Xilinx FFT IP核配置说明及使用方法(超详细)
FFT是一种DFT的高效算法,称为快速傅立叶变换(fast Fourier transform),它可以将一段有限长的离散信号(比如一段音频采样)从时域(振幅随时间变化)转换到频域(信号由哪些频率的正弦波组成)。傅里叶变换是时域一频域变换分析中最基本的方法之一。在数字处理领域应用的离散傅里叶变换(DFT:Discrete Fourier Transform)是许多数字信号处理方法的基础。本文详细介
Xilinx FFT IP核配置说明及使用方法
FFT是一种DFT的高效算法,称为快速傅立叶变换(fast Fourier transform),它可以将一段有限长的离散信号(比如一段音频采样)从时域(振幅随时间变化)转换到频域(信号由哪些频率的正弦波组成)。傅里叶变换是时域一频域变换分析中最基本的方法之一。在数字处理领域应用的离散傅里叶变换(DFT:Discrete Fourier Transform)是许多数字信号处理方法的基础。
一、FFT IP核配置界面参数说明
1、Configuration
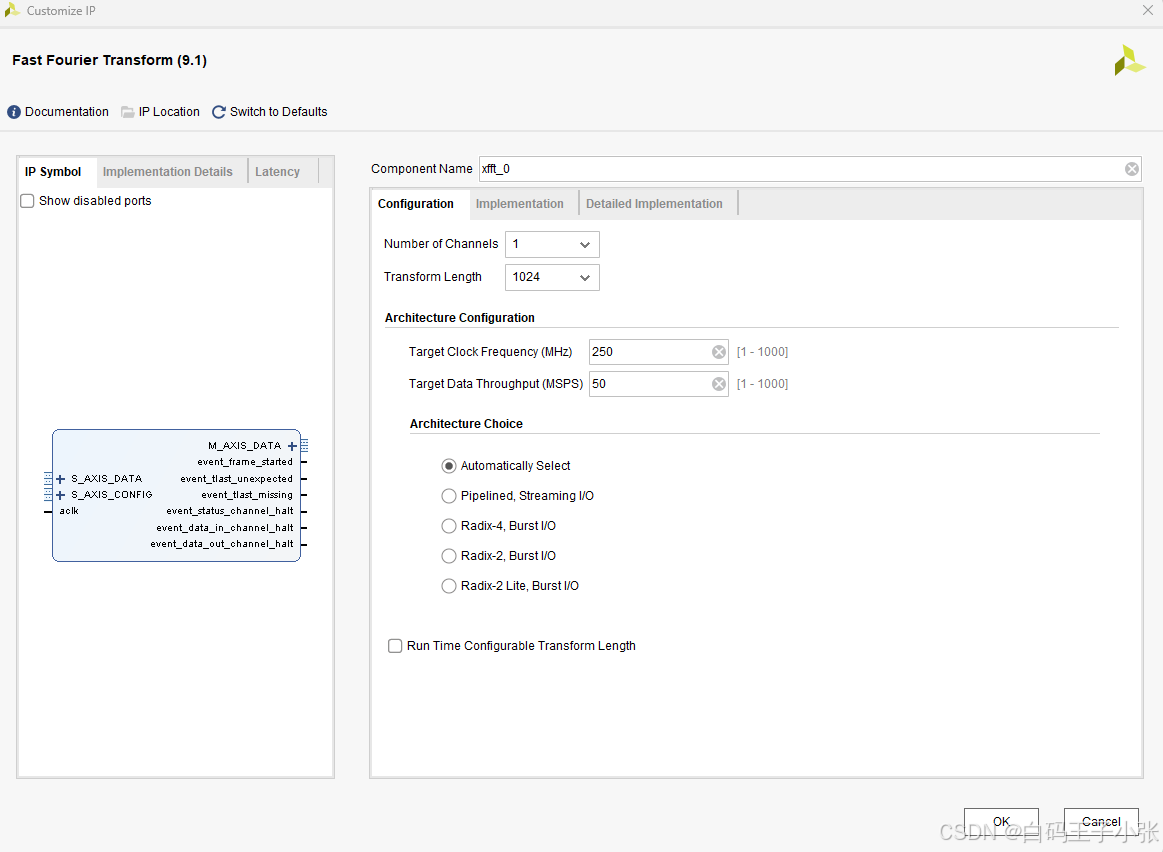
- Number of Channels:输入数据的通道,配置有几路数据进行FFT运算。在1 ~ 12之间选择通道数。支持多通道操作三种Burst I/O架构。当使用多通道时,控制逻辑是共享数据路径,节省资源,但是额外的扇出和路由可能会减少可实现的时钟速率。对于浮点格式(伪格式和本机格式),通道必须为1。
- Transform Length:选择所需的FFT点数大小。8到65536的所有2的幂。
- Architecture Configuration
- Target Clock Frequency(MHz):IP核工作时钟频率。
- Target Data Throughput(MSPS):目标数据的采样率(吞吐量)。
Target Clock Frequency和Target Data Throughput仅用于自动选择实现和计算延迟(Architecture Choice中勾选Automatically Select的情况)。IP核不能保证运行在指定的目标时钟频率或目标数据吞吐量。
- Architecture Choice(FFT结构选择)
FFT IP核提供了四种可选择的计算架构,可以在资源和转换时间之间进行权衡,下列所列出的结构从上到下所需要的转换时间依次变长。具体包括:- Automatically Select:自动选择,最终将IP核配置为Pipelined Streaming I/O架构。
- Pipelined Streaming I/O:支持点大小为8到65536。允许连续数据处理,支持原生浮点格式。
- Radix-4 Burst I/O:支持点大小为64到65536。使用迭代方法分别加载和处理数据。使用资源大小比流水线解决方案小,但是转换时间较长。
- Radix-2 Burst I/O:支持点大小为8到65536。使用与Radix-4相同的迭代方法,但蝶形较小。使用资源比Radix-4更少,但是转换时间更长。
- Radix-2 Lite Burst I/O:支持点大小为8到65536。基于Radix-2体系结构,该结构使用时间复用方法使用更小的内核执行蝶形运算,代价是转换时间更长。
- Run Time Configurable Transform Length:选择是否可以在IP核运行时动态配置FFT点数大小(Transform Length)。不勾选时IP核使用更少的逻辑资源,并且在转换时具有更快的最大时钟速度。当选择本机浮点格式或定点SSR>1时,此选项被禁用。
2、Implementation

