FrameShield: Adversarially Robust Video Anomaly Detection
弱监督视频异常检测(WSVAD)已经取得了显著进展,但现有模型仍然容易受到对抗攻击的影响,限制了其可靠性。由于弱监督的固有限制——尽管需要帧级预测,但只提供视频级标签——传统的对抗防御机制,如对抗训练,效果不佳,因为视频级对抗扰动通常较弱且不足。为了解决这一限制,直接从模型生成的伪标签可以实现帧级对抗训练;然而,这些伪标签本质上是嘈杂的,显著降低了性能。因此,我们引入了一种新颖的伪异常生成方法,称

FrameShield: Adversarially Robust Video Anomaly Detection
NeurIPS 2025
https://arxiv.org/pdf/2510.21532
摘要
弱监督视频异常检测(WSVAD)已经取得了显著进展,但现有模型仍然容易受到对抗攻击的影响,限制了其可靠性。由于弱监督的固有限制——尽管需要帧级预测,但只提供视频级标签——传统的对抗防御机制,如对抗训练,效果不佳,因为视频级对抗扰动通常较弱且不足。为了解决这一限制,直接从模型生成的伪标签可以实现帧级对抗训练;然而,这些伪标签本质上是嘈杂的,显著降低了性能。因此,我们引入了一种新颖的伪异常生成方法,称为时空区域扭曲(SRD),该方法通过在正常视频的局部区域应用严重增强同时保持时间一致性来创建合成异常。将这些精确标注的合成异常与嘈杂的伪标签相结合,显著减少了标签噪声,实现了有效的对抗训练。大量实验表明,我们的方法显著增强了WSVAD模型对对抗攻击的鲁棒性,在多个基准测试中,整体AUROC性能平均优于最先进方法71.0%。实现和代码可在https://github.com/rohban-lab/FrameShield上公开获取。
1 Introduction
视频异常检测是监控系统的基本组成部分,其应用跨越公共安全、医疗保健和工业监控,用于识别罕见和危险事件,如事故、暴力和设备故障[Gopalakrishnan, 2012], [Sultani et al., 2018]。近年来,由于帧级标注的劳动密集性,研究已转向弱监督视频异常检测[WSVAD][Majhi et al., 2021], [Yang et al., 2022], [Jia et al., 2023]。确保对对抗攻击的鲁棒性对于在关键和高可靠性场景中部署机器学习模型至关重要[Rony et al., 2019]。这些攻击在输入视频中引入细微、几乎无法察觉的扰动,导致模型将正常帧误分类为异常,反之亦然。尽管最先进的VAD方法在标准条件下已展现出接近最优的性能,但它们对对抗扰动的敏感性导致性能显著下降,如图1所示,这引发了对其在现实世界应用中可靠性和鲁棒性的严重担忧。
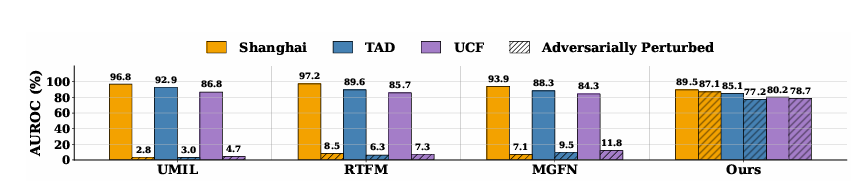
图1:视频异常检测(VAD)方法的鲁棒性评估:对最先进的VAD方法在公认的基准数据集(Shanghai、TAD和UCF Crime)上,于标准条件和对抗攻击两种场景下进行的比较评估。结果凸显了现有最先进方法的脆弱性,并展示了我们所提出的方法FrameShield在干净和对抗两种设置下的卓越鲁棒性和可靠性。
尽管VAD取得了进展,但WSVAD的对抗鲁棒性在很大程度上仍未被探索。增强其鲁棒性面临重大挑战。首先,当前的WSVAD方法严重依赖预训练的特征提取器,如I3D[Carreira and Zisserman, 2017], C3D[Tran et al., 2015], Swin Transformer[Liu et al., 2021]和CLIP[Radford et al., 2021],这些提取器尽管具有强大的表示能力,但极易受到对抗攻击。其次,对抗训练(AT)——一种通过用对抗样本增强训练数据来提高模型鲁棒性的广泛使用的防御机制——在WSVAD中面临独特挑战。这主要是由于多示例学习(MIL)框架的固有约束,即在训练期间只有视频级标签可用,而在推理期间需要帧级预测[Jafarinia et al., 2024]。
