Python爬取百度图片:手把手教你写一个图片爬虫
摘要: 本文介绍了百度图片爬虫的设计与实现,重点解决动态加载技术带来的爬取难题。通过分析JSON接口构造请求URL,从返回数据中提取图片地址,采用多线程并发下载提高效率。技术要点包括:请求参数构造、反爬策略(User-Agent模拟、请求间隔控制)、异常处理机制等。文章提供了完整的Python实现代码,包含URL获取、图片下载等核心功能,并给出代理IP池、自动重试等进阶优化建议。同时强调了遵守ro
·
爬虫设计原理
百度图片搜索采用动态加载技术,传统静态页面爬取方法无法直接获取全部图片。我们需要模拟浏览器行为,通过分析网络请求获取真实图片地址。
技术要点
- 请求分析:使用浏览器开发者工具(F12)分析XHR请求
- 参数构造:解析百度图片搜索的请求参数规律
- 反反爬策略:设置合理请求头和使用代理IP
- 异步下载:提高图片下载效率
完整爬虫实现
import requests
import re
import os
import time
from urllib.parse import quote
from concurrent.futures import ThreadPoolExecutor
class BaiduImageSpider:
def __init__(self, keyword, max_num=100, save_dir='images'):
self.keyword = keyword
self.max_num = max_num
self.save_dir = save_dir
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
self.session = requests.Session()
os.makedirs(save_dir, exist_ok=True)
def get_image_urls(self):
"""获取图片真实URL列表"""
base_url = f'https://image.baidu.com/search/acjson?tn=resultjson_com&logid=11111111111111111111&ipn=rj&ct=201326592&is=&fp=result&fr=&word={quote(self.keyword)}'
urls = []
pn = 0
while len(urls) < self.max_num:
url = f"{base_url}&pn={pn}&rn=30"
try:
response = self.session.get(url, headers=self.headers)
response.raise_for_status()
data = response.json()
if not data.get('data'):
break
for item in data['data']:
if 'thumbURL' in item and item['thumbURL']:
urls.append(item['thumbURL'])
if len(urls) >= self.max_num:
break
pn += 30
time.sleep(1) # 防止请求过快
except Exception as e:
print(f"获取图片URL失败: {e}")
break
return urls[:self.max_num]
def download_image(self, url, index):
"""下载单张图片"""
try:
response = self.session.get(url, headers=self.headers, timeout=10)
response.raise_for_status()
# 从URL提取文件扩展名
ext = os.path.splitext(url)[1][:4] or '.jpg'
filename = f"{self.keyword}_{index}{ext}"
save_path = os.path.join(self.save_dir, filename)
with open(save_path, 'wb') as f:
f.write(response.content)
print(f"成功下载: {filename}")
return True
except Exception as e:
print(f"下载失败 {url}: {e}")
return False
def run(self):
"""执行爬虫"""
print(f"开始爬取'{self.keyword}'相关图片...")
urls = self.get_image_urls()
print(f"共获取到{len(urls)}张图片URL")
# 使用线程池并发下载
with ThreadPoolExecutor(max_workers=5) as executor:
for i, url in enumerate(urls):
executor.submit(self.download_image, url, i+1)
time.sleep(0.5) # 控制下载频率
print("图片下载完成!")