- Data Format:数据格式。选择输入输出数据样本为定点格式或单精度(32位)浮点格式。当IP核配置为多通道时,浮点格式不可用。
- Scaling Options
- Scaled:缩放(截位),用户自定义的缩放计划决定了FFT各阶段之间数据的缩放方式。
- Unscaled:不缩放(不截位)。
- Block Floating-Point:IP核决定了需要多少缩放才能充分利用的可用动态范围,并将比例因子报告为块指数。
- Rounding Modes:在蝶形运算的输出端,数据路径中的最低有效位需要被截去。这些位可以采用截断方式(Truncated)或使用收敛舍入(Convergent Rounding)(一种无偏舍入方法)进行四舍五入。
- Truncated:截位处理。
- Convergent Rounding:四舍五入。当一个数的小数部分恰好等于二分之一时,收敛舍入法会在该数为奇数时向上舍入,在该数为偶数时向下舍入。使用此方法可以避免在蝶形运算阶段后因截断而引入的直流偏置。选择此选项会增加切片资源的使用量,并由于额外的延迟而导致变换时间略有增加。
- Precision Options
- Input Data Width:输入数据位宽。
- Phase Factor Width:相位因子位宽。
输入数据和相位因子的位宽均可独立配置为8至34位(含)。当数据格式为浮点型时,输入数据位宽固定为32位,相位因子位宽可根据所需的噪声性能和可用资源设置为24或25位。对于原生浮点格式,相位因子位宽固定为32位。对于定点数SSR>1的情况,相位因子位宽固定为19位,当变换长度小于65536时,输入数据位宽可设置为8至18位;当变换长度为65536时,输入数据位宽可设置为8至16位。
- Control Signals
- Clock Enable (aclken) :时钟使能信号。
- Synchronous Clear (aresetn):异步复位信号。
如果同时选择同步清零和时钟使能,则同步清零优先于时钟使能。如果不选择某个选项,可以节省部分逻辑资源,并可能实现更高的时钟频率。
- Output Ordering Options
- Output Ordering
- Bit/Digit Reversed Order:位/数字反转输出。基于Radix-2的架构(Pipelined Streaming I/O、Radix-2 Burst I/O和Radix-2 Lite Burst I/O)提供位逆序排列,而基于Radix-4的架构(Radix-4 Burst I/O)提供数字逆序排列。
- Natural Order:顺序输出。对于Pipelined Streaming I/O架构,选择自然顺序输出会导致核心使用的内存增加。对于突发I/O架构,选择自然顺序输出会增加整体变换时间,因为需要一个单独的卸载阶段。
- Cyclic Prefix Insertion:循环前缀插入。当输出顺序为自然顺序时,可选择循环前缀插入。除原生浮点SSR流水线流I/O架构外,其他所有架构均支持循环前缀插入,通常用于OFDM无线通信系统。对于原生浮点型SSR和定点型SSR>1流水线式流I/O架构,输出顺序固定为自然顺序,但这些架构中没有循环前缀插入。
- Output Ordering
- Optional Output Fields
- XK_INDEX:XK_INDEX 是数据输出通道中的可选字段。
- OVFLO:OVFLO 在数据输出通道和状态通道中均为可选字段。
- 当选择原生浮点或固定点 SSR>1 时,均不存在 XK_INDEX 和 OVFLO。
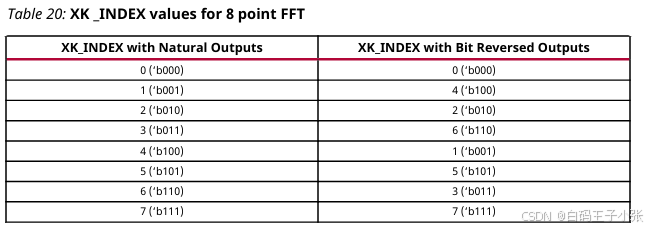
XK_INDEX字段(如果出现在数据输出通道中)给出了与当前呈现的XK_RE/XK_IM数据相对应的样本编号。对于自然顺序输出,XK_INDEX从0递增到N-1,N为配置的点数。当使用位反转输出时,XK_INDEX覆盖相同的数值范围,但以位(或数字)反转的方式排列。
