向量检索算法综述:KNN、近似KNN与主流ANN索引算法(PQ、NSW、HNSW)
本文系统介绍了向量索引技术及其在高效检索中的应用。首先解释了向量索引作为高维向量快速查找目录的核心功能,然后详细分析了RAG流程中的召回与排序两阶段:召回阶段追求高召回率,排序阶段则结合业务逻辑进行个性化重排序。文章重点剖析了多种ANN技术:倒排索引(IVF)的文本检索原理、KNN搜索及其时间复杂度问题、近似KNN的空间分块优化、Product Quantization(PQ)的向量压缩编码方法,
什么是向量索引?
在向量数据库中,每条记录是一个高维稠密向量。而检索的目标是:在上亿条向量中快速找到与查询向量最相近的K条(Top-K)。向量索引(Vector Index)是一种专门为高效存储和检索向量数据(通常是高维向量)而设计的数据结构和技术。简单来说,它就像一本专门为“高维空间中的点”准备的“快速查找目录”。
从基础RAG到进阶RAG
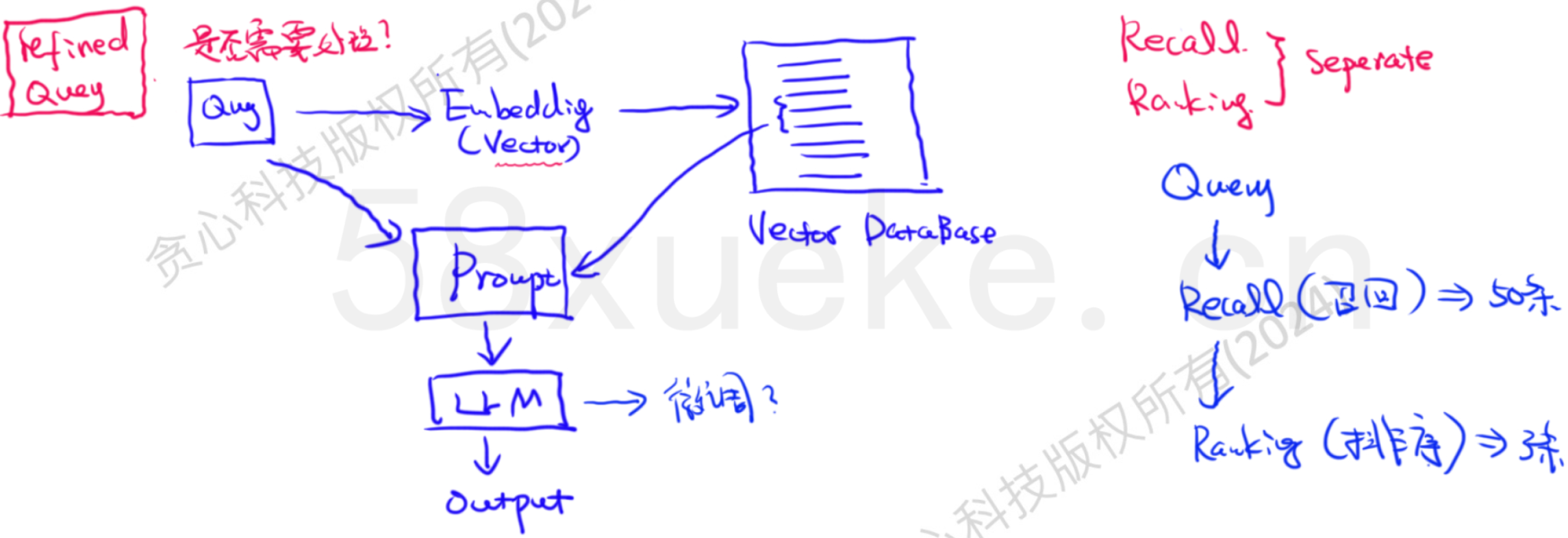
原始query是否需要处理?➡refined query
基础RAG通过向量数据库进行单一的检索排序过程➡更优的流程应将其拆分为两个关键阶段:召回(Recall)和排序(Ranking)
-
召回阶段: 核心目标是全面性。利用向量索引等技术,快速从海量数据中筛选出与查询语义相关的一批候选结果(例如 Top 100 或 Top 200)。这一步主要解决“有没有相关文档”的问题,追求高召回率(Recall),确保不错过潜在有用信息。
-
排序阶段: 核心目标是精准性与个性化。此阶段与业务逻辑和具体场景高度相关。在召回集的基础上,应用更精细、更贴合业务需求的排序规则对候选结果进行重排序(Re-ranking)。
-
关键点:排序逻辑需要灵活定制。 例如,不同用户可能有不同的偏好权重(如:用户A更看重时效性,用户B更关注某个特定主题或来源的可信度,也即考虑排序的维度不一样,会在排序中把更关注的权重设置的更高)。排序模型或规则应能将这些个性化因素(如时效、主题相关性、来源权威性、用户历史行为偏好等)作为特征,赋予不同的权重进行综合计算。
-
结果呈现: 最终呈现给LLM(大语言模型)的检索结果列表是经过重排序的。列表中越靠前的项目,表示其在当前查询和用户上下文下优先级越高、相关性越强,会被LLM优先考虑用于生成答案。 (即:位置越靠前,优先级/相关性越高)。
-
在整个RAG流程图中,最上面的最先被考虑修改调整,越下就越后考虑修改调整。
索引方法

ANN详看以下 ⬇ 注意区分,里面讲的是向量倒排索引
向量检索中的 ANN(Approximate Nearest Neighbor)技术_ann检索-CSDN博客
快速搜索文本 - 文字倒排索引(IVF)
倒排索引(Inverted Index)是信息检索系统中最核心的数据结构之一,主要用于加速文本检索。它最早由搜索引擎如 Google、Lucene 使用,现在在向量数据库(如 FAISS 的 IVF 索引)中也有应用。

🔍 一句话理解倒排索引
倒排索引是“词到文档”的映射表。
而正排索引是“文档到词”的映射。
📚 举个例子:正排 vs 倒排
假设有三个文档:
Doc1: "I love deep learning"
Doc2: "I love machine learning"
Doc3: "deep learning is fun
| DocID | 内容 |
|---|---|
| Doc1 | I, love, deep, learning |
| Doc2 | I, love, machine, learning |
| Doc3 | deep, learning, is, fun |
| 词项 | 出现的文档列表 |
|---|---|
| I | Doc1, Doc2 |
| love | Doc1, Doc2 |
| deep | Doc1, Doc3 |
| learning | Doc1, Doc2, Doc3 |
| machine | Doc2 |
| is | Doc3 |
| fun | Doc3 |
🧠 倒排索引的组成
一个倒排索引一般由两部分组成:
-
词典(Term Dictionary):所有唯一词项
-
倒排列表(Posting List):每个词项对应的文档列表,有时还包含位置、频率等信息。
例如:
{
"learning": [
{ "doc_id": 1, "positions": [3] },
{ "doc_id": 2, "positions": [3] },
{ "doc_id": 3, "positions": [1] }
]
}⚙️ 倒排索引如何支持快速搜索?
