在 RAG 中,你知道有哪些 Embedding Model 嵌入模型?
目前这个 Embedding 模型相关的榜单被广泛认可,从分类、聚类、语义文本相似性、重排序和检索等多个角度评测排行各种模型,大家可以从上面了解更多的 Embedding 模型。
·
在 RAG 中,常用的 Embedding Model(嵌入模型)主要分为以下几类:
text-embedding-ada-002(2022年12月发布):OpenAI 的第二代模型,支持多语言,性价比高,适合大多数场景(如文档检索、相似度匹配)。text-embedding-3-small(large):OpenAI 推出的第三代高效模型,性能更强,MIRACL( multi-language retrieval )比上代从 31.4% 提升到了44.4%,MTEB(Massive Text Embedding Benchmark)从 61.0% 提升到了62.3%,且价格更低。- Sentence-BERT(SBERT):基于BERT优化,大幅提升句子嵌入速度和相似度计算效果,开源且免费(如
all-mpnet-base-v2性能最好,而all-MiniLM-L6-v2速度最快)。 - Gemini Embedding:在 MTEB 基准测试中表现出色,目前排名第一。
- Cohere Embed:有 embed-english-light-v2, embed-english-v3等模型
- BGE(BAAI General Embedding):智源研究院研发,专为中文优化(如bge-large-zh),在中文MTEB榜单排名前列。
- M3E(Moka Massive Mixed Embedding):开源轻量模型,专为中文优化,适合本地部署。
对我们实战而言:中文选BGE/M3E,英文选OpenAI/Cohere,轻量部署选Sentence-BERT。
扩展知识
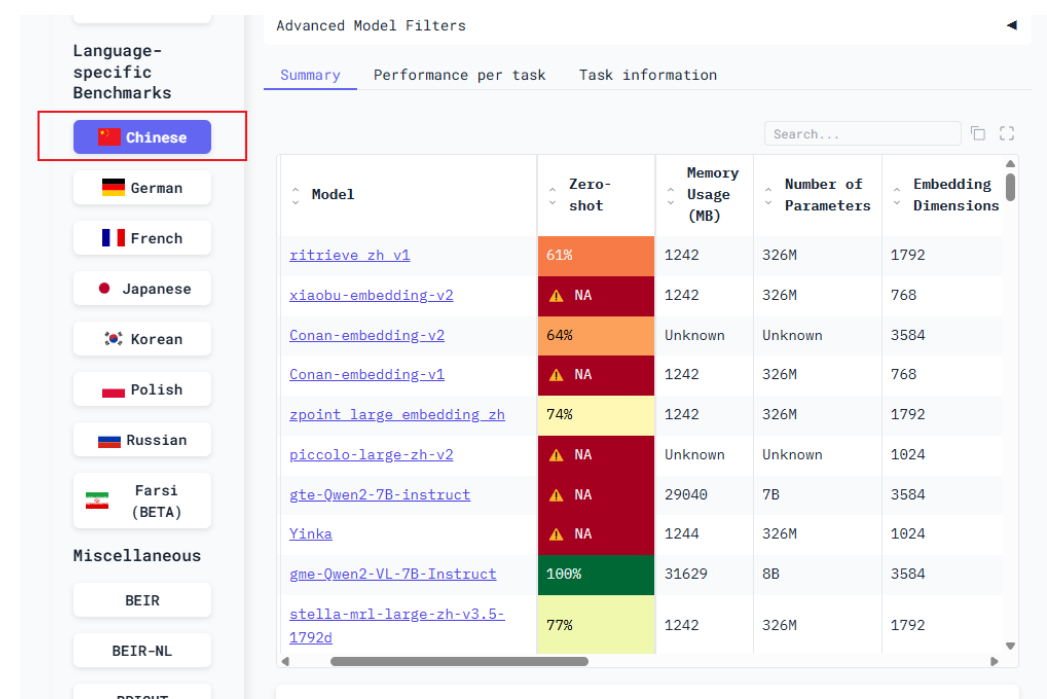
MTEB(Massive Text Embedding Benchmark) 和 C-MTEB (Chinese Massive Text Embedding Benchmark)
目前这个 Embedding 模型相关的榜单被广泛认可,从分类、聚类、语义文本相似性、重排序和检索等多个角度评测排行各种模型,大家可以从上面了解更多的 Embedding 模型。
选择左侧的语言即可切换到 Chinese 相关榜单:
专用优化模型(特定场景)
- 代码嵌入:
codebert、code2vec(处理代码语义,适合技术文档RAG)。 - 长文本:
Longformer、RetriBERT(优化长序列处理,适合书籍、法律文档等长内容)。 - 多模态:
CLIP(图文联合嵌入,支持图像+文本混合检索,但RAG中较少用)。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)