例如,当进行8点FFT运算时,XK_INDEX取值如下表所示:
如果使用循环前缀插入,则首先卸载循环前缀,XK_INDEX 从(点数)减去(循环前缀长度)开始计数,直到(点数)减 1。在循环前缀卸载完成后,或当循环前缀长度为零时,整个输出数据帧被卸载。此后,XK_INDEX 像之前一样从 0 计数到(点数)减 1。循环前缀插入仅在自然顺序输出时才可能实现。
- Throttle Schemes
在性能和数据时序要求之间选择权衡。- Non Real Time:非实时模式对数据的提供和消耗时间没有限制,但设计可能更大且更慢。
- Real Time:实时模式通常可实现更小、更快的设计,但对数据的提供和消耗时间有严格限制。
3、Detailed Implementation
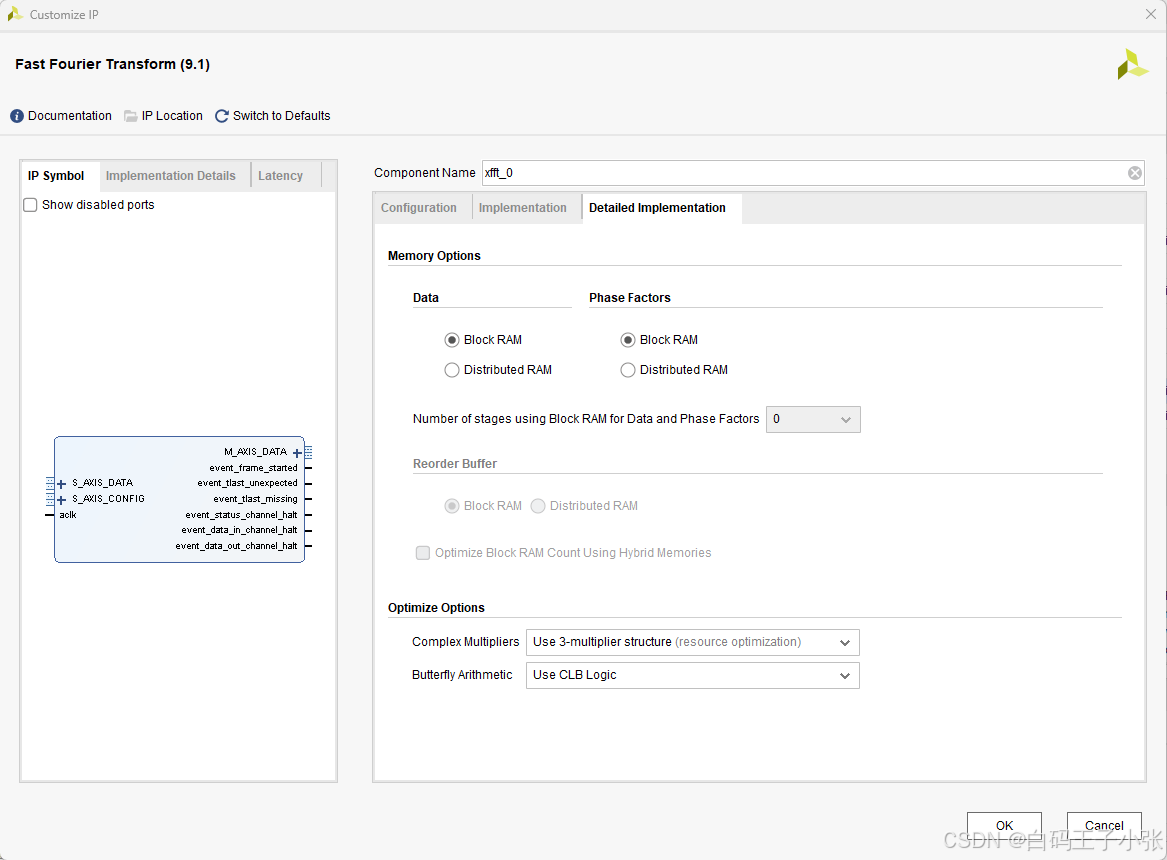
- Memory Options
- Data And Phase Factors (Burst I/O architectures):对于突发 I/O 架构,数据和相位因子存储可以使用块 RAM 或分布式 RAM。对于所有等于或小于 1024 点的点数,数据和相位因子存储均可位于分布式 RAM 中。
- Data And Phase Factors (Pipelined Streaming I/O):在流水线流式I/O架构中,数据可以部分存储在块RAM中,部分存储在分布式RAM中。从输入端开始计算的每一级流水线,所使用的数据和相位因子存储器都比前一级更小。您可以选择使用块RAM来存储数据和相位因子的流水线级数,后续级则使用分布式RAM。IDE上显示的默认设置在这两者之间提供了良好的平衡。如果输出顺序为自然顺序,则用于重排缓冲区的存储器可以是块RAM或分布式RAM。当点数小于或等于1024时,重排缓冲区可以使用分布式RAM。当流水线流I/O架构选择块浮点时,需要使用RAM缓冲区来存储自然顺序和位反转顺序的输出数据。在这种情况下,重排序缓冲区选项仍然可用,并且对于所有小于2048点的尺寸,可以选择分布式RAM。
- Optimize Options
- Complex Multipliers:复数乘法器实现选项。
- Use CLB logic:所有复数乘法器均使用片上逻辑构建。这适用于性能要求较低的目标应用,或目标器件中DSP片数量较少的情况。
- Use 3-multiplier structure (resource optimization):所有复数乘法器均采用三个实数乘法、五次加/减运算的结构,其中乘法器使用DSP片。这种结构可减少DSP片的数量,但会占用部分slice逻辑资源。该结构可利用DSP片中的预加法器,从而减少或避免额外的slice逻辑需求,并提升性能。
- Use 4-multiplier structure (performance optimization):所有复数乘法器均采用四个实数乘法和两个加/减运算的结构,利用DSP片实现。这种结构以消耗更多的专用乘法器为代价,实现了最高的时钟性能。在带有DSP片的器件中,加/减运算在DSP片内部实现。对于原生浮点数据格式和定点SSR>1的情况,采用四乘法器结构。
- Butterfly Arithmetic
- Use CLB logic:所有蝶形阶段均使用Slice逻辑资源构建。
- Use XtremeDSP Slices:此选项强制所有蝶形运算级均使用DSP片中的加法器/减法器实现。对于原生浮点数据格式和定点SSR>1,蝶形运算级使用DSP片实现。
- Complex Multipliers:复数乘法器实现选项。
二、IP核接口信号说明
