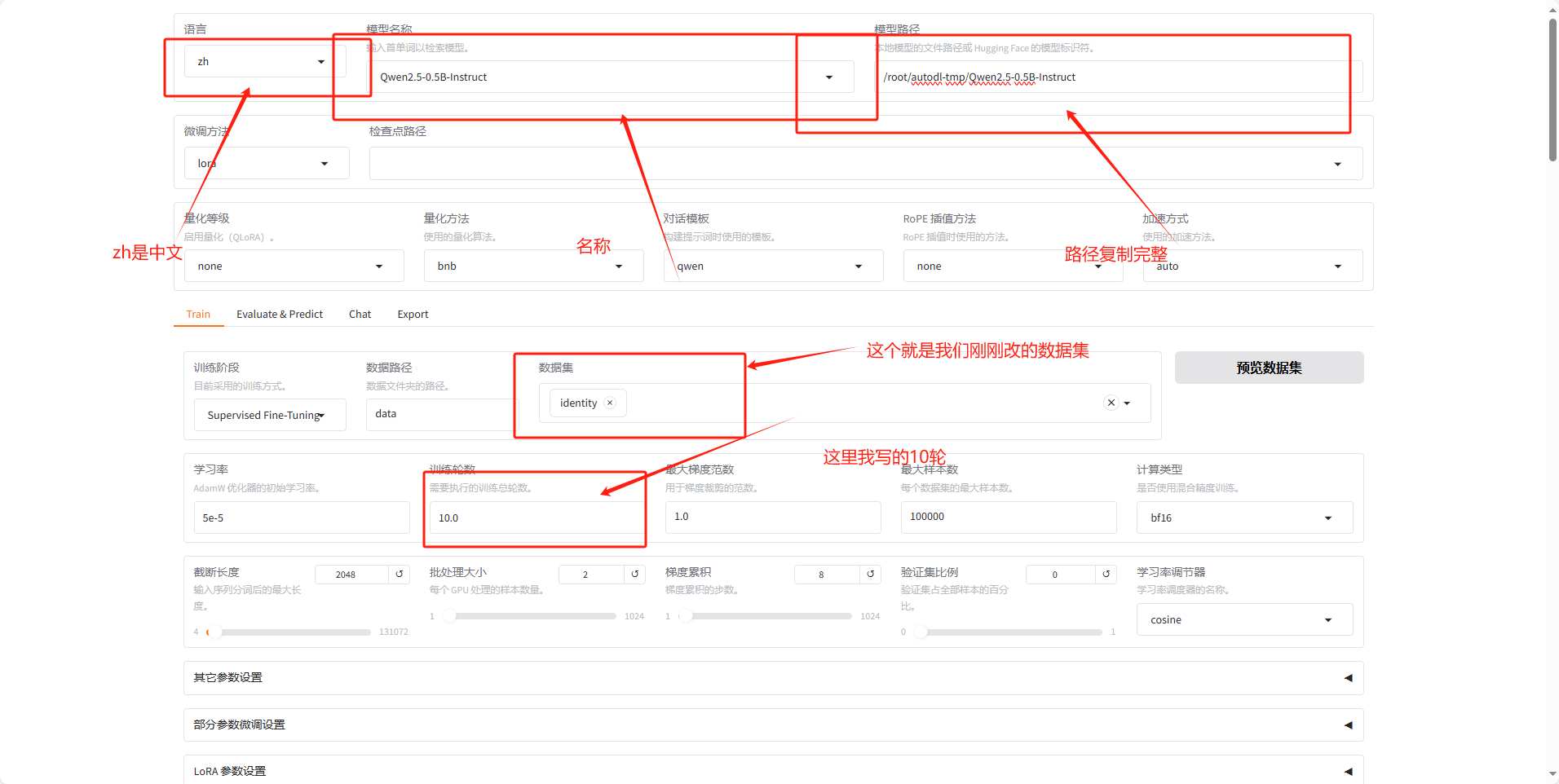
可以点击预览数据集
然后开始就可以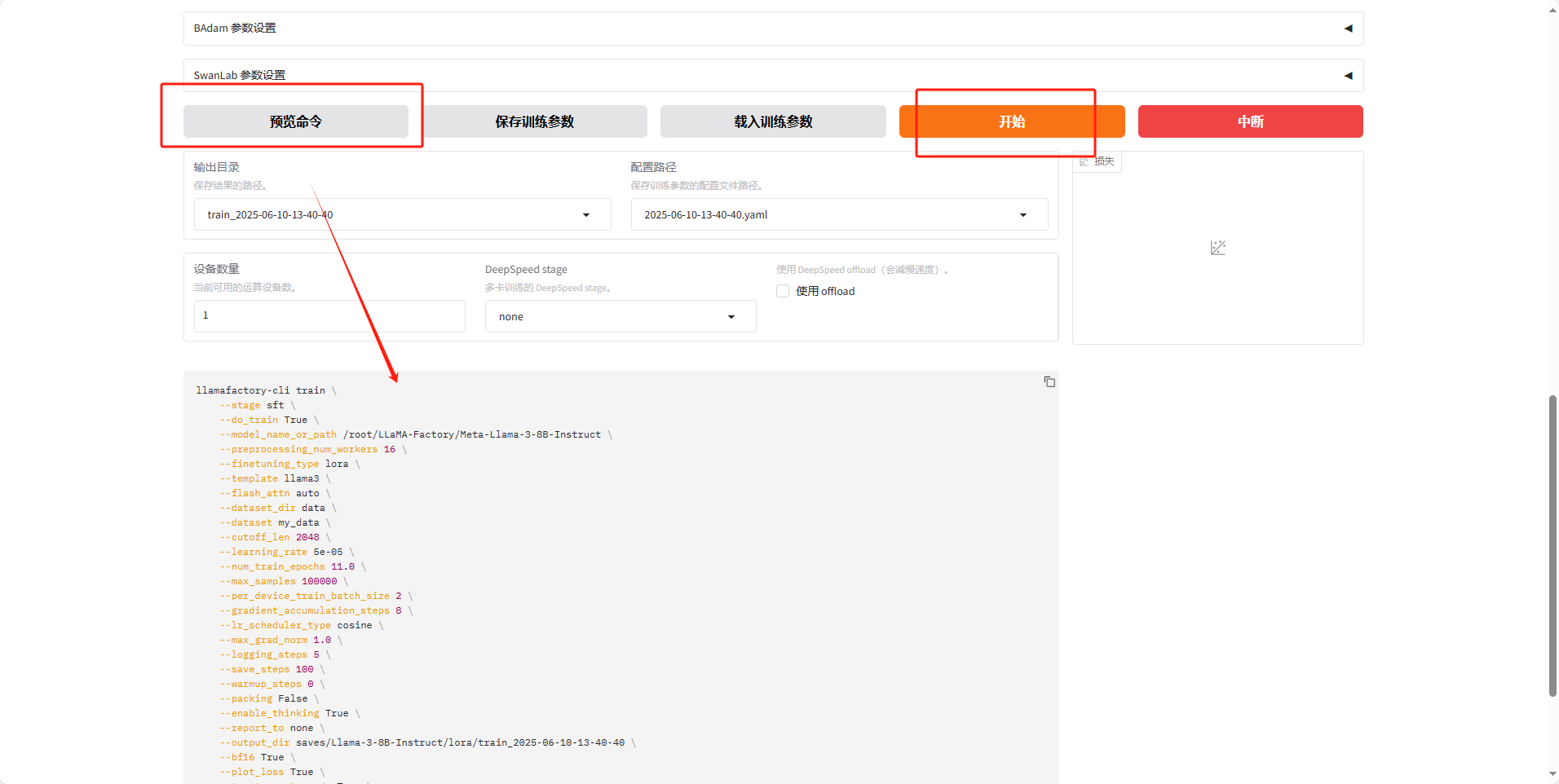
