Linux 部署 Ollama + DeepSeek-R1,配置 Page Assist 浏览器插件
最近倒腾在自己本机本上的虚拟机中部署DeepSeek-R1大模型,其中有不少踩坑的地方,在统一这里记录下来,同时提供给猿友们以作参考。Ollama 是一个开源的、可以在本地运行大型语言模型的工具。它允许用户在自己的设备上部署和运行语言模型,而不必完全依赖云端服务。这在数据隐私等方面有诸多优势,比如用户担心数据发送到云端会产生安全风险,使用 Ollama 就可以在本地处理数据。1、更新一下 apt
最近在自己笔记本上的 VM 虚拟机(Debian12)中部署 DeepSeek-R1 大模型,其中有不少踩坑的地方,在这里记录下来,同时提供给猿友们以作参考。
关于RAG的实现请看:通过 Page Assist 浏览器插件实现 DeepSeek-R1 RAG(检索增强生成)
前言
Ollama 是一个开源的、可以在本地运行大型语言模型的工具。它允许用户在自己的设备上部署和运行语言模型,而不必完全依赖云端服务。这在数据隐私等方面有诸多优势,比如用户担心数据发送到云端会产生安全风险,使用 Ollama 就可以在本地处理数据。
Ollama 官网:https://ollama.com/
Page Assist 是一款用于 Chrome/Edge 浏览器的扩展插件,主要功能是为本地运行的 AI 模型提供直观的操作界面,方便用户进行各种任务。它支持与本地AI模型交互,提供便捷的侧边栏操作、视觉模型支持(如图像识别)、简洁的 WebUI 界面、与 PDF 文件和文档进行聊天交流等功能。
DeepSeek-R1 共有7个版本,由于虚拟机配置有限,本次选择最小的 DeepSeek-R1:1.5b 版本进行测试。
一、前期准备
1、切换至 root 用户
su root2、更新一下 apt 源和软件包
apt-get update && sudo apt-get upgrade -y3、安装必要的工具
apt-get install -y wget curl git pciutils lshw二、安装 Ollama
1、方法一:执行命令安装 Ollama(这里如果下载太慢,可使用第二种方法)