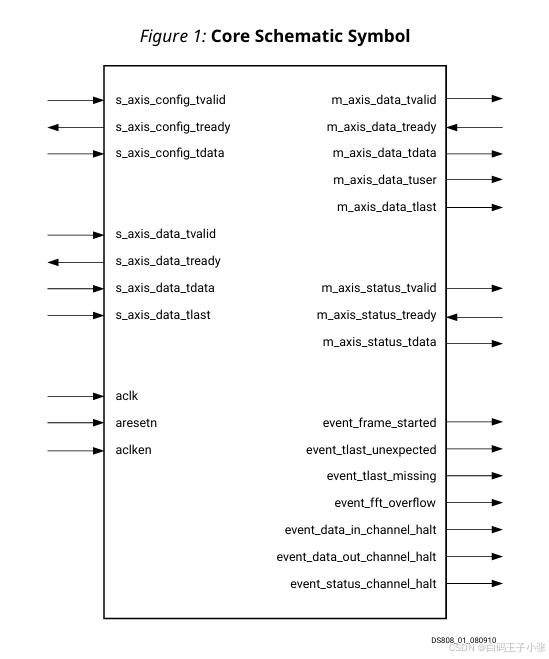
1、时钟/复位接口
- aclk:同步时钟。
- aresetn:低电平有效的同步清零(可选,优先级始终高于 aclken)。需要至少两个时钟周期的 aresetn有效脉冲。该信号可选择性配置。
- aclken:时钟使能,高电平有效。该信号可选择性配置。
2、数据配置接口
(1)接口信号
- s_axis_config_tvalid:外部配置数据输入有效信号。
- s_axis_config_tready:握手信号,表示IP核准备好接收配置数据了。
- s_axis_config_tdata:外部输入配置数据。
配置通道 (s_axis_config) 是一个 AXI 通道,在其 TDATA 接口中传输下表中的字段: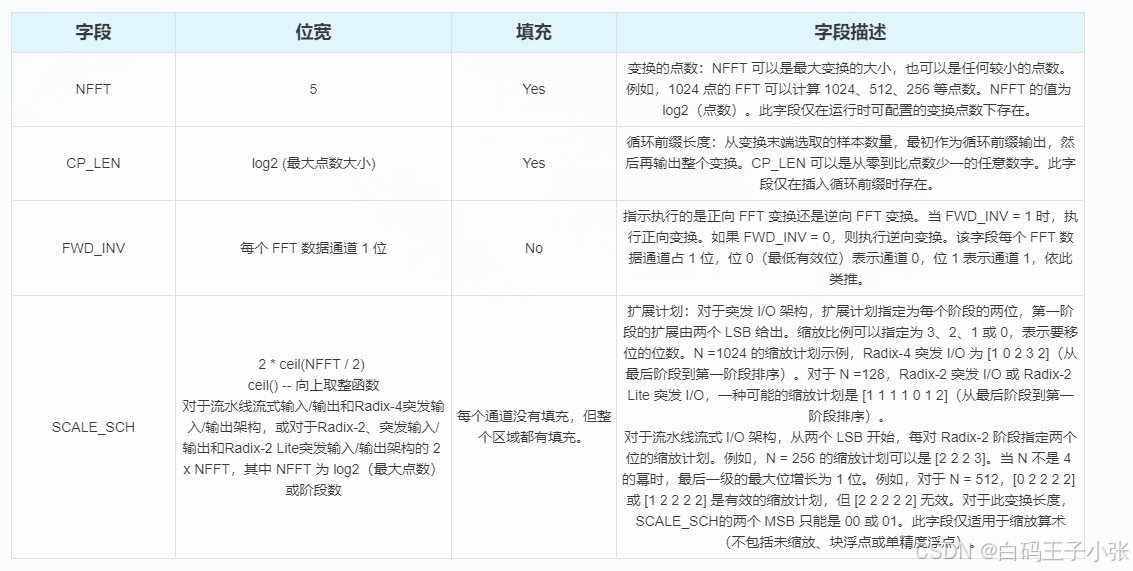
配置字段按以下顺序打包到 s_axis_config_tdata 信号中(从最低有效位开始):
(1)(可选) NFFT 加填充
(2)(可选) CP_LEN 加填充
(3)FWD/INV
(4)(可选) SCALE_SCH
可选字段以虚线显示。s_axis_config_tdata 的总线宽度可能超过容纳所有字段(包括 SCALE_SCH)所需的宽度,即使 SCALE_SCH 字段经过填充以确保宽度为 8 位的倍数。多余的位未使用,因此在综合时会被优化掉。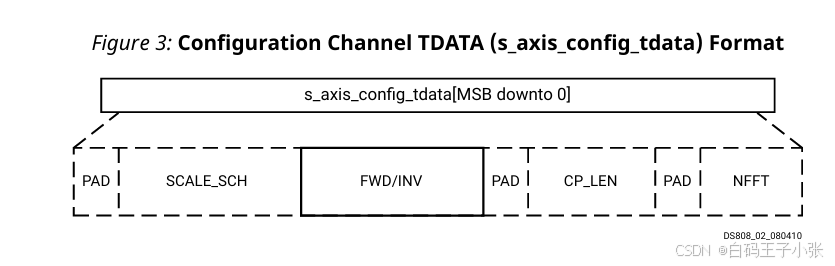
(2)举个栗子
该IP核具有可配置的变换大小,最大为128点,支持循环前缀插入和3个FFT通道。该核心需要配置为执行8点变换,对通道0和1执行逆变换,对通道2执行正向变换。需要4点循环前缀。各字段的取值如下表所示。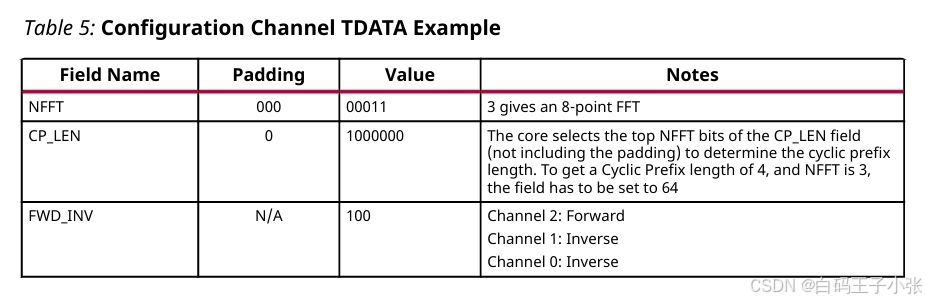
这给出了一个19位的向量长度。由于所有AXI通道必须对齐到字节边界,因此需要5个位的填充,使得s_axis_config_tdata长度为24位。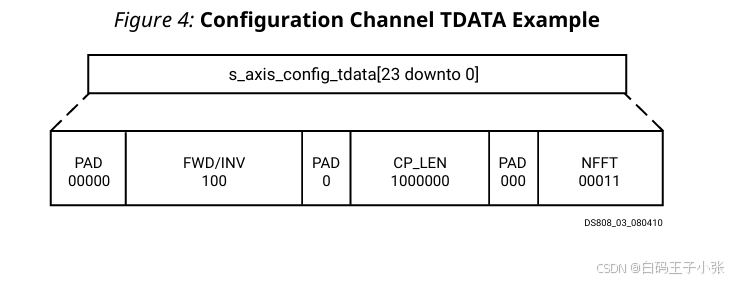
3、数据输入接口
(1)接口信号
- s_axis_data_tvalid:外部输入给IP核的数据有效标志。
- s_axis_data_tready:握手信号,表示IP核准备好接收数据了。
- s_axis_data_tdata:外部输入给IP核的数据。
- s_axis_data_tlast:由外部主控在数据帧的最后一个采样时刻拉高。该信号除用于生成
event_tlast_unexpected 和 event_tlast_missing 事件外,IP核不作他用。
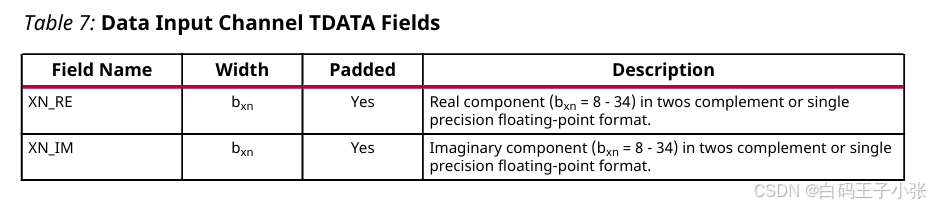
- XN_RE:实部 (bxn = 8 - 34) 以二进制补码或单精度浮点格式表示。可填充。
- XN_IM:虚部 (bxn = 8 - 34) 以二进制补码或单精度浮点格式。可填充。
如果带有填充的所有字段尚未在8位边界结束,应将其扩展到下一个8位边界。IP会忽略填充位的值,因此它们可以设置为任意值。将其连接到固定值可以帮助减少设备资源的使用。然后,这些字段会在设计中的每个通道重复出现。
SSR:Super Sample Rate(超采样率):本地浮点格式和定点格式支持每个时钟周期多个采样。对于本地浮点格式,SSR的可用值为2、4、8、16、32和64。对于定点格式,SSR的值为1、2和4。对于伪浮点格式,SSR固定为1。
(2)多通道和非SSR
数据字段按以下顺序打包到 s_axis_data_tdata 信号中(从最低有效位开始):
- 通道0的XN_RE加上填充
- 通道0的XN_IM加上填充
- (可选)通道1的XN_RE加上填充
- (可选)通道1的XN_IM加上填充
