Distilling Privileged Knowledge for Anomalous Event Detection From Weakly Labeled Videos
弱监督视频异常检测(WS-VAD)旨在仅凭借视频级别的二元标签,识别长未修剪视频中涉及异常事件的片段。现有WS-VAD方法中的一种典型范式是采用多种模态作为输入,例如RGB、光流和音频,因为它们可以提供足够的判别线索,能够适应多样、复杂的现实场景。然而,这种流程高度依赖多种模态的可用性,并且在处理长序列时计算成本高昂且存储需求大,这限制了其在某些应用中的使用。

中文标题:从弱标记视频中蒸馏特权知识用于异常事件检测
类型:VAD
发布于:IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS(CCF-B)
源码地址:无
目录
A. Unsupervised Video Anomaly Detection
C. Activity Analysis and Recognition
B. Multimodal Interaction-Based Teacher Network
C. Training Student Network by Privileged KD Framework
Abstract
弱监督视频异常检测(WS-VAD)旨在仅凭借视频级别的二元标签,识别长未修剪视频中涉及异常事件的片段。现有WS-VAD方法中的一种典型范式是采用多种模态作为输入,例如RGB、光流和音频,因为它们可以提供足够的判别线索,能够适应多样、复杂的现实场景。然而,这种流程高度依赖多种模态的可用性,并且在处理长序列时计算成本高昂且存储需求大,这限制了其在某些应用中的使用。为了解决这一困境,我们提出了一种专门用于WS-VAD任务的特权知识蒸馏(KD)框架,该框架可以保留利用额外模态的优势,同时避免在推理阶段使用多模态数据。我们认为,特权KD框架的性能主要取决于两个因素:1)多模态教师网络的有效性;2)有用信息传递的完整性。为了获得可靠的教师网络,我们提出了一种跨模态交互学习策略和一种异常-正常判别损失,前者旨在学习特定任务的跨模态特征,后者则鼓励异常和正常表示的可分离性。此外,我们设计了表示级和逻辑(logits)级的蒸馏损失函数,这些函数迫使单模态学生网络以从片段到视频的方式,从训练良好的多模态教师网络中提取丰富的特权知识。在三个公开基准数据集上的大量实验结果表明,所提出的特权KD框架可以训练出一个轻量级且有效的检测器,用于在视频级注释的监督下定位异常事件。
I. INTRODUCTION
视频异常检测(Video Anomaly Detection,VAD)在学术界和工业界都引起了广泛关注,这归因于其在现实世界中的广泛应用[1], [2], [3], [4],如智能监控系统、自动驾驶以及电影内容审查等领域。VAD的目标是在未经剪辑的长视频中定位异常事件(例如暴力、抢劫和盗窃等)发生的时间区间。在以往的研究中,无监督的VAD方法[5], [6], [7], [8], [9]得到了广泛探索,这类方法仅使用正常样本训练模型。其基于的假设是,训练好的模型能够很好地编码正常模式,在推理时,那些具有高重建误差的独特编码模式将被检测并识别为异常。然而,由于在训练阶段缺乏对异常样本的了解,无监督VAD方法的性能仍然有限。最近,弱监督VAD(Weakly Supervised VAD,WS-VAD)[10], [11], [12], [13]方法被提出,这类方法利用视频级标签来指示每个训练样本是否包含异常事件。与无监督VAD方法相比,WS-VAD模型只需付出相对较少的标注工作量,其检测性能就有了显著提升[14]。
受最近发布的大规模视听XD-Violence数据集[15]的启发,处理WS-VAD任务的一种典型设置是利用多模态输入,通过探索不同模态的互补性来应对现实场景中的各种干扰因素。然而,这种方法高度依赖多种模态的可用性,这在一些实际应用中可能并不现实,例如传统的监控摄像头。此外,处理各种模态通常计算成本高昂且对存储要求较高,尤其是在处理长未修剪视频时。这些问题提出了一个有趣但具有挑战性的问题,即如何训练一个模型,既能保持探索多模态信息的优势,又能避免在推理时处理繁琐的多模态数据。一种潜在的方法是采用跨模态知识蒸馏(KD)框架[16], [17], [18],该框架已证明在保留特权模态的有用信息方面是有效的,且无需在推理阶段对其进行处理。然而,以前大多数视频分析工作都致力于短剪辑视频的分类[19], [20], [21], [22],这些方法并不适用于在长未修剪视频中定位异常实例。尽管Dai等人[23]提出了一种用于未修剪视频动作检测的跨模态KD框架,但该方法是基于全监督设置设计的,训练时需要密集的帧级标签。因此,它不能直接推广到弱监督视频异常检测(WS-VAD)任务中,因为视频级标签与帧级注释相比是一种更弱的监督信号。在这项工作中,我们提出了一种面向WS-VAD任务的特权知识蒸馏(KD)框架,主要从两个方面进行考虑:一方面是利用多模态输入来训练一个可靠的教师网络;另一方面是设计多层次的损失函数,迫使学生网络从教师网络中提取丰富的特权知识(见图1)。
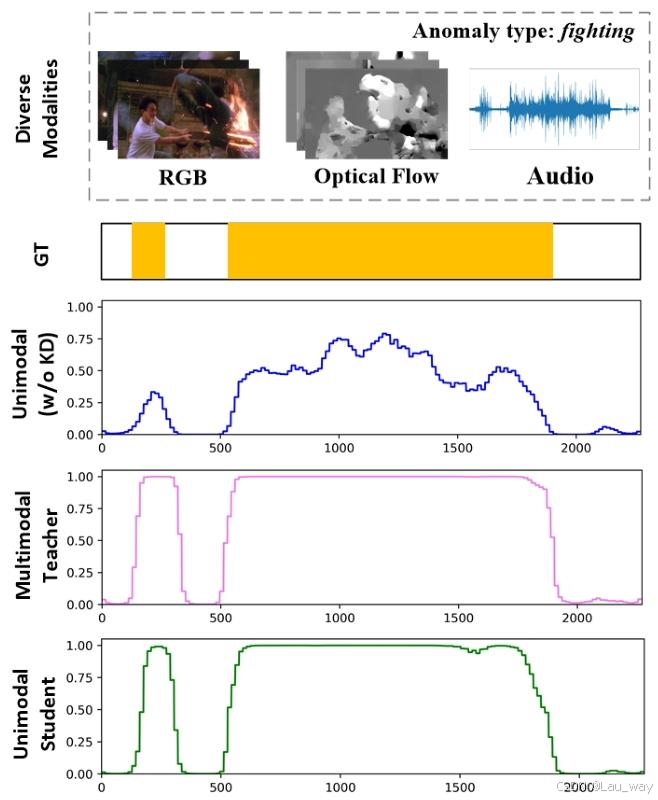
图1. 我们提出的特权知识蒸馏(KD)策略对弱监督视频异常检测(WS-VAD)任务的影响。普通单模态基线模型在检测异常实例(例如 “打斗” 事件)时信心不足,而我们提出的单模态学生网络的性能与探索多种模态的教师网络相当。
现有的弱监督视频异常检测(WS-VAD)方法通常将不同模态的特征连接起来,并采用多实例学习(MIL)[24]原理来训练一个分类器,以识别异常片段[15,25]。这种方法本质上存在两个局限性。第一,多模态特征通常是从在一些大规模的修剪过的动作数据集(如Kinetics-400[26])上预训练的编码器中提取的。因此,通过简单的连接来融合这些特征,不可避免地会为该任务引入无关和冗余的信息。第二,由于视频级别的监督信号较弱,仅使用MIL原理很难扩大异常片段和正常片段得分之间的差距,因为无法保证异常和正常表示之间的可分离性。由于教师网络的性能会影响特权知识转移的有效性,我们提出通过解决上述两个问题来训练一个强大的多模态教师模型。第一,为了学习特定任务的表示,我们提出了一种跨模态交互学习策略,旨在通过突出不同模态中有区分力的时间步和通道,动态地重新校准原始的序列特征。第二,为了促进异常和正常表示的可分离性,我们提出了一种基于自上而下注意力机制的异常-正常判别(AND)损失。将这种损失与传统的MIL原理相结合,可以形成一个闭环学习准则,有助于网络在弱监督设置下区分异常片段和正常片段。
