彻底搞懂Transformer05:Encoder+Decoder总结篇
本文系统总结了Transformer核心机制的原理与作用。首先回顾了Transformer的关键组件:词嵌入与位置编码解决了并行计算丢失序列位置信息的问题;点积注意力机制通过矩阵乘法高效计算相似度,并采用√dk缩放防止梯度消失;层归一化通过通道级归一化降低BatchSize影响,更适合NLP任务。特别对比了Encoder-Decoder结构的差异:Decoder采用掩码注意力处理目标序列,第二层注
0 前言
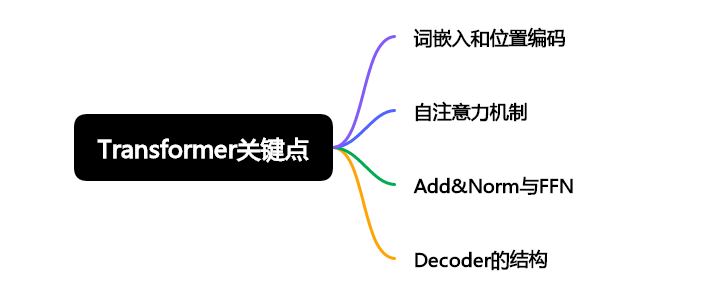
学习了前面四篇内容,终于来到了最终总结篇。我们首先回顾一下Tranformer主要包含哪些内容:
-
词嵌入和位置编码:我们由One-Hot到嵌入矩阵,再到词嵌入,词嵌入再加上位置编码得到了Transformer的输入。
-
自注意力机制:输入数据与Wq、Wk、Wv相乘得到了Q、K、V矩阵,Q与K的转置相乘得到注意力分数Y矩阵,Y与V相乘得到了Z矩阵。多个注意力机制就有多个Z矩阵,把多个Z矩阵拼接,就成了多头注意力。
-
Add&Norm与FFN:Add指的残差连接,Norm指的层归一化,FFN是前馈网络层,残差连接有利于加深网络,层归一化能够加速模型收敛稳定训练,而FFN则将提取的特征进行整合,提高了模型的特征提取能力。
-
Decoder的结构:需要注意此时Decoder的输入和Encoder的输入不同,它的输入是目标序列,并且一个Decoder包含两个注意力机制,第一个注意力机制的注意力分数需要加上掩码,第二个注意力机制的QKV来源不同。
讲道理,我们学习了这么多内容,知道Transformer中各种各样的运算,比如词嵌入怎么算的,注意力分数是怎么算的,但是为了简化阅读的内容,因此前面的文章中,我都是一笔带过,着重讲述了是计算过程,可是为什么这么计算,却没有做太多介绍,这篇文章我们来着重了解一下Transformer中,众多机制的原因和作用。
1 思维导图
首先来看一下我们这篇文章主要解决哪几个疑问:
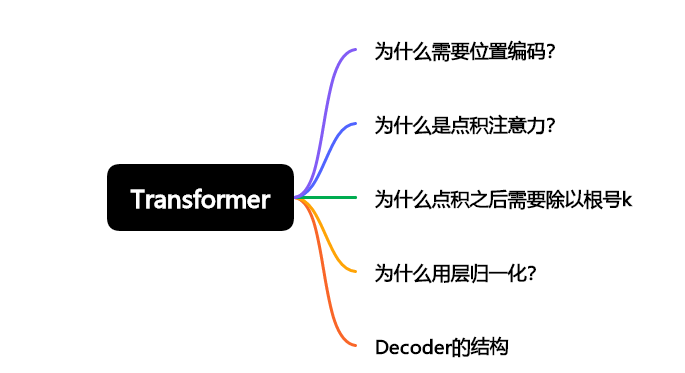
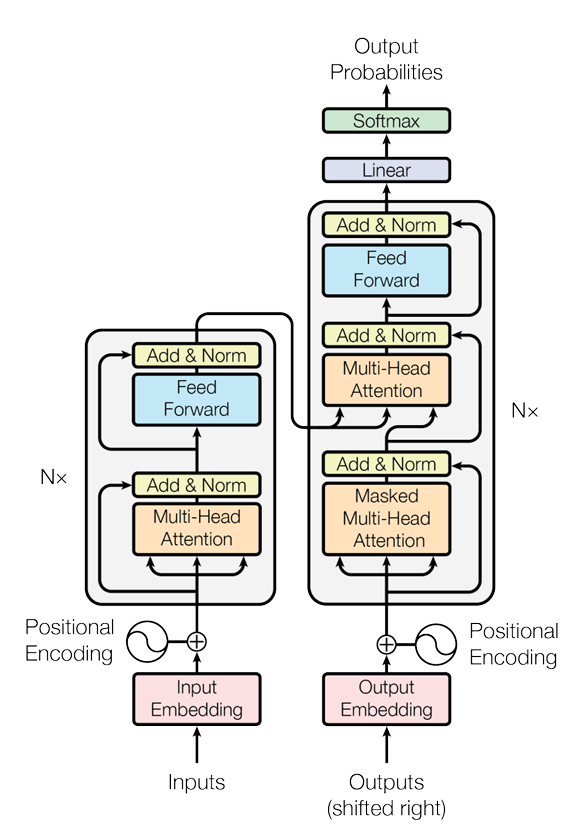
包含五点,内容基本也覆盖了Transformer中几个关键的零件。差点忘记放了:Transformer结构图接着镇场子:
2 为什么需要位置编码?