- (可选)通道2的XN_RE加上填充
- (可选)通道2的XN_IM加上填充
- 等等,一直到通道11
可选字段显示为虚线。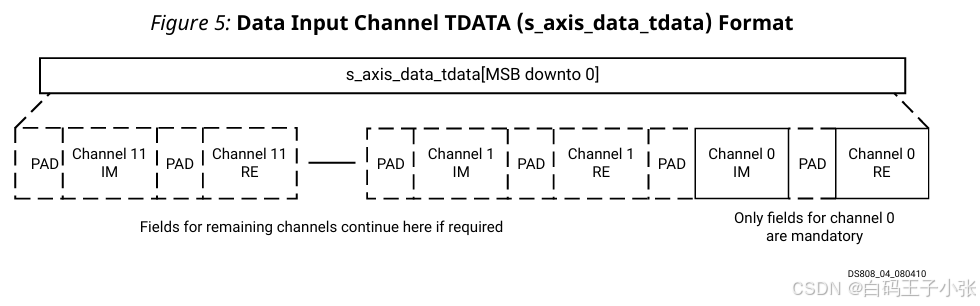
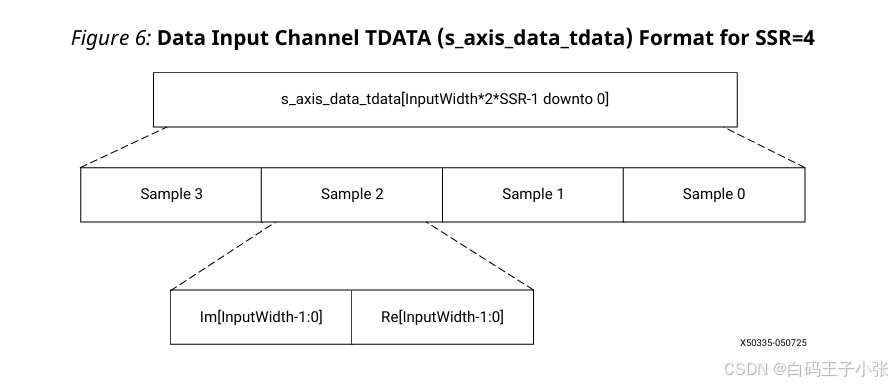
(3)单通道和SSR
SSR 的数据字段按以下顺序打包到 s_axis_data_tdata 信号中(从最低有效位开始):
- 样本0的XN0_RE
- 样本0的XN0_IM
- 样本1的XN1_RE
- 样本1的XN1_IM
- (可选)样本2的XN2_RE
- (可选)样本2的XN2_IM
- (可选)样本3的XN3_RE
- (可选)样本3的XN3_IM
(4)举个栗子
IP已配置为具有两个12位数据的FFT数据通道。
通道0的示例值如下:
- Re = 0010 1101 1001
- IM = 0011 1110 0110
通道1的示例值如下:
- Re = 0111 0000 0000
- IM = 0000 0000 0000
这些字段取以下表格中的值:
这给出了一个64位的字段长度。
4、数据输出接口
(1)接口信号
- m_axis_data_tvalid:IP核输出,表示输出数据有效。
- m_axis_data_tready:由外部从设备置位,以指示其已准备好接收数据。仅在非实时模式下存在。
- m_axis_data_tdata:输出处理后的样本数据 XK_RE 和 XK_IM。
- m_axis_data_tuser:输出额外的样本数据信息,例如XK_INDEX、OVFLO和BLK_EXP
- m_axis_data_tlast:由IP核在数据帧的最后一个采样时刻拉高。
数据输出通道包含变换的实部和虚部结果,这些结果在 TDATA 上传输。此外,TUSER 携带与 TDATA 上样本数据相关的每样本状态信息。此状态信息供直接处理数据样本的下游从设备使用。由于它与数据在同一通道中传输,因此不会失去同步。以下信息被归类为每个样本状态:
- XK_INDEX
- 每个 FFT 通道的块指数 (BLK_EXP)
- 每个 FFT 通道的溢出 (OVFLO)
数据输出通道(m_axis_data)是一个 AXI 通道,其 TDATA 信号中携带下表中的各个字段。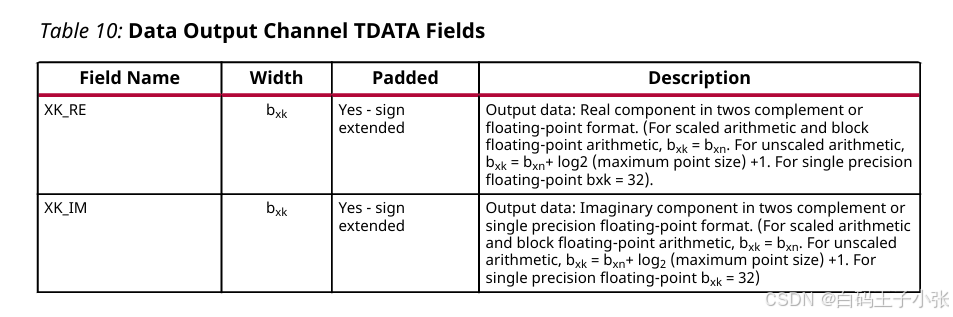
- XK_RE:输出数据。实部使用二进制补码或浮点格式。(对于缩放运算和块浮点运算,bxk = bxn。对于非缩放运算,bxk = bxn × log2(最大点数)+ 1。对于单精度浮点数,bxk = 32)。可填充(符号扩展)。
- XK_IM:输出数据。以二进制补码或单精度浮点格式表示的虚数分量。(对于缩放算术和块浮点算术,bxk = bxn。对于未缩放算术,bxk = bxn × log2(最大点数) + 1。对于单精度浮点,bxk = 32)。可填充(符号扩展)。
如果字段尚未在 8 位边界上结束,则所有字段都将被符号扩展到下一个 8 位边界。然后,这些字段会在设计中的每个 FFT 通道上重复。
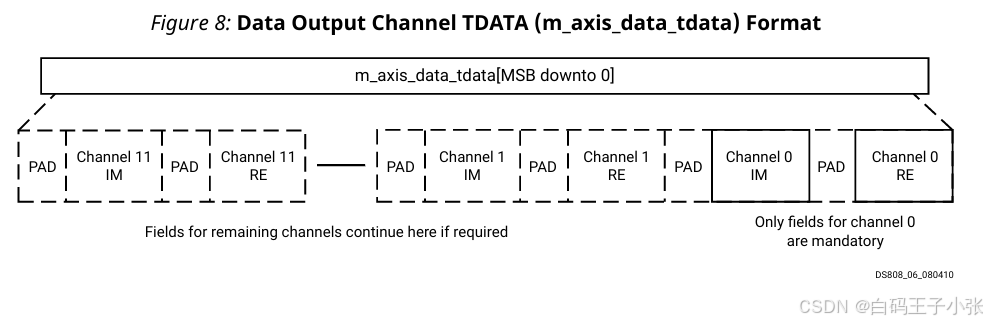
(2)多通道和非SSR
数据字段按以下顺序(从最低有效位开始)打包到 s_axis_data_tdata 信号中:
- XK_RE 加上通道 0 的填充
- XK_IM 加上通道 0 的填充
- (可选)XK_RE 加上通道 1 的填充
- (可选)XK_IM 加上通道 1 的填充
- (可选)XK_RE 加上通道 2 的填充
- (可选)XK_IM 加上通道 2 的填充
- 等等,直到通道 11
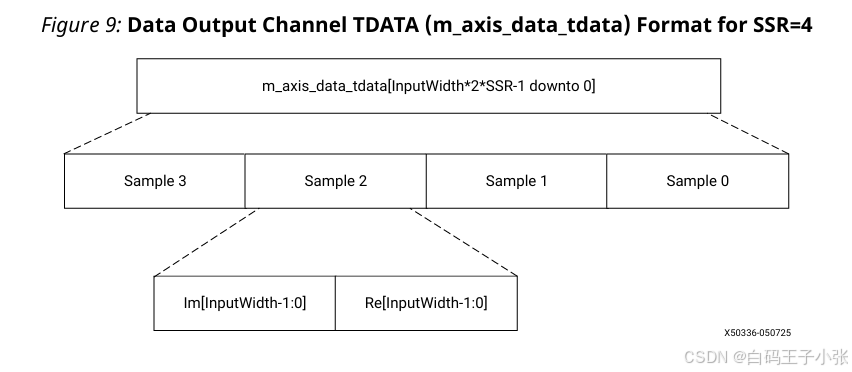
(3)单通道和SSR