在训练好的多模态教师网络基础上,我们需要考虑的另一个问题是如何将尽可能多的有用特权知识转移到学生网络中。我们认为,一个强大的教师网络可以在特征表示和逻辑(logits)层面提供丰富的指导。因此,我们设计了专门针对WS-VAD任务的多层次蒸馏损失函数,用于训练仅以单模态作为输入,但能实现与多模态教师网络相媲美的检测性能的学生网络。 首先,我们设计了两个表示级蒸馏损失项,用于学习边界感知的片段级特征和整体异常-正常嵌入。前者在教师模型和学生模型之间传递一对一的局部特征,重点关注异常实例的边界相关片段;而后者则有助于在视频层面模仿异常和正常嵌入的特征表示。因此,整合这两个损失将迫使学生网络学习一个与教师网络一样紧凑且具有判别力的特征空间。 其次,从片段级和视频级两个角度设计了逻辑(logits)级蒸馏损失函数。一方面,由于在弱监督训练中没有提供片段级标签,教师网络预测的异常分数可以作为伪标签,将片段级的逻辑(logits)知识转移到学生网络中。另一方面,视频级的逻辑(logits)蒸馏是通过采用一种广义的面向分类的蒸馏损失来实现的,该损失同时利用了硬标签(即真实标注)和软标签(即教师网络预测的逻辑(logits))。
本文的主要贡献总结如下。
第一,我们提出了一种跨模态交互学习策略,用于过滤掉从预训练编码器中提取的特征所带来的与任务无关的冗余信息。此外,我们还提出了一种基于自上而下注意力机制的异常-正常判别(AND)损失,以确保异常和正常表示的可分离性。这两个部分共同构成了一个有效的多模态教师网络,用于处理弱监督视频异常检测(WS-VAD)任务。
第二,我们设计了多种蒸馏损失函数,以片段到视频的方式将足够的表示级和逻辑(logits)级特权知识转移到单模态学生网络中。
第三,在三个公开基准数据集上进行的大量实验结果和消融研究验证了所提出的专门用于WS-VAD任务的特权知识蒸馏(KD)框架的有效性。据我们所知,这是首次探索在弱监督设置下,利用跨模态知识蒸馏方法检测未修剪视频中异常事件的工作。
II. RELATED WORK
A. Unsupervised Video Anomaly Detection
无监督视频异常检测(U-VAD)方法在训练阶段仅使用正常样本,并在推理过程中将突变的编码模式检测为异常。近年来,通过充分挖掘卷积神经网络(CNNs)提供的强大特征表示能力,出现了两种主流的基于深度学习的U-VAD方法,即基于重建的方法和基于预测的方法。在基于重建的U-VAD方法中,自动编码器(AEs)被广泛用于重建训练样本,例如卷积自动编码器(Conv-AE)[27]和卷积长短期记忆自动编码器(ConvLSTM-AE)[28]。这些基于AE的方法基于这样一个假设,即经过正常样本训练的模型很难重建异常样本。由于这一假设并非总是成立,Gong等人[5]为自动编码器增加了一个记忆模块,用于存储学习到的正常事件原型。为了减轻背景干扰,Georgescu等人[2]提出了以对象为中心的自动编码器,并利用对抗学习策略生成伪异常样本。基于预测的U-VAD方法通过将前一帧作为输入来学习预测未来帧,并将预测误差较高的区域识别为异常[29]。此外,基于变分自动编码器的卷积长短期记忆网络(ConvLSTM)[30]被进一步用于探索时间动态以进行未来帧预测。最近,有人尝试将这两种范式结合起来,以获得一个混合框架[31]。Liu等人[7]利用条件变分自动编码器对重建流和预测帧之间的潜在相关性进行建模。与这些U-VAD方法不同,本文主要研究弱监督视频异常检测(WS-VAD)任务,旨在以可承受的标注成本提高异常检测性能。
B. Weakly Supervised VAD
弱监督设置是视频异常检测(VAD)任务的一种折衷选择,因为与在全监督设置中使用密集的帧级标签相比,它所需的标注工作量和成本更少,并且能取得比无监督设置更好的性能。当前的弱监督视频异常检测(WS-VAD)方法主要可分为两类。第一类是基于编码器的方法,这类方法同时训练特征编码器和分类器。Zhong等人[32]将WS-VAD任务视为一个带有噪声标签的二分类问题,并采用图卷积网络(GCN)[33]通过迭代训练来清除标签噪声。Zhu和Newsam[34]联合训练了一个运动感知特征编码器和一个注意力增强分类器,以探索用于视频异常检测的时间上下文信息。Feng等人[11]提出了一种基于注意力的自引导编码器来学习特定任务的表示,并生成片段级伪标签来指导网络优化。然而,由于弱监督设置仅提供视频级标签,所以需要一次性处理整个视频。因此,同时训练特征编码器和分类器通常会给WS-VAD任务带来沉重的计算负担,尤其是在处理长视频时。第二类是与编码器无关的方法,这类方法利用预训练的编码器提取序列特征,仅训练用于检测异常片段的分类器。Sultani等人[10]收集了一个大规模的视频异常检测基准数据集UCF-Crime,该数据集仅包含视频级标签,并提出了一种深度排序模型来定位异常事件。Chang等人[25]提出了一个对比注意力模块,以缓解WS-VAD任务中异常样本和正常样本之间的不平衡问题。Wu和Liu[13]利用长期时间结构并改进了不同类别之间的特征区分度,以提升异常检测性能。尽管如此,这些编码器通常是在一些大规模的修剪过的视频数据集上进行预训练的,与用于WS-VAD任务的长未修剪视频相比存在领域差距。因此,直接使用这些编码器提取的特征很可能会引入与任务无关的冗余信息。考虑到实际应用所需的计算效率,我们的方法是基于与编码器无关的流程构建的。不过,我们并没有直接使用原始特征来训练分类器,而是充分利用不同模态的互补性,提出了一种跨模态交互学习策略,通过动态突出有区分力的时间步和通道来优化原始序列特征。
C. Activity Analysis and Recognition
异常事件检测与活动分析和识别密切相关,因为它们都旨在理解视频中以人类为中心的行为。在早期,大多数关于人类活动分析的研究致力于识别剪辑视频中的活动。在深度学习时代,有两种主流的活动识别方法。