等待训练完毕,因为训练的东西也比较少很快就训练好,
我们记住这个输出目录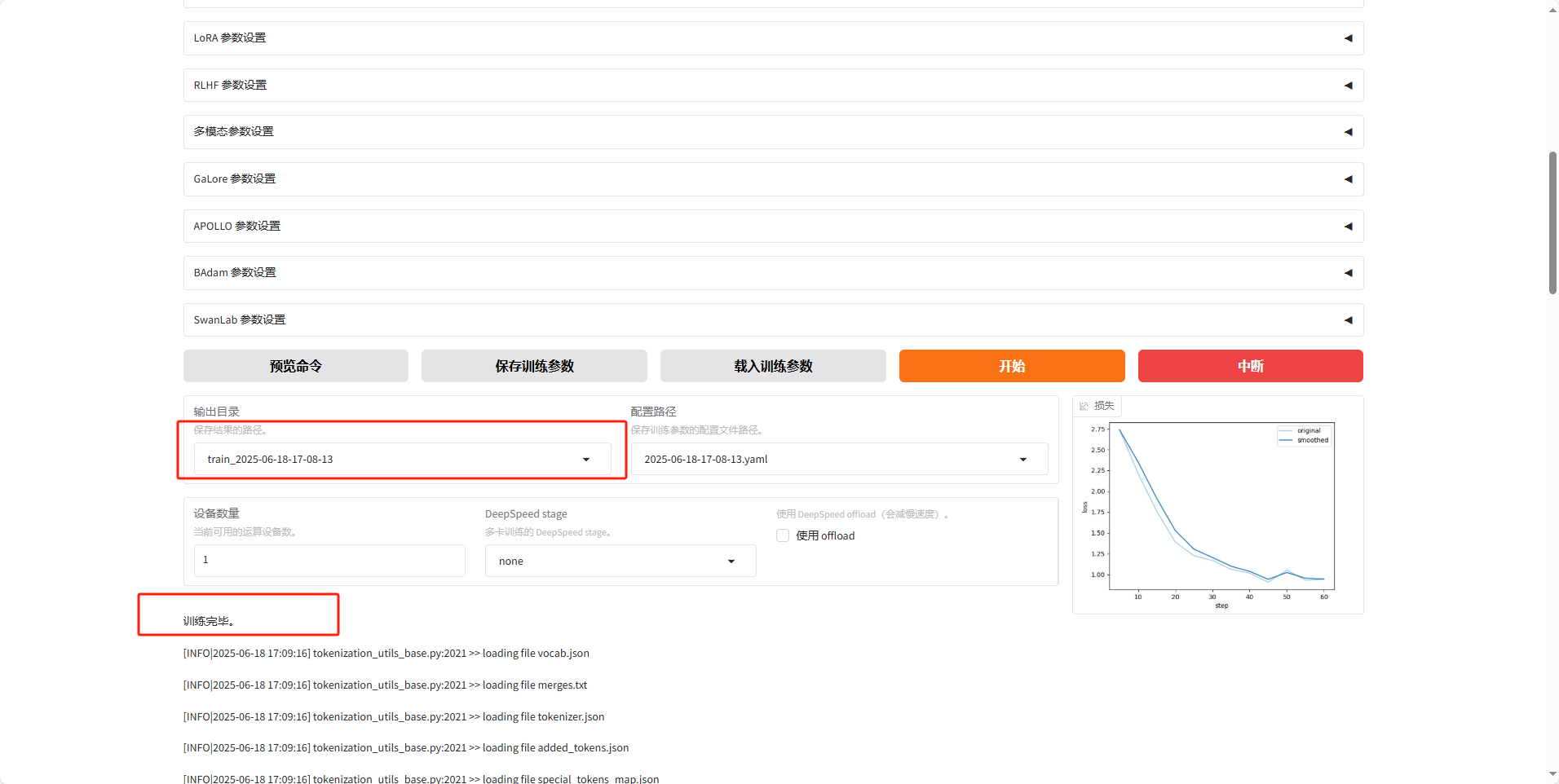
现在点击chat,微调方法刚才的路径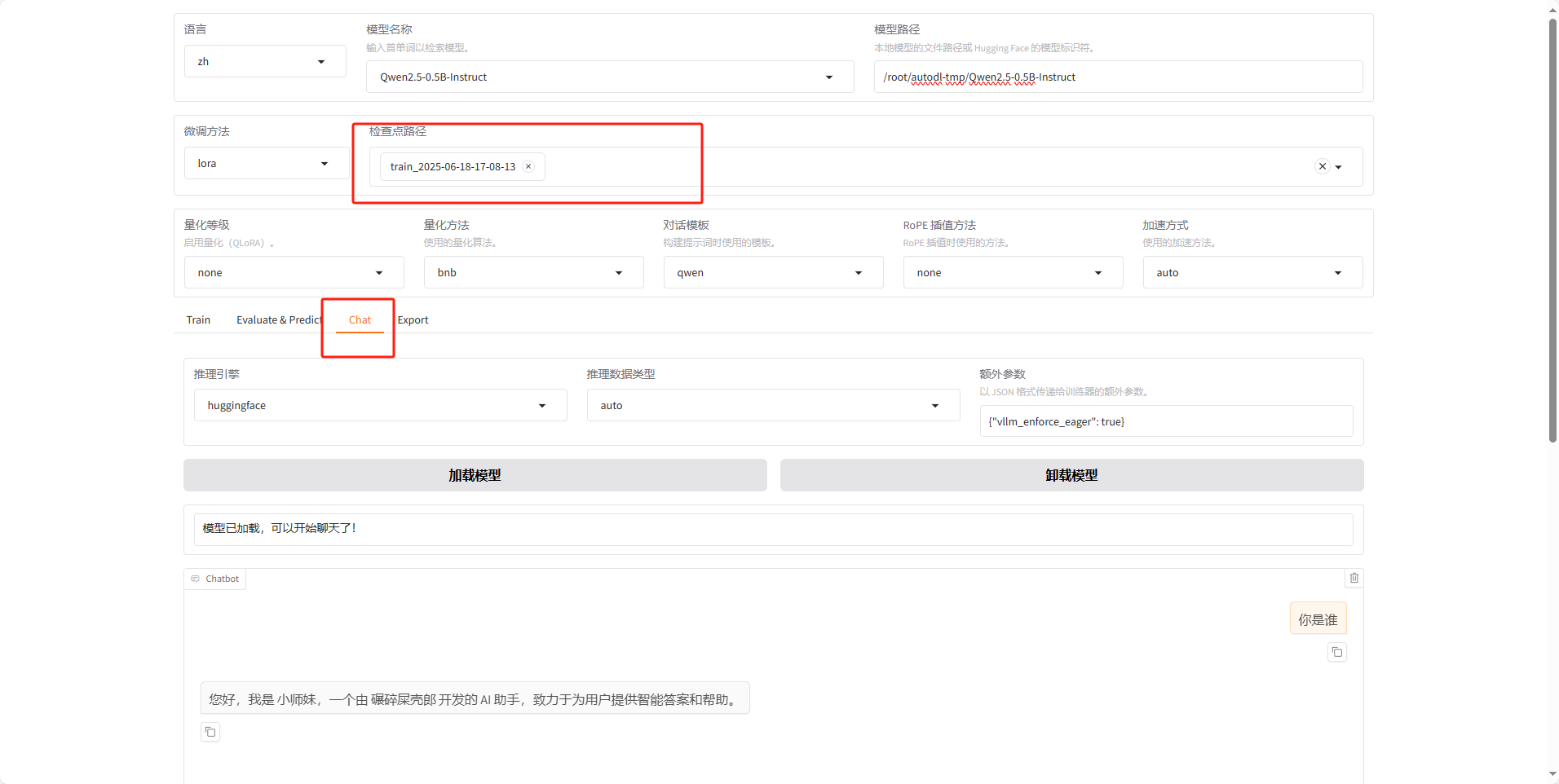