在WSVAD中,通常采用基于MIL的损失函数,其中将聚合器函数(如最大池化)应用于帧级输出,以产生与可用标签匹配的视频级预测,从而能够使用交叉熵损失进行训练[Sultani et al., 2018]。在对抗训练期间,扰动被应用于整个视频。然而,只有被聚合器选择的特征(如最大值特征)会受到对抗性影响,因为梯度主要流经该特定组件。这种设计引入了一个关键漏洞。在训练期间,扰动仅应用于聚合器选择的特征(例如,最大值)。相比之下,在推理期间,攻击者不受此方式约束,可以操纵整个帧,在所有特征上产生更局部化和更有影响的扰动。训练中缺少帧级标注将对抗样本的生成限制在视频级监督上,导致较弱的扰动,降低了WSVAD模型对攻击的鲁棒性[Mirzaei et al., 2024a], [Chen et al., 2021]。我们在第4节中提供了这种现象的理论分析,展示了基于最大值的聚合如何忽略非最大帧上的扰动,使它们在推理期间暴露于攻击之下。
为了解决这些限制,我们提出了FrameShield,一种新颖的端到端对抗训练流程,旨在通过微调特征提取器来解决预训练模型的局限性。训练过程分为两个主要阶段。首先,我们使用一个简单而有效的WSVAD方法进行标准训练,生成作为伪标签的预测标签。在第二阶段,我们利用这些帧级伪标签进行对抗训练,制作更强的对抗样本以增强模型鲁棒性。然而,如表2所示,最先进的WSVAD方法在基准测试的异常片段上的定位性能仍然不理想,通常仅略优于随机检测。我们的方法在异常定位方面也面临类似困难,产生嘈杂的伪标签,导致假阳性和假阴性,特别是在异常视频中。相比之下,正常视频的所有帧都被一致地标记而没有错误。因此,嘈杂伪标签的存在使我们的方法容易受到对异常视频的对抗攻击[Dong et al., 2023]。
为了解决这一漏洞,我们提出了时空区域扭曲(SRD),一种创新的伪异常视频生成方法,旨在产生具有精确帧级标注的合成异常。SRD的工作原理是从正常视频中随机选择一个中间帧,利用Grad-CAM[Selvaraju et al., 2017]识别前景对象,然后对该区域内最大的连通组件执行多次严苛的增强。为了模拟移动异常在整个视频序列中的出现,我们通过定义一个随机弯曲的向量引入运动不规则性[Zhu and Newsam, 2019], [Yang et al., 2021],引导损坏区域在连续帧中的位移,并附加额外的严苛增强。该技术能够生成具有精确帧级标注的合成异常视频,无需额外监督,并增强了对抗训练。通过将这些精确标注的合成异常与从伪标签得出的真实异常分布的见解相结合,我们引入了我们具有对抗鲁棒性的WSVAD框架FrameShield。
贡献:我们引入了FrameShield,这是第一个专门设计用于增强WSVAD模型对抗对抗攻击鲁棒性的对抗训练流程。我们的方法在弱监督设置内采用帧级对抗训练,利用来自伪标签的真实异常分布,并通过时空区域扭曲(SRD)减轻假阳性和假阴性错误,以获得精确的帧级标注。我们从理论上证明了监督对抗训练相对于基于MIL的方法的优越性。FrameShield针对强大的攻击方法进行了评估,包括PGD-1000[Madry et al., 2017], AA[Croce and Hein, 2020]和A3[Liu et al., 2022]。实验结果,在成熟的基准测试中平均显示,在鲁棒性能的整体AUROC上提高了近53%,在异常片段上提高了68.5%,同时在标准设置上保持了有竞争力的性能。
2 Related Work
视频异常检测(VAD)在监控、公共安全和自动化监控中至关重要。传统的全监督方法由于异常事件的稀有性,需要耗费巨大的帧级标注。弱监督视频异常检测(WSVAD)通过仅使用视频级标签来解决这个问题,它利用多示例学习(MIL)将每个视频视为一个帧的集合,并假设异常存在于正样本视频中。早期的基于MIL的VAD方法面临着噪声标签和时序建模能力不足的挑战[Sultani et al., 2018]。后续的改进工作包括噪声抑制、时序建模(例如,MGFN [Chen et al., 2022])、双记忆单元(UR-DMU [Zhou et al., 2023])以及通过特征聚类和对比损失实现的无偏训练(UMIL [Lv et al., 2023])。