1)三维卷积神经网络(3 - D CNNs)[35]:由于视频由一系列连续的帧组成,三维卷积是一种直观的同时编码空间和时间线索的方法。为了提高计算效率,人们进一步提出了几种变体,将三维卷积核分解为二维空间核和一维时间核,例如R(2 + 1)D [36]和S3D [37]。
2)双流架构:Simonyan和Zisserman[38]首次采用两个并行的二维卷积神经网络,分别从RGB和光流模态中捕捉外观和运动模式。
时序片段网络(TSN)[39]进一步将稀疏片段采样方案集成到双流架构中,以涵盖整个视频的活动语义。随后,一些方法借鉴了双流架构的基本思想,设计了多分支框架来学习用于活动识别的时空表示,例如ARTNet[40]和SlowFastNet[41]。受这些强大的视频分类骨干网络的启发,我们还利用预训练的膨胀三维(I3D)[42]网络来提取每个片段的视觉特征,并利用原始光流图像为我们的多模态教师网络提供运动模式。
近来,由于未修剪视频中的活动分析具有广泛的应用,它受到了越来越多的关注。时间活动定位(Temporal Activity Localization,TAL)[43]旨在检测未修剪视频中每个活动实例的开始和结束时间戳,并识别其类别,这一领域已得到广泛研究。为了减轻在全监督设置下对成本高昂的帧级注释的依赖,仅使用视频级标签的弱监督TAL(WS-TAL)方法应运而生。Wang等人[44]提出了UntrimmedNets,将分类模块和选择模块集成到双流TSN网络中,以处理WS-TAL任务。W-TALC[45]模型引入了共活动相似性损失,用于在弱监督设置下对属于同一类别的片段表示进行聚类。实际上,大多数关于WS-VAD和WS-TAL任务的研究都采用了基本的多实例学习(MIL)流程,该流程弥合了片段级预测和视频级注释之间的差距。此外,我们通过引入专门针对WS-VAD任务的异常-正常判别(AND)损失,改进了传统MIL框架的性能。
D. Cross-Modal KD
跨模态知识蒸馏(KD)的目标是将教师模型获取的额外模态的特权知识转移到学生模型中。Hoffman等人[46]训练了一个幻觉网络来提取深度信息,旨在提升RGB目标检测器的性能。Georgescu等人[47]通过三元组损失训练了一个师生框架,在完全可见的面部和被遮挡的面部之间转移有用知识,以提高在强遮挡下多项面部图像分析任务的性能。在视频理解领域,Zhang等人[48]提出将光流中的细粒度运动细节转移到粗略运动向量中,这样可以在不牺牲动作识别准确率的前提下保持处理速度。深度转移运动向量卷积神经网络(deeply transferred motion - vector CNNs)[49]进一步通过利用中间层来改进运动知识蒸馏。Crasto等人[21]利用三维卷积神经网络从光流流中提取运动模式,增强RGB输入以生成混合外观 - 运动表示。然而,这些方法本质上是为短剪辑视频分类设计的,因此可能无法捕捉未修剪视频中的复杂时间关系。为了检测长未修剪视频中的动作实例,Luo等人[17]提出了一种图蒸馏方法来转移多种模态获取的知识。但是,这种方法采用滑动窗口处理长视频,仅提取片段级的局部特征,没有对片段之间的关系进行建模。为了解决这个问题,Dai等人[23]引入了两个序列级蒸馏损失项来转移用于动作检测的长程时间知识。然而,这两种方法是为全监督动作检测设计的,无法直接推广到弱监督设置下的异常事件定位任务。与上述工作不同,我们提出的方法利用跨模态知识蒸馏框架,仅使用视频级注释来训练一个轻量级且有效的模型,该模型能够在未修剪视频中高精度地检测出异常片段,并且仅需极少的模态资源。
III. METHODOLOGY
A. Problem Formulation
弱监督视频异常检测(WS-VAD)的目标是利用粗略的视频级标签进行训练,从而在未修剪的视频中定位异常片段(段)。因此,WS-VAD任务可以表述如下:给定一组训练视频\(V=\{v_{i}\}_{i = 1}^{|V|}\) ,其中\(|V|\)是视频的数量;以及相应的视频级注释集\(Y=\{y_{i}\}_{i = 1}^{|V|}\) ,如果\(v_{i}\)是异常视频,则\(y_{i}=1\) ,否则\(y_{i}=0\) 。针对WS-VAD任务训练的模型,要为每个视频输出一个异常分数向量\(s_{i}\in\mathbb{R}^{T_{i}}\) ,其中\(T_{i}\)是第\(i\)个视频中的片段总数,并且\(s_{i}\)中的每个元素都被归一化到\([0,1]\) 。
B. Multimodal Interaction-Based Teacher Network
1) 整体架构:所提出的基于多模态交互的教师网络的整体架构如图2(a)所示。由于视频天然包含多种模态,例如RGB、光流和音频,它们从不同角度描述了视频中事件的语义,因此在训练阶段,我们从所有可用的原始模态中提取多模态特征。具体而言,每个视频\(v\)首先被划分为\(T\)个不重叠的片段,每个片段由16个连续的帧组成。我们利用预训练的I3D[42]网络作为视觉编码器,分别从RGB和光流模态中提取外观特征\(x^{r} \in \mathbb{R}^{T ×d_{r}}\)和运动线索\(x^{o} \in \mathbb{R}^{T ×d_{o}}\),其中\(d_{r}=d_{o}=1024\)。此外,预训练的VGGish[50, 51]网络用于从同步音频信号中提取音频特征\(x^{a} \in \mathbb{R}^{T ×d_{a}}\),其中\(d_{a}=128\)。为简单起见且不失一般性,我们以使用RGB和音频这两种模态为例,来阐述多模态教师模型。如图2(a)所示,从编码器中提取的RGB和音频特征被输入到两个并行分支中。每个分支包含两个时间卷积(TC)层,每个TC层学习特定模态的时间嵌入,\(d\)表示潜在特征空间的维度。在每个TC层之后部署所提出的跨模态交互(CI)模块,以从不同时间尺度学习具有判别性的跨模态表示。在跨模态交互学习阶段之后,多模态特征被融合并输入到最后的TC层,随后经过sigmoid激活函数,输出异常分数向量\(s \in \mathbb{R}^{T}\)。
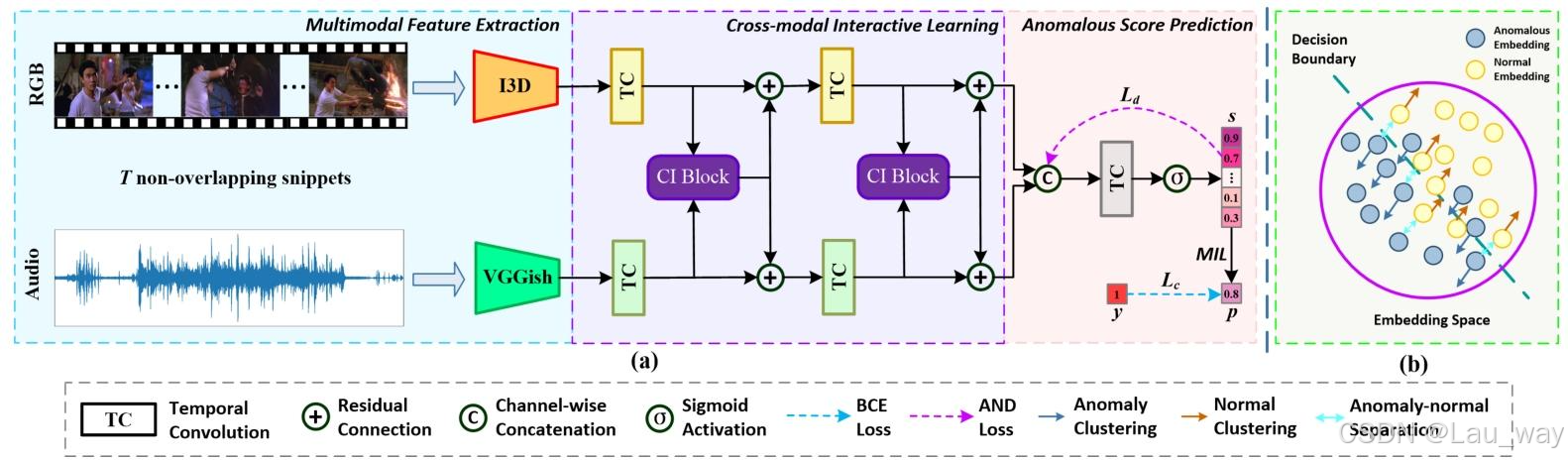
图2. (a)我们基于多模态交互的教师网络整体架构(以RGB和音频输入为例)。(b)所提出的异常 - 正常判别(AND)损失的示意图。