当用户搜索 “deep learning”:
-
在倒排索引中查找 "deep" → 得到 [Doc1, Doc3]
-
查找 "learning" → 得到 [Doc1, Doc2, Doc3]
-
求交集 → 得到匹配两个词的文档 [Doc1, Doc3]
-
按词频/TF-IDF/位置进行排序 → 返回结果
速度远快于对所有文档做全文搜索。
但是这种直接将文本数据和索引对应的查询(从文本到索引)效率并不高,我们需要考虑更快的方法,从文本到向量。
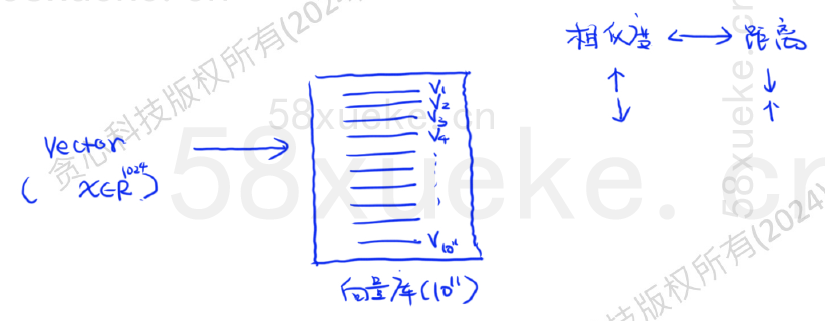
KNN搜索
KNN 搜索(K-Nearest Neighbors Search,K近邻搜索)是向量检索、推荐系统、图像识别、语义搜索等任务中最基本也是最核心的一种操作。这种搜索方式查出来的数据准确度高,但是时间复杂度也很高。

🔍 什么是 KNN 搜索(K-Nearest Neighbors Search)
✅ 一句话定义
KNN 搜索就是:给定一个查询向量,转换成向量,找到与它最近的K个向量(邻居)。
它不是机器学习中 KNN 分类算法,而是用于向量相似性检索的 K 最近邻查找。
相似度度量方式
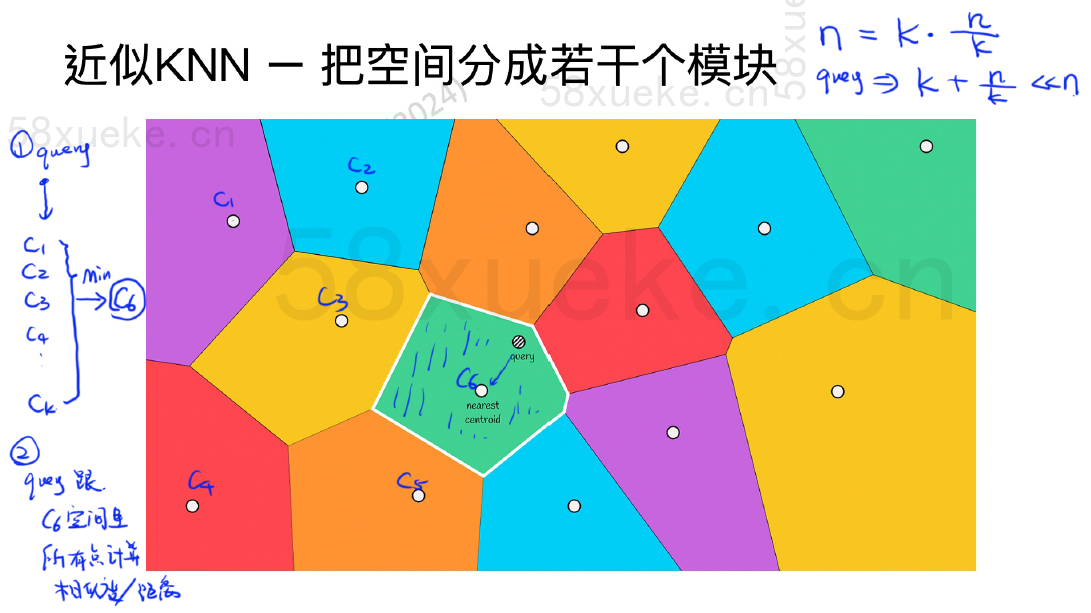
近似KNN - 把空间分成若干个模块
近似 KNN 搜索的核心是将搜索空间从点转换为块。它首先确定距离查询点最近的那个块,然后仅在该块内部搜索距离最近(或相似度最高)的点。
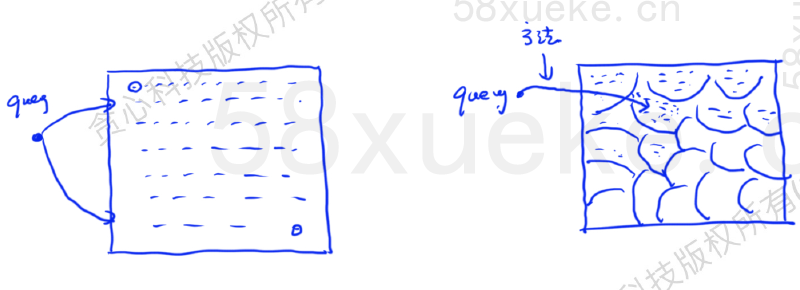
每个块设有一个中心点。查询点到块的距离,即为其到该块中心点的距离。
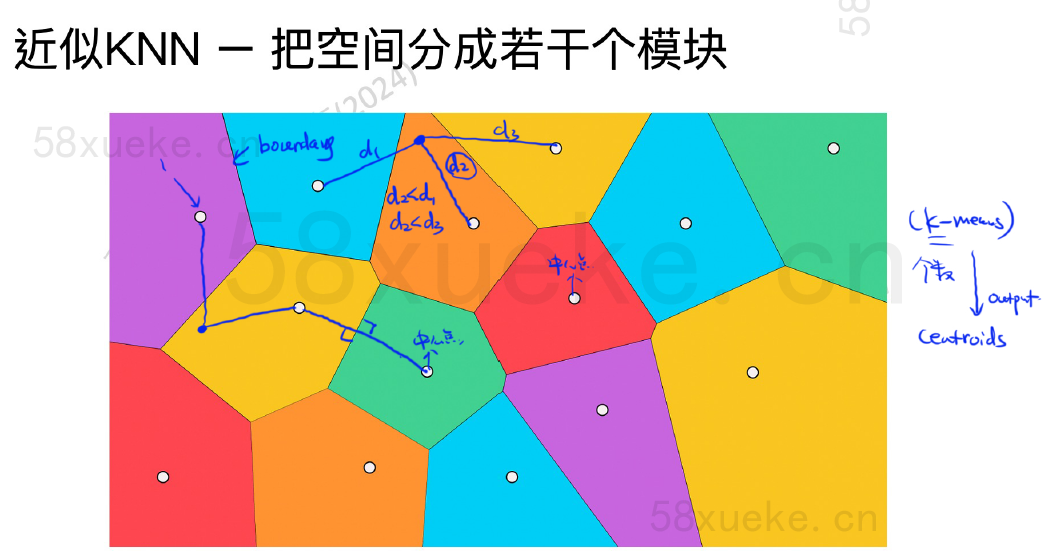
第一步,query与k个空间中的中心点做一个距离计算,找到最短距离的点。第二步,query与这个空间中的所有点计算距离/相似度,返回最短/相似的点。这样时间复杂度会大大变小。
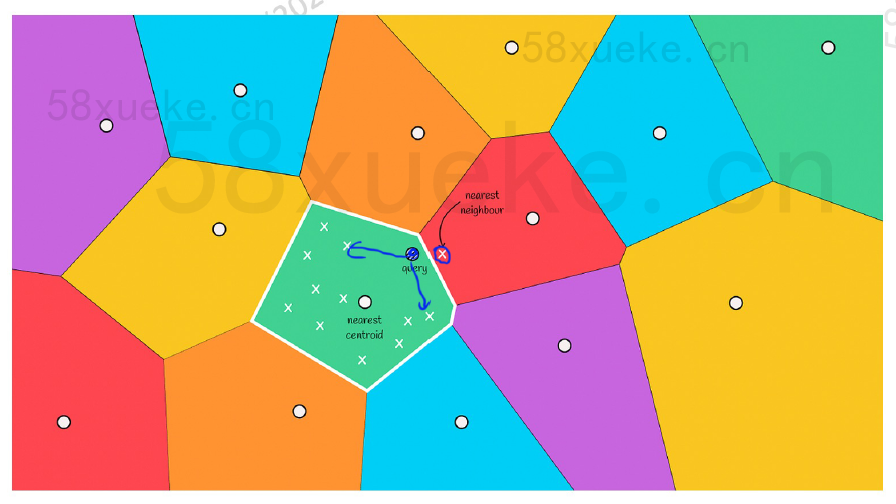
新的问题
query已经所处一个区域,但与红色边界线很近。
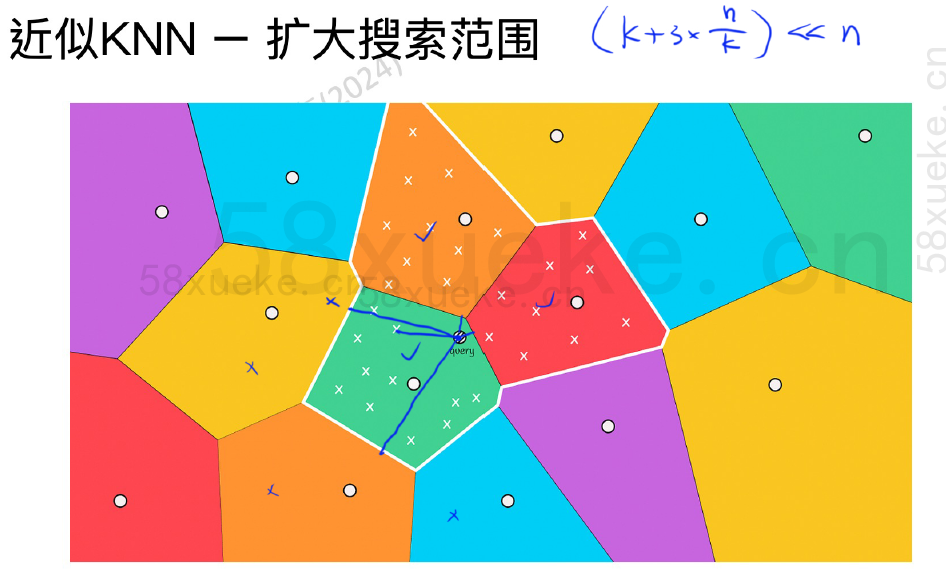
解决思路:把跟当前空间相邻的橙、红两块包含起来就好了。
距离计算:欧氏距离、曼哈顿距离等。

Product Quantization(PQ)
虽然近似KNN提高了搜索效率,但是它没有解决memory(存储空间)的问题,即没有在存储空间上做任何优化。
Product Quantization(简称 PQ)是大规模向量检索中一种非常核心的 压缩与加速技术。它最早由 Facebook 提出,并广泛应用在 FAISS、Annoy、ScaNN、Milvus 等向量检索系统中。
在亿级数据的语义检索、图像检索、推荐系统中,PQ 通过将高维向量压缩成更紧凑的表示,在保证一定精度的同时大幅降低内存和计算开销。
➡️ PQ 的目标是:用较小的码表示向量,同时保留其主要的相似性结构

✅ 一句话理解 PQ
PQ 是一种把高维向量分块,对每块分别做聚类编码,从而将原始向量压缩为多个短码(code)的技术。
压缩后只需要存储少量的整数编码 + 查表,就能恢复近似的向量距离。
🧠 Product Quantization 原理详解
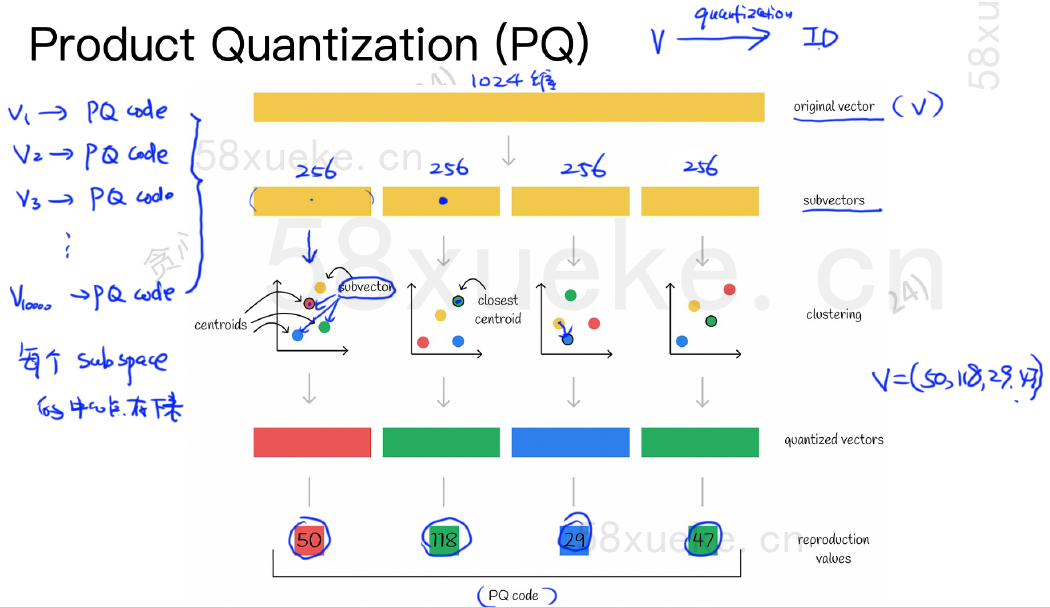
Step 1:向量分块 (Vector Splitting):把维度切分为M段
-
将每个
D维的原始向量x均匀划分为M个互不相交的子向量。 -
原始向量表示为:
x = [x₁, x₂, ..., xₙ](维度D) -
划分后:
x = [x⁽¹⁾, x⁽²⁾, ..., x⁽ᴹ⁾]-
其中
