Ollama本地部署大模型
Ollama是一个开源工具,支持在本地运行和部署大型语言模型(LLM),如LLaMA、Mistral等。它简化了模型下载、配置和管理过程,适合开发者和研究者使用。安装支持macOS、Linux和Windows系统,通过简单命令即可下载和运行模型。Ollama提供预量化模型,支持自定义配置、GPU加速和REST API集成,还可通过Docker部署。常见问题包括性能优化和网络代理设置,适用于本地开发
Ollama 简介
Ollama 是一个开源工具,支持在本地运行和部署大型语言模型(LLM)。它简化了模型的下载、配置和管理,支持多种模型架构(如 LLaMA、Mistral、Gemma 等),适合开发者和研究者快速在本地环境中测试和运行大模型。
安装 Ollama
操作系统支持:macOS、Linux(Windows 可直接下载)。
-
macOS/Linux 安装
从官方 GitHub 或网站下载安装包,或通过命令行安装:curl -fsSL https://ollama.ai/install.sh | sh -
Windows 用户
到Ollama下载安装即可,安装过程和一般软件一致。
https://ollama.com/
下载与运行模型
命令行使用打开windows命令行,可在命令行使用。
基本命令:
查看版本:ollama -v
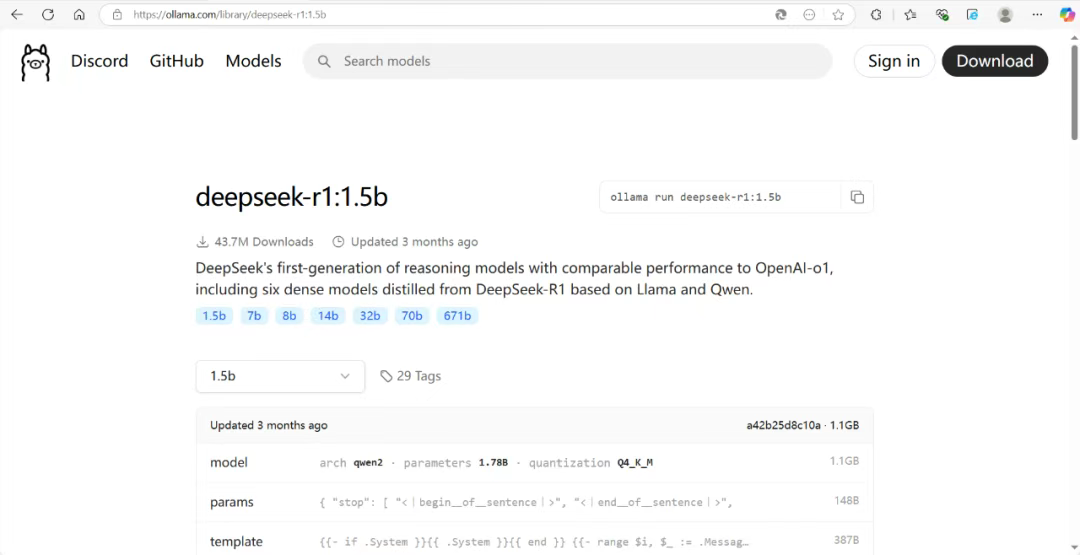
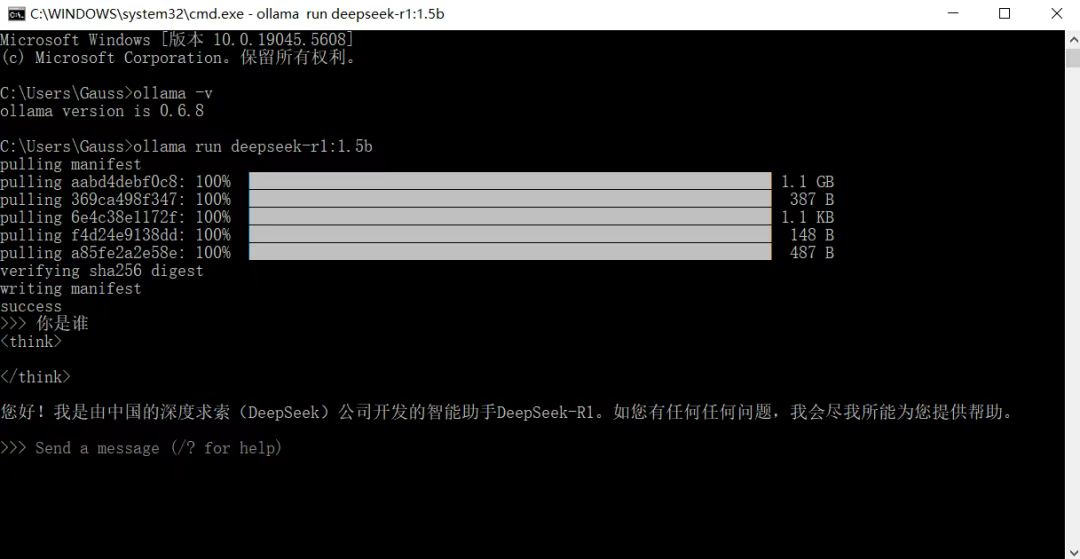
使用大模型(以deepseek-r1-1.5b模型为例,首次使用会下载):
ollama run deepseek-r1:1.5b
Ollama 提供预量化模型,可直接通过命令拉取和运行:
ollama pull llama3 # 下载 LLaMA3 模型
ollama run llama3 # 运行模型交互界面
支持的其他模型包括 mistral、gemma、phi3 等,完整列表可通过 ollama list 查看。
也可以在官网https://ollama.com/search查看自行下载
本地化使用
下载完之后就可以直接在本地使用了
配置与自定义
-
修改模型参数
创建自定义配置文件(如Modelfile)调整参数(如温度、上下文长度):FROM llama3 PARAMETER temperature 0.7 PARAMETER num_ctx 4096构建并运行自定义模型:
ollama create my_model -f Modelfile ollama run my_model -
GPU 加速
若系统支持 CUDA,Ollama 会自动启用 GPU 加速。可通过环境变量强制指定:OLLAMA_NO_CUDA=0 ollama run llama3
高级功能
-
REST API 集成
Ollama 提供本地 API(默认端口11434),可用于与其他应用交互:curl http://localhost:11434/api/generate -d '{ "model": "llama3", "prompt": "为什么天空是蓝色的?" }' -
Docker 部署
适用于隔离环境或云部署:docker run -d -p 11434:11434 --name ollama ollama/ollama
常见问题
- 性能优化:确保系统内存足够(如 7B 模型需至少 8GB RAM)。
- 模型存储:默认路径为
~/.ollama,可通过环境变量OLLAMA_MODELS修改。 - 网络代理:若拉取模型失败,检查代理设置或使用镜像源。
通过上述步骤,可快速在本地部署和定制大模型,适用于开发、测试或研究场景。更多细节参考 Ollama 官方文档。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)