2) 跨模态交互学习:从编码器中提取的原始特征可能包含一些与任务无关的冗余信息,因为这些编码器通常是在一些大规模数据集(如经过剪辑的动作数据集)上进行预训练的,而这些数据集与弱监督视频异常检测(WS - VAD)任务并无直接关联。为了过滤掉与任务无关的冗余信息,并学习更好的跨模态表示,我们提出了一个跨模态交互(CI)模块。这是基于这样一个观察结果:在不同场景下,从每种模态中提取的序列嵌入在时刻和通道上的判别能力有所不同。例如,当细微的异常事件仅在视野中占据很小区域或涉及自我遮挡时,音频信号能为异常检测提供更独特且有用的信息。而在一些嘈杂环境中,从视觉信号中提取的外观模式则更为可靠。因此,如图3所示,为了突出每种模态中有区分力的时间步和通道的特征,CI模块是基于时间维度和通道维度的注意力机制设计的。
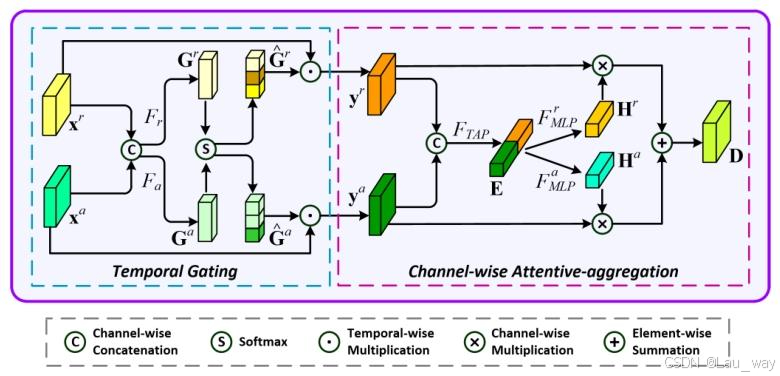
图3. 所提出的跨模态交互(CI)模块的结构。
a) 时间门控:基于时间门控(TG)方案,我们根据不同模态在每个时间步的判别能力,对这些模态的特征进行重新校准。具体来说,我们首先将这两种模态的序列特征沿着通道维度进行拼接。然后,拼接后的特征分别被投影到两个特定模态的时间门中,如下所示:
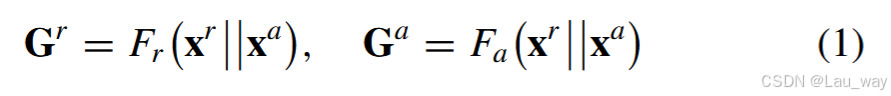
其中 || 表示按通道拼接操作,\(G_r \in \mathbb{R}^T\) 和 \(G_a \in \mathbb{R}^T\) 分别是RGB和音频模态的时间门。\(F_r(·)\) 和 \(F_a(·)\) 是两个由时间卷积(TC)内核实现的独立投影函数。 这两个门进一步通过softmax操作进行归一化,如下所示:
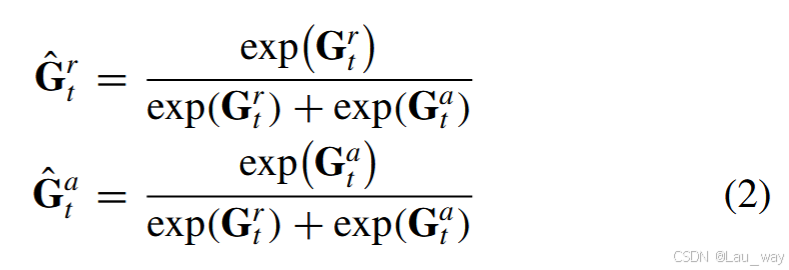
其中,$\hat{G}_{r,t}$和$\hat{G}_{a,t}$分别是分配给RGB和音频序列特征每个时间步t的权重。然后,基于每个通道的逐元素乘法,通过这两个归一化的时间门对原始输入进行重新校准,如下所示:
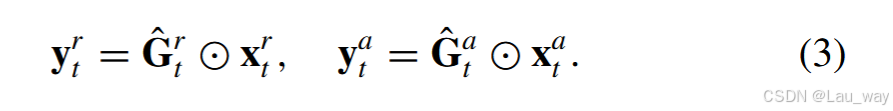
b) 通道注意力聚合:我们进一步采用通道注意力机制,来衡量不同模态的序列特征中每个通道的重要性。具体而言,我们首先将重新校准后的序列特征,即和
,沿通道维度进行拼接,然后应用时间平均池化(TAP),以获得跨模态全局统计信息,如下所示:
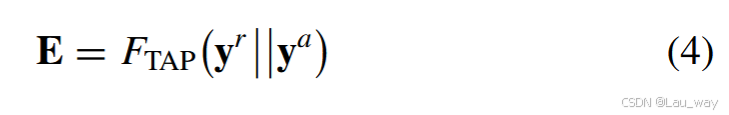
其中\(F_{TAP}(\cdot)\)表示时间平均池化(TAP)操作。然后,基于跨模态整体描述符\(\mathbf{E} \in \mathbb{R}^{2d}\)学习得到两个通道注意力权重向量,如下所示:
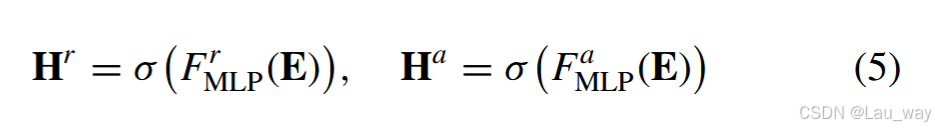
其中,和
是两个独立的多层感知器(MLP)网络,
是sigmoid激活函数。最后,我们利用这两个通道注意力权重向量,即
和
,按如下方式聚合经过时间重新校准的特征:
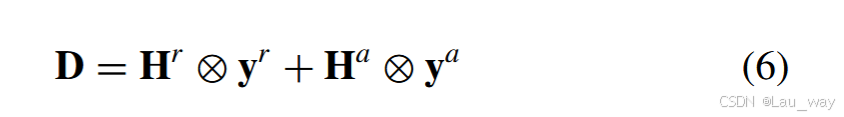
其中 ⊗ 表示按通道相乘。因此,跨模态表示 整合了不同模态中有区分力的时间步和通道的特征,对现实场景中的各种干扰因素具有鲁棒性。
c) 传播方案:我们在每个时间卷积(TC)层之后插入所提出的跨模态交互(CI)模块,它作为RGB和音频分支之间进行交互学习的桥梁。受残差学习 [52] 的启发,由第 l 个CI模块生成的跨模态表示 被反向注入到两个独立的分支中,以细化第 l 个TC层的原始序列特征,如下所示:
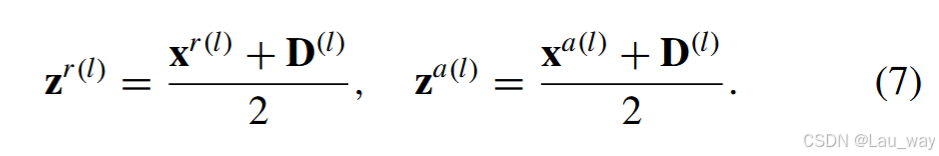
经过细化的序列特征和
分别作为RGB分支和音频分支第
层的输入,用于特定模态的传播。
3)异常-正常判别(AND)损失:为了促进对可分离的异常和正常表示的学习,我们基于自上而下的注意力机制提出一种判别损失,如图2(b)所示。具体而言,在异常分数预测阶段开始时,我们首先将来自RGB和音频分支的细化后的序列特征和
进行拼接,以获得融合的多模态特征
,即
,其中L是每个特定模态分支中最后一个时间卷积(TC)层的索引。然后,我们利用异常分数向量
作为自上而下的注意力权重,分别计算视频级别的异常和正常嵌入,即
和
,如下所示:
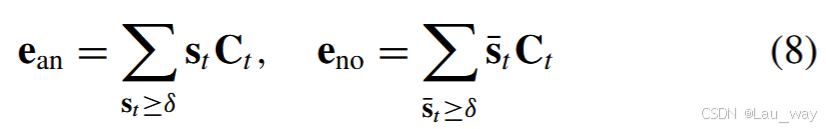
其中, 是一个阈值,
是正常注意力,即
。最大化异常和正常嵌入之间的距离,有助于使异常片段与正常片段的相应分数更具可分离性,从而提升时间定位性能。此外,对异常和正常嵌入进行聚类,分别有利于为异常事件和正常事件的分类学习一个紧凑的表示空间。因此,我们制定了三个项,分别表示为
、
和
,用于异常 - 正常分离、异常聚类和正常聚类,其定义如下:
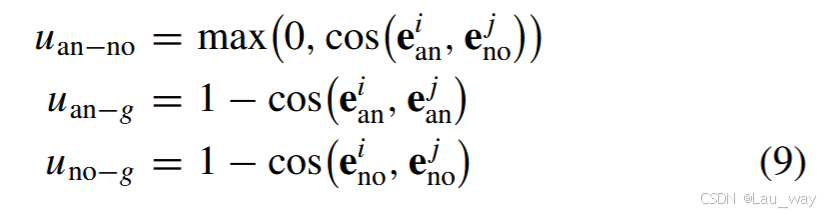
其中, 和
分别是一个小批量中第 i 个和第 j 个视频的嵌入,
表示余弦距离函数。因此,基于这三项,异常 - 正常判别(AND)损失定义如下:
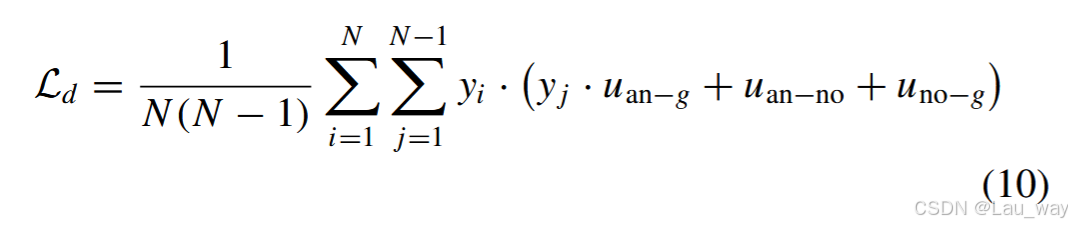
其中,N 是每个小批量的大小。在实际操作中,对于每个异常样本 i(),我们从同一批次中采样其他 N - 1 个视频来计算判别损失。当第 $j$ 个视频是正常样本(
)时,异常聚类项
将被舍弃,因为正常视频不包含任何异常片段。
4)整体目标函数:为了引入视频级别的标注来监督片段级别的异常检测,我们利用多示例学习(MIL)原则[45],该原则将时间维度上Top - K分数的平均值作为视频级别的预测值,即
,其中
是选择指示符,
。然后,基于预测分数
与真实值
之间的二元交叉熵来定义视频级别的分类损失,如下所示:
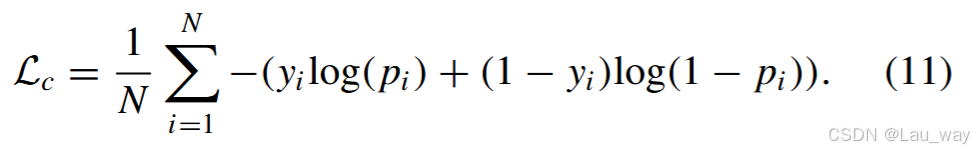
此外,基于异常片段在异常视频的较长时长中稀疏分布这一先验知识,我们引入了稀疏正则化损失,即
。因此,整体目标函数表述如下:
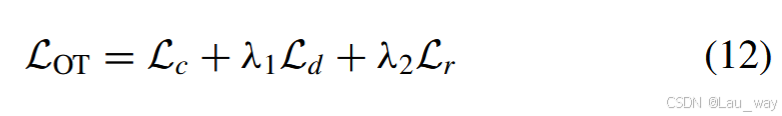
其中,参数和
用于平衡相应损失项的权重。
C. Training Student Network by Privileged KD Framework
多模态弱监督视频异常检测(WS - VAD)方法高度依赖各种模态的可用性,并且需要大量的处理资源,尤其是在分析较长的未修剪视频时。为了解决这一问题,我们利用知识蒸馏(KD)框架,通过从教师网络中提取特权信息来训练一个学生网络。