x⁽ᵐ⁾表示第m个子向量 (m = 1, 2, ..., M)。 -
每个子向量的维度为
d = D / M(假设D能被M整除)。
-
Step 2:子空间聚类 (Subspace Clustering):每一个小段单独进行 K-Means 聚类。
-
对每个子空间
m(m = 1, 2, ..., M) 独立执行:-
收集所有训练数据向量的第
m个子向量x⁽ᵐ⁾。 -
在这个
d维的子空间上运行 K-Means 聚类算法,得到K个聚类中心(质心)。 -
将所有
K个中心点cₖ⁽ᵐ⁾(k = 0, 1, ..., K-1) 组成的集合称为该子空间的码本 (Codebook)C⁽ᵐ⁾。C⁽ᵐ⁾ = {c₀⁽ᵐ⁾, c₁⁽ᵐ⁾, ..., c_{K-1}⁽ᵐ⁾}
-
-
关键点: 每个子空间都有自己的码本
C⁽ᵐ⁾,不同子空间的码本是独立学习的。通常设定K = 256,这样每个中心索引可以用1个字节 (8位) 表示 (0到255)。每个码本包含K=256(自己设置)个聚类中心向量(也称为码字 - Codeword)。这些码本存储在内存里。
Step 3:编码向量 (Vector Encoding):用“字典编号”代替原始子向量
概要
-
对于数据集中的每个原始向量
x,找到离它最近的聚类中心,并用其索引代替:-
对于其第
m个子向量x⁽ᵐ⁾(m = 1, 2, ..., M):-
在它所属子空间的码本
C⁽ᵐ⁾中,找到与其距离最近 (L2距离) 的聚类中心c_{iₘ}⁽ᵐ⁾。 -
记录下该中心在码本中的索引
iₘ(iₘ ∈ {0, 1, ..., K-1})。
-
-
向量
x的压缩表示就是这M个索引组成的序列:[i₁, i₂, ..., i_ᴍ]。
-
-
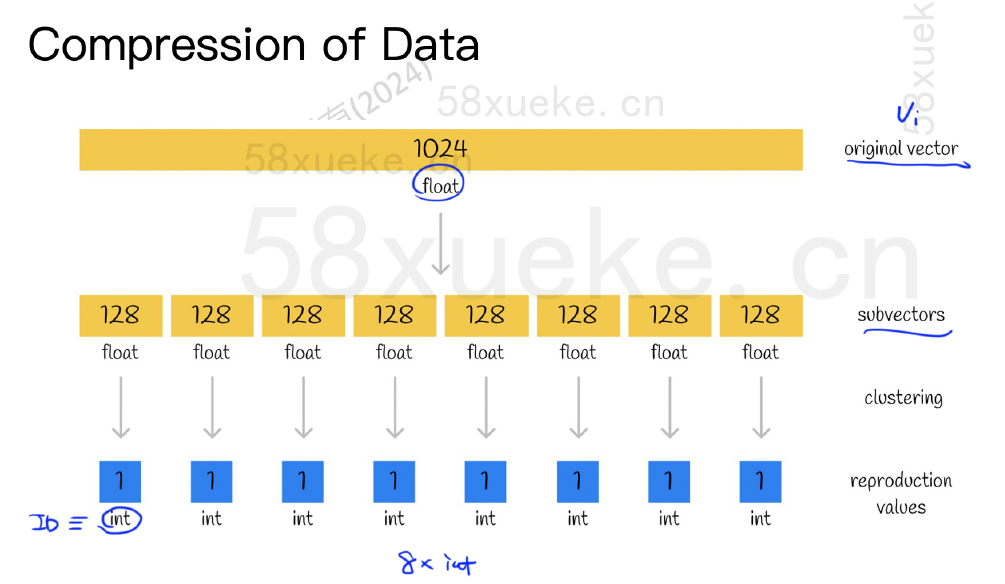
存储开销: 原始
D维float向量 (4D字节) 被压缩成M个byte索引 (M字节)。例如D=128,M=8,则128 * 4 = 512字节 →8字节,压缩比为64倍。
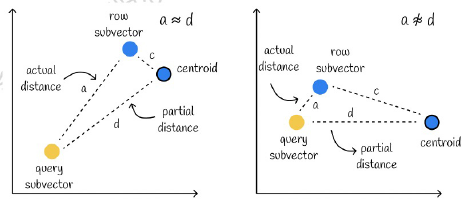
仍然存在一些小问题,但实际情况下,绝大情况下不会出现右图问题。
编码步骤详解
想象你有一件衣服(一个向量),要用 PQ 给它办一张“身份证”(PQ Code)。这张身份证只允许用 M 个数字(通常是 8-16 个),每个数字在 0 到 255 (K=256) 之间。
第 0 步:前提条件(准备工作已完成)
-
分段规则确定: 我们已经把整个高维空间(比如 128 维)均匀地切成了
M段(比如M=8)。每段子空间维度D* = D/M(128/8=16 维)。 -
码本已训练好: 对于每一段子空间(第1段,第2段,...,第8段),我们都用 K-Means 聚类(比如
K=256)生成了一个码本 (Codebook)。每个码本包含K=256个聚类中心向量(也称为码字 - Codeword)。这些码本存储在内存里。-
第1段码本
C1: 256 个 16 维向量,代表颜色/材质等特征的最佳“样板”。 -
第2段码本
C2: 256 个 16 维向量,代表袖子/领型等特征的最佳“样板”。 -
...
-
第8段码本
C8: 256 个 16 维向量,代表其他特征的最佳“样板”。
-
第 1 步:分解向量 - “撕清单”
-
操作: 拿到你要编码的原始高维向量
x(比如代表某件衣服的 128 维特征向量)。按照预设的分段规则,把它切成M个连续的、互不重叠的子向量 (Subvector)。-
x = [x1, x2, ..., x128](原始128维) -
切成:
-
x⁽¹⁾ = [x1, x2, ..., x16](第1段,16维) -
x⁽²⁾ = [x17, x18, ..., x32](第2段,16维) -
...