SSR 的数据字段按以下顺序打包到 m_axis_data_tdata 信号中(从最低有效位开始):
- 样本0的XK0_RE
- 样本0的XK0_IM
- 样本1的XK1_RE
- 样本1的XK1_IM
- (可选)样本2的XK2_RE
- (可选)样本2的XK2_IM
- (可选)样本3的XK3_RE
- (可选)样本3的XK3_IM
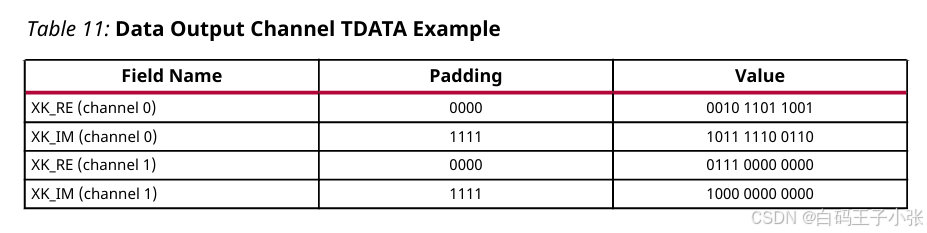
(4)举个栗子
IP已配置为具有两个 FFT 数据通道,每个通道输出 12 位数据。
FFT 为通道 0 产生以下示例结果:
- Re = 0010 1101 1001
- IM = 1011 1110 0110
FFT 为通道 1 产生以下示例结果:
- Re = 0111 0000 0000
- IM = 1000 0000 0000

(5)TUSER字段
数据输出通道在其 TUSER信号中携带下表中的字段: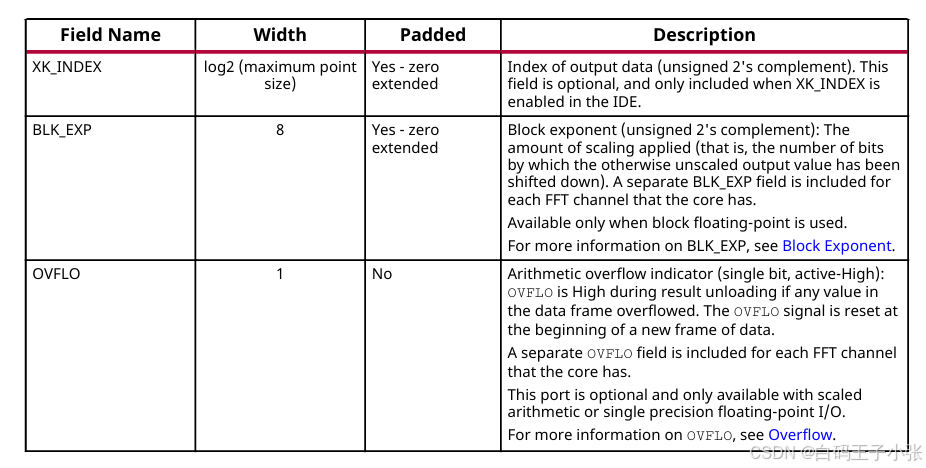
- XK_INDEX:输出数据索引(无符号二进制补码)。此字段为可选,仅在IDE中启用XK_INDEX时包含。可填充(0填充)。
- BLK_EXP:块指数(无符号二进制补码):应用的缩放量(即未缩放输出值向下移动的位数)。每个核心的 FFT 通道都有一个单独的BLK_EXP 字段。仅在使用分块浮点时可用。可填充(0填充)
- OVFLO:算术溢出指示器(单比特,高电平有效):如果数据帧中的任何值发生溢出,结果卸载期间 OVFLO 为高电平。OVFLO信号在新数据帧开始时重置。对于核心拥有的每个 FFT 通道,都包括一个单独的 OVFLO字段。该端口是可选的,仅在使用缩放算术或单精度浮点输入/输出时可用。不可填充。
所有带有填充的字段如果尚未在8位边界上结束,应扩展填充0以对齐到下一个8位边界数据字段按以下顺序打包到 m_axis_data_tuser 信号中(从最低有效位开始):
- (可选)XK_INDEX 加填充
- (可选)通道 0 的 BLK_EXP 加填充
- (可选)通道 1 的 BLK_EXP 加填充,依此类推
- (可选)通道 0 的 OVFLO
- (可选)通道 1 的 OVFLO,依此类推
- 填充以使 TUSER 对齐到 8 位。仅在存在 OVFLO 时需要。
核心无法同时配置 BLK_EXP 和 OVFLO。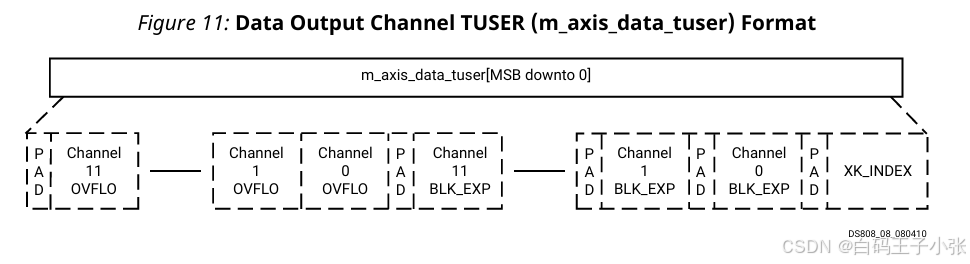
可选字段显示为虚线。由于所有字段都是可选的,因此可以配置核心,使 TUSER 没有任何字段。在这种情况下,它会自动从核心界面中移除。
栗子1
该核心已配置为具有两个 FFT 数据通道、128 点变换大小、溢出和 XK_INDEX。第三个样本(XK_INDEX = 3)在通道 0 上发生溢出,但在通道 1 上没有。XK_INDEX 长度为 7 位。字段取以下表中的值。
这给出了一个 10 位的向量长度。由于所有 AXI 通道必须对齐到字节边界,因此需要 6 位填充位,使 m_axis_data_tuser 的长度为 16 位。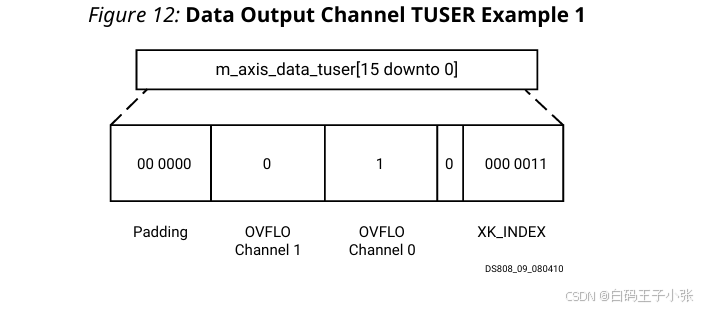
栗子2
内核已配置为具有两个 FFT 数据通道、块指数,但没有 XK_INDEX。通道 0 的输出样本块指数为 4,通道 1 的输出样本块指数为 31。
这会产生一个16位的向量长度,因此不需要更多的填充。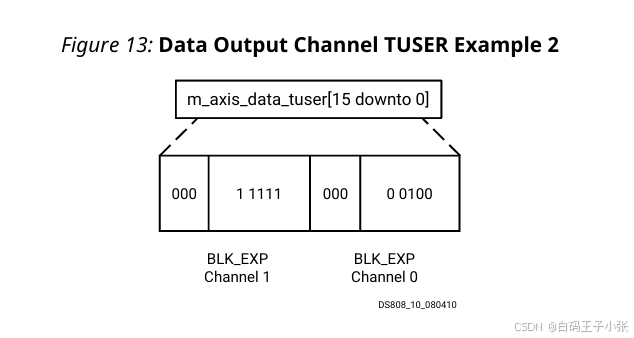
5、IP状态接口
(1)接口信号
- m_axis_status_tvalid:IP核输出的状态数据有效标志。
- m_axis_status_tready:由外部从设备置位,以指示其已准备好接收状态数据。仅在非实时模式下存在。