1) 概述:学生网络的输入模态取决于实际场景中的特定需求。我们选择RGB模态作为默认设置,因为它易于获取,且能为弱监督视频异常检测(WS - VAD)任务提供丰富的视觉线索。对于教师网络,其输入可根据实际可用情况灵活采用多种模态。不失一般性,我们以第三节B部分所描述的同时使用RGB和音频两种模态的教师模型为例,来详细阐述跨模态知识蒸馏(KD)框架的细节。因此,任务具体设定如下:我们仅将RGB序列输入学生模型,并对其进行训练,使其在视频级弱监督下,从教师网络中提取跨模态知识,以检测异常片段。如图4所示,学生网络基于单分支构建,该分支由三个时间卷积(TC)层构成。前两个TC层用于学习时间嵌入\(x^{S} \in \mathbb{R}^{T ×2d}\),而第三个配备了sigmoid激活函数的TC层,可视为一个片段级分类器,它生成学生模型的异常分数向量\(s^{S} \in \mathbb{R}^{T}\)。特权知识蒸馏在两个层面进行。首先,我们执行表征级蒸馏,促使学生模型学习具有边界感知能力的逐片段特征以及整体的异常 - 正常嵌入。其次,从片段级和视频级两个角度进行对数几率(logits)级蒸馏。
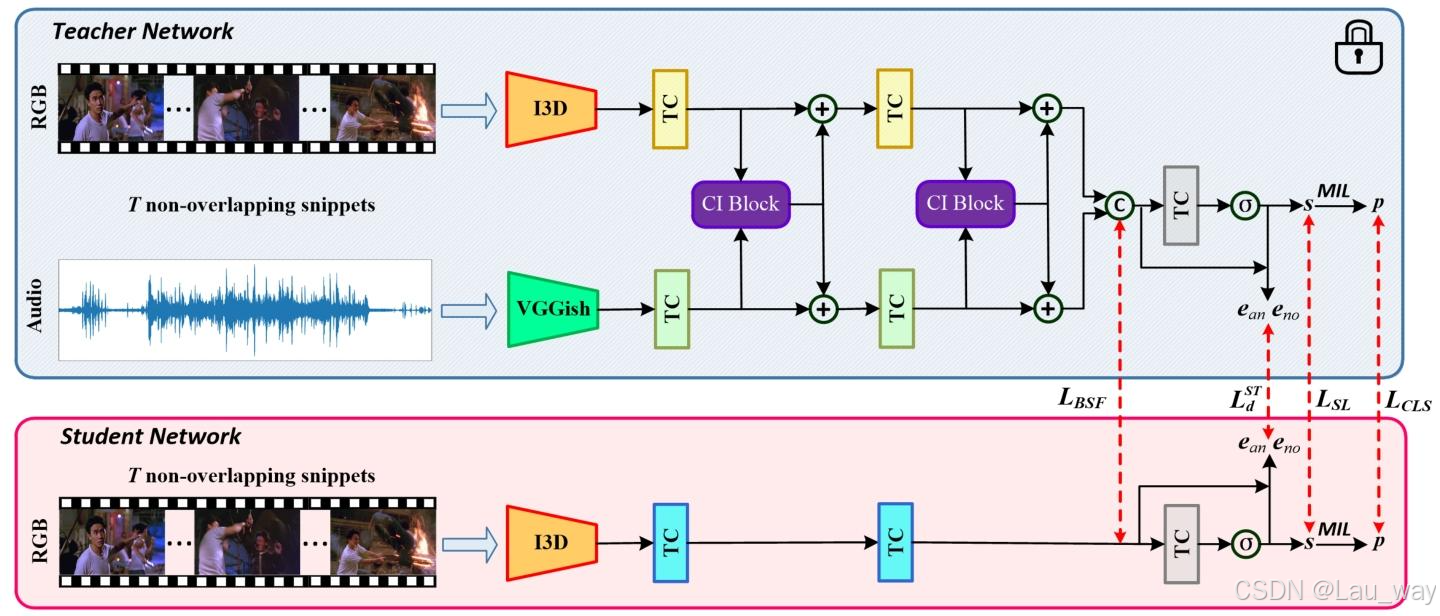
图4. 所提出的用于训练单模态学生网络的特权知识蒸馏框架示意图。
2) 边界感知逐片段特征:受文献[17]启发,为促使学生网络模仿教师网络的局部跨模态表示,我们采用余弦距离来衡量两个网络逐片段特征之间的角度差异。此外,一个关键的观察结果是,异常事件开始和结束对应的片段通常比其他部分更显著,这为在未修剪视频中区分异常和正常片段提供了有用线索。这种边界显著性可以通过连续片段间的急剧变化来捕捉。因此,为了强调对这些信息丰富的片段进行特征模仿,如图5(a)所示,我们提出如下的边界感知逐片段特征蒸馏损失:
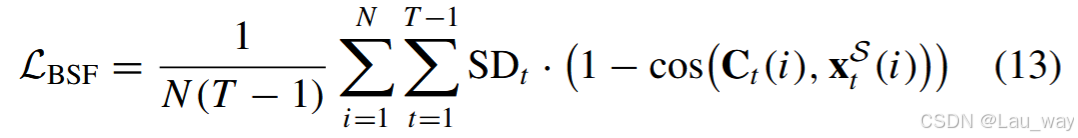
其中, 表示教师网络在时间步 t 生成的多模态片段特征,
代表学生网络第二个时间卷积(TC)层输出的片段特征,
衡量了教师网络中连续片段之间的特征通道变化。最小化
意味着要求学生模型更多地关注在与边界相关的片段上提取局部跨模态表示。
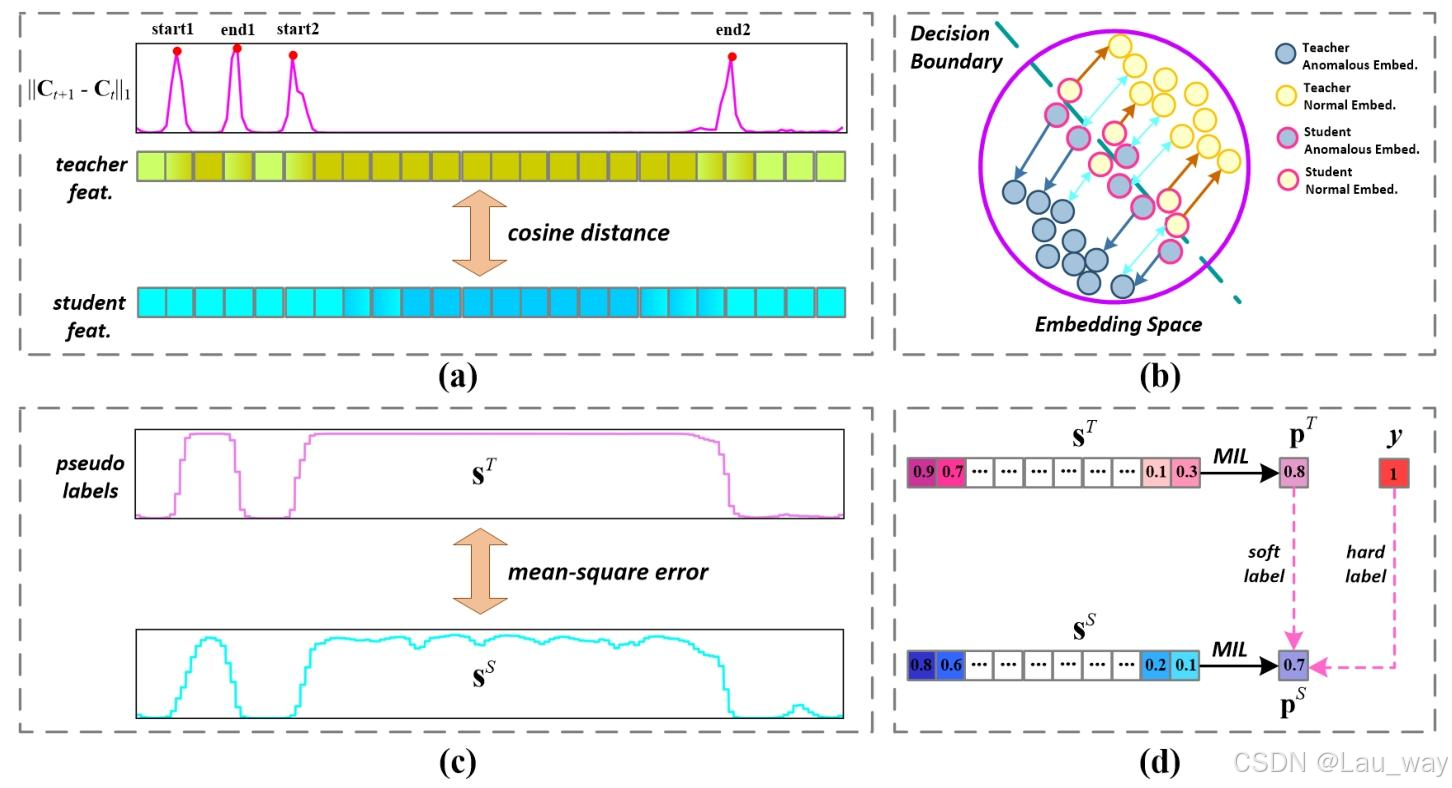
图5. 所提出的多种蒸馏损失函数示意图,这些函数专注于提取 (a) 边界感知的逐片段特征(即
),(b) 异常 - 正常嵌入(即
),(c) 片段级预测分数(即SL),以及 (d) 视频级对数几率(即
)。
3)整体异常 - 正常嵌入:视频级别的异常和正常嵌入会根据异常程度对片段进行聚类,这有助于模型从整体角度区分异常事件和正常事件的语义。因此,为了促进学生模型学习这种整体表示,基于(9)和(10),我们提出如下异常 - 正常嵌入蒸馏损失:
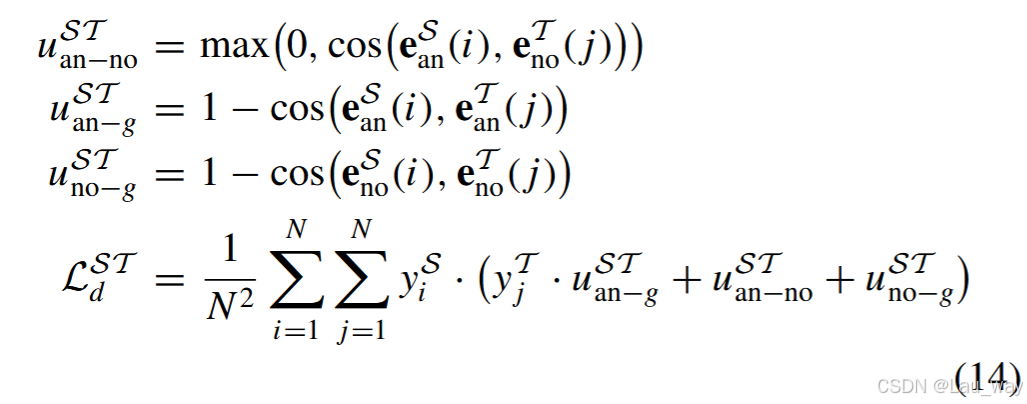
其中,和
分别是学生网络的异常嵌入和正常嵌入,即
且
。
和
分别是由多模态教师网络生成的异常嵌入和正常嵌入。由于教师模型已经为异常片段和正常片段学习到了一个可分离的表示空间,所以嵌入
和
可以作为整体特征目标,供学生模型进行蒸馏学习。因此,如图5(b)所示,优化式(14)中定义的损失,将迫使学生模型的视频级异常 - 正常嵌入空间接近教师模型提供的相应嵌入空间。
4)片段级预测分数:由于在弱监督视频异常检测(WS - VAD)任务中无法获取片段级别的真实标注,如图5(c)所示,我们利用教师网络预测的异常分数作为伪标签,来指导学生网络的学习。基于均方误差设计片段级对数几率蒸馏损失如下:
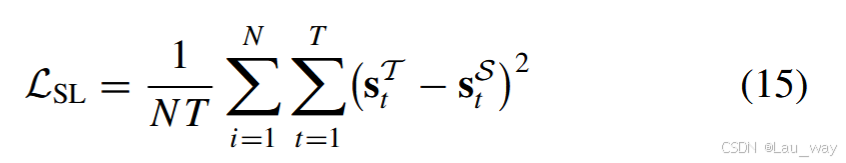
其中,\(s^{\mathcal{S}} \in \mathbb{R}^{T}\) 和 \(s^{\mathcal{T}} \in \mathbb{R}^{T}\) 分别是学生模型和教师模型的异常分数向量。这一损失项有助于保持学生网络和教师网络在片段级预测上的一致性。
5)视频级对数几率:基于多示例学习(MIL)原则,我们还从\(s^{\mathcal{S}}\)中选取前\(K\)个分数,并计算它们的平均值作为学生模型的视频级预测值\(p_{i}^{\mathcal{S}}\) 。然后,如图5(d)所示,我们通过同时使用硬标签和软标签,针对视频分类任务采用一种广义蒸馏损失[53],如下所示
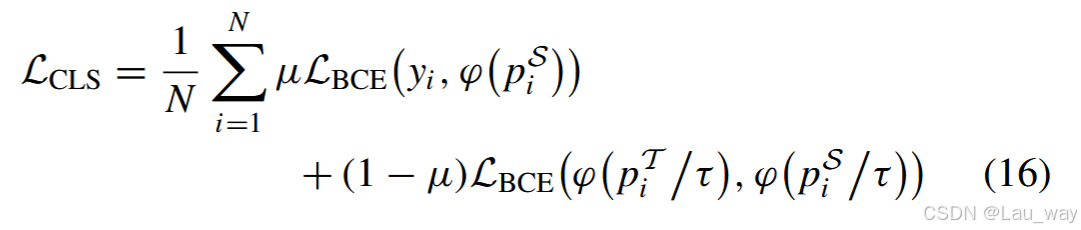
其中,\(\varphi\)是一个Softmax函数,\(\mathcal{L}_{BCE}(\cdot)\)表示二元交叉熵损失,\(p_{i}^{\mathcal{T}}\)表示教师网络的视频级预测值。参数\(\mu \in [0, 1]\)用于平衡视频级对数几率蒸馏损失中真实标签\(y_{i}\)和软标签\(\varphi(p_{i}^{\mathcal{T}} / \tau)\)的权重。\(\tau\)是用于软化预测的温度参数。除了真实标注提供的监督外,式(16)中定义的蒸馏损失还考虑了软标签,通过从多模态教师模型中提取视频级对数几率信息,提高了学生模型的泛化能力。
6)训练与推理:特权知识蒸馏的训练范式包含两个步骤。第一步,如第三节B部分所述,通过探索多种模态来训练教师网络。第二步,冻结教师模型的权重,为学生网络进行蒸馏学习提供一个稳定的目标。训练学生网络的整体目标函数由(13) - (16)中定义的四个损失项组合而成,如下所示:
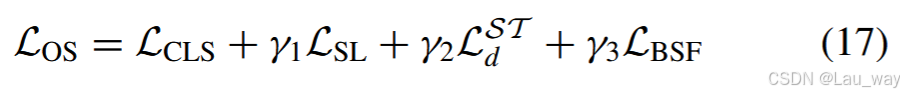
其中,参数\(\gamma_{1}\)、\(\gamma_{2}\)和\(\gamma_{3}\)用于平衡不同项之间的权重。
在推理阶段,学生模型仅将RGB视频作为输入,并输出片段级别的异常分数。然后,我们对预测的片段级对数几率进行上采样,以获得帧级别的异常分数。为了定位异常序列,保留分数高于固定阈值的帧,进一步连接连续的帧,从而得到时间维度上的异常定位结果。
IV. EXPERIMENTS
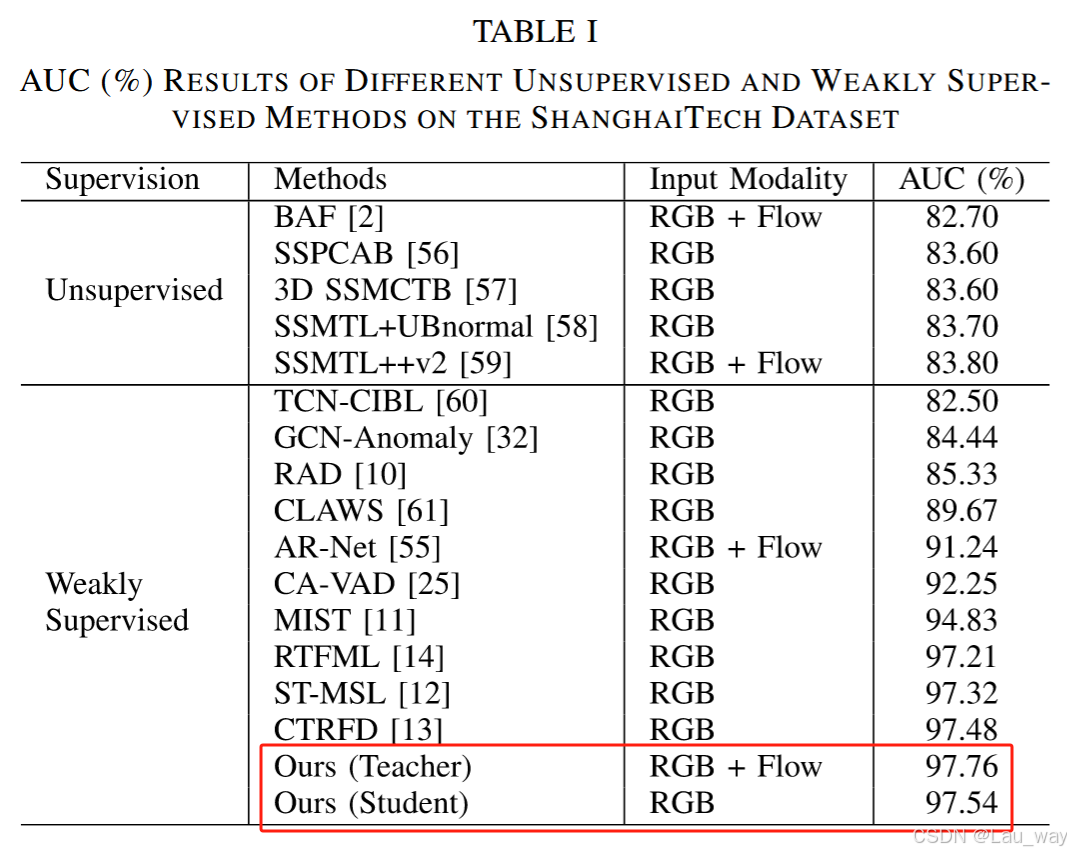