-
x⁽⁸⁾ = [x113, x114, ..., x128](第8段,16维)
-
-
-
类比: 把这件衣服的详细描述清单撕成了 8 张小纸条,每张小纸条只描述衣服的一部分特性。
第 2 步:分段量化 - “找最像的样板” (核心编码操作)
-
操作: 对每一段子向量
x⁽ᵐ⁾(m从 1 到M),执行以下操作:-
定位对应码本: 找到这段子向量所属子空间的码本
Cₘ。例如,第1段找C1,第2段找C2。 -
搜索最近邻码字: 在码本
Cₘ包含的K=256个码字(16维向量)中,计算x⁽ᵐ⁾到每一个码字cₘ₍ₖ₎(k从 0 到 255) 的距离(通常用欧氏距离或平方欧氏距离)。找到那个距离最小的码字!也就是说,找到Cₘ中与x⁽ᵐ⁾最相似的那个“样板描述”。-
kₘ = argminₖ distance(x⁽ᵐ⁾, cₘ₍ₖ₎)
-
-
记录编号: 记下这个最优码字在码本
Cₘ中的索引 (Index)kₘ。这个索引是一个在0到255(K-1) 之间的整数。
-
-
关键点:
-
这个过程在
M个子空间上完全独立进行!给第1段找编号时,完全不看第2段到第8段的信息。颜色专家只根据颜色小纸条在颜色字典里找编号,不管袖子是什么样。 -
计算
x⁽ᵐ⁾到 256 个码字的距离是在D* = D/M维空间进行的(例如 16 维),比在原始高维空间(128维)计算快很多。但这一步是编码过程的主要计算开销。
-
-
类比: 把第1张小纸条(颜色/材质)交给第1组专家。专家拿出他们的颜色字典(256个样板),挨个对比你的小纸条和每个样板,找出最像的那个(比如编号
42的“纯棉-亮红色”样板),并告诉你编号42。接着把第2张小纸条(袖子/领子)交给第2组专家,他们同样操作,找出最像的样板(比如编号153的“短袖-圆领”),告诉你153。... 直到第8张小纸条处理完,拿到编号(比如78)。
第 3 步:组合编码 - “办身份证”
-
操作: 把上一步为每一段子向量找到的最优码字索引
k₁, k₂, ..., kₘ按顺序组合起来,形成一个整数序列[k₁, k₂, ..., kₘ]。这就是原始向量x的 PQ Code! -
存储: 每个索引
kₘ取值范围是0-255,正好可以用 1 个字节 (8 bits) 存储。所以一个M=8的 PQ Code 总共只需要 8 个字节。-
原始 128 维 float 向量:
128 * 4 bytes = 512 bytes -
PQ Code (
M=8):8 bytes -
压缩率:
512 / 8 = 64 倍!
-
-
类比: 你把 8 组专家分别告诉你的编号 (
42,153, ...,78) 按顺序写在一张小卡片上:[42, 153, ..., 78]。这张卡片就是这件衣服独一无二的、极其紧凑的“PQ 身份证”。你把它贴在衣服上,而那张超长的原始描述清单可以扔掉了(实际上数据库只存储这个 PQ Code 和原始数据的关联关系,比如数据库主键)。
编码过程总结 (关键点回顾)
-
输入: 一个高维向量
x(如 128 维 float)。 -
分段: 按预设规则切成
M个低维子向量x⁽¹⁾, x⁽²⁾, ..., x⁽ᴹ⁾(如 8 个 16 维向量)。 -
独立量化 (核心): 对每一段
m独立操作:-
取出该段对应的码本
Cₘ(包含 256 个低维码字)。 -
计算该段子向量
x⁽ᵐ⁾到Cₘ中每一个码字的距离。 -
找到距离最小的那个码字。
-
记录该码字在
Cₘ中的索引编号kₘ(0-255)。
-
-
输出: 将所有
M个索引编号k₁, k₂, ..., kₘ按顺序组合,得到 PQ Code (一个包含M个整数的序列,通常占M字节)。
为什么这样编码有效?(理解精髓)
-
分治与降维: 把困难的高维最近邻搜索问题 (
128维找 1个最近邻),分解成M个相对简单的低维最近邻搜索问题 (16维找 1个最近邻,做M次)。大大降低了计算复杂度(虽然编码时仍要算M * 256次低维距离)。 -
空间压缩: 用
M个整数 (每个代表 256 种可能性) 代替原始的高维浮点向量,实现了极高的压缩比 (64倍或更高)。这是存储海量向量的基础。 -
为快速查询奠基: 这种编码方式的真正威力在查询时爆发。查询向量
q被同样切分后,可以预计算其每一段子向量到该段所有 256 个码字的距离,并保存成M张距离表 (Table_m, 每张表有 256 个值)。要计算q和一个数据库向量x(由其 PQ Code[k1, k2, ..., kM]表示) 的近似距离,只需要:-