最近,像CLIP这样的视觉-语言模型(VLMs)通过捕捉视觉和语义线索,增强了异常检测能力[Joo et al., 2023], [Wu et al., 2024], [Chen et al., 2023]。然而,WSVAD模型仍然容易受到对抗攻击,因为它们依赖于非鲁棒的预训练主干网络(如I3D、C3D、Swin Transformer、CLIP)[Schlarmann et al., 2024], [Chen et al., 2019], [Li et al., 2021]。帧级标注的缺乏进一步使对抗防御复杂化,使模型暴露在现实世界的威胁之下。如需更多信息和相关工作的详细讨论,请参阅附录M。
3 Preliminaries
弱监督视频异常检测(WSVAD):视频异常检测(VAD)是识别视频中不寻常或异常事件并确定它们在帧级别的时间位置的任务。在WSVAD设置中,训练期间只有视频级监督可用,指示视频是否包含异常,而不提供具体的帧级标签。在推理过程中,模型FΘF_\ThetaFΘ处理包含NNN帧的视频VVV,并为每帧iii生成异常分数Si(FΘ;V)S_i(F_\Theta;V)Si(FΘ;V)。如果某一帧的分数超过预定义阈值,则该帧被分类为异常;否则,它被认为是正常的。
针对视频异常检测器的对抗攻击:对抗攻击通常在分类任务的背景下进行研究,涉及故意修改带有相应标签yyy的输入样本xxx,以生成新样本x∗x^*x∗,通过最大化损失函数ℓ(x∗;y)\ell(x^*;y)ℓ(x∗;y)来增加模型的预测误差[Yuan et al., 2019], [Xu et al., 2019]。生成的输入x∗x^*x∗被称为对抗样本,而差异x∗−xx^* - xx∗−x被称为对抗扰动。为确保对抗样本在语义上与原始输入相似,扰动被约束为其lpl_plp范数不超过预定义阈值ϵ\epsilonϵ。形式上,对抗样本满足条件x∗=argmaxx′:∥x−x′∥p≤ϵℓ(x′;y)x^* = \arg\max_{x':\|x-x'\|_p\leq\epsilon} \ell(x';y)x∗=argmaxx′:∥x−x′∥p≤ϵℓ(x′;y)。制作对抗样本最常用和有效的技术之一是投影梯度下降(PGD)方法[Madry et al., 2017],它使用步长α\alphaα,沿着ℓ(x∗;y)\ell(x^*;y)ℓ(x∗;y)的梯度符号方向迭代更新输入。
在这项工作中,我们将对抗攻击范式适应到视频异常检测(VAD)领域,引入一种有针对性的、任务特定的攻击,该攻击基于单个帧的异常分数来操纵视频,而不是针对整体损失函数进行优化——WSVAD中的大多数现有方法依赖于基于MIL的损失。我们的目标是通过增加正常帧的异常分数和降低异常帧的分数来误导模型,我们通过实验证明这是一种更有效的攻击形式(表14)。攻击公式如下。从原始视频V0∗=VV^*_0 = VV0∗=V开始,我们使用以下规则迭代更新对抗视频:
Vt+1∗=Vt∗+Y⋅α⋅sign(∇VS(FΘ;Vt∗)), V^*_{t+1} = V^*_t + Y \cdot \alpha \cdot \text{sign}(\nabla_V S(F_\Theta;V^*_t)), Vt+1∗=Vt∗+Y⋅α⋅sign(∇VS(FΘ;Vt∗)),
其中S(FΘ;Vt∗)S(F_\Theta;V^*_t)S(FΘ;Vt∗)表示模型FΘF_\ThetaFΘ为视频Vt∗V^*_tVt∗的每一帧预测的异常分数,α\alphaα是步长。向量YYY定义为:对于正常帧Yi=+1Y_i = +1Yi=+1,对于异常帧Yi=−1Y_i = -1Yi=−1,其中iii是帧位置的索引。
4 Methods
理论动机。我们假设使用最大值作为多示例学习(MIL)聚合器会导致对实例或帧的攻击效果较弱。注意,通过将 x=(x1,...,xk)x = (x_1, ..., x_k)x=(x1,...,xk) 表示为 kkk 个视频帧,损失相对于输入 xxx 的梯度变为:
∇xl(max(f(x1),...,f(xk)),y)=l′(f,y)⋅∇xf(xj), \nabla_x l(\max(f(x_1), ..., f(x_k)), y) = l'(f, y) \cdot \nabla_x f(x_j), ∇xl(max(f(x1),...,f(xk)),y)=l′(f,y)⋅∇xf(xj),
其中 jjj 是导致最大值的帧的索引,即对于特定输入 xxx,j=argmaxif(xi)j = \arg\max_i f(x_i)j=argmaxif(xi)。这导致基于梯度的攻击仅应用于单个帧。一旦这种攻击用于训练,基础分类器 fff 将仅对帧的子集(即那些得分最高的帧)变得鲁棒。另一方面,可能存在其他帧 j′≠jj' \neq jj′=j,其中 f(xj′)f(x_{j'})f(xj′) 也很高,尽管略小于 f(xj)f(x_j)f(xj)。攻击不考虑这些帧,如果 xj′x_{j'}xj′ 不遵循与 xjx_jxj 相同的分布,那么基于此攻击进行对抗训练的基础分类器将无法在 xj′x_{j'}xj′ 上泛化鲁棒性。可以使用最大值的其他软版本,例如对数求和指数(LSE)来缓解此问题。然而,我们在表3中的实验表明,尽管LSE优于最大值函数,但在对抗攻击下,它仍然无法将干净训练模型的性能降至零。我们注意到,此类运算符降低了模型对单个/少量帧的敏感性。
基于这些原因,我们倾向于应用于每一帧但不改变最大值运算符的训练攻击,以不损害模型对异常值的敏感性。这可以通过直接攻击所有 iii 的 f(xi)f(x_i)f(xi) 来实现。这里,攻击基于以下设计:
L:=max∥δi∥∞≤ϵl(f(xi+δi),f(xi)), L := \max_{\|\delta_i\|_\infty \leq \epsilon} l(f(x_i + \delta_i), f(x_i)), L:=∥δi∥∞≤ϵmaxl(f(xi+δi),f(xi)),
即,使模型对于给定输入视频中的每一帧都不改变其原始预测。这里,我们将 f(xi)f(x_i)f(xi) 视为伪标签,并基于此设计攻击。公式1中的损失与所谓的TRADES方法[Zhang et al., 2019a]中的“边界误差”非常相似,而非“自然误差”。此类攻击可以作为鲁棒性的正则化。在这里,可以旨在优化公式1中对抗损失所增加的标准误差,以在标准误差和对抗误差之间实现更好的权衡。事实上,该损失已被证明是鲁棒风险与最优标准风险之间差异的一个几乎尖锐的上界[Zhang et al., 2019a]:
Rrob(f)−Rnat⋆≤ψ−1(Rl(f)−Rl⋆)+E(L), R_{rob}(f) - R^\star_{nat} \leq \psi^{-1}(R_l(f) - R^\star_l) + E(L), Rrob(f)−Rnat⋆≤ψ−1(Rl(f)−Rl⋆)+E(L),
其中 RrobR_{rob}Rrob 和 Rnat⋆R^\star_{nat}Rnat⋆ 分别表示鲁棒风险和最优标准风险。此外,ψ\psiψ 是一个非递减函数,RlR_lRl 表示相对于损失函数 lll 的风险,而 LLL 在公式1中定义。因此,在许多实例缺少真实标签的弱监督场景中,这种损失可能是一个绝佳的选择。
概述。当前的弱监督视频异常检测(WSVAD)方法表现出对对抗攻击的显著脆弱性。我们在表3和第6节中基于MIL损失函数的实验和分析强调了帧级标签对于增强对抗鲁棒性的必要性。为了应对这一挑战,我们引入了FrameShield,一种新颖的方法,它通过利用弱标记的真实异常数据生成伪标签和精确标记的块级伪异常来增强模型的韧性。FrameShield分两个主要阶段运行:首先,WSVAD模型使用基于MIL的损失函数进行标准训练,使其能够有效学习异常模式。然后,利用学到的知识为训练数据的异常子集生成伪标签。在第二阶段,调整后的WSVAD模型使用伪标签和伪异常进行对抗训练,在帧级别提供更细粒度的监督,并提高其对对抗操作的鲁棒性。以下部分详细介绍了FrameShield训练流程中每个阶段的分解。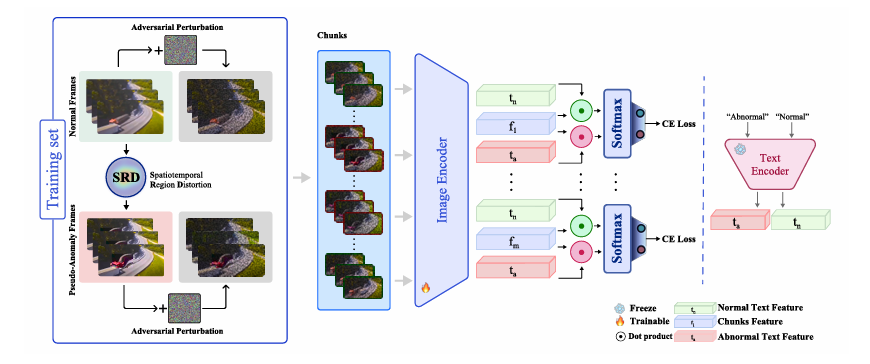
