智能问数的破局之道:把表间关系做成底层引擎
当行业还在靠 “人工作坊 + 提示词堆砌” 维持智能问数的 Demo 效果,换个业务域就准确率 “跳水”、生成 SQL 难溯源、成本失控时,一种更工程化、更稳的解法已浮出水面 —— 以 IntaLink × AriLink 为核心的 AI-Native 问数架构,把 “表间关系” 做成可迁移、可解释、可治理的底层引擎,让智能问数从 “经验活” 升级为能规模化落地的工程能力。SQL 能跑≠答案对:同
当行业还在靠 “人工作坊 + 提示词堆砌” 维持智能问数的 Demo 效果,换个业务域就准确率 “跳水”、生成 SQL 难溯源、成本失控时,一种更工程化、更稳的解法已浮出水面 —— 以 IntaLink × AriLink 为核心的 AI-Native 问数架构,把 “表间关系” 做成可迁移、可解释、可治理的底层引擎,让智能问数从 “经验活” 升级为能规模化落地的工程能力。
智能问数的 “落地魔咒”:为何 Demo 很美,实操却满是坑?
对甲方数据负责人、方案商、平台厂商而言,智能问数的落地之路总被多重难题卡住:
1、换域即 “翻车”:靠人工梳理字段口径,换个行业、换个数据库,之前调好的模型立刻 “打回原形”,重体力建模成了常态;
2、SQL 能跑≠答案对:同一指标的时间窗、统计口径、维度粒度悄悄 “漂移”,问数从 “查事实” 变成 “猜玄学”;
3、Join 路径 “随缘”:主外键缺失时,单靠字段名相似度匹配,错连表、漏连数据、重复计算成了高频问题;
4、提示词 “扛不住长尾”:冷启动场景频繁掉链子,Prompt 复现性差,想工程化落地难如登天;
5、解释成 “糊涂账”:拿 “结果回溯截图” 当可解释性,用户真正关心的 “为何选这条 Join、不选那条” 始终说不清楚;
6、成本与安全双失控:纯 LLM 直出反复重试,QPS 上不去、账单却翻倍;权限脱敏后置,SQL 生成时已存在越权风险;
7、信创适配 “浅尝辄止”:对达梦、金仓等国产数据库,Iceberg/Hudi 湖仓的语法差异处理不足,信创环境难兼容。
这些问题的核心,在于行业大多把 “智能问数” 当成了 “LLM + 提示词” 的简单组合,却忽略了最关键的底层支撑 —— 表间关系的系统化处理。
破局关键:IntaLink × AriLink 架构,把表间关系做成引擎
不同于 “堆人堆提示词” 的粗放模式,IntaLink × AriLink 架构的核心理念是:将表间关系从 “外挂式配置” 升级为 “内置引擎”,通过自动建链、约束搜索、口径资产化,守住智能问数的 “准确性底线”,同时解决可迁移、可解释、可治理的核心诉求。
1. 底座引擎 IntaLink:筑牢数据关系的 “地基”
作为底层支撑,IntaLink 不依赖人工干预,而是主动构建稳定的数据关系体系:
1)自动生成表间关系图谱:智能识别主外键、候选键、同义字段映射、编码表,甚至精准定位账期、业务日等时序锚点,无需人工逐条标注;
2)跨源实体对齐:搞定多数据库、多数据源的主数据统一与冲突消解,国产数据库、湖仓环境都能无缝兼容;
3)Join 路径多因子打分:不单一依赖字段名相似度,而是结合键约束、数据一致性采样、选择性估计、语义匹配综合评估,杜绝 “错连漏连”;
4)指标口径注册表:把常用指标的统计口径、时间窗规则、维度层级沉淀为可复用资产,换库不换口径,避免重复定义;
5)权限脱敏前置:生成 SQL 前就限定可见字段、可用表、最大查询行 / 列数,从源头规避越权风险,而非事后过滤。
2. 交互编排层 AriLink:让问数 “准、透、稳”
1)在 IntaLink 基础上,AriLink 聚焦用户交互与 SQL 全生命周期管理,解决 “生成准、能解释、可修复” 的问题:
2)“澄清卡片” 智能消歧义:遇到时间窗、指标口径、维度定义模糊时,以 “最小打扰” 方式确认,不增加用户操作负担;
3)Hybrid NL2SQL 生成:不是纯 LLM 直出,而是结合结构化约束搜索、语法 / 权限双重校验、Top-k 自洽检验,确保 SQL 既合规又准确;
4)Exec-Repair 闭环修复:遇到语法错误、权限问题、查询空集、高基数等问题,自动判断错误类型并重试修复,无需人工介入;
5)可解释问数可视化:直观展示 “为何选这条 Join 路径、放弃了哪些候选路径”,指标口径来源、数据切片预览一屏看懂,不再是 “黑箱输出”;
6)量化评测体系:内置黄金 SQL 集,以 “SQL 可执行率、业务口径一致率、解释可读性覆盖率” 为核心指标,告别 “只谈 Demo 不谈效果”。
3. 工程化嵌入:无缝融入现有体系
架构支持 API/SDK/ 白标输出,可私有化部署、适配多租户,既能与现有 BI 工具、数据中台共存,也能为平台厂商、ISV 提供底层能力支撑,无需推翻现有系统。
直面行业 “共性坑”:IntaLink × AriLink 如何实现降维打击?