1) 上海科技大学(ShanghaiTech)数据集上的结果:表1列出了我们所提方法与其他最先进的无监督和弱监督方法在上海科技大学数据集上的对比结果。总体而言,弱监督方法相较于近期最先进的无监督方法展现出显著的性能提升,这证实了在训练中引入具有成本效益的视频级标签的益处。我们可以发现,所提出的多模态教师网络取得了97.76%的AUC成绩,始终优于其他竞争对手。与AR - Net [55]中使用的基于简单拼接的融合策略相比,6.52%的性能提升验证了所提CI模块的有效性,因为它能够通过跨模态交互生成面向任务的时间嵌入。此外,仅使用RGB输入时,我们所提学生网络的性能可与第二好的结果(CTRFD [13])相媲美,这表明所提出的多层次蒸馏框架能够为弱监督视频异常检测(WS - VAD)任务学习到丰富的跨模态特权知识。再者,学生模型比专注于通过自训练生成特定任务表示的MIST [11]方法高出2.71% 。这表明所提出的基于两阶段的蒸馏框架也能够有效地将特定任务特征从教师模型转移到学生模型,以助力异常片段的检测。
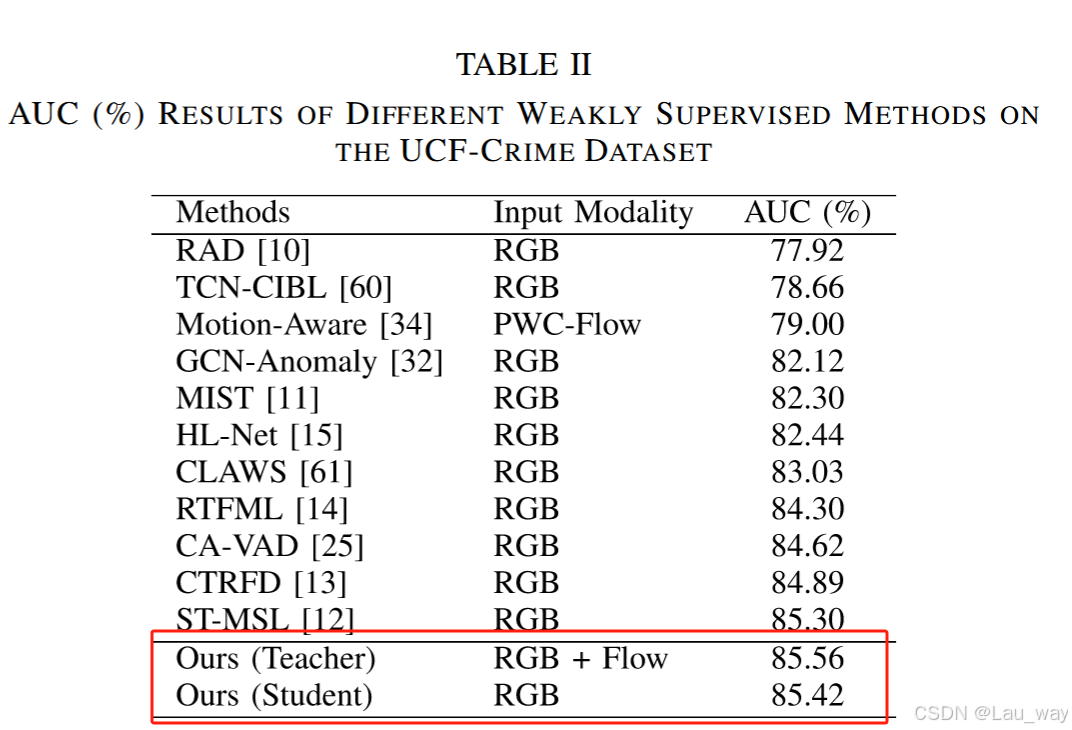
2) UCF - Crime数据集上的结果:表二展示了不同方法在UCF - Crime数据集上的AUC结果。所提出的教师网络和学生网络分别取得了85.56%和85.42%的AUC分数,超过了其他与之对比的最先进方法。我们的学生网络比基于图的方法,即GCN - Anomaly [32]和CA - VAD [25],分别高出3.3%和0.8%,这表明在有效学习准则的引导下,时间卷积也能够学习长距离依赖关系。与基于聚类的方法CLAWS [61]相比,我们的学生模型实现了2.39%的AUC提升,因为所提出的AND损失同时考虑了类间可分离性和类内分组,对于学习紧凑的特征空间而言更为完善。尽管motion - aware [34]方法利用PWCNet [62]提取光流作为增强的运动线索,并在多示例学习(MIL)排序模型中引入了自下而上的注意力模块,但我们的学生网络仍比它高出6.42%,这体现了使用外观 - 运动表示蒸馏的优势。此外,我们的方法在损失函数中融入了自上而下的注意力机制,以学习可分离的异常和正常嵌入,这对于弱监督视频异常检测(WS - VAD)任务来说更为直接有效。
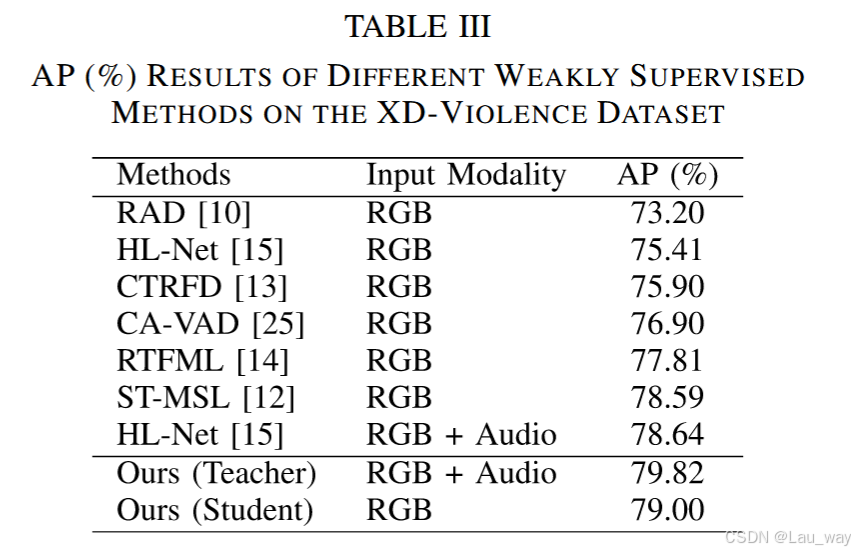
3) XD - Violence数据集上的结果:表三总结了在最新发布的XD - Violence数据集上基于平均精度(AP)指标的对比结果。在同时探索RGB和音频模态时,我们的多模态教师网络比HL - Net [15]高出1.18%,这再次表明通过所提出的跨模态交互学习策略过滤掉与任务无关的冗余信息所带来的优势。仅将RGB视频作为输入时,我们的学生网络比基于多示例学习(MIL)的方法,即RAD [10]和RTFML [14],分别高出5.8%和1.19%,这表明所提出的跨模态特权知识蒸馏方法能够在弱监督环境下提升基于MIL框架的性能。
消融实验
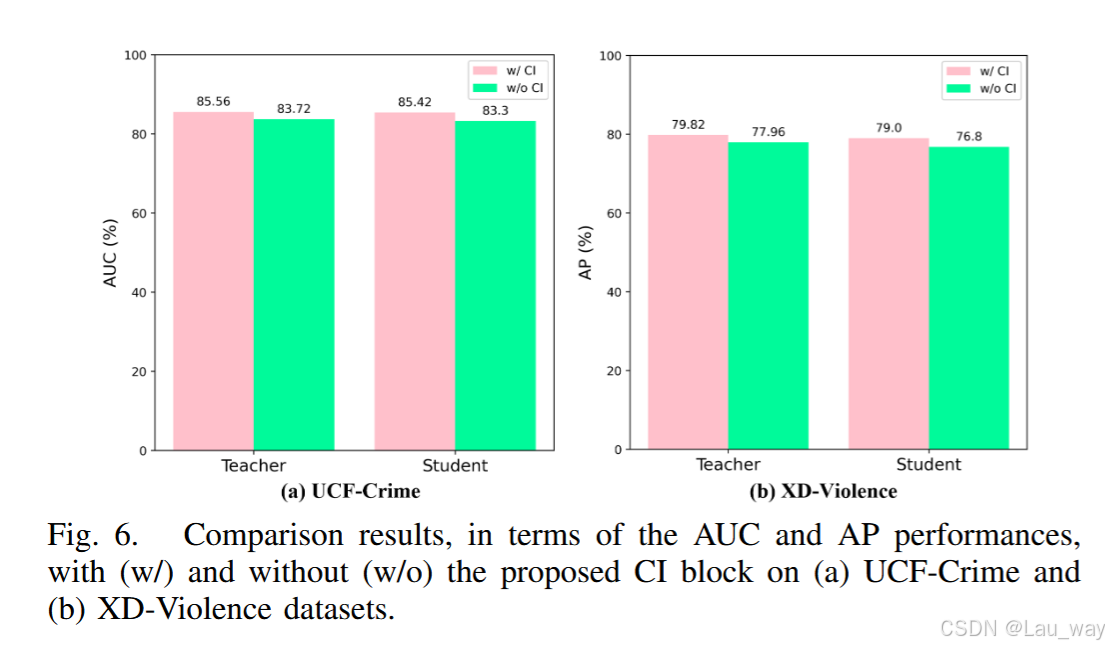 1)CI模块的作用:我们评估所提出的CI模块对多模态教师网络的贡献,以及它对特权知识蒸馏框架的后续影响。相应的AUC和AP结果如图6所示。在UCF - Crime数据集上,如果不使用所提出的CI模块,教师模型的AUC从85.56%降至83.72%,这表明通过跨模态重新校准来过滤掉与任务无关的冗余信息是必要的。此外,我们发现,未使用CI模块训练的教师模型对特权知识蒸馏有负面影响,因为这导致学生模型在XD - Violence基准测试中的性能下降了2.2%。这也表明,教师模型学习到的特定任务跨模态表示,对于在弱监督视频异常检测(WS - VAD)任务中训练出有效的学生模型至关重要。
1)CI模块的作用:我们评估所提出的CI模块对多模态教师网络的贡献,以及它对特权知识蒸馏框架的后续影响。相应的AUC和AP结果如图6所示。在UCF - Crime数据集上,如果不使用所提出的CI模块,教师模型的AUC从85.56%降至83.72%,这表明通过跨模态重新校准来过滤掉与任务无关的冗余信息是必要的。此外,我们发现,未使用CI模块训练的教师模型对特权知识蒸馏有负面影响,因为这导致学生模型在XD - Violence基准测试中的性能下降了2.2%。这也表明,教师模型学习到的特定任务跨模态表示,对于在弱监督视频异常检测(WS - VAD)任务中训练出有效的学生模型至关重要。
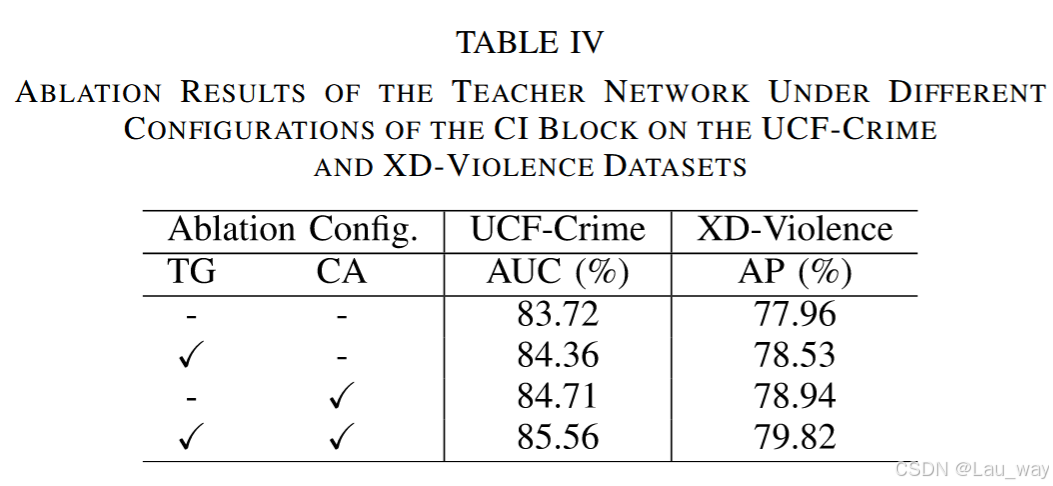
由于CI模块主要由两个部分组成,即时间门控(TG)和通道注意力聚合(CA),我们进一步进行了消融实验,以探究这两个部分的有效性。结果如表四所示。在XD - Violence数据集上,仅将时间门控(TG)引入基线模型时,教师网络的平均精度(AP)从77.96% 提升至78.53%,这表明突出不同模态中有区分度时间步的特征是有益的。由于通道注意力聚合(CA)旨在借助其他模态的帮助来发现每个模态中有信息含量的特征通道,所以仅将其纳入基线模型,在UCF - Crime数据集上仍能使曲线下面积(AUC)提升0.99%。总体而言,使用完整的CI模块可实现最佳性能,因为时间门控(TG)和通道注意力聚合(CA)组件分别有助于在时间维度和通道维度学习特定任务的表示,本质上这两个维度的视角具有互补性。
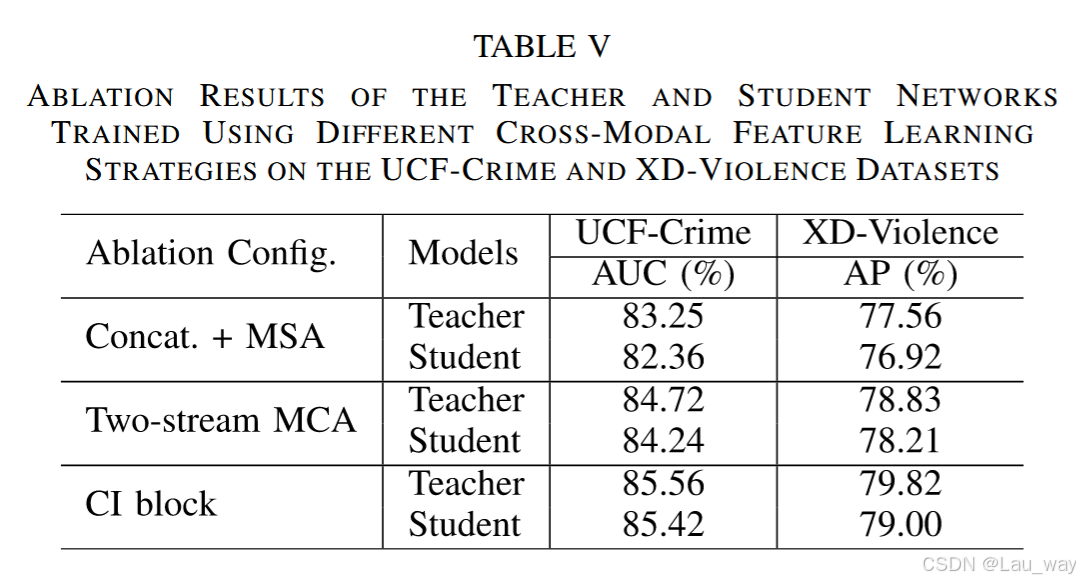
为进一步验证CI模块在跨模态特征学习中的有效性,我们通过探究另外两种基本设计进行消融实验。如图7(a)所示,第一种变体(表示为“拼接 + 多头自注意力”)将来自不同模态的特征进行拼接,并利用多头自注意力[63]模块对多模态特征进行优化。 第二种变体“双流多头交叉注意力(Two - stream MCA)”[见图7(b)]采用两个并行分支,每个分支利用一个用于交叉交互(CIs)的多头交叉注意力模块[64]。对比结果列于表V中。与这两种变体相比,基于CI模块的教师网络在UCF - Crime和XD - Violence数据集上能够取得更好的性能,并且在训练学生检测器时,分别进一步带来超过1.18%的AUC提升和0.79%的AP提升。这表明了所提出的CI模块在学习面向任务的跨模态表示方面的优势。
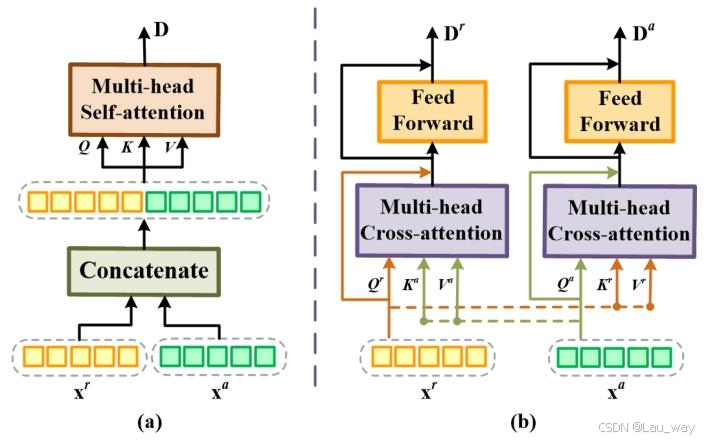