对每一段
m,去Table_m中查找下标为kₘ的值d(q⁽ᵐ⁾, cₘ₍ₖₘ₎)(这就是q的第m段和x的第m段所对应的那个码字之间的距离)。 -
把这
M个查表得到的距离值加起来:d_approx = Σₘ Table_m[kₘ]。 -
这个操作只需要
M次内存查找 (查表) 和M-1次加法!速度极快 (O(M)复杂度),完全规避了高维向量直接计算距离 (O(D)复杂度) 的巨大开销。
-
-
近似性: 用分段最近邻码字的组合 (
c₁₍ₖ₁₎, c₂₍ₖ₂₎, ..., c_M₍ₖ_M₎) 来近似表示原始向量x。用分段距离之和 (d_approx) 来近似真实距离 (distance(q, x))。这是一种有损压缩和近似计算,但通过合理选择M和K,可以在精度、存储和速度之间取得很好的平衡。
第 4 步:查表计算距离 (Lookup-based Distance Computation):“近似”找相似 (Query)

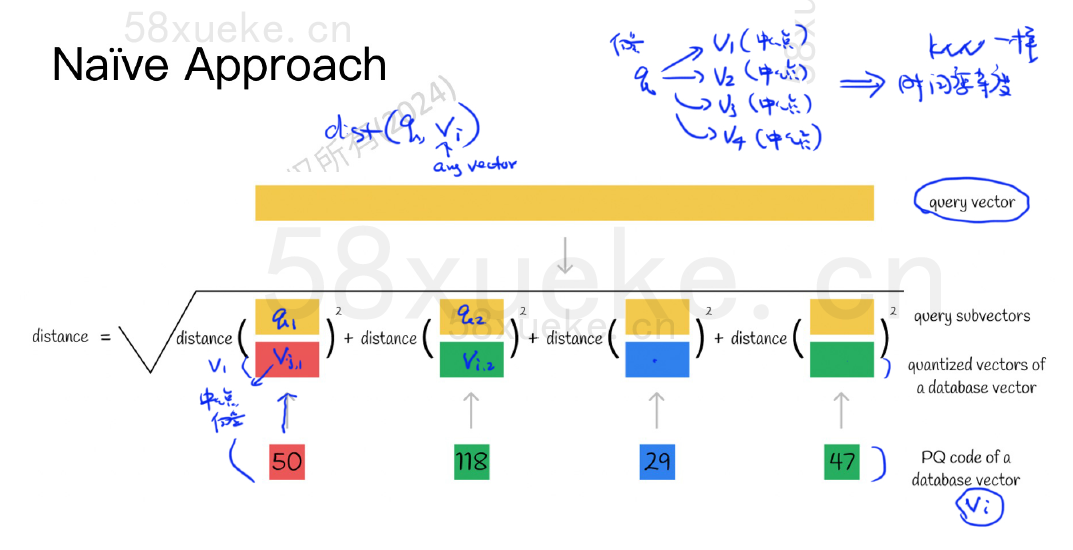
实际还是跟knn一样的时间复杂度,怎么实际用起来计算相似度呢?
查询过程:将查询向量分块成同样数目(M)的子向量。针对每个子空间,预先计算查询子向量到所有中心点的距离,形成查表缓存(cache),加速后续匹配。
查找表(Lookup Tables)是在查询阶段临时建立的。
理解逻辑
明确 PQ 两个阶段的职责:
| 阶段 | 动作 | 说明 |
|---|---|---|
| 1. 向量编码阶段(离线) | 对数据库中每个向量进行 PQ 编码(如 [3, 8, 15, 122]) |
离线执行一次,压缩向量,存储的是中心点编号(整数) |
| 2. 查询阶段(在线) | 针对查询向量,构建查找表,然后对比所有 PQ 编码 | 每次查询时动态生成,查表计算近似距离 |
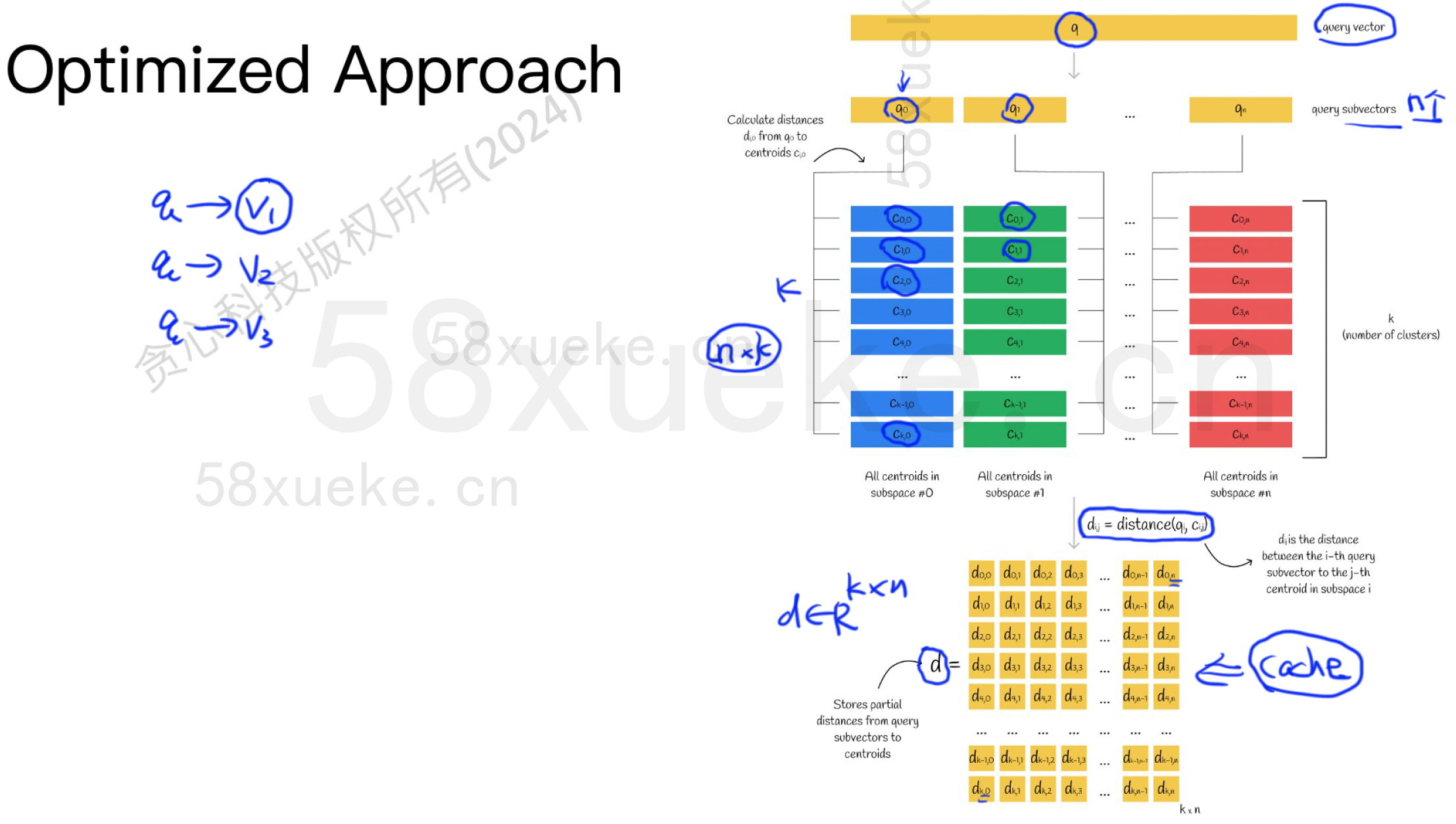
-
查询向量
q的处理: 查询向量q保持为原始D维float向量,不进行 PQ 压缩编码。但为了距离计算,q也需要被划分为M个子向量:q = [q⁽¹⁾, q⁽²⁾, ..., q⁽ᴹ⁾]。
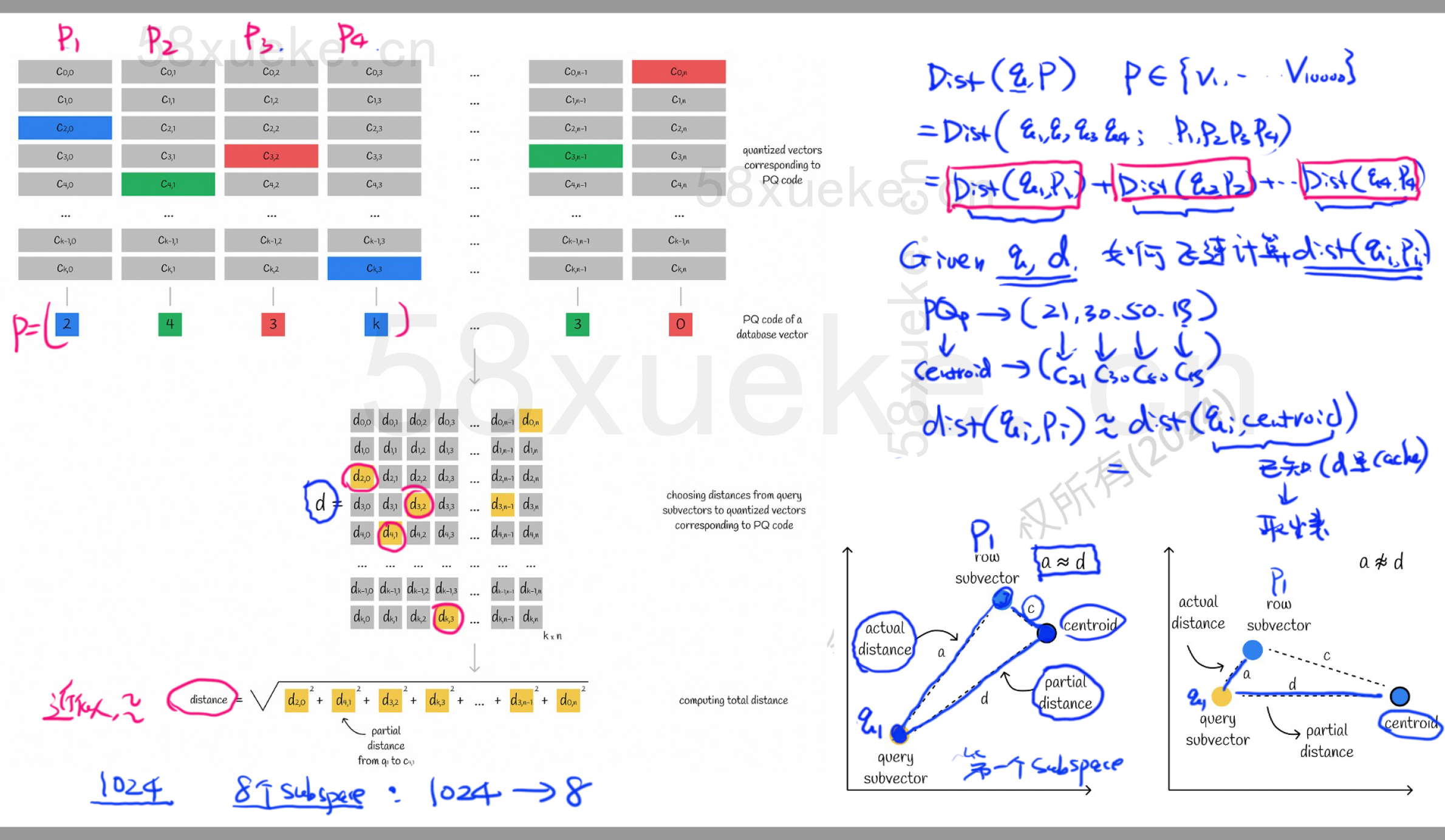
-
核心优化 - 预计算距离表 (Distance Tables):
-
对于每个子空间
m(m = 1, 2, ..., M):-
计算查询子向量
q⁽ᵐ⁾到该子空间码本C⁽ᵐ⁾中所有 K 个中心{c₀⁽ᵐ⁾, c₁⁽ᵐ⁾, ..., c_{K-1}⁽ᵐ⁾}的距离 (L2距离平方通常更方便)。 -
将这些距离存储在一个查询表 (Lookup Table)
T⁽ᵐ⁾中:T⁽ᵐ⁾[k] = || q⁽ᵐ⁾ - cₖ⁽ᵐ⁾ ||²(k = 0, 1, ..., K-1)。
-
-
最终得到
M个距离表T⁽¹⁾, T⁽²⁾, ..., T⁽ᴹ⁾,每个表有K项。
-
-
计算近似距离: 要计算查询
q与数据库中某个 PQ 编码向量x(其编码为[i₁, i₂, ..., i_ᴍ]) 之间的近似欧氏距离平方:-
对于每个子空间
m,使用x在该子空间的编码索引iₘ去查表T⁽ᵐ⁾,得到q⁽ᵐ⁾到x的第m个子向量所对应中心c_{iₘ}⁽ᵐ⁾的距离平方:dₘ = T⁽ᵐ⁾[iₘ] = || q⁽ᵐ⁾ - c_{iₘ}⁽ᵐ⁾ ||²。 -
将所有
M个子空间的距离平方求和:dist²(q, x) ≈ Σₘ₌₁ᴹ dₘ = Σₘ₌₁ᴹ T⁽ᵐ⁾[iₘ] = Σₘ₌₁ᴹ || q⁽ᵐ⁾ - c_{iₘ}⁽ᵐ⁾ ||²
-
-
为什么是近似距离? 因为我们没有原始
x,只有它每个子向量对应的中心点c_{iₘ}⁽ᵐ⁾。我们用Σₘ || q⁽ᵐ⁾ - c_{iₘ}⁽ᵐ⁾ ||²来近似真正的欧氏距离平方|| q - x ||²。 -
效率: 计算
dist²(q, x)只需要M次查表 (T⁽ᵐ⁾[iₘ]) 和M-1次加法,复杂度是O(M),远低于直接计算原始D维向量距离的O(D)。预计算M个距离表的复杂度是O(M*K*d)=O(D*K)(因为M*d = D),但只需要对查询q做一次。
查表加速的关键点
这个距离矩阵被缓存(cache)下来,作用是:
当我们检索数据库中 PQ 编码的向量时(如
[c_0, c_1, ..., c_{m-1}]),我们只需把这些索引拿来在这张矩阵中查表加和即可!