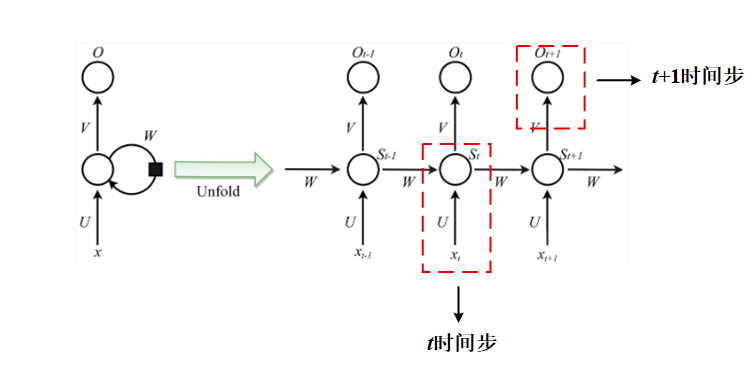
还记得我们之前说在Transformer中,数据计算是并行的吗?我们来回忆一下RNN和LSTM的计算过程,每次计算t+ 1时间步的数据,我们都需要先计算出t时间步,因此RNN和LSTM是关注输入序列顺序的,只不过说距离太长的话,RNN和LSTM就会记不住。
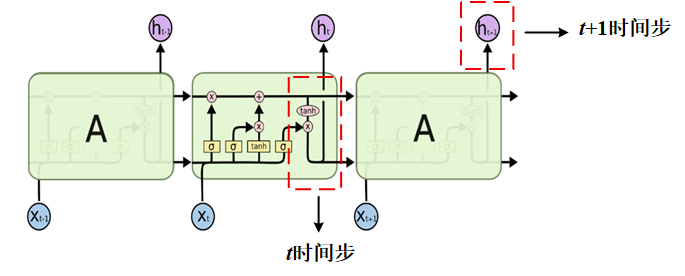
我们再来看看Transformer的输入:
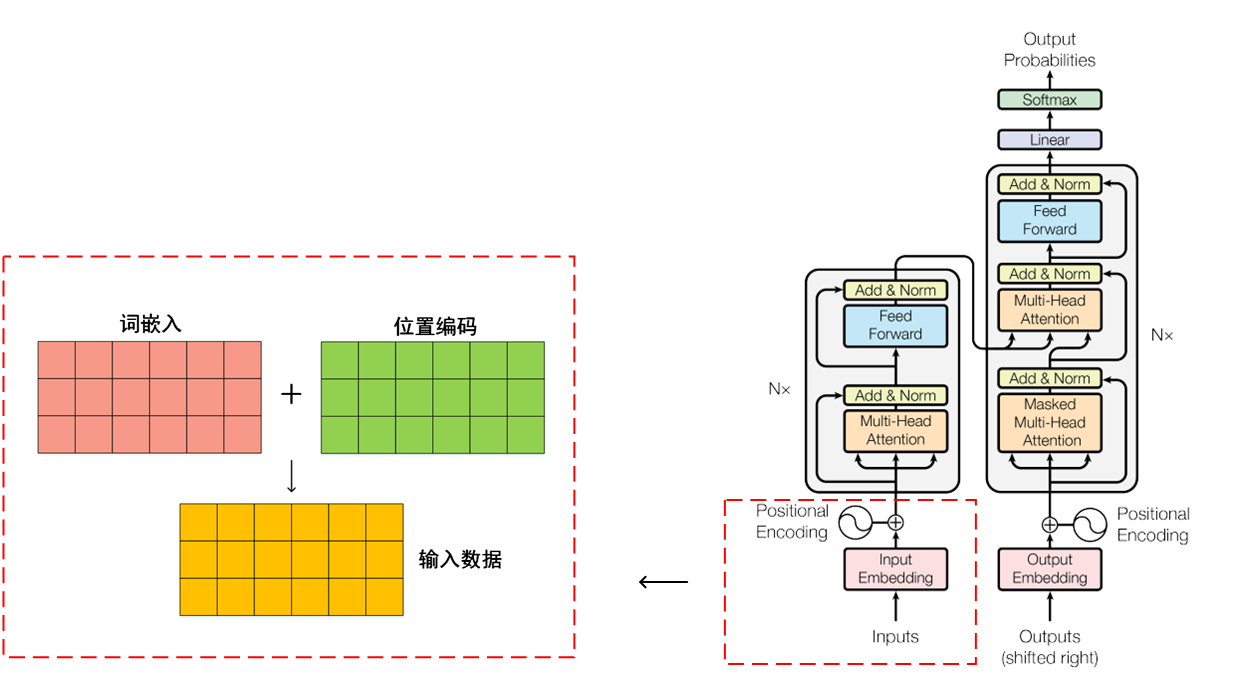
这样对比我们就可以发现,我们暂时不看位置编码,Transformer的输入不是一个接着一个的,我们并不需要知道上一时刻的计算结果再来计算下一时刻的输出,它们是同时被送到模型中进行计算的。
因此虽然Transformer为了注意力机制实现并行计算,但同时也丢失了序列的位置信息。天下没有免费的午餐。
既然自注意力机制是个瞎子,因此我们需要给输入注入位置信息,手动告诉它每个词的位置。
而我们用到的就是正弦余弦编码,它具有三个特点:
-
唯一性:每个位置都有独一无二的编码。
-
相对位置:对于任意固定的偏移量 k,PE(pos + k) 可以被表示为 PE(pos) 的线性函数。这意味着模型可以轻松地学会关注“相对位置”(例如,下一个词、前一个词),这比绝对位置更重要。
-