- m_axis_status_tdata:IP核输出的状态数据BLK_EXP 或者 OVFLO.。
状态通道包含每帧的状态信息,即与整帧数据相关的信息。这是为下游从属设备准备的,它们不直接操作数据,但可能需要了解这些信息以控制系统的其他部分。状态信息发送在帧中的具体位置取决于状态信息的性质。以下信息被归类为每帧状态:
- 每个通道的 BLK_EXP
- 每个通道的 OVFLO
核心无法配置为同时具有 BLK_EXP 和 OVFLO。BLK_EXP 状态信息在帧开始时发送,OVFLO 状态信息在帧结束时发送。
状态通道在其 TDATA 向量中包含下表中的字段: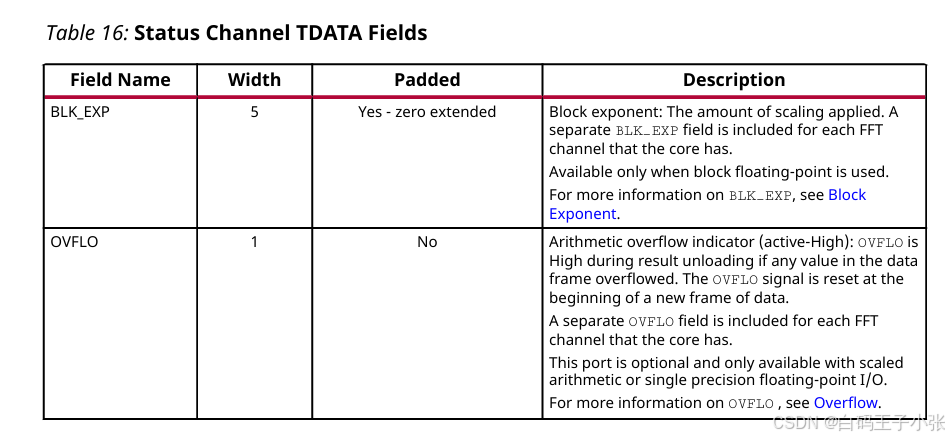
- BLK_EXP:块指数:应用的缩放量。核心的每个 FFT 通道都包含一个单独的 BLK_EXP 字段。仅在使用块浮点时可用。
- OVFLO:算术溢出指示器(高电平有效):如果数据帧中的任何值溢出,则在结果卸载期间,OVFLO 为高电平。OVFLO 信号在新数据帧开始时复位。对于核心拥有的每个 FFT 通道,都会包含一个独立的 OVFLO 字段。此端口是可选的,仅在使用缩放算术或单精度浮点输入/输出时可用。
所有带填充的字段如果尚未在8位边界上结束,应扩展填充0以对齐到下一个8位边界。
数据字段按以下顺序(从最低有效位开始)打包到 m_axis_status_tdata 信号中:
- (可选)通道0的BLK_EXP加上填充
- (可选)通道1的BLK_EXP加上填充,依此类推
- (可选)通道0的OVFLO
- (可选)通道1的OVFLO,依此类推
- 填充以使TDATA对齐到8位,仅在存在OVFLO时需要
核心无法配置为同时具有 BLK_EXP 和 OVFLO。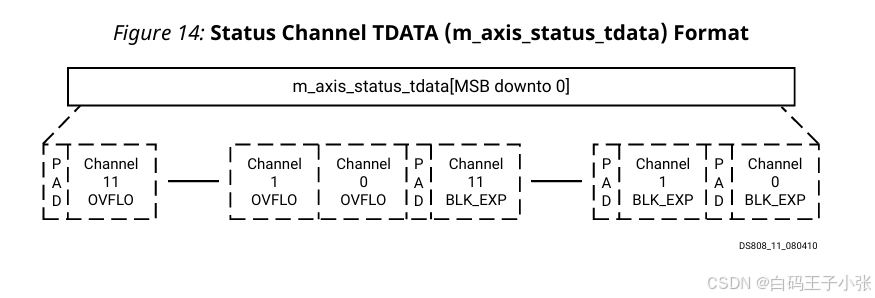
可选字段显示为虚线。由于所有字段都是可选的,因此可以配置核心,使 TDATA 没有任何字段。在这种情况下,整个状态通道会自动从核心界面中移除。
(2)举个栗子1
IP已配置为具有四个FFT数据通道和溢出。当前帧在通道2和通道3中存在溢出。
这给出了一个 4 位的向量长度。由于所有 AXI 通道必须对齐到字节边界,因此需要 4 位填充位,使 m_axis_status_tdata 的长度为 8 位。
(2)举个栗子2
核心已配置为拥有一个 FFT 数据通道和溢出。当前帧不包含溢出。
这给出了一个向量长度为1位。由于所有AXI通道必须对齐到字节边界,因此需要7个位的填充,使得m_axis_status_tdata的长度为8位。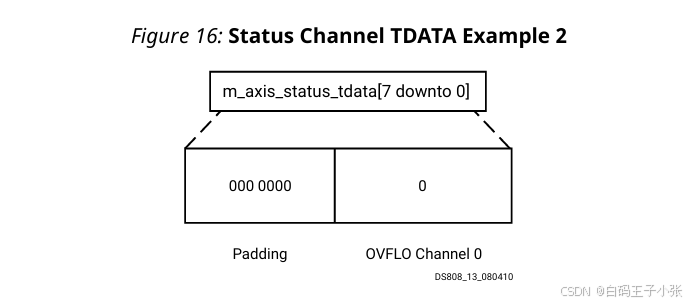
6、IP事件接口
- event_frame_started:IP核开始处理一帧新的数据时拉高。
- event_tlast_unexpected:s_axis_data_tlast信号拉高后,IP核判断当前数据不是数据帧的最后一个数据的时候拉高该信号,表示tlast信号错误。
- event_tlast_missing:当一帧数据最后一个数据到来时,s_axis_data_tlast仍然是低电平,该信号拉高,表示tlast信号丢失。
- event_fft_overflow:数据溢出时拉高。event_data_in_channel_halt: 当IP核从数据输入通道请求数据但未获得数据时拉高。
- event_data_out_channel_halt:当IP核试图将数据写入数据输出通道但无法这样做时拉高该信号。仅在非实时模式下存在。
- event_status_channel_halt:当IP核试图将数据写入状态通道但无法这样做时拉高该信号。仅在非实时模式下存在。
三、AXI接口时序