curl -fsSL https://ollama.com/install.sh | sh2、方法二:下载 Ollama 慢或卡顿解决方案
(1)下载 ollama_install.sh 并保存
curl -fsSL https://ollama.com/install.sh -o ollama_install.sh(2)使用 github 文件加速替换 github 下载地址(注意:请将 v0.5.12 替换成自己对应的 ollama 版本号)
sed -i 's|https://ollama.com/download/ollama-linux|https://gh.llkk.cc/https://github.com/ollama/ollama/releases/download/v0.5.12/ollama-linux|g' ollama_install.sh
(3)替换后增加可执行权限
chmod +x ollama_install.sh(4)执行sh下载安装
sh ollama_install.sh三、更改 Ollama 模型路径(可跳过)
在 Linux 系统中,Ollama 默认的模型存储路径为:/usr/share/ollama/.ollama/models,如要更改模型存储路径,有以下两种方式。
1、临时更改(当前会话有效)
添加环境变量
export OLLAMA_MODELS="/data/ollama/models"2、永久更改
(1)创建新的模型存储目录
首先,创建一个新的目录作为模型存储路径。例如,创建 /data/ollama/models 目录:
mkdir -p /data/ollama/models(2)更改目录权限
确保新目录的权限设置正确,允许 Ollama 访问和写入:
chown -R ollama:ollama /data/ollama/models
chmod -R 775 /data/ollama/models(3)修改 Ollama 服务配置文件
①编辑服务配置文件
使用文本编辑器(如 vim)编辑 Ollama 服务的配置文件:
vim /etc/systemd/system/ollama.service②修改配置内容
在 [Service] 部分的 Environment 字段后,添加新的 Environment 字段,指定新的模型路径,并修改访问权限:
Environment="OLLAMA_MODELS=/data/ollama/models"
Environment="OLLAMA_HOST=0.0.0.0" # 允许外部网络访问
Environment="OLLAMA_ORIGINS=*" # 允许所有域访问完整的配置示例如下:
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/root/anaconda3/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
Environment="OLLAMA_MODELS=/data/ollama/models"
Environment="OLLAMA_HOST=0.0.0.0"
Environment="OLLAMA_ORIGINS=*"
[Install]
WantedBy=default.target(4)重载配置并重启 Ollama 服务
①重载系统服务配置
systemctl daemon-reload②重启 Ollama 服务
systemctl restart ollama.service③查看 Ollama 服务状态
systemctl status ollama④查看 Ollama 服务日志
journalctl -u ollama.service⑤关闭 Ollama 服务
systemctl stop ollama(5)验证更改
①检查默认路径
进入默认的模型路径 /usr/share/ollama/.ollama/models,会发现 models 文件夹已经消失。
②检查新路径
在新的路径 /data/ollama/models 下,会看到生成了 blobs 和 manifests 文件夹,这表明模型路径已经成功更改。
四、运行模型
1、启动 ollama 服务(后台启动)