可扩展性:由于正弦函数的周期性,它可以自然地外推到比训练序列更长的序列。
为什么是点积注意力?
我们再来回忆一下自注意力机制的公式:
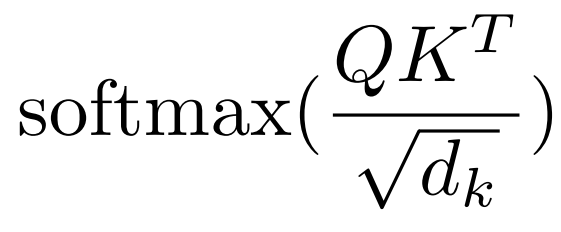
这里在进行Softmax之前,Q和K的转置,做的是矩阵相乘,其实严格意义上来说,Q和K的转置相乘不能算是点积,但是我们借用了向量空间中的说法:
-
在向量空间中,两个向量的点积结果可以表示它们的相似度。点积值越大,通常意味着两个向量在方向上越接近,即越“相似”。
-
在注意力中的应用:一个词元的查询向量(Q)与另一个词元的键向量(K)点积得分高,就意味着当前词应该“更多地关注”那个词元。
所以,使用点积作为注意力分数是这种机制的本质,因此得名“点积注意力”。
其实我们在Transformer中学习到的注意力机制只是其中一种,注意力机制并不是Transformer首创的,在Transformer之前,就有了很多种注意力机制的计算方法,比如加性注意力。
我们不对加性注意力做过多介绍,只是做出对比:
点积注意力本质上可以视为矩阵乘法,而加性注意力需要一个前馈网络和激活函数,计算路径更长更复杂。
在如今的深度学习框架下,最擅长的莫过于矩阵乘法了,有了Pytorch和GPU的加持,点积注意力能够充分利用这些优化,实现极高的并行度。因此Transformer中用到的是点积注意力。
为什么需要除以根号k?
