M2WLLM:基于大语言模型的多模态多任务超短期风电预测算法
风能并入电网需要准确的超短期风电预测,以确保电网稳定性和优化资源配置。本研究引入了 M2WLLM,这是一种创新模型,它利用大型语言模型 (LLM)的功能以粒度时间间隔预测风电输出。M2WLLM 通过无缝集成文本信息和时间数值数据,克服了传统和深度学习方法的局限性,通过多模态数据显着提高了风电预测的准确性。其架构具有。
目录
文章地址:https://doi.org/10.1016/j.inffus.2025.103541
摘要:风能并入电网需要准确的超短期风电预测,以确保电网稳定性和优化资源配置。本研究引入了 M2WLLM,这是一种创新模型,它利用大型语言模型 (LLM)的功能以粒度时间间隔预测风电输出。M2WLLM 通过无缝集成文本信息和时间数值数据,克服了传统和深度学习方法的局限性,通过多模态数据显着提高了风电预测的准确性。其架构具有提示嵌入器(Prompt Embedder)和数据嵌入(Data Embedder),能够在 LLM 框架内有效融合文本提示和数字输入。数据嵌入器中的语义增强器(Semantic Augmenter)将时间数据转换为 LLM 可以理解的格式,使其能够提取潜在特征并提高预测准确性。对中国三个省份的风电场数据进行的实证评估表明,M2WLLM 在各种数据集和预测范围内始终优于现有方法,例如时间序列生成式预训练转换 (GPT4TS)。结果凸显了法学硕士在超短期预测中提高准确性和鲁棒性的能力,并展示了其强大的少量学习能力。
PART 1:研究背景与意义
一、风能的战略地位
清洁可再生能源核心组成,是全球能源结构转型的关键力量
2024年全球陆上风电新增装机容量预计超100GW,规模化应用趋势显著
二、风电并网的核心挑战
风能具有间歇性、不确定性,大规模并网会破坏电网功率平衡,威胁电网稳定运行
需通过精准预测风电输出,支撑电网调度与资源优化配置
三、超短期预测的关键价值
风电预测按时间尺度分:超短期(分钟几小时)、短期(几小时几天)、中长期(长期规划)
超短期预测直接服务实时电力市场,是电网实时调度、调频调压的核心依据,需求迫切。
PART 2:当前研究综述
一、超短期风电预测主流方法

二、LLM在时间序列预测的应用进展
核心优势:LLM具备强大序列建模能力与预训练知识,可泛化至多领域时序任务。
现有应用:GPT4TS(基于GPT2做时序预测)、STELLM(LLM+季节趋势分解预测风速)、BERT4ST(BERT微调预测风电)。
现存不足:多聚焦结构化数值数据,未充分利用文本语义;缺乏风电预测专属任务设计。
PART 3:研究现存挑战
一、多模态信息利用不足