图7. 跨模态特征学习模块两种变体的结构,包括(a)“拼接 + 多头自注意力(Concat. + MSA)”和(b)“双流多头交叉注意力(Two - stream MCA)” 。
2) AND损失的影响:我们进行了消融实验,以探究所提出的AND损失对教师模型性能的影响。实验结果总结在表VI中。在未采用AND损失的情况下,基线模型在XD - Violence基准测试中的平均精度(AP)为78.03%,性能下降了1.79%。这表明AND损失有助于在未修剪的视频中定位异常片段。我们还分别研究了使用类间分离项(即)和类内分组项(即
和
)的影响。可以观察到,在这两种情况下,基线模型的性能均有所提升。类间分离项带来的性能提升大于类内分组项,例如,在UCF - Crime数据集上分别为0.94%和0.73%。实际上,类间分离项是基于对比学习方式设计的,它直接引导模型持续学习区分异常和正常嵌入。此外,图8使用t - SNE [65]可视化了使用和未使用所提出的AND损失时学习到的异常和正常嵌入的分布情况。我们可以发现,当模型在AND损失的监督下进行训练时,在UCF - Crime和XD - Violence数据集上,每个类别的嵌入都紧密聚集在一起[图8(a)和(b)右侧的图]。
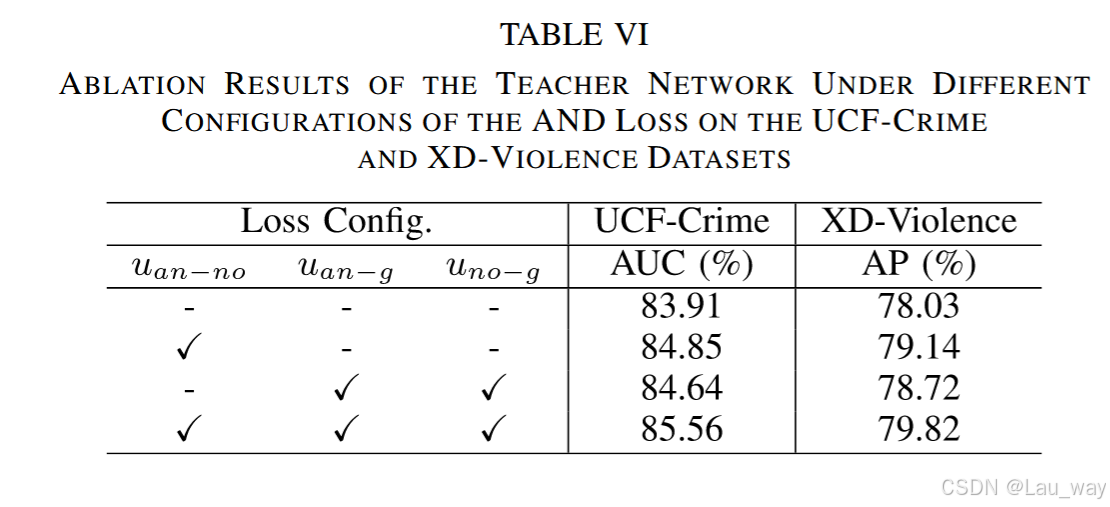
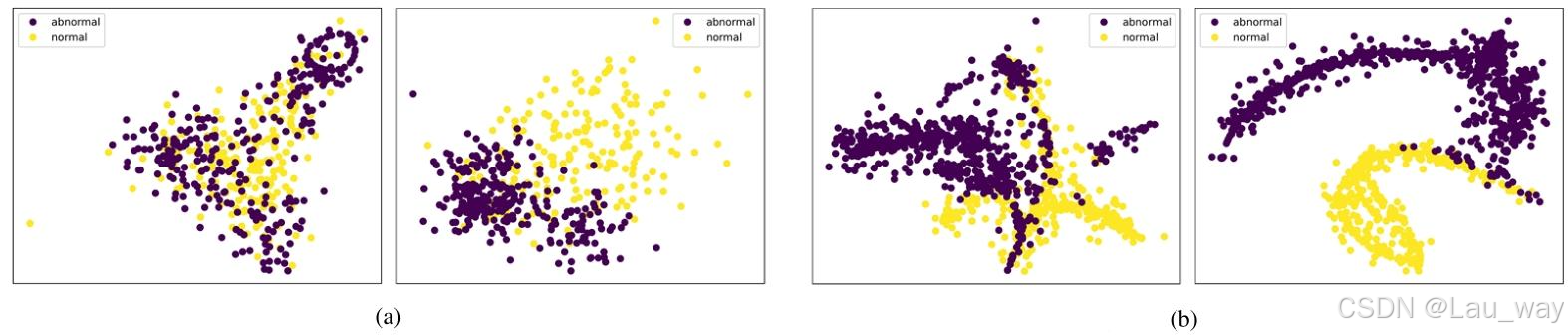
图8. 使用t-SNE对(a)UCF - Crime和(b)XD - Violence数据集上,在使用与不使用所提出的AND损失情况下学习到的异常和正常嵌入分布进行的可视化。
3) 多种蒸馏损失函数的作用:我们开展消融实验,以探究所提出的多种蒸馏损失函数对学生模型性能的影响。表VII列出了消融实验结果。为作对比,我们实现了一个基线模型,该模型仅以RGB模态作为输入,且在无知识蒸馏(KD)的情况下,通过基于多示例学习(MIL)的视频级分类损失进行训练。基于实验结果,我们有以下发现。
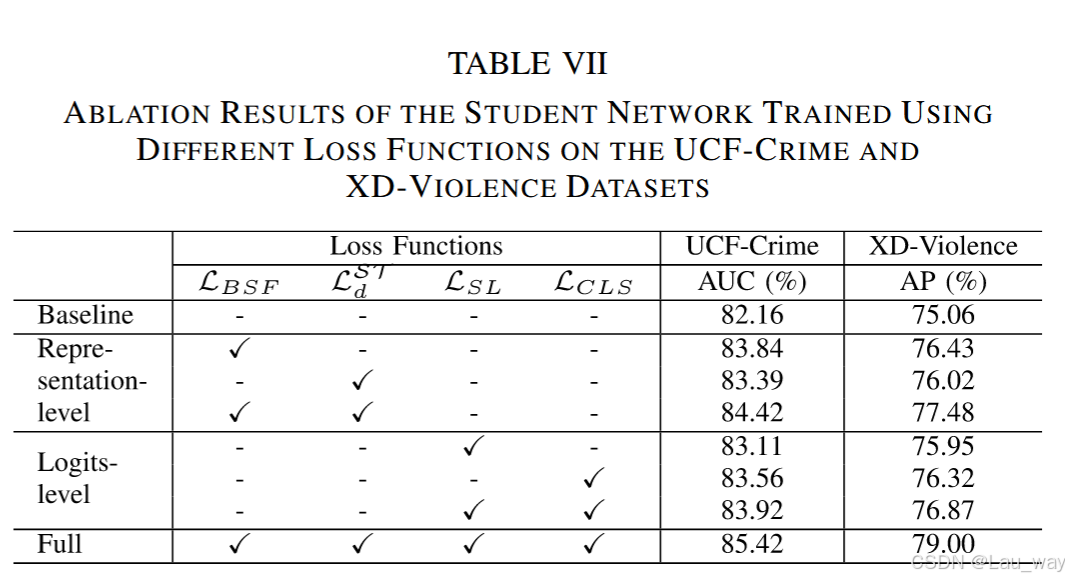
1) 两个表示层蒸馏损失项,\(L_{BSF}\)和\(L_{d}^{ST}\),在UCF - Crime数据集上分别使曲线下面积(AUC)独立提升了1.68%和1.23%。由于弱监督视频异常检测(WS - VAD)任务旨在定位异常事件的起始和结束,边界感知的逐片段特征蒸馏损失\(L_{BSF}\)能够强调边界片段上的特征模仿,这直接影响了学生网络的异常检测性能。
2) 在对数几率层蒸馏方面,在XD - Violence数据集上,分别将损失项\(L_{SL}\)和\(L_{CLS}\)引入基线模型,平均精度(AP)性能分别提升了0.89%和1.26%。视频级对数几率蒸馏损失\(L_{CLS}\)的贡献高于片段级分数蒸馏损失\(L_{SL}\)。这一现象背后的根本原因是,教师模型生成的伪片段级标签相对较弱,而在弱监督设置下仅提供了视频级的真实标签。
3) 当同时使用表示层和对数几率层蒸馏损失函数进行训练时,学生网络取得了最佳性能。在UCF - Crime数据集上,相较于基线模型,曲线下面积(AUC)提升了3.26%;在XD - Violence数据集上,平均精度(AP)提升了3.94%。
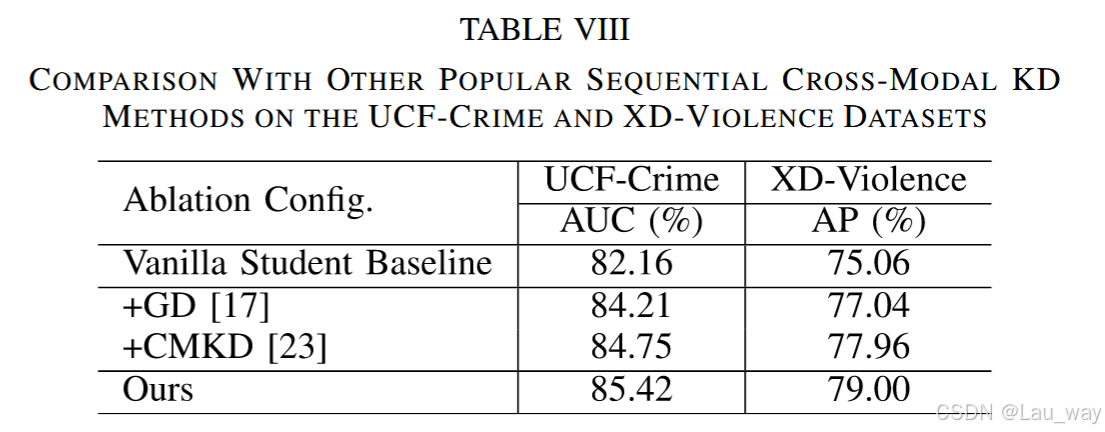
为进一步验证专为弱监督视频异常检测(WS - VAD)任务设计的跨模态知识蒸馏(KD)框架的有效性,我们通过整合两种广泛应用的知识蒸馏方法——最初为全监督动作检测设计的通用蒸馏(GD)[17]和跨模态知识蒸馏(CMKD)[23]——来开展消融实验。具体而言,为使这些方法适用于弱监督环境,我们将对数几率层损失(即\(L_{SL}\)和\(L_{CLS}\))与GD和CMKD中提出的表示层蒸馏损失相结合,以进行公平比较。消融实验结果见表VIII。我们发现,在UCF - Crime和XD - Violence数据集上,我们提出的KD框架始终优于GD和CMKD方法(AUC提升0.67%,AP提升≥1.04%)。GD中基于普通余弦距离的损失在局部表示蒸馏中对每个片段一视同仁,而我们的边界感知蒸馏损失\(L_{BSF}\)能促使学生模型更多地关注正常与异常事件之间的过渡点,这更适合弱监督定位任务。尽管CMKD方法考虑了传递片段间的显著关系,但我们提出的视频级嵌入蒸馏损失有助于学生模型构建一个可分离的特征空间,以明确区分异常和正常嵌入,从而在WS - VAD任务中取得更好的性能。
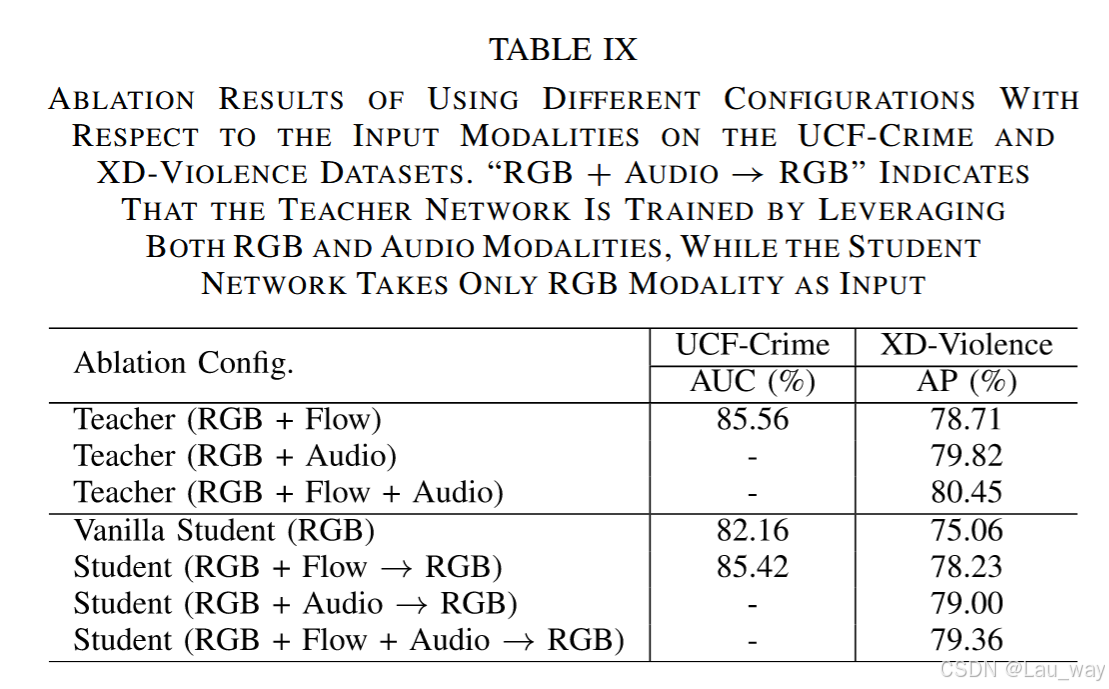
4) 不同输入模态的影响:我们开展了消融实验,以验证所提出的知识蒸馏(KD)框架对不同输入模态具有通用性。结果如表IX所示。光流模态可提供显著的运动模式,而音频信号本质上对视觉遮挡不敏感。因此,这两种模态的特权知识可以增强单模态RGB输入,在XD - Violence数据集上,使普通学生网络的平均精度(AP)性能分别提升3.17%(光流模态)和3.94%(音频模态)。总体而言,在教师网络中利用更多模态有助于提高蒸馏性能。例如,将光流和音频信号都作为特权模态进行整合,可使平均精度(AP)获得4.3%的更大提升。
5) 超参数分析:在公式(12)中有两个超参数,即\(\lambda_{1}\)和\(\lambda_{2}\),在公式(17)中有三个超参数,即\(\gamma_{1}\)、\(\gamma_{2}\)和\(\gamma_{3}\),这些超参数用于在训练教师模型和学生模型时平衡各个损失项的权重。我们通过在XD - Violence数据集上进行消融实验来评估这些超参数的影响。基于图9和图10所示的评估结果,我们有以下观察。
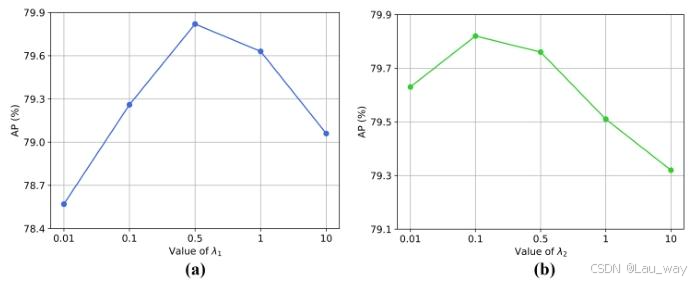
图9. 在XD - Violence数据集上训练教师网络时,对公式(12)中两个超参数(a)\(\lambda_{1}\)和(b)\(\lambda_{2}\)的评估。
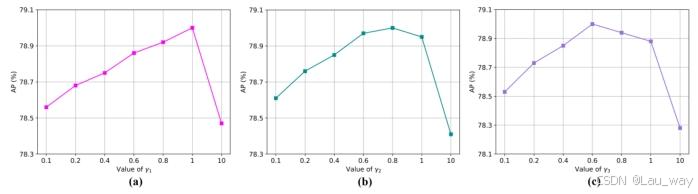
图10. 在XD - Violence数据集上训练学生网络时,对公式(17)中三个超参数(a)\(\gamma_{1}\) 、(b)\(\gamma_{2}\) 以及(c)\(\gamma_{3}\)的评估。