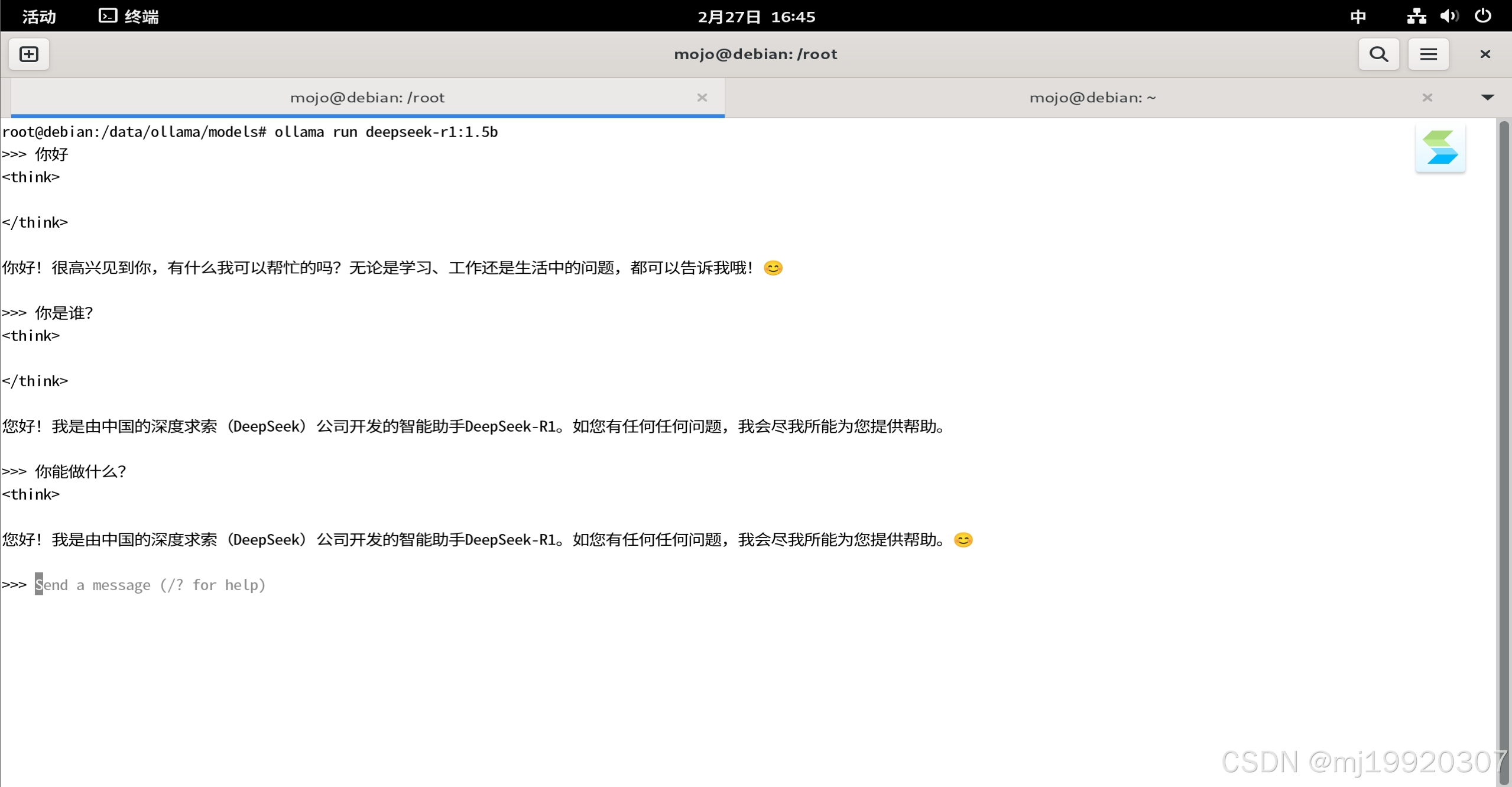
systemctl restart ollama.service2、下载并运行模型(如果本地已下载过该模型,则直接运行)
ollama run deepseek-r1:1.5b3、至此,DeepSeek-R1 就算是部署起来了,简直不要太简单
五、Page Assist浏览器插件安装与配置
1、打开 Edge 浏览器,进入扩展商店
2、在搜索框中搜索 Page Assist
3、点击【获取】按钮添加至浏览器
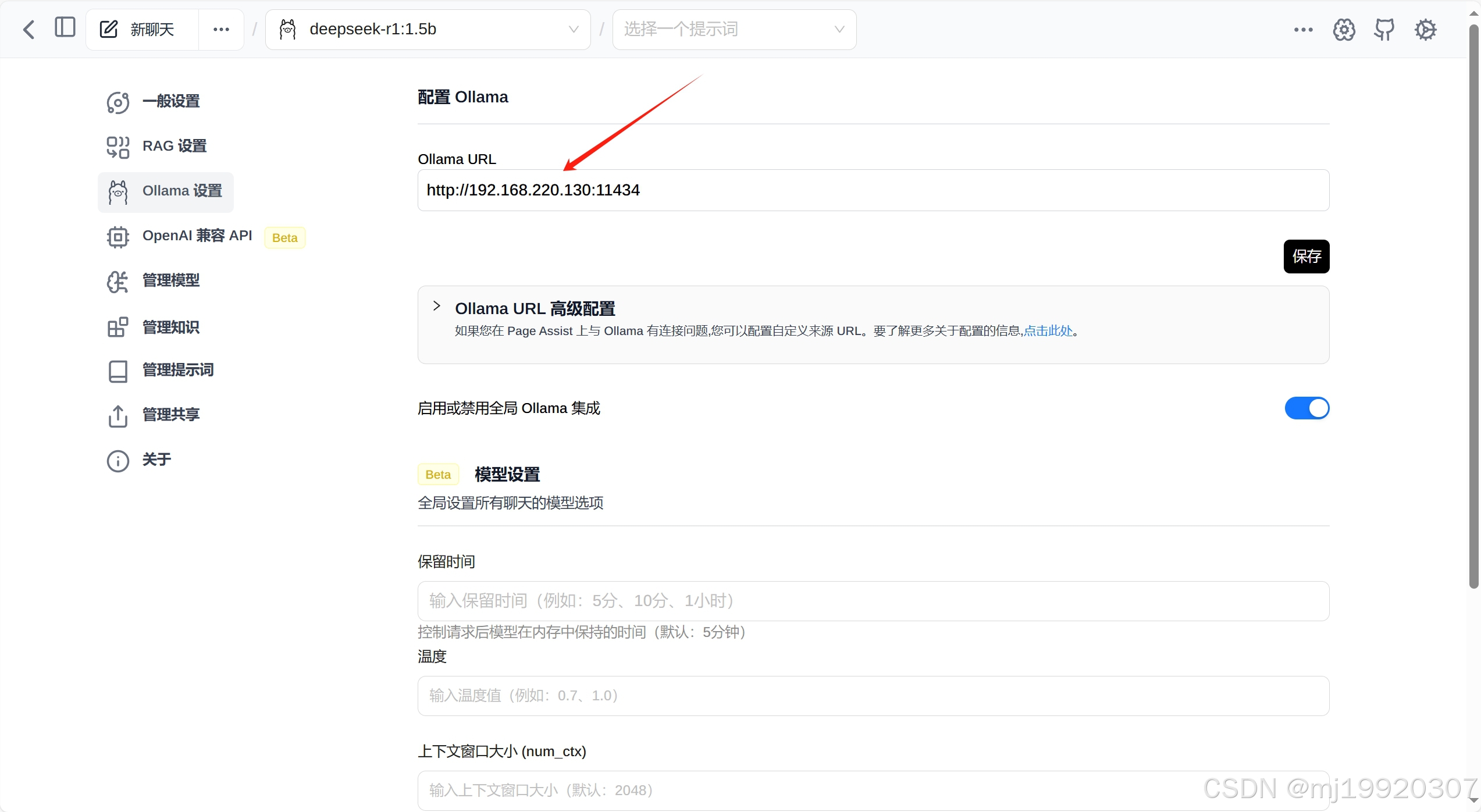
4、打开 Page Assist 进行配置
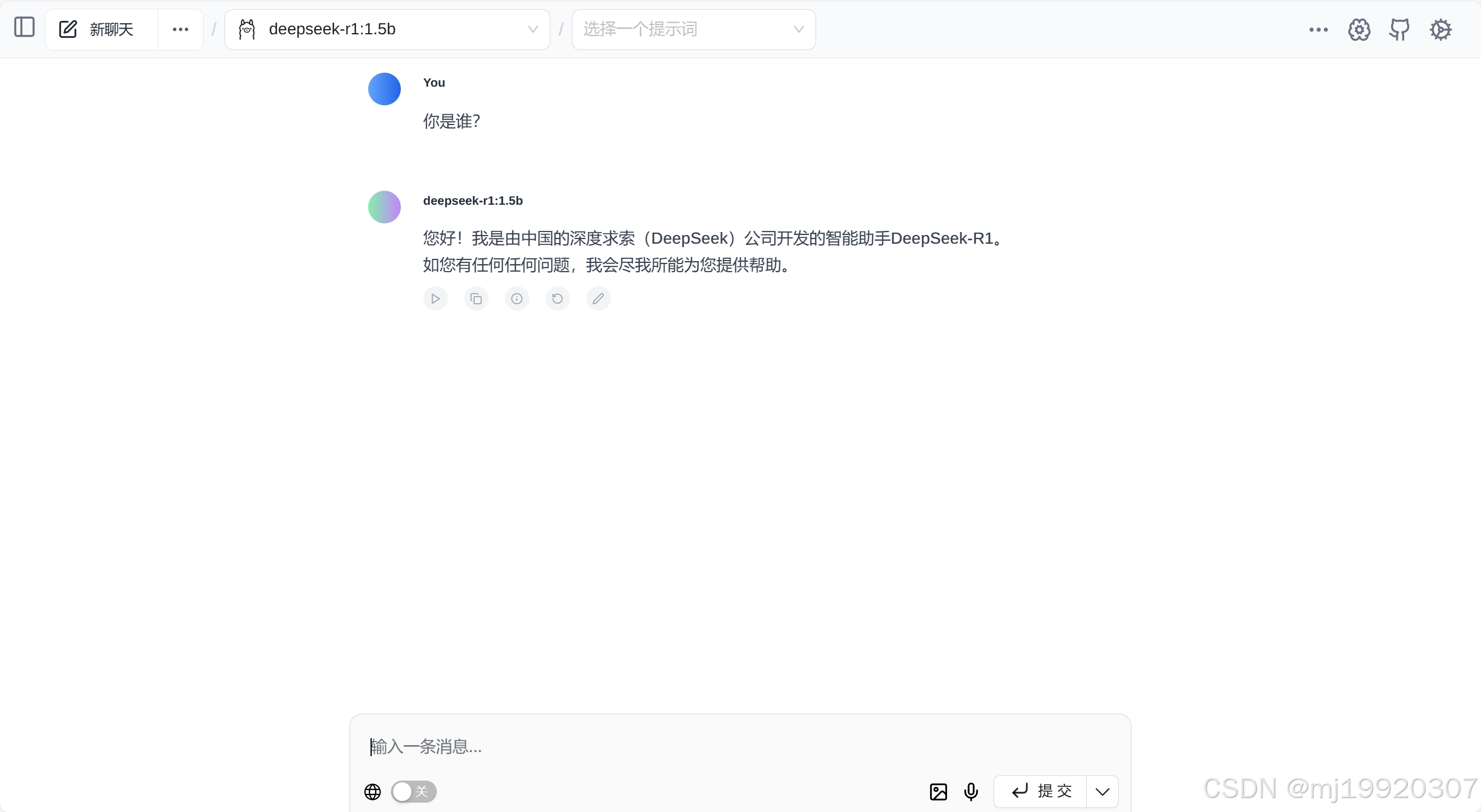
5、进入 Page Assist 对话窗口
六、Ollama 使用教程
1、Ollama 基础命令
(1)启动 Ollama 服务(后台运行)
systemctl restart ollama.service(2)停止 Ollama 服务
ps -ef | grep ollama
kill -9 <PID>(3)更新 Ollama
ollama upgrade2、模型管理
(1)下载预训练模型
# 下载官方模型(如 deepseek-r1:1.5b、llama2、mistral)
ollama pull <model-name>
# 示例
ollama pull deepseek-r1:1.5b(2)查看已安装模型
ollama list(3)运行模型(启动交互式对话)
# 启动交互式对话
ollama run <model-name>
# 示例
ollama run deepseek-r1:1.5b(4)停止模型
ollama stop <model-name>(5)删除模型
ollama rm <model-name>(6)从 Modelfile 创建自定义模型
①创建一个 Modelfile 文件
FROM <model-name> # 基础模型
SYSTEM """你是一个友好的助手,用中文回答。"""