举个例子:
数据库中某个向量的 PQ 编码是 [5, 22, 100, ..., 12],那么:
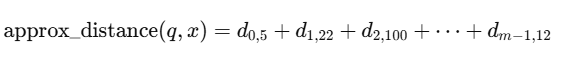
这个过程是无乘法、无还原、纯查表加法,非常快。

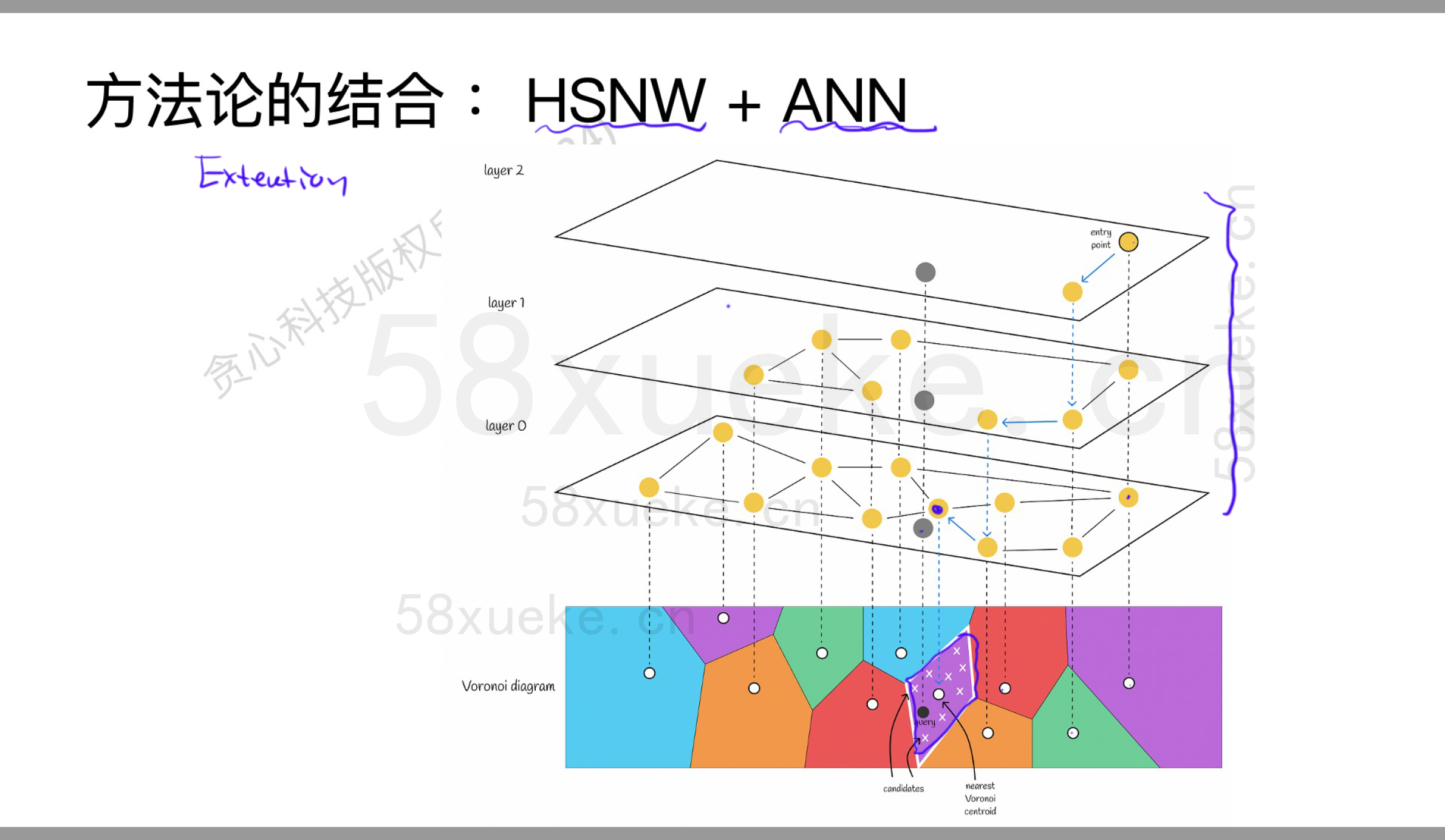
可以一起结合使用。可以先做近似KNN,当到达具体某个区域时,使用PQ。
为什么查询向量不做 K-Means?
查询阶段的目标是:尽可能快地估算查询向量与数据库中编码向量之间的距离,而不是对查询向量再做编码或聚类。其次,查询向量没有必要编码压缩(会丢失查询向量的精度,导致搜索质量下降)。
查询向量不做 K-Means,是因为它不是为了编码压缩,而是为了高效、精确地构造查找表来参与距离计算(ADC)。这是 PQ 的核心设计理念。
NSW
NSW 是什么?
NSW(Navigable Small World)图是一种用于高效 近似最近邻搜索(ANN) 的图结构,灵感来自于“小世界网络”(Small World Network)理论。它的设计目标是在高维空间中支持快速、高质量的近似搜索,同时保持可扩展性。
其核心思想是:构建一个稀疏图,图中的点彼此“导航性”强,即从任意一点出发,通过一系列跳跃,很快就能到达查询点的近邻。
理论背景:Small World Network
-
小世界性质(Small World Property):
-
平均路径长度短(即任意两个点之间的平均最短路径很小)
-
节点之间高度聚类
-
-
Kleinberg's Navigable Small World 模型:
-
添加远距离“跳跃”边,使得贪心算法可以高效导航整个网络
-
NSW结构的灵感来自该模型
-
NSW 的核心组成
NSW 是一种 基于图的近似最近邻索引结构,具体特征如下:
-
数据点作为图的节点(vertices)
-
每个节点连接到一部分其他节点,形成边(edges)
-
图不要求全连接,反而要稀疏(每个点只连接K个近邻)
NSW 图的构建过程
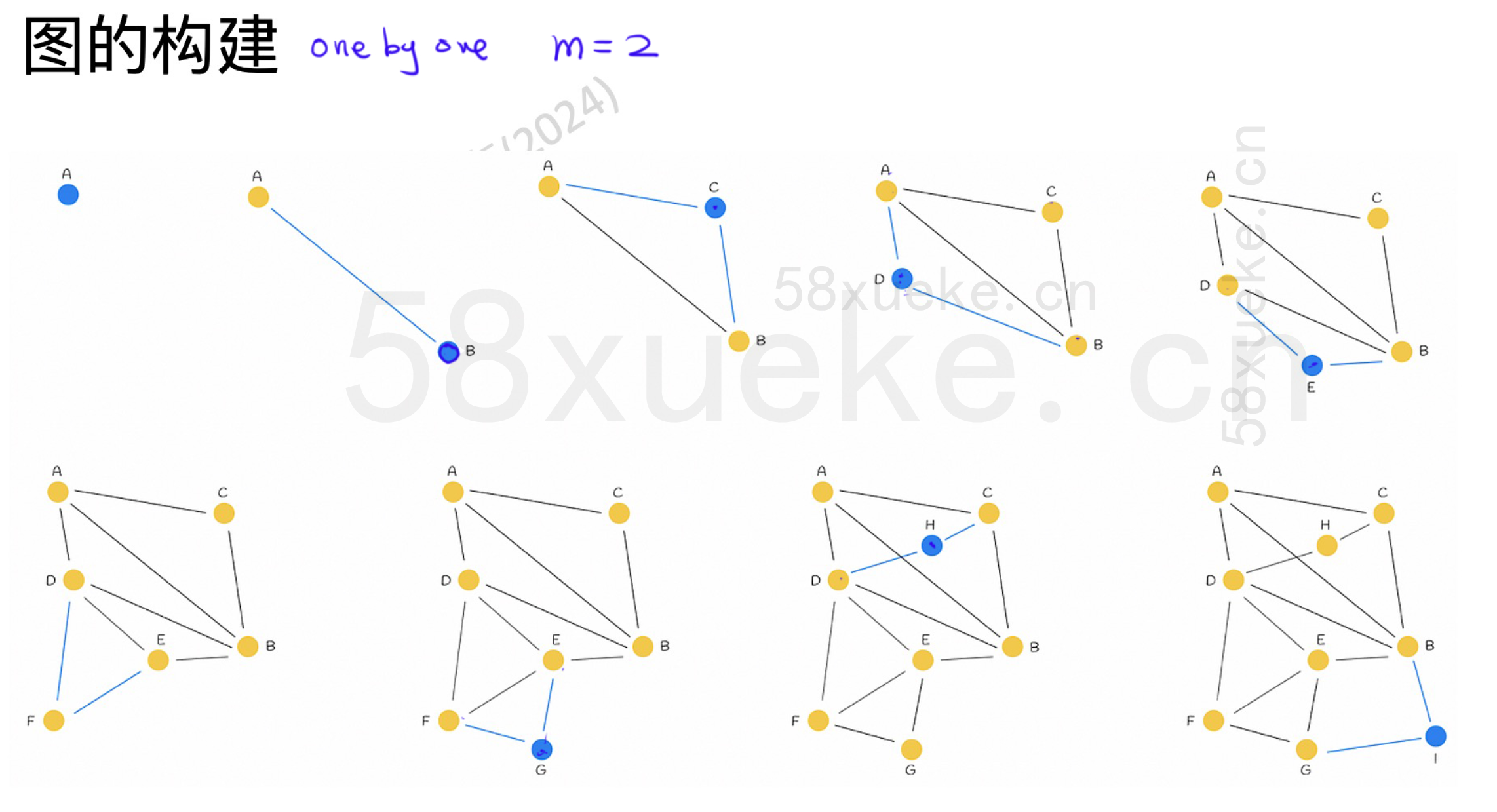
一个节点一个节点地构造,在构造时会设置m(每个节点允许它跟多少个节点相连接)。
1. 初始化:
-
创建空图
-
插入第一个点,图中只有一个节点
2. 插入一个新数据点的过程:
对于新点 x_new:
-
近似搜索:使用当前图,通过贪心搜索或多起点搜索,找到其
efConstruction个近似近邻 -
选择邻居:从这些近邻中选择前
M个距离最近的作为连接边(也可以使用邻居选择策略) -