图2:FrameShield框架概述:(1) 弱监督视频异常检测(WSVAD)训练集的构建使用了正常数据的帧级标签和弱标记真实异常数据的帧级伪标签。此外,时空区域扭曲(SRD)模块生成具有精确帧级标注的伪异常样本,通过对抗性扰动进一步扩充训练集。(2) 使用两个预定义的提示词,“normal”和“anomaly”,从冻结的文本编码器中提取文本嵌入。(3) 训练视频被分割成块,并由基于X-Clip的编码器处理。计算每个块的特征表示与文本提示嵌入之间的点积,以获得正常性和异常性分数,通过块级交叉熵损失优化网络。
4.1 First Phase:Prompt MIL Training
我们提出的弱监督视频异常检测(WSVAD)方法,即PromptMIL,将每个视频分割成mmm个块,记作viv_ivi,其中i∈{1,2,...,m}i \in \{1, 2, ..., m\}i∈{1,2,...,m}。我们采用X-Clip [Ma et al., 2022]作为特征提取器,表示为FΘF_\ThetaFΘ。每个视频块viv_ivi通过FΘF_\ThetaFΘ处理,生成相应的特征向量fif_ifi。
此外,我们使用X-Clip文本编码器为两个特定的文本提示词:"Normal"和"Abnormal"提取特征向量。对于每个视频块,我们计算其特征向量fif_ifi与这两个文本提示词特征向量的点积。然后,我们应用softmax函数来产生一个概率分布,该分布表示该块为正常或异常的可能性:
Si(FΘ;V),(1−Si(FΘ;V))=softmax(fi⋅ta,fi⋅tn)(2) S_i(F_\Theta; V), (1 - S_i(F_\Theta; V)) = \text{softmax}(f_i \cdot t_a, f_i \cdot t_n) \quad (2) Si(FΘ;V),(1−Si(FΘ;V))=softmax(fi⋅ta,fi⋅tn)(2)
其中,FΘF_\ThetaFΘ代表我们的FrameShield模型,tnt_ntn和tat_ata分别是"Normal"和"Abnormal"的文本特征向量。这里,Si(FΘ;V)S_i(F_\Theta; V)Si(FΘ;V)表示第iii个块的预测异常分数。在处理完所有块后,我们获得每个块的正常性和异常性概率。然后,我们使用多示例学习(MIL)最大聚合器对所有块的异常分数进行聚合,该聚合器从所有块中选择最大的异常分数。此聚合步骤之后是二元交叉熵损失计算,该损失直接应用于最大异常分数,而不是对所有块的分数求和:
L=BCE(max(S1(FΘ;V),S2(FΘ;V),...,Sm(FΘ;V)),y)(3) L = \text{BCE}(\max(S_1(F_\Theta; V), S_2(F_\Theta; V), ..., S_m(F_\Theta; V)), y) \quad (3) L=BCE(max(S1(FΘ;V),S2(FΘ;V),...,Sm(FΘ;V)),y)(3)
其中,mmm是块的总数,yyy是视频的真实标签。这种表述确保模型基于块中最高的异常分数进行优化,这对于识别视频中最关键的异常片段特别有效。
推理。在推理过程中,视频同样被分割成mmm个块,并通过特征提取器FΘF_\ThetaFΘ处理。对于每个块,我们执行与文本提示词的点积操作,并应用softmax来获得正常性和异常性分数。异常分数大于τ=0.5\tau = 0.5τ=0.5的块被标记为异常;其他为正常。帧级预测通过将每个块的分数复制到其包含的所有帧来获得。关于τ\tauτ的消融研究见附录D。
伪标签生成。一旦PromptMIL模型训练完成,我们利用它为训练集中异常视频的每个块生成伪标签。值得注意的是,正常视频中的帧本质上被标记为正常,因此不需要伪标签。在此阶段,我们的目标是为训练数据打标签——这个任务本质上不那么具有挑战性,因为模型已经在其上进行了训练。关于伪标签生成的替代方法和我们的PromptMIL模型的性能评估的详细信息可以在附录B中找到。
4.2 Second Phase: Adversarial Training