点击加载模型,在下面对话我们可以发送内容,比如我们微调的是让模型的自我认知改变,通过对话,看我们改动的内容以已经生效,若是想知道不训练之前ai回复的内容,点击卸载模型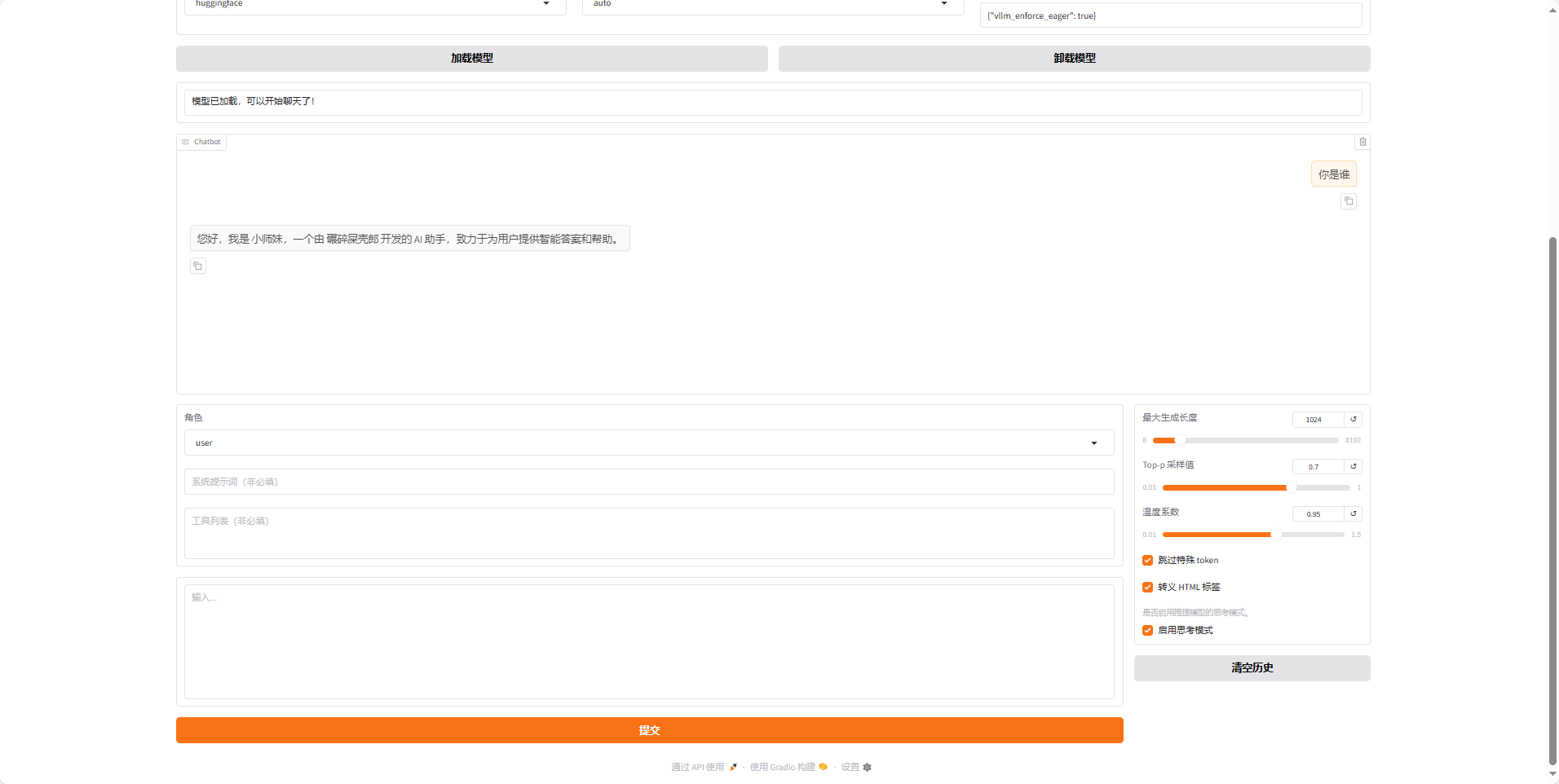
路径不用填写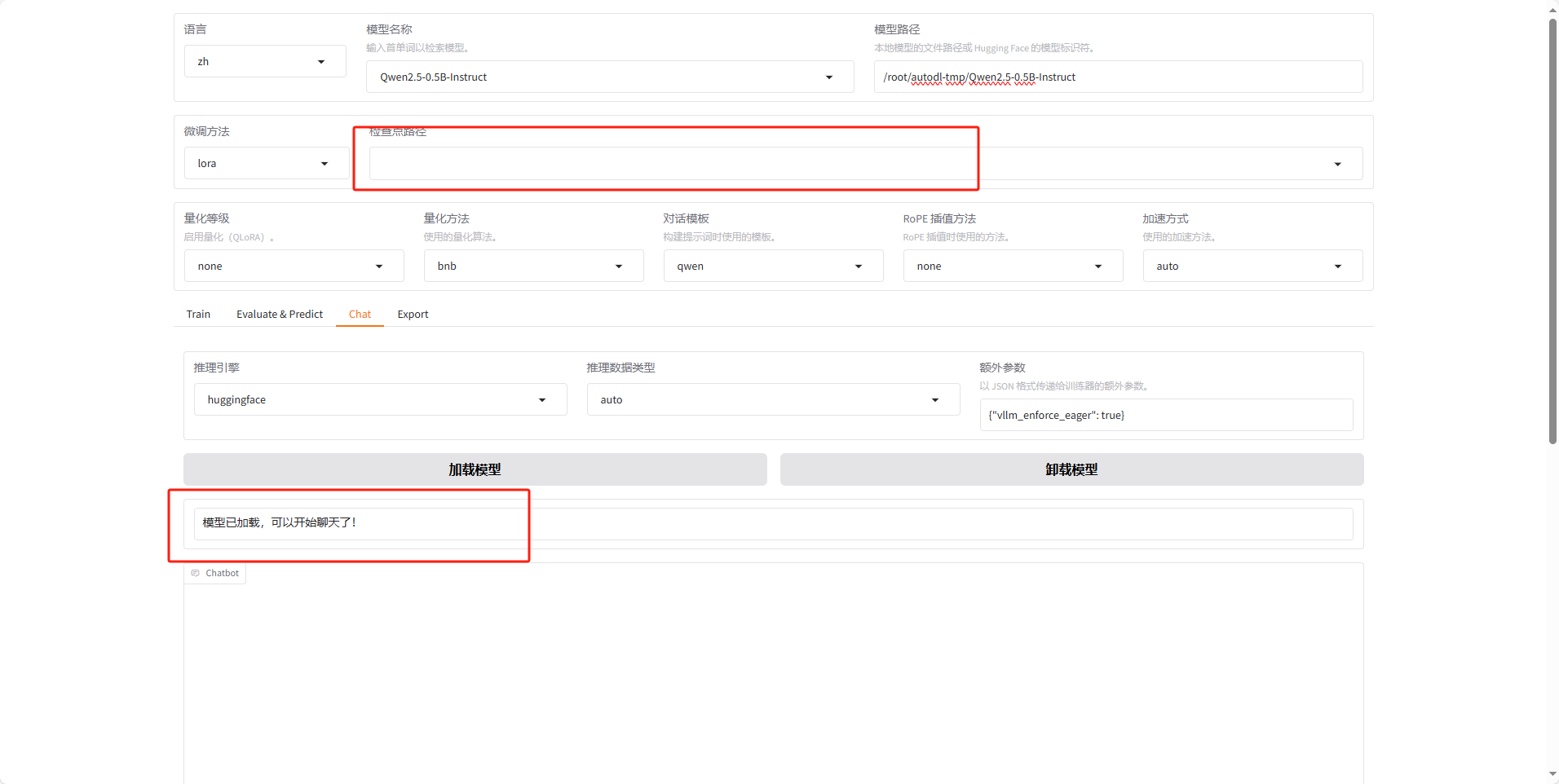
这是本身大模型会输出的内容