添加边:将
x_new与这些邻居互相连边
3. 重复:
-
对每个数据点重复上述过程,直到全部点插入
⚠ NSW 是一种“在线插入”的结构,不像KD-Tree那样需要构建完成才能用。
构建图的复杂度
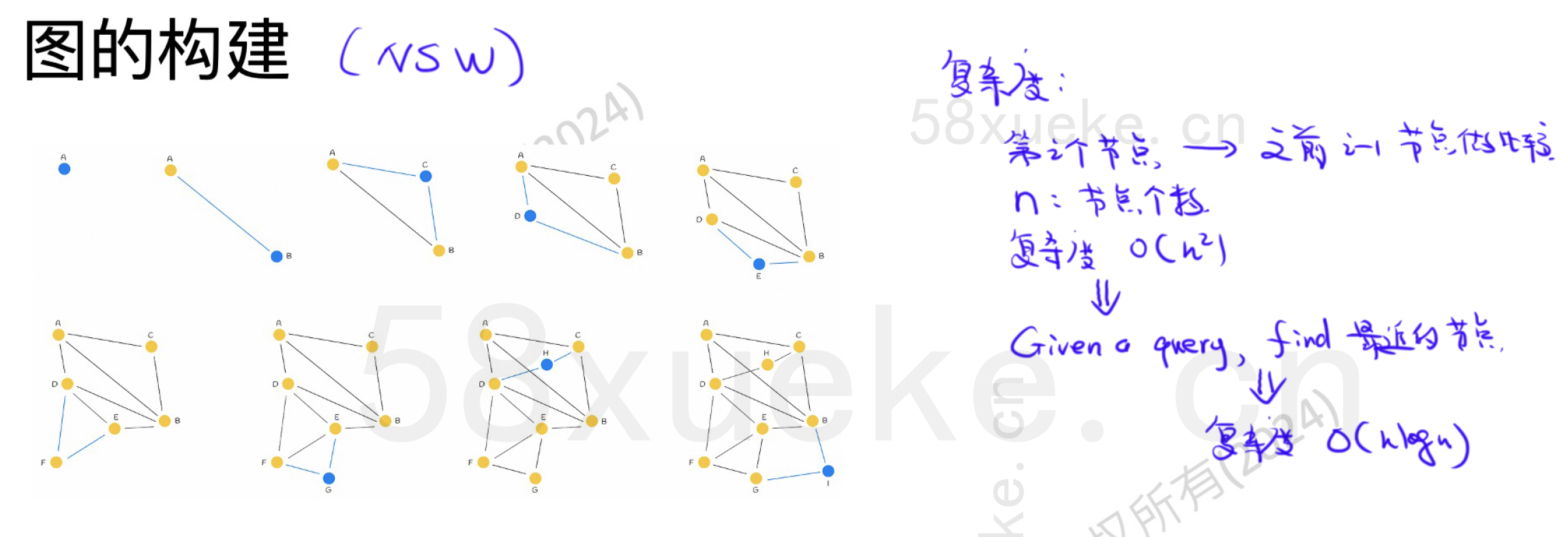
构建过程中,每插入一个节点 x_i,需要在当前图中找到其近邻。
-
如果不使用加速结构(如层次索引或树结构),你需要和前面的所有
i-1个节点作距离比较 -
这样,第一个点不比,第二个比1次,第三个比2次……最后一个比
n-1次 -
总复杂度:
所以,如果 从0构建 NSW 图,在没有优化的前提下是
时间复杂度。
为什么实际构造图是 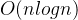 ?
?
在实际实现中(如 nmslib),每插入一个点 x_i:
-
不是暴力比对所有已有点;
-
而是利用已有图结构,从某个起点出发,进行近似搜索(和查询流程几乎一样);
-
搜索过程中维护一个候选集(
efConstruction),只考察这部分节点; -
最后从这些近邻中选出
M个作为连接边。
这样:
-
插入一个点的近邻搜索就类似一次图中“查询”的过程;
-
每次的代价是:
因此总构建复杂度是:
搜索过程
搜索一个查询向量 q 的近似最近邻:
-
选起点:从图中随机选择一个或多个起始节点
-
贪心搜索:从当前节点开始,贪心地跳向更接近查询点的邻居
-
局部最优跳出:当无法找到更近的邻居时,当前节点即为局部最优
-
重复若干起点(Multi-Start):增加搜索范围
-
返回最优节点:选取在搜索过程中遇到的 top-k 最近点
HNSW
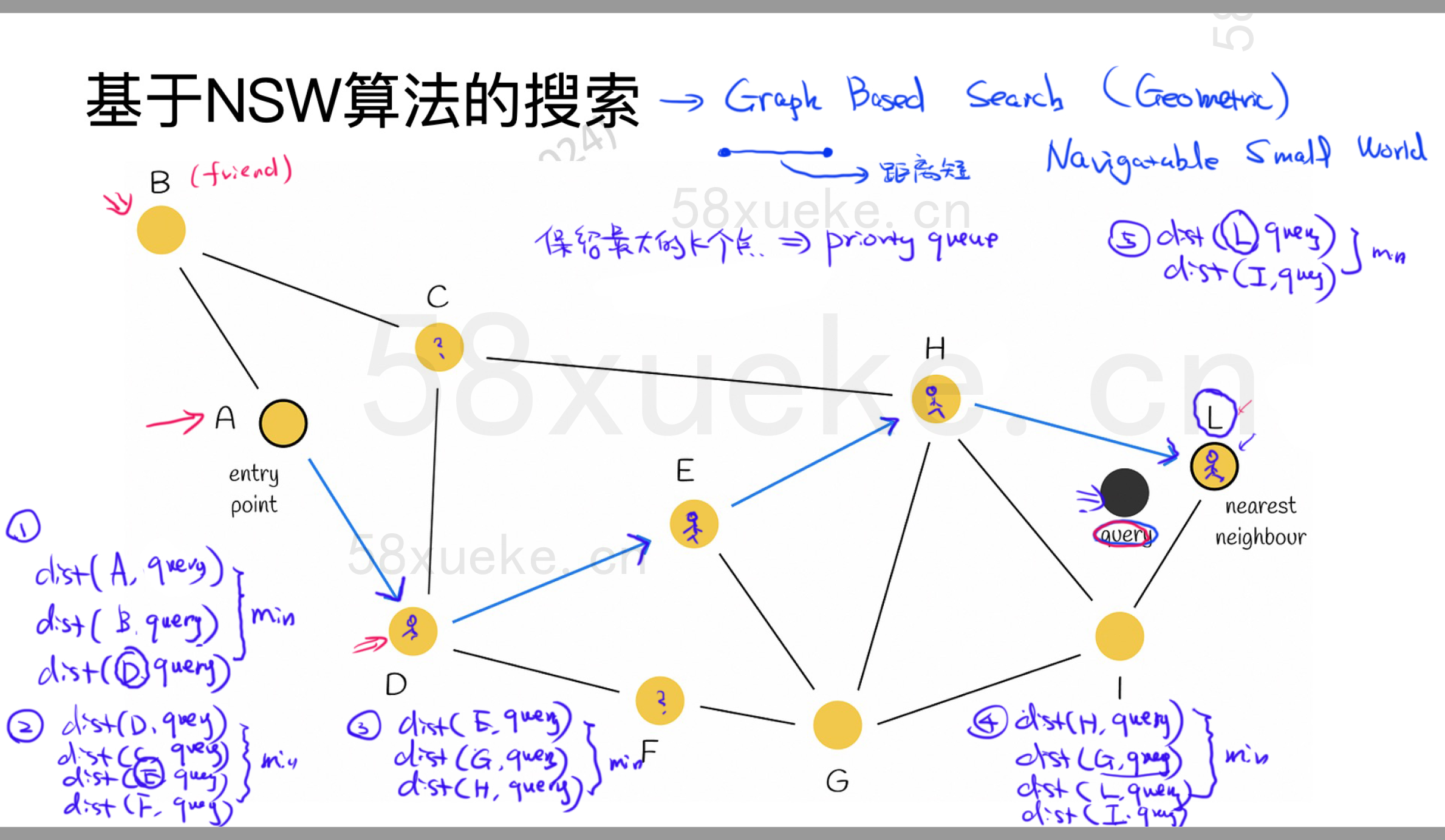
高速公路思想
在HNSW中,搜索从一个“高层抽象地图”开始,就像你从高速公路(快速路径)进入城市一样,逐层接近目标。这种设计灵感可以类比为:
高速公路 = 高层图:快速穿越大范围区域
小街道 = 底层图:细致探索目标周围区域
由此,我们的改进方向:指定高速公路和小街道。
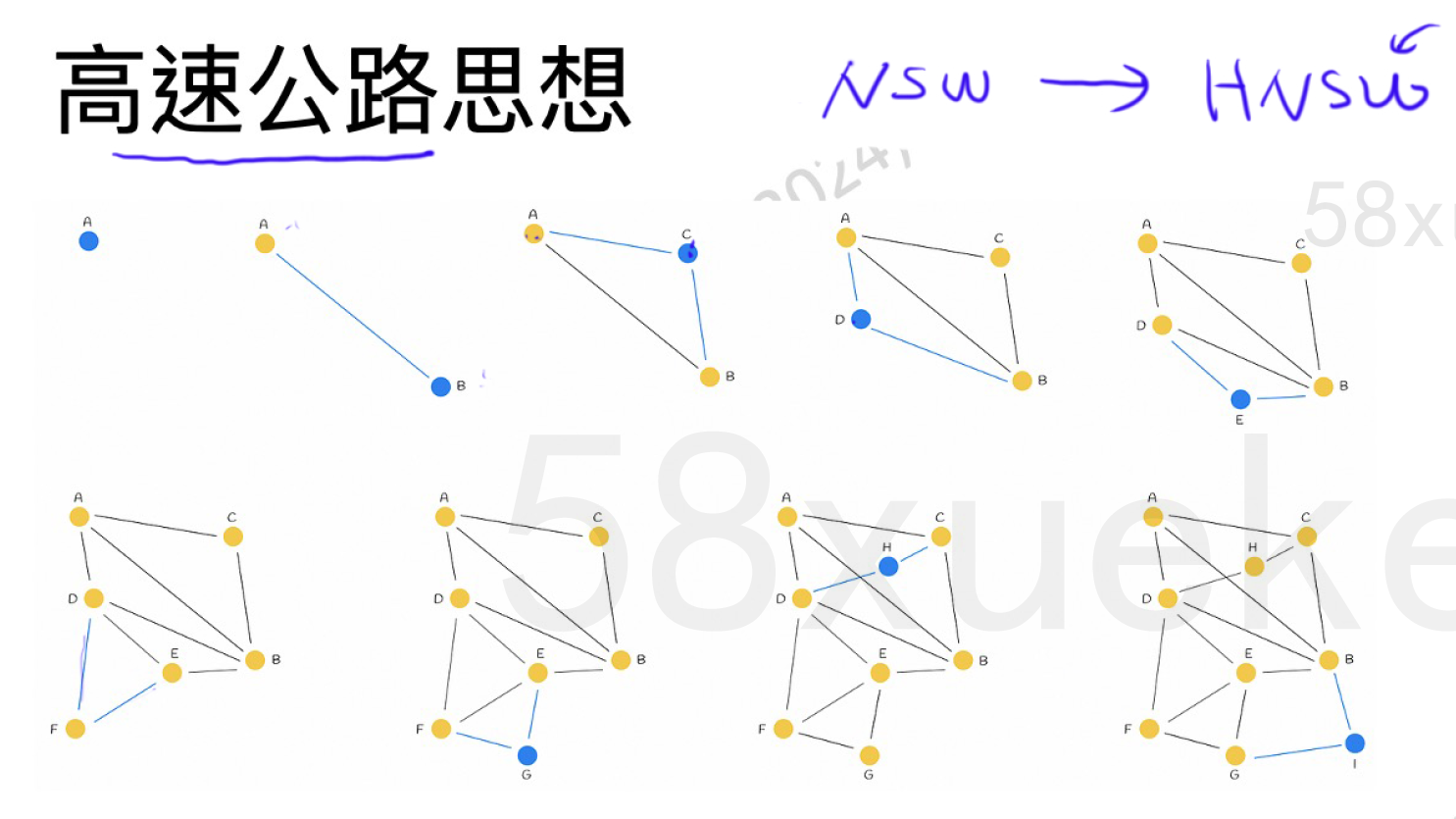
Skip List
跳表(Skip List) 是一种基于概率的高效数据结构,融合了链表的灵活性与二分查找的高效性,可支持 O(log n) 复杂度的搜索、插入和删除操作。它通过构建多层级的“快速通道”实现加速,是平衡树的简洁替代方案。
关键设计:随机化层高