1) 由于提出AND损失\(L_{d}\) 是为了确保异常与正常表示之间的可分离性,通过系数\(\lambda_{1}\) 为其赋予合理权重(如1),能够提升教师网络的整体性能。此外,\(\lambda_{2}\) 的值过大(如10)会导致性能下降,因为在严格的稀疏正则化训练下,检测器无法从异常实例中学习到足够有用的线索。
2) 由于损失项\(L_{SL}\)、\(L_{d}^{ST}\)和\(L_{BSF}\)在教师模型与学生模型之间传递多层次知识方面具有互补作用,将这些平衡权重\(\gamma_{1}\)、\(\gamma_{2}\)和\(\gamma_{3}\)调整到合适范围(如[0.6, 1]),能让学生检测器获得不错的平均精度(AP)得分。根据评估结果,在所有其他实验中,我们将\(\lambda_{1}\)、\(\lambda_{2}\)、\(\gamma_{1}\)、\(\gamma_{2}\)和\(\gamma_{3}\)分别设置为0.5、0.1、1、0.8和0.6 。
6) 运行时间分析:我们在单张RTX 3090 GPU上评估了几种近期与编码器无关的方法的计算效率。推理时间的对比结果总结在表X中。在利用多模态输入时,我们的教师网络将HL - Net [15]的平均精度(AP)性能提高了1.18%,同时在处理每16帧片段时,每个片段节省0.52毫秒。更重要的是,在推理阶段,我们提出的学生网络处理每个RGB片段仅需7.04毫秒,满足实时异常检测的要求。我们的学生网络也比HL - Net和RTFML [14]更快,因为我们的网络本质上是基于单分支的轻量级模型,无需使用繁琐的多分支图卷积网络(GCNs)或多尺度处理。
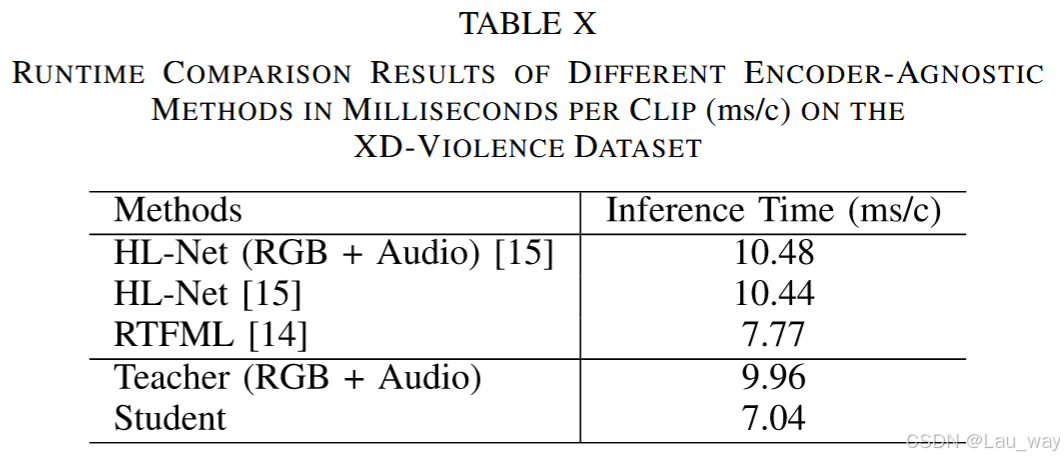
7) 定性结果:我们在三个基准数据集上,对未使用知识蒸馏(KD)训练的普通基线模型以及我们提出的学生模型所预测的帧级异常分数进行可视化,以定性展示我们所提方法的有效性。结果如图11所示。在上海科技大学(ShanghaiTech)数据集上,与基线模型相比,我们提出的学生网络能够更早地检测到“自行车”异常事件[例如,图11(b)]。基线模型在“滑板”事件中未能定位异常片段,而我们学生模型的帧级检测结果更接近真实情况[例如,图11(a)]。其根本原因在于,光流这一特权模态能够提供对运动敏感的模式,有助于我们提出的学生网络检测到图11(a)中仅占据小区域的异常事件。在UCF - Crime数据集上,我们的学生模型在“入室盗窃”“道路事故”和“抢劫”等人为主的异常事件中,更有把握检测到异常片段[例如,图11(e) - (g)]。在图11(h)所示的正常视频中,基线模型的检测结果误报率相对较高,这可归因于其区分异常与正常片段的能力较弱。在XD - Violence数据集上,我们提出的学生网络能够在长未修剪视频中检测到多个异常实例,并且异常与正常片段的分数之间有较大差距[例如,图11(i) - (k)中的“暴乱”和“爆炸”事件]。我们的学生模型还能过滤掉正常事件中的波动误报[图11(l)]。这些定性结果证实,从多模态教师网络在表示层和对数几率层蒸馏出的特权知识,能够提升学生网络在弱监督视频异常检测(WS - VAD)任务中的性能。
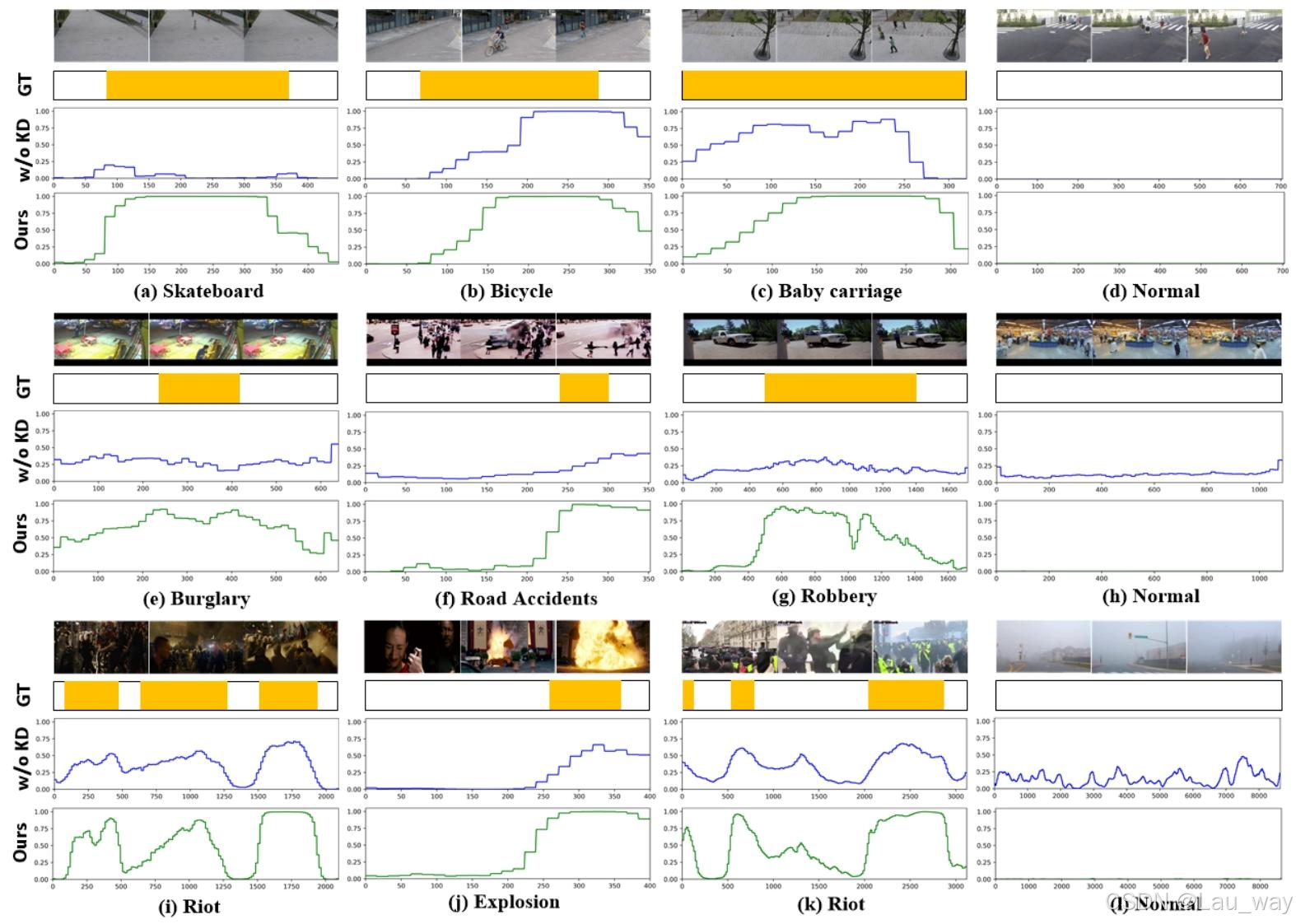
图11. 由未使用知识蒸馏(KD)训练的普通基线模型(无KD)和本文提出的学生模型(我们的模型)在上海科技大学数据集[(a) - (d)]、UCF - Crime数据集[(e) - (h)]以及XD - Violence数据集[(i) - (l)]上预测的视频异常检测(VAD)结果可视化。“GT”表示帧级真实分数。(a)滑板。(b)自行车。(c)婴儿车。(d)正常。(e)入室盗窃。(f)道路事故。(g)抢劫。(h)和(l)正常。(i)和(k)暴乱。(j)爆炸。
如图12所示,我们进一步可视化了通过在不同级别进行特权知识蒸馏(privileged KD)训练得到的学生模型的视频异常检测(VAD)结果。两个基线“无表示蒸馏(w/o RD)”和“无对数几率蒸馏(w/o LD)”分别表示模型在训练时未使用表示层(即\(L_{BSF}\)和\(L_{d}^{ST}\) )和对数几率层(即\(L_{SL}\)和\(L_{CLS}\) )蒸馏损失项。尽管基线“无对数几率蒸馏(w/o LD)”在检测“爆炸”和“打斗”等异常事件时表现出一定的置信度,但由于缺乏足够的语义线索,它在正常部分会导致相对较高的误报[例如,图12(b) - (d)]。由于没有蒸馏细粒度的表示,基线“无表示蒸馏(w/o RD)”只能在长未修剪视频中定位显著的异常片段,这通常会导致异常检测结果不完整[例如,图12(a)和(d)]。通过同时利用表示层知识蒸馏和对数几率层知识蒸馏,本文提出的学生检测器能够准确地定位异常事件的时间边界[例如,图12(c)],并抑制正常片段上的响应[例如,图12(b)]。
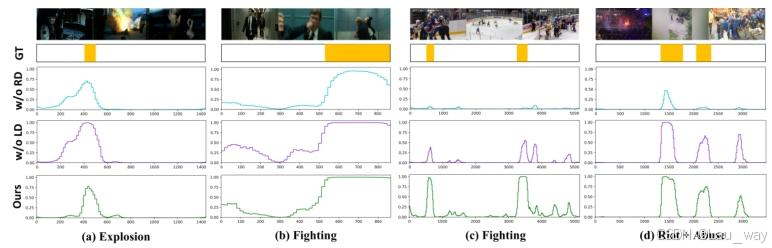
图12. 我们的学生模型在XD - Violence数据集上,使用不同蒸馏损失函数训练后得到的视频异常检测(VAD)结果可视化。“w/o RD”和“w/o LD”分别表示未考虑表示层蒸馏和对数几率层蒸馏的基线模型。“GT”表示帧级真实分数。(a)爆炸。(b)和(c)打斗。(d)暴乱+辱骂。
V. CONCLUSION
在本文中,我们提出了一种特权知识蒸馏(KD)框架,用于在弱监督设置下训练高效的视频异常检测器。该框架利用额外模态提供的互补信息,而在推理时仅以单模态作为输入。为实现这一目标,我们首先提出了一种跨模态交互学习策略和一种 “与” 损失(AND loss),它们分别通过滤除与任务无关的冗余信息以及学习可分离的异常和正常表示,助力构建强大的多模态教师网络。接着,我们设计了多种蒸馏损失函数,以片段到视频的方式,将表示层和对数几率层的特权知识,从训练良好的多模态教师网络提炼到单模态学生网络。在三个公共数据集上的大量评估结果表明,经过训练的单模态学生模型借助特权模态得到增强,在保持实时处理速度的同时,性能得到持续提升。未来,我们将探索把所提出的跨模态知识蒸馏框架推广到其他与弱监督视频相关的任务,如时序动作定位(TAL)。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)