Whisper 幻觉问题
比如输入噪音或者咳嗽声,输出 “Thank you ” 或者 “Thank you for watching”,猜测可能是由于whisper的训练数据中有大量的youtube的视频数据,在视频结尾一般会有噪音等对应的字幕“Thank you for watching”;实际使用中,如果客户没有指定语种,那么系统会先进行语种识别 再执行语音识别,如果语种识别错误那么语音识别也会出错;但是对于咳嗽等声
whisper是多语种 语音识别 和 语音翻译工具,尤其在英文的识别,准确率较高;但是实际使用中却有各种问题,其中比较严重的一个是幻觉问题:
比如输入噪音或者咳嗽声,输出 “Thank you ” 或者 “Thank you for watching”,猜测可能是由于whisper的训练数据中有大量的youtube的视频数据,在视频结尾一般会有噪音等对应的字幕“Thank you for watching”;
所以如果要使用whisper一般还是需要在某个领域对模型进行微调后在使用;
本文从工程侧给出可以缓解的方法:
1、加提示词:
识别时加提示词如“Transcribe only valid speech, ignore background noise.” 可以提示模型只识别有效的音频,忽略背景噪声等,实际测试有效果但是不明显;

2、使用vad
在模型识别前加入vad,同时要调低 no_speech_threshold 的值(例如 0.2),实际测试可以有效去除背景噪声减少幻觉;但是对于咳嗽等声音不能很好的过滤;
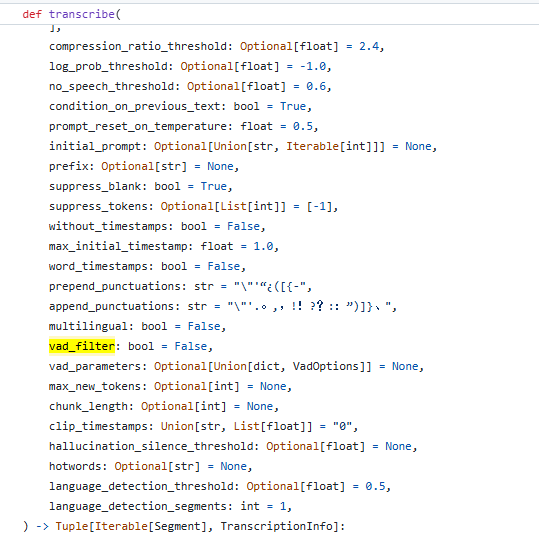
3、 添加suppress_tokens
对于某些领域不希望也确定不会出现某些文本(例如意语识别中包含了法语、俄语等),那么可以将这些文本的token加入到suppress_tokens中,这样可以禁止这些文本的输出;实际测试效果明显;
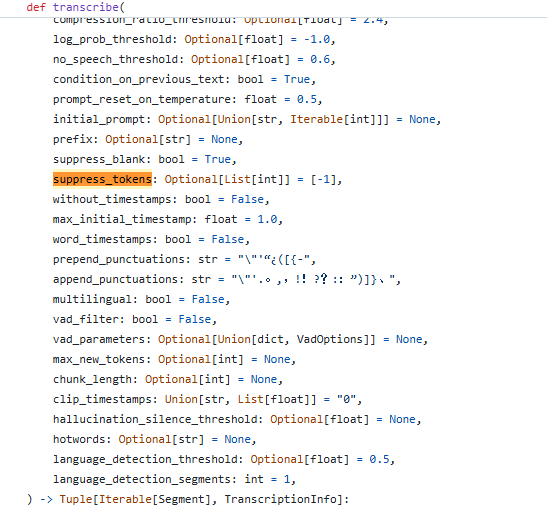
4、禁止语种
实际使用中,如果客户没有指定语种,那么系统会先进行语种识别 再执行语音识别,如果语种识别错误那么语音识别也会出错;例如中文识别时经常会出现 韩语; 如果确定使用中不会出现某些语种,那么可以在语种识别时限制语种的范围;

具体操作可以将语种识别的结果(见上图中的result)中,其它的语音输出概率全部置零;实际测试效果明显;
开源代码:https://github.com/SYSTRAN/faster-whisper
(完)

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)