跳表的核心魔法在于:每个节点的层高由概率决定(如掷硬币)。某层的块能跳到下一个相同层的块,实现高速公路。
-
规则:
-
所有节点必在 L0 层。
-
50% 概率升至 L1,50% 概率停止。
-
升至 L1 的节点中,50% 概率升至 L2,依此类推。
-
-
效果:
-
高层节点指数级减少(≈ 1/2ᵏ 节点在 Lk 层)。
-
结构近似平衡,无需旋转(相比平衡树)。
-
举例:插入节点 6 的随机层高过程:
-
必插入 L0:
1→3→5→6→7→9... -
从L0的1开始,掷硬币:正面 → 升至 L1
-
再掷:反面 → 停止。跳到L0的3。
-
再掷:反面 → 停止。跳到L0的5。
-
再掷:正面 → 升至 L1。
-
再掷:正面 → 升至 L2。
-
再掷:反面 → 停止。跳到L0的6。
-
再掷:反面 → 停止。跳到L0的7。
-
再掷:正面 → 升至 L1。
-
再掷:正面 → 升至 L2。
-
再掷:反面 → 停止。跳到L0的9。
-
……
NSW结合Skip List思想
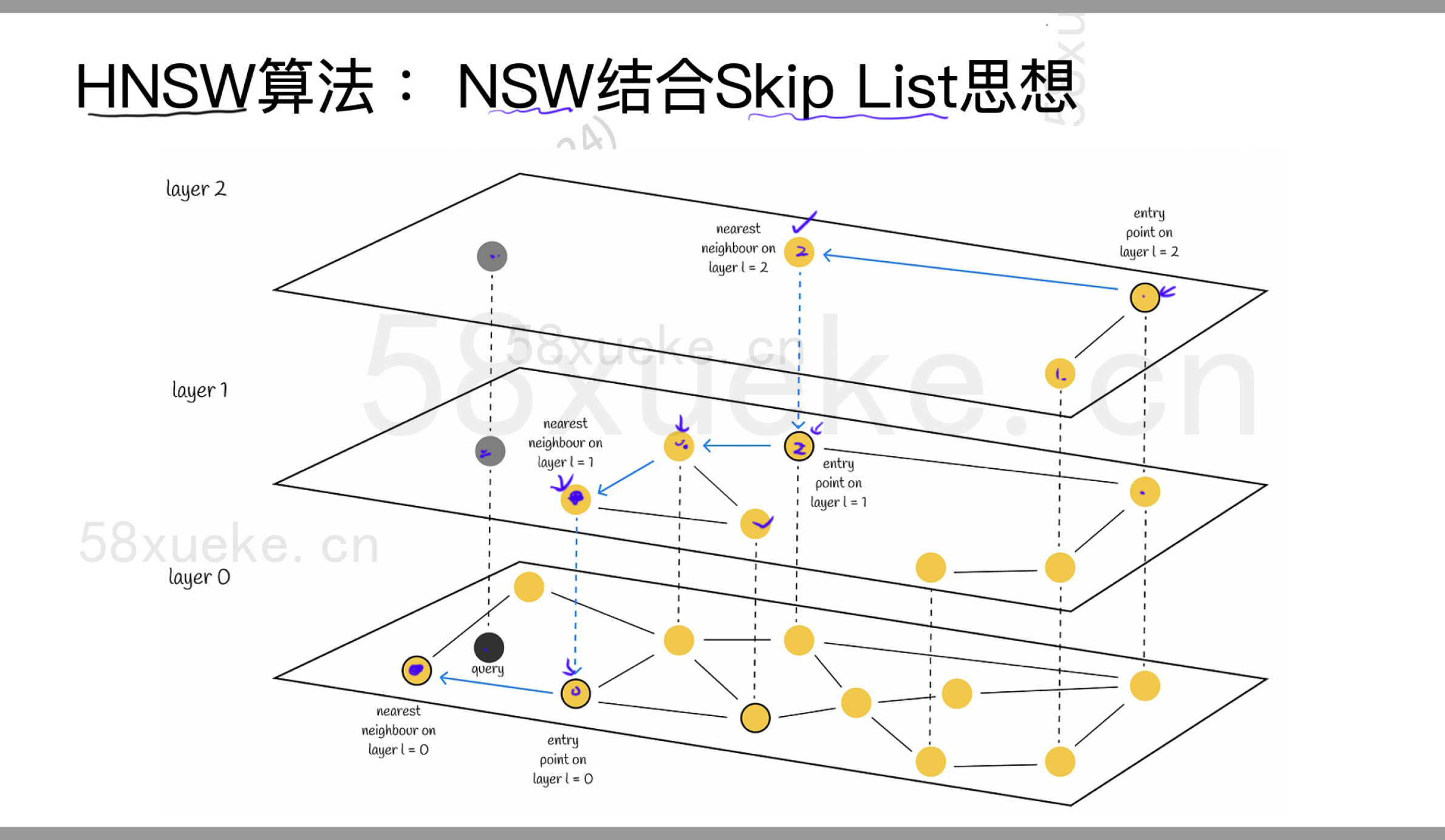
搜索流程
Step 1️⃣:从 Level 2 开始(高速公路入口)
-
起点随机选择一个 Level 2 的节点,比如
A -
使用贪心策略:在
A的邻居中选择距离q最近的一个,比如找到B -
再从
B的邻居找,发现C比B更靠近q -
继续搜索直到无法更新更近的点,比如
C是最接近的 -
Level 2 搜索结束,当前最近点是
C
类比:你开车上高速,在城市的高层地图上,从北京开到杭州的大概方向。
Step 2️⃣:降到 Level 1(开始进城市)
-
从刚才 Level 2 找到的
C开始,在 Level 1 上继续贪心搜索 -
C的邻居有 F、G、D,你发现 G 更接近q,继续前进 -
最终找到一个点
E,是当前最接近q的 Level 1 节点 -
不能再变得更近了 → 结束 Level 1 的搜索
类比:你已经从高速口下来,在城市主干道导航到更靠近目标的大概街区
Step 3️⃣:降到 Level 0(深入街区精确找目标)
-
在 Level 0,从
E开始,用优先队列 + 局部扩展搜索 -
扩展
E的近邻,比如发现E1,E2,E3 -
这些中,
E2距离q最近,继续扩展E2的邻居…… -
直到收敛于最靠近
q的 K 个点(返回 Top-K 近邻)
类比:你已经在城市小路上走,问路、兜圈,最终精确找到目标门牌。
HSNN+ANN

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)