PARAMETER temperature 0.7 # 控制生成随机性(0-1)②构建自定义模型
ollama create <my-model> -f Modelfile③运行自定义模型
ollama run <my-model>3、高级功能
(1)通过 HTTP 调用 API(默认端口 11434)
①启动 API 服务(默认端口 11434)
ollama serve②通过 HTTP 调用 API
curl http://localhost:11434/api/generate -d '{
"model": "deepseek-r1:1.5",
"prompt": "你好,请介绍一下你自己",
"stream": false
}'(2)多会话管理
# 启动一个会话并命名
ollama run <model-name> --name chat1
# 在另一个终端启动新会话
ollama run <model-name> --name chat2(3)环境变量配置
# 更改默认端口
OLLAMA_HOST=0.0.0.0:8080 ollama serve
# 使用 GPU 加速(需 NVIDIA 驱动)
OLLAMA_GPU_METAL=1 ollama run <model-name>4、常见问题与技巧
(1)加速模型下载
# 使用镜像源(如中国用户)
OLLAMA_MODELS=https://mirror.example.com ollama pull <model-name>(2)查看日志
tail -f ~/.ollama/logs/server.log(3)模型参数调整
在 Modelfile 中可设置:
-
temperature: 生成随机性(0=确定,1=随机) -
num_ctx: 上下文长度(默认 2048) -
num_gpu: 使用的 GPU 数量
(4)模型导出与分享
# 导出模型
ollama export <my-model> > <my-model.tar>
# 导入模型
ollama import <my-model.tar>
火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)