FFT IP核使用AXI4-Stream 协议完成数据的输入和输出。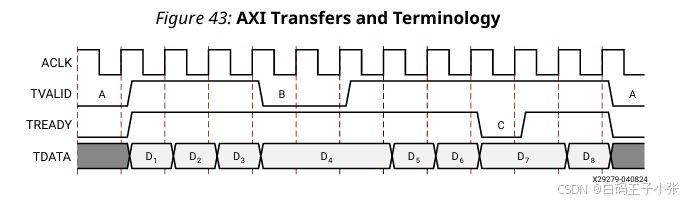
在主设备将 TVALID 拉高后,必须保持拉高状态(并保持相关数据稳定),直到从设备将 TREADY 拉高。
要将一帧数据加载到IP核中,提供 XN_RE 和 XN_IM 数据的上游主设备必须在准备好时发送它。如果IP核可以接收它(即 s_axis_data_tready = 1),则数据会在IP核中缓冲,直到可以处理为止。如果IP核无法接收它(即 s_axis_data_tready = 0),AXI 通道中会出现从设备等待状态,主设备被阻塞。上图显示了 8 点 FFT 样本数据的加载过程。上游主设备驱动 TVALID,而IP核驱动 TREADY。在这种情况下,主设备和核心都会插入等待状态。
IP核发送一帧的工作方式类似,只是这次IP核是主设备。当它有 XK_RE 和 XK_IM 数据要发送时,它会发送 TVALID 信号(m_axis_data_tvalid = 1)。下游的从设备在处理完样本数据后可以选择接收数据(m_axis_data_tready = 1)或不接收(m_axis_data_tready = 0)。前图还显示了 8 点 FFT(无循环前缀)的样本数据卸载。IP核驱动 TVALID,下游从设备驱动 TREADY。这种情况下,IP核和从设备都插入等待状态。
上面的描述仅适用于IP核配置为使用非实时模式的情况。在实时模式下情况有所不同,实时模式用于以牺牲加载和卸载数据的灵活性为代价来创建更小更快的设计。当IP核配置为使用实时模式时,会发生以下情况:
- 数据输出通道(m_axis_data_tready)的TREADY信号被移除
- 状态通道(m_axis_status_tready)的TREADY信号被移除
- 当帧加载开始后,数据输入通道的TVALID信号会被忽略
因为IP核上没有这些信号。两个从设备都必须能够在IP核产生数据的每个时钟周期立即响应(m_axis_data_tvalid 或 m_axis_status_tvalid 置高)。如果从设备不能立即响应,则数据将丢失。
1、无循环前缀插入的 Pipelined Streaming I/O架构
当选择流水线流式 I/O 且未使用循环前缀时,IP核可以在处理和输出先前帧的同时重叠加载新帧。如果上游主设备在上一帧的最后一个符号之后立即提供新帧的第一个符号,IP核会立即开始加载它。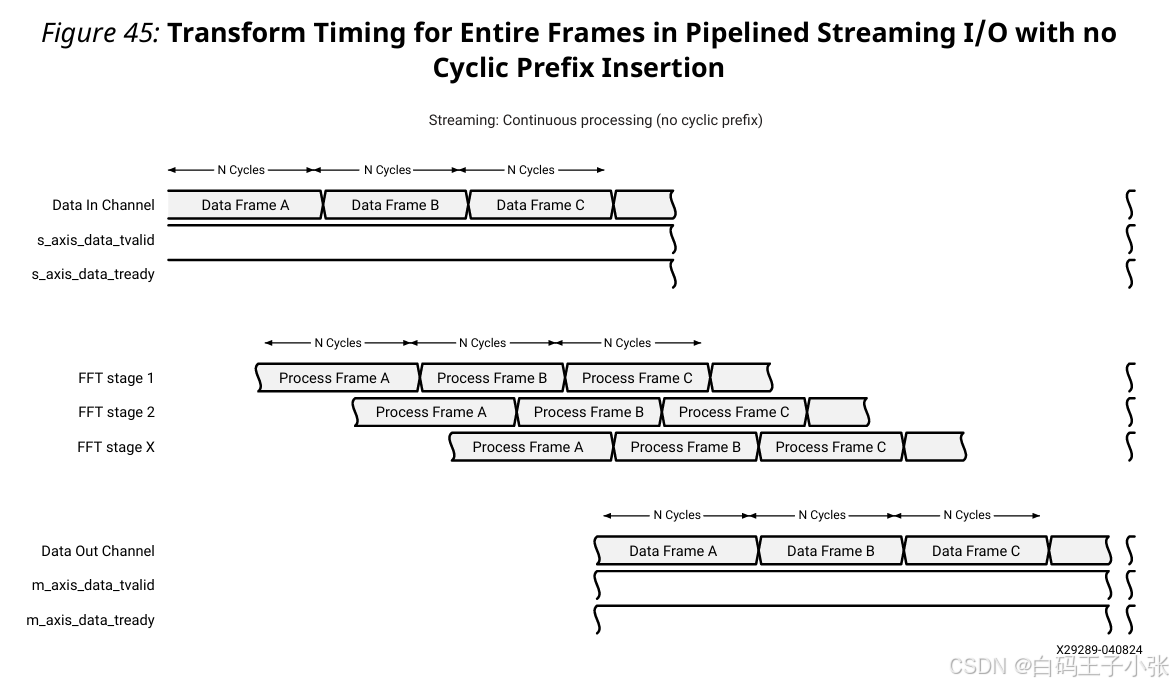
在一个帧被加载和该帧的处理数据可用之间存在延迟。这个延迟取决于在 Vivado IDE 中为核心参数化时选择的选项。然而,当延迟过去后,处理后的帧会连续出现。
2、带循环前缀插入的 Pipelined Streaming I/O架构
如果使用循环前缀插入,则从IP核输出的样本比加载的样本更多。因此,IP核无法连续地流式传输帧,必须在每帧输入数据之间插入一个循环前缀长度的时钟周期间隔,以适应卸载循环前缀所需的额外时钟周期(参见下图)。这通过数据输入通道上的 TREADY 信号表示。当信号为低电平时,允许IP核有时间卸载循环前缀。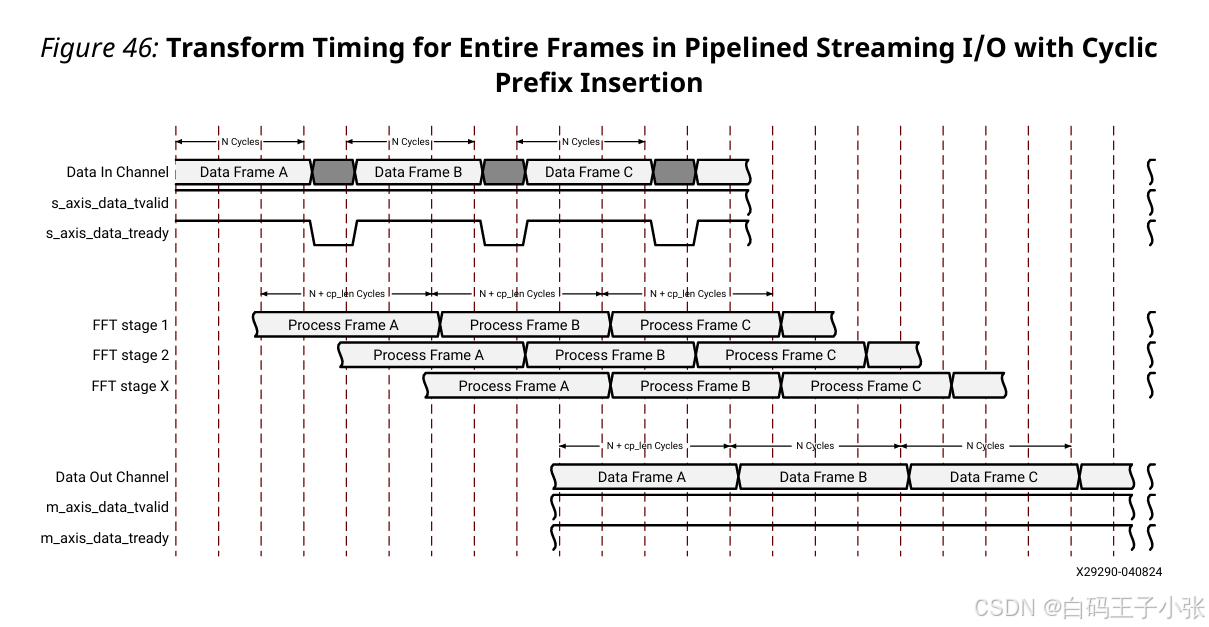
3、Burst I/O架构
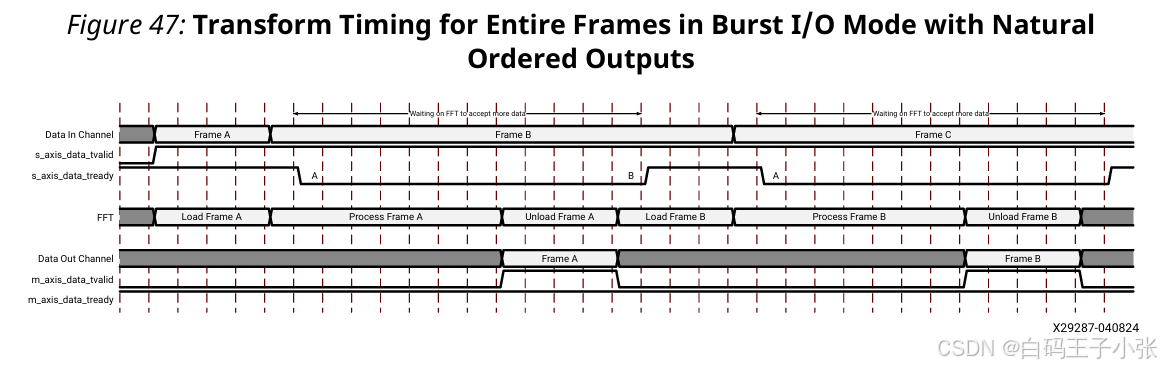
突发I/O架构无法像流水线流式I/O架构那样允许帧重叠。当使用自然顺序输出时,必须先处理并输出一个帧,IP核才能开始加载下一个帧。
(1)自然顺序输出
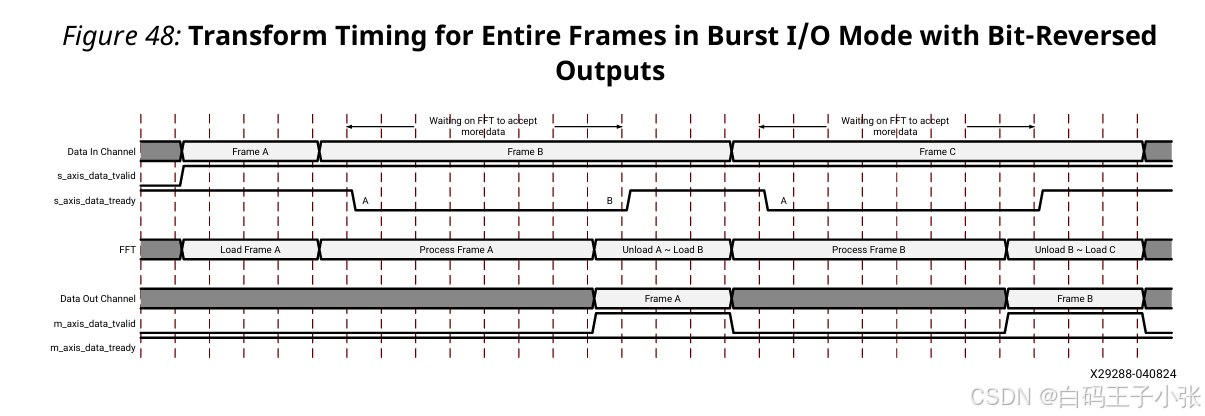
(2)位反转顺序输出

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)