在此训练阶段,我们通过利用正常视频的精确块级标签、真实异常块的生成伪标签,以及我们提出的时空区域扭曲(SRD)方法生成的伪异常的精确块级标注,在一个构建的全监督视频异常检测(VAD)模型上进行对抗训练。这种方法旨在减轻伪标签数据中的标签噪声,从而增强模型的鲁棒性和准确性。以下各节将全面分解我们的伪异常生成过程、详细的训练程序、所采用的损失函数以及对抗训练策略的具体细节。
时空区域扭曲(SRD)。基于我们在表5中的观察和附录F中提出的分析,我们发现仅依赖生成的伪标签进行对抗训练是无效的,因为存在假阳性和假阴性,这阻碍了正确的优化。为解决此问题,我们提出了一种新颖而直接的伪异常生成方法,称为时空区域扭曲(SRD),旨在提供具有精确帧级标注的异常,并纠正伪标签视频中的错误。
我们认识到,视频领域中有效的伪异常应满足三个关键标准。首先,扭曲的数据应具有很高的可能性被识别为异常。其次,生成的数据应接近正常样本的分布,共享相似的语义和风格属性。这与现有的对抗鲁棒性文献一致,该文献强调了接近分布的决策边界样本对于增强模型鲁棒性的好处[Xing et al., 2022]。最后,将时间特征融入异常至关重要,以反映随时间发生的意外变化,如突然的速度变化、突然的运动中断或破坏正常活动流程的不规则事件序列。
基于我们对视频领域伪异常生成的见解,我们提出了时空区域扭曲(SRD)。SRD首先从正常视频中随机选择一个连续的帧序列并提取初始帧。为了识别对象区域,我们使用预训练的ResNet18[He et al., 2016], [Nafez et al., 2025]模型应用Grad-CAM,有效地突出最显著的前景区域。然后对得到的显著性图进行阈值处理以分离最突出的特征,之后计算最大的连通分量。在该区域周围拟合一个边界矩形(为泛化引入一些随机性),作为二值掩码的基础。最后,我们应用kkk次严苛的增强,这些增强是从预定义的NNN种已知会破坏语义完整性的激进变换中随机选择的,这得到了先前研究的支持[Sinha et al., 2021], [DeVries and Taylor, 2017], [Ghiasi et al., 2021], [Zhang et al., 2018], [Mirzaei et al., 2024b, 2025]。这些增强仅应用于掩码区域,最大化转换视频被感知为异常的可能性。更多细节请参阅附录A。
为了将时间特征引入异常,SRD定义了一个从矩形中心出发并向随机方向延伸的随机弯曲向量。然后复制掩码区域,用一组新的增强进行扭曲,并根据向量的轨迹定位在后续帧中。这种运动在帧序列中逐步推进,每一步覆盖的距离与向量的总长度除以序列中的帧数成正比。这种同步运动有效地模拟了整个视频中的时空异常传播。图3展示了将SRD应用于视频序列的说明性示例。
图3:时空区域扭曲(SRD)的可视化:一种用于精确帧级标注的合成异常生成方法,该方法对Grad-CAM识别的前景区域应用严苛增强,并通过随机弯曲向量在帧间模拟运动不规则性。
训练过程。在此阶段,我们利用正常视频、真实异常视频和SRD生成的伪异常视频的帧级标注。与依赖视频级损失函数的传统基于MIL的训练不同,我们转向全监督学习范式。这使得模型能够通过直接优化块级预测来学习更细粒度的表示。如图2所示,损失函数独立地为每个块计算,允许细粒度的监督:
Lchunk-wise(V,Y)=∑i=1mBCE(Si(FΘ;V),yi)(4) L_{\text{chunk-wise}}(V, Y) = \sum_{i=1}^{m} \text{BCE}(S_i(F_\Theta; V), y_i) \quad (4) Lchunk-wise(V,Y)=i=1∑mBCE(Si(FΘ;V),yi)(4)
其中mmm是块的总数,yiy_iyi是其对应的真实标签。此外,YYY表示完整的块级标签集。这种块级交叉熵计算确保模型以更细的粒度进行更新。此外,这种监督策略允许我们在训练期间对输入视频应用强对抗扰动,有效地构建一个更鲁棒的VAD模型以抵御对抗攻击。
WSVAD的对抗训练。给定输入视频样本VVV,通过引入通过PGD-10攻击生成的扰动δ∗\delta^*δ∗来制作对抗版本VadvV_{adv}Vadv。该扰动受l∞l_\inftyl∞范数约束,ϵ=0.5255\epsilon = \frac{0.5}{255}ϵ=2550.5,并根据我们的块级损失函数进行优化:
δ∗=argmax∥δ∥∞≤ϵLchunk-wise(V+δ,Y),Vadv=V+δ∗(5) \delta^* = \arg\max_{\|\delta\|_\infty \leq \epsilon} L_{\text{chunk-wise}}(V + \delta, Y), \quad V_{adv} = V + \delta^* \quad (5) δ∗=arg∥δ∥∞≤ϵmaxLchunk-wise(V+δ,Y),Vadv=V+δ∗(5)
我们已经为异常和伪异常预定义了块级标签,表示为YYY,在训练期间使用。对抗训练遵循最小-最大优化策略,旨在调整模型参数Θ\ThetaΘ以最小化来自训练批次BBB的对抗扰动数据样本的期望损失:
minΘE(V,Y)∈B[max∥δ∥∞≤ϵLchunk-wise(V+δ,Y)].(6) \min_{\Theta} \mathbb{E}_{(V,Y) \in B} \left[ \max_{\|\delta\|_\infty \leq \epsilon} L_{\text{chunk-wise}}(V + \delta, Y) \right]. \quad (6) ΘminE(V,Y)∈B[∥δ∥∞≤ϵmaxLchunk-wise(V+δ,Y)].(6)
攻击和训练的ϵ\epsilonϵ值分析。在视频异常检测模型中,输入通常由高维视频序列组成,通常包含至少100帧,每帧分辨率为224×224224 \times 224224×224像素。由于这些输入的规模较大,对抗扰动往往很显著,这可能会破坏对抗训练的稳定性[Sharma and Chen, 2018]。为缓解此问题,像[Shaeiri et al., 2020]这样的一些方法探索了逐渐增加ϵ\epsilonϵ值的策略。该策略的性能详见附录E。在我们的实验中,我们采用ϵ=0.5255\epsilon = \frac{0.5}{255}ϵ=2550.5作为训练和评估的默认设置。为了验证这一选择,我们在上海数据集上进行了实验,该数据集为训练集提供了帧级标注。最初,我们在全监督数据上训练我们的框架,代表了最优场景。在此设置下,模型在整体和特定异常指标上都达到了近乎完美的性能。然而,当我们使用更高的ϵ\epsilonϵ值(2.0255\frac{2.0}{255}2552.0和1.0255\frac{1.0}{255}2551.0)训练模型时,即使没有对抗攻击,模型的标准检测性能也下降到接近随机水平。相比之下,当ϵ=0.5255\epsilon = \frac{0.5}{255}ϵ=2550.5时,模型保持了稳定的训练,并展现出对对抗攻击的鲁棒性能。该实验的更多细节可在表10中找到。
5 Experiments
为了证明FrameShield的有效性,我们在VAD领域的多个知名基准数据集上进行了广泛的实验。我们将我们的方法与多种最先进(SOTA)方法进行了比较,报告了标准设置和对抗攻击场景下的AUROC指标。这些基准数据集完整测试集的结果(记为AUCO)呈现在表1中,而针对测试集中异常部分的性能指标(记为AUCA,代表更具挑战性的评估)则在表2中详述。这些表格突显了现有SOTA方法的不足,并强调了我们提出方法的增强鲁棒性和有效性。与近期多模态大语言模型(LLM)方法的详细比较在附录K中提供。在附录L中,我们进一步在黑盒攻击设置下评估了FrameShield,附录N则展示了与基线VAD方法的对抗训练版本的比较,以确保评估的公平性。总体而言,所有实验一致地证实了FrameShield的鲁棒性和整体优越性。
结果分析。如表1和表2所示,尽管先前的SOTA方法如UMIL、RTFM和MGFN在干净数据上取得了强劲的结果,但在对抗条件下经历了显著的性能下降。这些不足促使我们开发了所提出的解决方案FrameShield。平均而言,FrameShield在各种数据集上将鲁棒检测性能提高了高达71.0%。正如先前研究中所强调的,为了鲁棒性的大幅提升,干净性能的轻微下降通常被认为是可接受的权衡(更多讨论见附录O)。