传统方法(含部分LLM based方法)仅依赖历史风电、NWP等数值数据,忽略文本信息(如任务描述、气象语义)。未发挥LLM的语义理解能力,错失文本数值融合带来的精度提升空间。
二、风电预测任务定制性缺失
缺乏针对风电特性的设计:未解决“风电输出NWP数据”的跨模态联合表示与融合问题,无法适配风电输出的动态性、场景依赖性(如低风速零输出、突发阵风)。
三、少样本场景泛化能力弱
新建成风电场历史数据稀缺,传统模型需大量数据训练,数据不足时精度骤降,现有LLM方法未充分利用预训练知识提升少样本学习性能。
PART 4:文章主旨与主要内容
一、核心主旨
提出M2WLLM(Multimodal multitask LLMbased Wind Power Prediction Model),一款基于大语言模型的多模态多任务超短期风电预测模型,通过融合文本与数值数据,解决现有方法精度低、泛化弱的问题。
二、主要内容
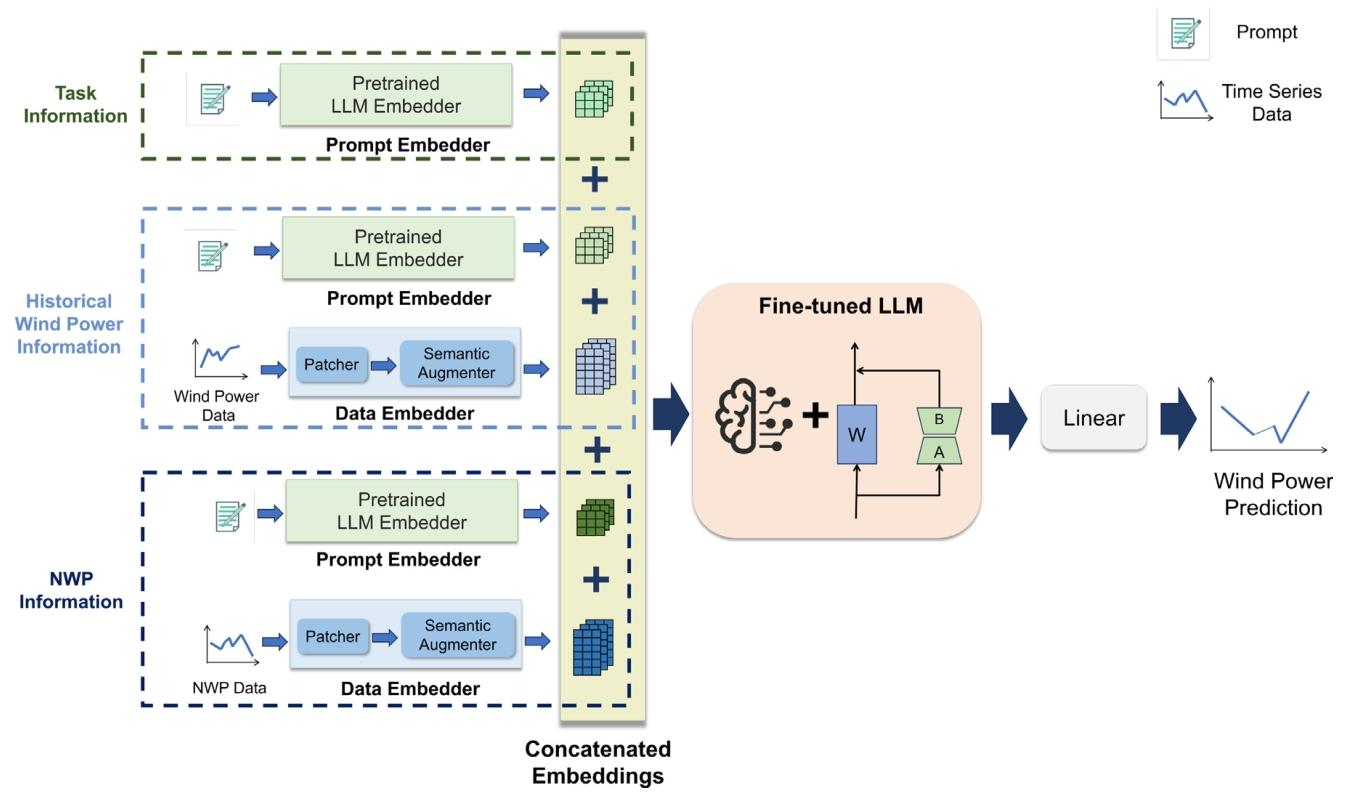
1. 模型架构设计:构建Prompt Embedder(处理文本)、Data Embedder(处理数值)、LoRA微调LLM的三层架构,实现多模态融合。
2. 关键模块开发:设计Semantic Augmenter(将时序数据转化为LLM可理解格式)、Patcher(分割长时序序列)。
3. 实验验证:基于中国3省份风电场数据,对比9种主流方法,验证模型精度、鲁棒性与少样本能力。
4. 消融研究:分析Prompt、Semantic Augmenter、LoRA等模块的作用,以及NWP数据、LLM层数对性能的影响。
PART 5:文章核心创新点
创新点1:多模态融合架构,释放文本数值协同价值
首次将文本提示(任务描述、风电/NWP语义)与时序数值数据联合输入LLM,通过Prompt Embedder(处理文本)与Data Embedder(处理数值)实现双模嵌入,帮助LLM理解任务目标与数据分布,精度优于纯数值方法。
创新点2:高效利用LLM预训练知识,降低微调成本
提出Semantic Augmenter:通过跨注意力机制将时序补丁与LLM预训练词嵌入对齐,让LLM用预训练知识提取隐藏时序特征。采用LoRA(低秩适应)微调:仅训练少量参数(而非全量LLM参数),兼顾预训练知识利用与任务适配,提升少样本能力。
创新点3:多维度全面验证,覆盖实际应用场景
数据集:内蒙古、云南、甘肃3省份风电场数据(2020.38,15分钟间隔,17546样本)
验证维度:多预测 horizon(15min4h)、多对比方法(9种主流模型)、少样本场景(10%100%训练数据),全面验证模型实用性。
PART 6:技术路线与实验平台
一、技术路线
1. 数据准备:收集历史风电输出(功率)、NWP数据(风速、风向、温度),构建文本提示(任务、风电、NWP语义)