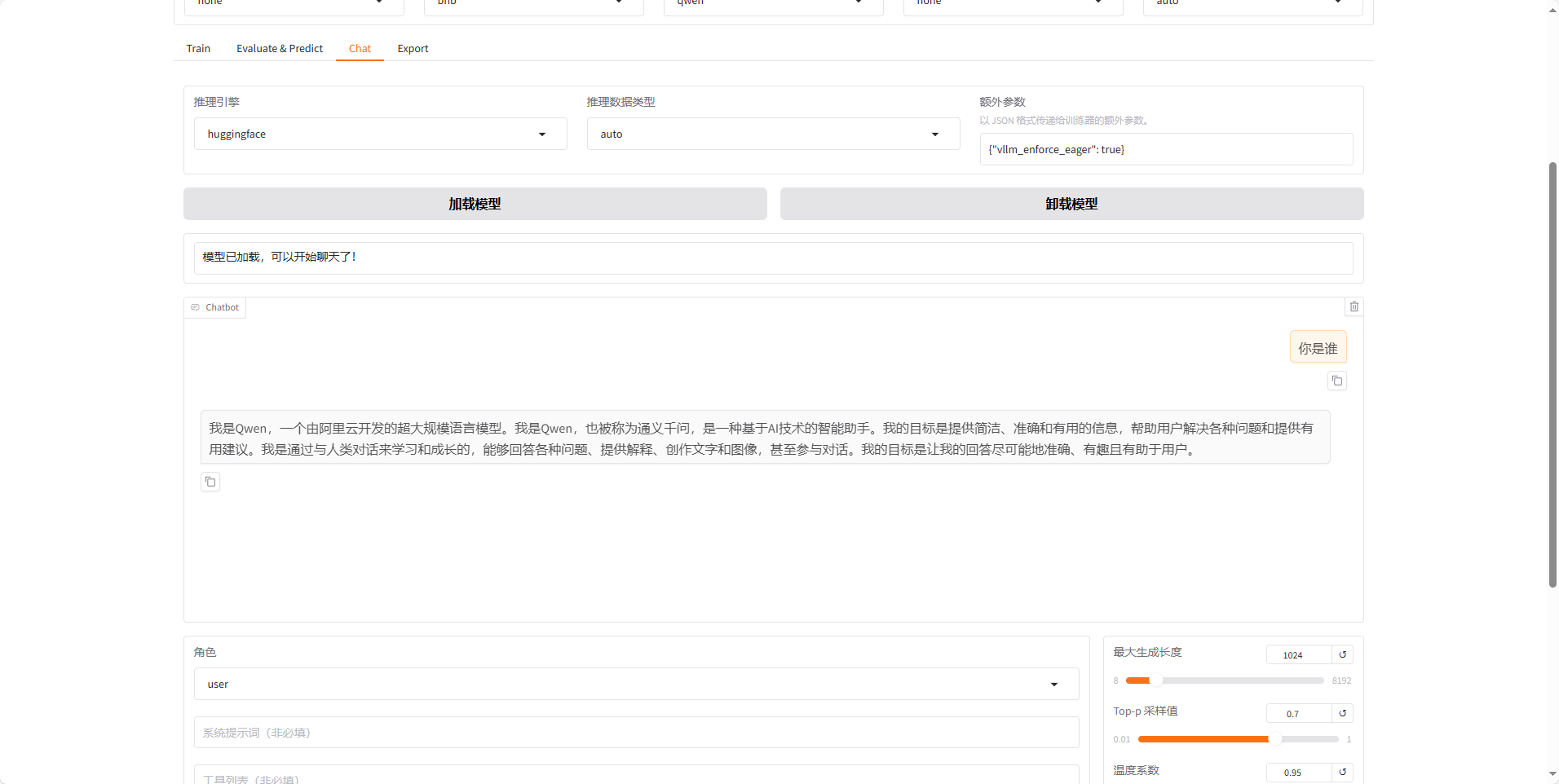
最后一定要回到autodl控制台关机,否则会一直扣费!!!
总结
微调大模型是不是很简单,之后可以做一个自己的数据集进行训练,单论对话,多轮对话等都有。当然数据集在官方也有格式要求,可以看一下官方文档,都是有非常明确的说明的。
这次没写导出部分,之后如果时候将模型导出,部署在ollama就可以正常使用,范围也是很广的,总之如果时间空闲可以研究研究,还是很有意思的。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 27
27 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)