if __name__ == '__main__':
keyword = input("请输入搜索关键词: ")
max_num = int(input("请输入最大下载数量: "))
spider = BaiduImageSpider(keyword, max_num)
spider.run()
代码解析
1. 核心组件说明
- 请求构造:通过分析百度图片的JSON接口构造请求URL
- URL解析:从返回的JSON数据中提取
thumbURL字段 - 并发下载:使用
ThreadPoolExecutor实现多线程下载 - 异常处理:全面捕获网络请求和IO操作异常
2. 关键参数说明
tn=resultjson_com:指定返回JSON格式数据pn和rn:控制分页参数(pn=偏移量,rn=每页数量)word:URL编码后的搜索关键词
3. 反爬策略应对
- User-Agent:模拟Chrome浏览器
- 请求间隔:每次请求间隔1秒
- 会话保持:使用
requests.Session维持会话
进阶优化建议
-
代理IP池:应对IP被封禁问题
proxies = { 'http': 'http://your.proxy.ip:port', 'https': 'https://your.proxy.ip:port' } response = session.get(url, headers=headers, proxies=proxies) -
自动重试机制:
from tenacity import retry, stop_after_attempt, wait_exponential @retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=4, max=10)) def download_image_with_retry(self, url, index): return self.download_image(url, index) -
分布式爬取:使用Scrapy-Redis实现分布式爬虫
-
图片去重:计算图片MD5值避免重复下载
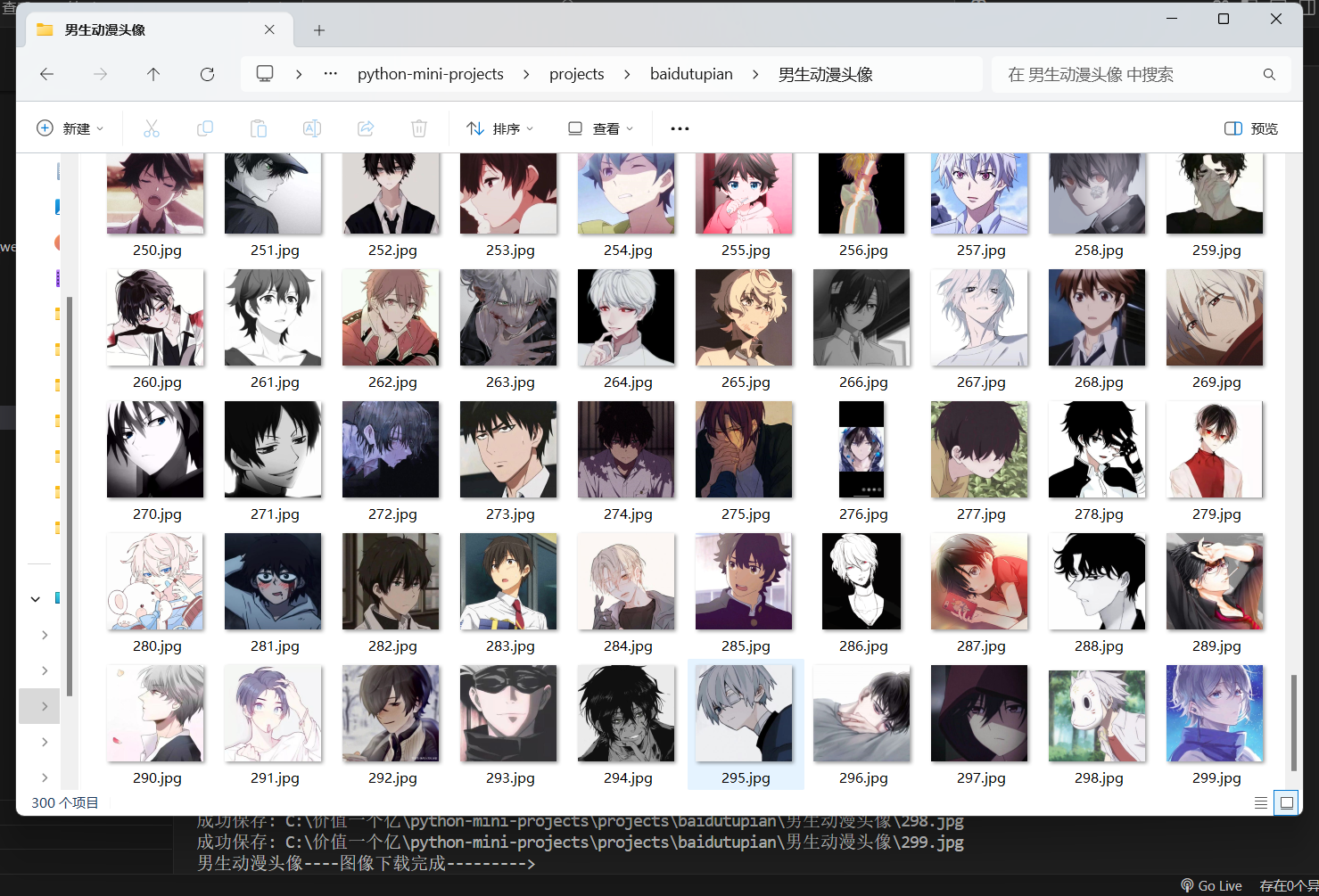
实战
注意事项
- 遵守robots.txt:百度图片的robots.txt对爬虫有一定限制
- 控制请求频率:避免给服务器造成过大压力
- 版权问题:下载的图片仅限个人学习使用
- 异常处理:网络不稳定时需要有完善的错误处理机制

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)