对比行业常见做法,IntaLink × AriLink 从根源上补齐工程化短板,让智能问数真正 “能落地、能复用、能治理”:
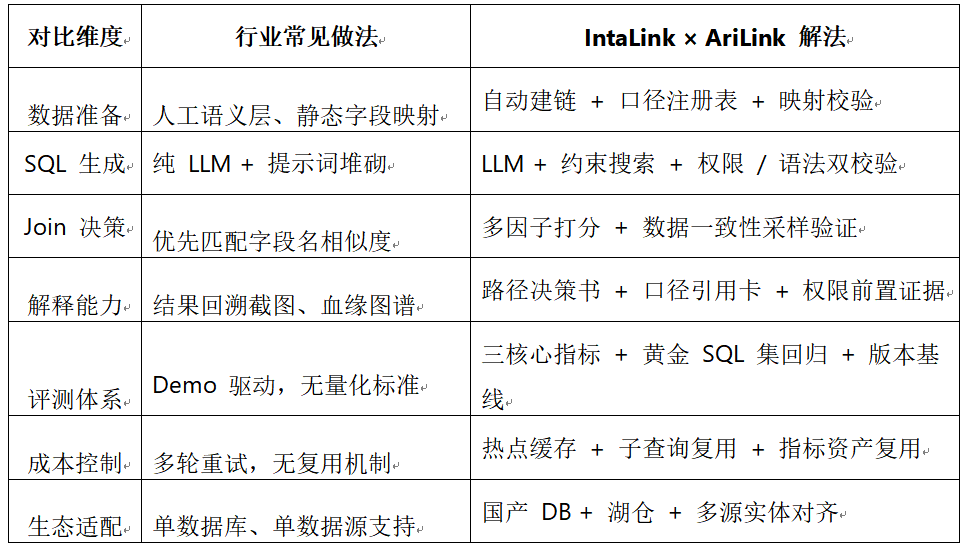
核心价值落地:可迁移、可解释、可治理的准确性
对甲方数据负责人、方案商、平台厂商而言,IntaLink × AriLink 带来的不仅是技术升级,更是业务价值的确定性:
1. 可迁移:换域换库不 “翻车”
1)Schema-RAG 减少幻觉:将真实元数据、表间关系纳入检索上下文,避免 LLM “记错库表结构”;
2)Join 路径抽样验证:每条候选路径都做选择性估计与数据一致性抽样,杜绝 “看起来像对的、实际错的” 误连;
3)口径资产复用:相同业务域换数据库时,无需重建模型,只需 “映射 + 校验”,迁移效率提升 80%+。
2. 可解释:从 “黑箱” 到 “透明”
1)路径决策书:列出所有候选 Join 路径,标注键约束、选择性、样本一致性等打分因子,决策逻辑一目了然;
2)口径引用卡:指标定义、时间窗规则、数据来源清晰可查,业务人员无需懂技术也能验证结果;
3)权限前置证据:明确哪些字段因权限被隐藏、为何不选用某张表,机器可读 + 人工可查,合规性有迹可循。
3. 可治理:成本可控、迭代稳定
1)离线回归集保障:覆盖高频问法与长尾场景,每次迭代都能验证准确性,避免 “改一处坏一片”;
2)成本延迟可预期:通过缓存、子查询复用,热点问题响应延迟降低 70%,算力成本减少 50%+;
3)信创开箱即用:内置国产数据库、湖仓语法适配逻辑,方言归一化处理,信创环境无需额外开发。
结语:智能问数的门槛,从来不是 “写提示词”
当行业还在纠结 “如何优化提示词” 时,真正的破局点早已聚焦在 “如何做对表间关系”。IntaLink × AriLink 用自动建链替代人工梳理,用工程化校验替代经验判断,用可量化指标替代 Demo 演示,让智能问数真正从 “实验室” 走向 “生产场”。
对甲方数据负责人,它是 “准确性可迁移、上线可度量” 的定心丸;对平台厂商、方案商,它是 “快速交付、信创适配” 的底层能力。告别 “人海堆问数” 的粗放模式,从 “把表间关系做成引擎” 开始,让智能问数真正服务于业务增长。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)