Q和K的转置做完矩阵乘法后,为什么还需要除以根号k?
这个问题我们简单了解一下,真正要弄懂还需要严格的数学推导,但是如果需要面试大模型岗位的同学,建议好好研究一下,这是一个高频题。
事实上Transformer的注意力机制有一个更加完整的名字:“缩放”点积注意力。
为什么要除以根号dk呢?
我们Q和K通常不是我们举的例子里的大小,实际训练中维度可能会非常大,因此点积的结果也可能是一个很大的数。
-
原因:当查询和键向量的维度 dk很大时,点积的结果在数值上可能会变得非常大。
-
问题:这会导致Softmax函数的输入值进入其梯度非常小的区域(饱和区)。在饱和区,梯度会接近于零,从而引发梯度消失问题,使得模型难以训练。
为什么是根号而不是其他值?
-
除以 dₖ:这会使方差变成 1/dₖ,可能会过度压缩,使注意力分数过于相似。
-
除以 √dₖ:这正好将标准差归一化为1,是理论上的最优选择。
从统计角度看,如果 q·k 的方差是 dₖ,那么 (q·k)/√dₖ 的方差就是1,这正好是我们想要的。
5 为什么用层归一化?
什么是归一化?针对一批数据归一化事实上就是计算出这批数据的均值和方差,然后数据减去均值再除以标准差(方差的开平方)。我们再来回忆一下层归一化是如何处理数据的,注意和Batch Norm进行区分。
从下图可以看出来Batch Norm是在batch进行计算的,而层归一化是在每个数据通道层面的。
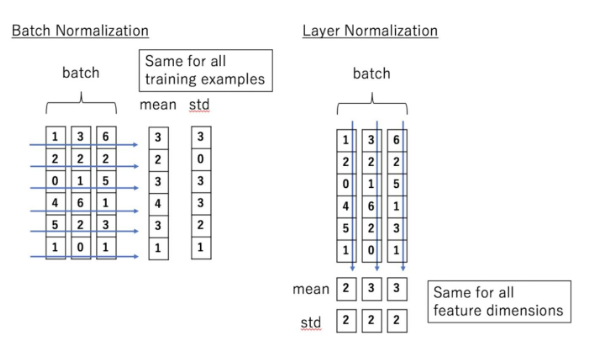
并且在计算完均值和方差后,层归一化还会进行缩放:
1、计算均值和方差:
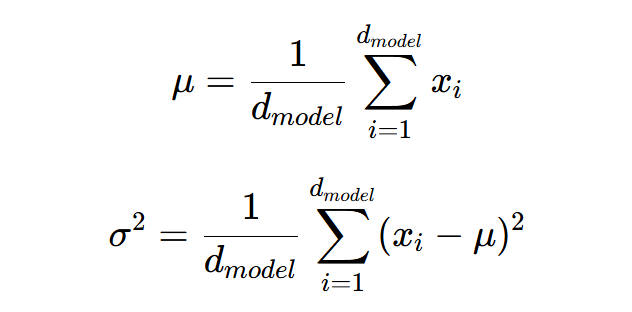
2、归一化:
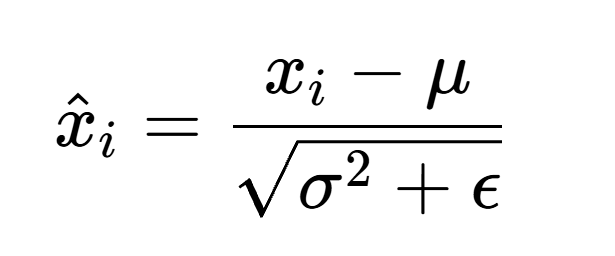
3、缩放:
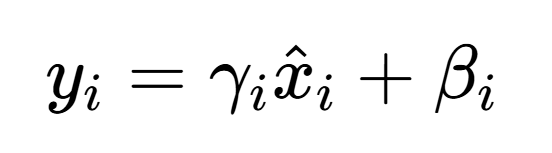
为什么在NLP中一般采用层归一化而不是批处理归一化呢?