实现细节与数据集。对于训练,我们使用的学习率为8×10−68 \times 10^{-6}8×10−6,块大小为16帧。模型使用AdamW优化器训练了40个周期,该优化器有效地融入了权重衰减。为了安排学习率,我们应用了余弦调度器,它按照余弦衰减模式逐步降低学习率。这种方法促进了更平滑的收敛和更好的泛化能力。我们在知名基准数据集上评估我们的方法:MSAD [Zhu et al., 2024]、UCF-Crime [Sultani et al., 2018]、ShanghaiTech [Liu et al., 2018]、TAD [Lv et al., 2021]和UCSD Ped2 [Mahadevan et al., 2010];更多细节在附录A中提供。在对抗场景中,我们使用l∞l_\inftyl∞ PGD-1000攻击评估每种方法,扰动幅度为ϵ=0.5255\epsilon = \frac{0.5}{255}ϵ=2550.5。在l2l_2l2范数下的评估在附录G中提供。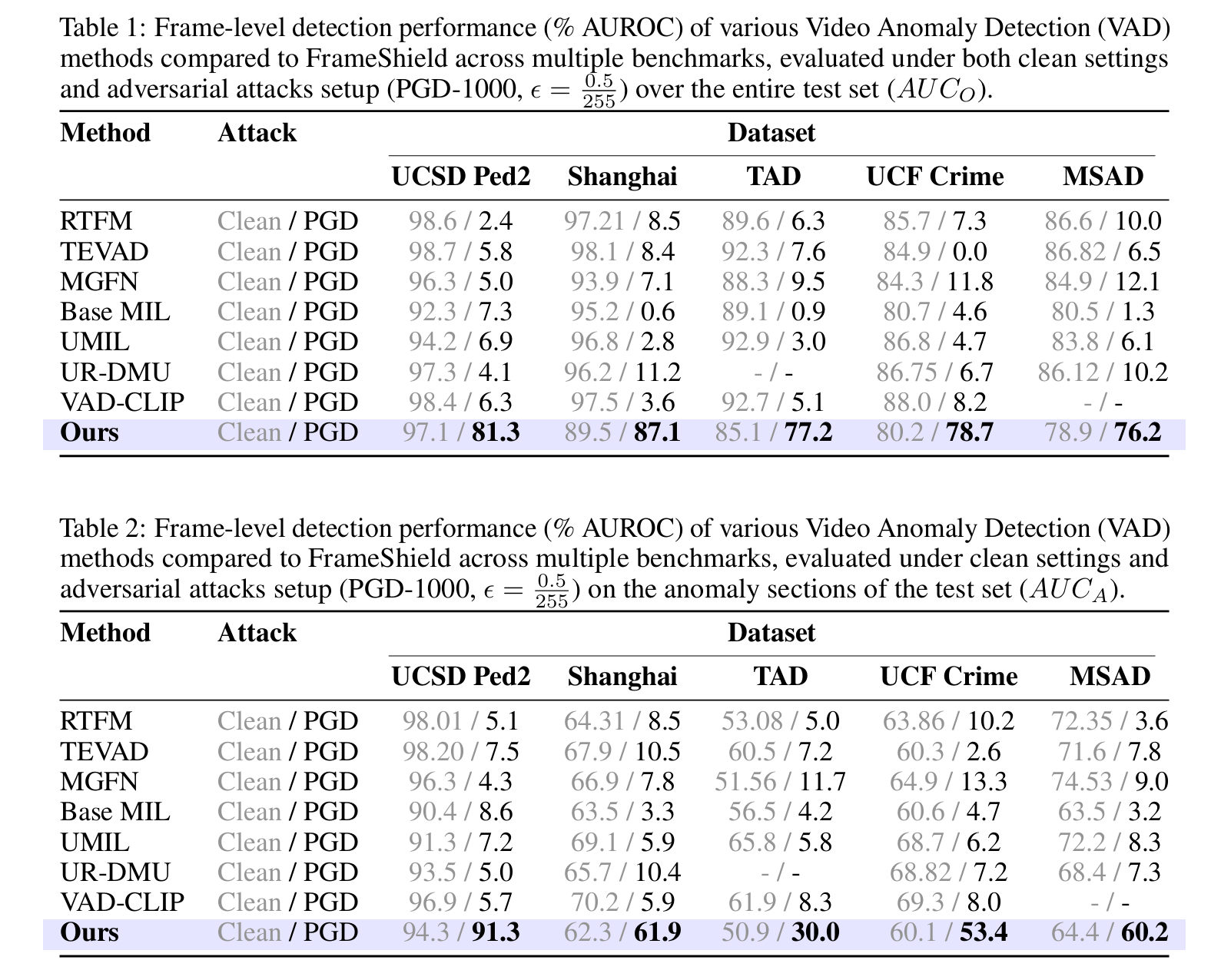
6 Ablation Study
在本节中,我们对方法的组件进行了详细分析,并评估了它们的有效性。
伪监督组件的消融研究。为了评估我们提出的伪标签生成器(PromptMIL)和伪异常生成器(SRD)的有效性,我们进行了一项消融研究,如表5所示。在该实验中,我们在三种配置下训练和评估FrameShield:仅使用伪标签监督、仅使用伪异常生成,以及使用我们默认的、结合两者的设置。结果表明,将真实异常信息与精确生成的伪异常标签相结合,显著增强了模型的对抗鲁棒性。
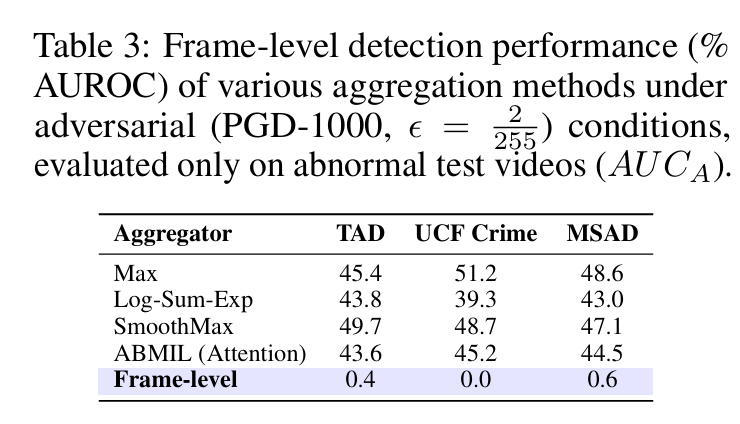
视频级攻击与帧级攻击。在VAD领域,大多数模型在视频级别运行,利用各种聚合器结合基于MIL的损失函数进行视频级监督。如表4所示,我们在标准条件下训练我们的PromptMIL模型,不进行对抗训练,采用不同的聚合器,如Max、LSE、SmoothMax和ABMIL。训练后,我们对这个干净模型的最终视频级分数应用对抗攻击。我们的实验表明,即使是最有效的基于梯度流的聚合器也无法将模型的性能降低到AUC为零的程度。相比之下,我们的帧级对抗攻击成功地完全欺骗了模型,展示了我们提出方法的卓越有效性和鲁棒性。这凸显了转向帧级对抗训练的战略优势,能够实现更强、更有影响力的对抗扰动。
高级攻击。我们在模型的训练和评估阶段都采用了PGD攻击[Madry et al., 2017]。为了进一步证明我们提出的方法在各种对抗场景下的灵活性和韧性,我们还在表4中评估了它对几种高级攻击策略的有效性,包括AutoAttack[Croce and Hein, 2020]和A3(对抗攻击自动化)[Liu et al., 2022]。我们在附录I中提供了在VAD背景下针对这些攻击类型的适配方法的全面细节。值得注意的是,训练过程保持直接,始终使用标准的PGD-10配置以保持简单性和实用性。
额外的消融研究。我们进行了进一步的实验来评估SDR组件的影响,具体分析了Grad-CAM和Motion的效果,详见附录H。此外,我们对使用基于MIL的对抗样本生成训练FrameShield模型进行了消融研究,这在附录J中讨论。此外,我们研究了使用替代的WSVAD方法作为伪标签生成器,结果也在附录C中呈现。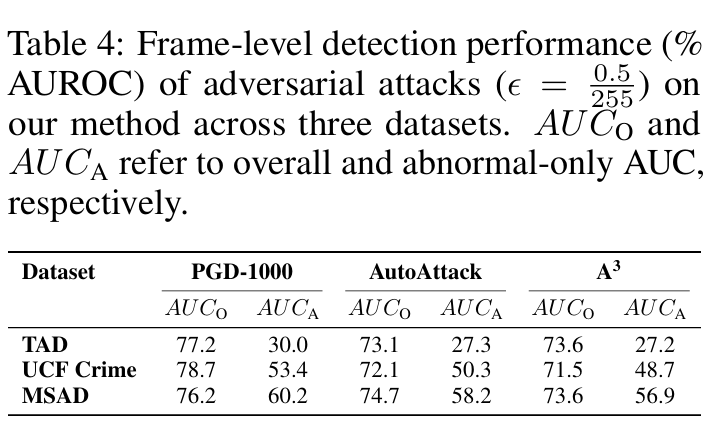

7 Conclusion
我们提出了FrameShield,一种用于增强弱监督视频异常检测(WSVAD)对抗鲁棒性的新颖方法。我们的方法采用帧级对抗训练,利用从弱标记数据生成的块级伪标签,并引入时空区域扭曲(SRD)以实现精确的帧级异常标注。我们展示了最先进的VAD模型在对抗攻击下的脆弱性,并通过FrameShield弥补了这一差距,为现实世界场景中的鲁棒视频异常检测建立了更强的防御机制。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)