2. 多模态嵌入:
文本:Prompt Embedder将文本提示转化为LLM嵌入向量
数值:Data Embedder(Patcher分割时序→Semantic Augmenter跨注意力增强)转化为嵌入向量
3. LLM微调与预测:输入GPT2,通过LoRA微调,经线性层输出预测结果(反归一化后得最终值)
4. 模型优化:以MSE(均方误差)为损失函数,优化LoRA与Semantic Augmenter参数
二、实验程序
1. 数据集设置:训练:验证:测试=3:1:1;输入序列长96(24h),预测序列长16(4h)
2. 实验环境:Ubuntu 18.04,4×NVIDIA RTX 4090(24GB),PyTorch,GPT2为LLM骨干
3. 对比方法:LSTM、TCN、Transformer、Informer、Autoformer、AdaptiveGCN、CNNBiLSTMAtt、GPT4TS(共8种)
4. 评估指标:MAE(平均绝对误差)、RMSE(均方根误差),衡量不同预测horizon性能
PART 7:实验结果与讨论
一、整体预测性能:M2WLLM精度最优
跨数据集、跨horizon领先:如内蒙古15min MAE=3.36MW(GPT4TS为5.12MW),云南4h RMSE=11.59MW(CNNBiLSTMAtt为11.81MW)
原因:多模态融合让LLM理解语义与数值关联,Semantic Augmenter挖掘深层时序特征
二、少样本学习:优势显著
10%训练数据时:M2WLLM性能接近100%数据(云南15min MAE=3.76→2.58)
对比传统方法:Informer用10%数据MAE=14.00,100%数据才降至6.00;M2WLLM 10%数据精度超Informer 100%数据
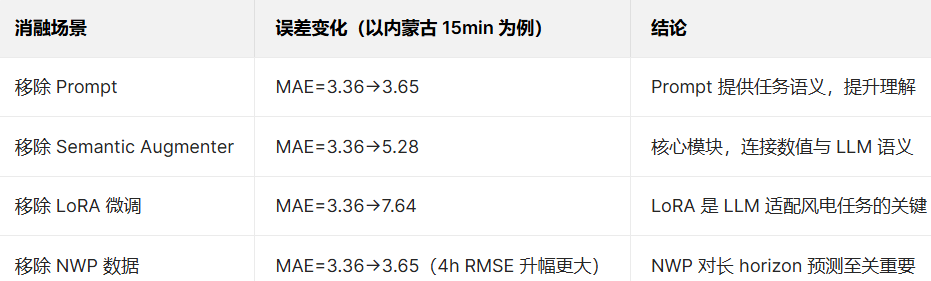
三、消融研究:关键模块不可替代
PART 8:文章结论与未来展望
一、主要结论
1. 精度领先:M2WLLM在3省份数据集、全预测horizon下,MAE/RMSE均超现有方法(含GPT4TS)
2. 多模态有效:文本数值融合充分发挥LLM语义理解能力,Semantic Augmenter是核心桥梁
3. 实用价值高:少样本学习能力强,适配新风电场数据稀缺场景;鲁棒性好,满足电网调度需求
二、未来展望
1. 模型优化:开发风电专属LLM底座,替代通用GPT2,减少计算资源浪费
2. 任务扩展:将方法推广至光伏预测、中短期风电预测,覆盖更广泛新能源场景
3. 效率提升:研究轻量化训练策略,进一步降低LLM微调的计算成本

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)