-
由于我们在实际语境中,序列的长度可能不一定一致,因此有时候需要填充0,这就导致同一个batch内有些序列实际上是无效的。
-
采用层归一化,使得模型对Batch size不敏感,这非常适合训练NLP模型。(由于模型和序列通常很大,有时不得不使用较小的Batch Size)
-
在训练和推理时使用的batch很可能不是一致的,不采用Batch Norm,降低Batch的影响。 总而言之,在NLP的训练中,要尽可能降低Bacth size对模型的影响,因此层归一化是最好的选择。
6 Decoder的结构
针对Encoder和Decoder一些特殊的地方做出对比。
6.1 输入
Encoder是源序列,Decoder是目标序列:
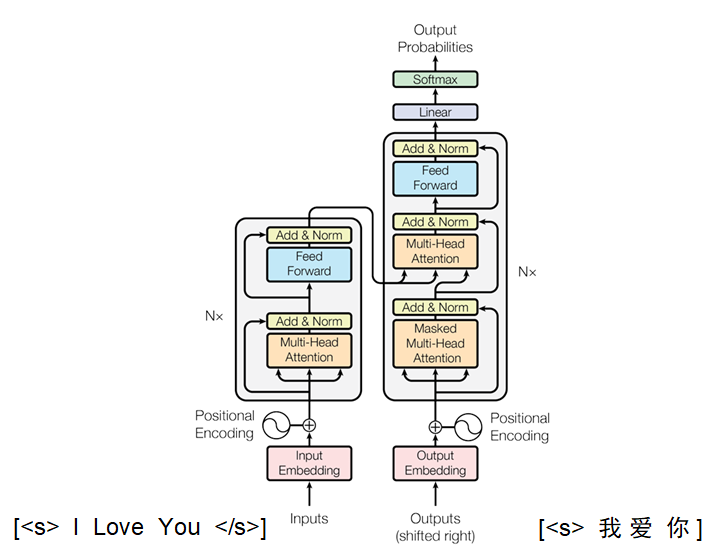
6.2 第一个注意力机制
Encoder直接计算注意力分数与V矩阵的乘积,而Decoder需要对Y矩阵加上掩码:
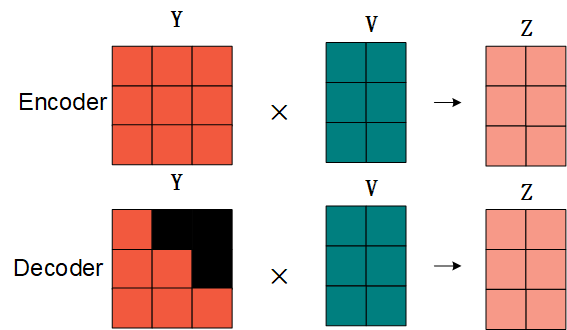
6.3 第二个注意力机制
Encoder都是相同的注意力机制,而Decoder第二个注意力机制的K、V来自于Encoder,Q来自于上一层的输出。
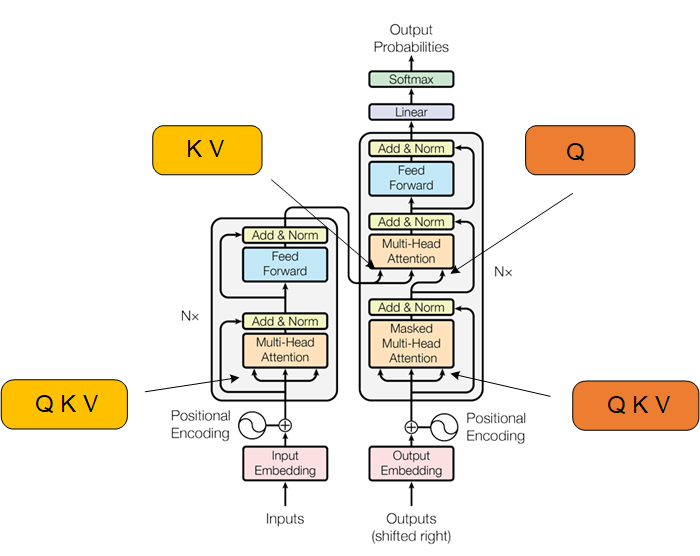
Transformer的介绍终于告一段落了,至此也初步踏入了NLP的大门,Transformer的变体相当多,世界上主流的大语言模型基本上都是从Transformer衍生出来的,比如ChatGPT、DeepSeek,Transformer开辟了AI的新时代,在如今AI的领域,Transformer一直在书写自己的传奇。
欢迎大家有疑问和我交流讨论,也可以关注我的gzh:阿龙AI日记。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 33
33 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)