论文阅读: Game-theoretic LLM: Agent Workflow for Negotiation Games
LLM的一个应用前景是去进行战略决策,而LLM因为幻觉以及本身能力的原因,决策会偏离理性。在博弈论框架的研究下,面临的情况是不确定性和不完全信息。构建workflow在很多方面会去提升agent在复杂交互场景下的表现。LLM的3个应用推理(planning)、行动(acting)、决策(decision-making)。
目录
一、整体说明
这是一篇使用LLM-based Agent进行game theory实验的论文。主要的新内容是,构建了workflow,研究agent在谈判情况下,对于Deal or Not Deal实验的表现。
二、具体解读
1、作者

2、问题介绍
LLM的一个应用前景是去进行战略决策,而LLM因为幻觉以及本身能力的原因,决策会偏离理性。在博弈论框架的研究下,面临的情况是不确定性和不完全信息。构建workflow在很多方面会去提升agent在复杂交互场景下的表现。
LLM的3个应用推理(planning)、行动(acting)、决策(decision-making)。进阶agent的3个应用,自动谈判(automated negotiations)、经济建模(economic modeling)、合作问题解决(collaborative problem-solving)。
未解决的问题,博弈论战略环境下的理性行为能力。博弈论有更好的对于战略评估的方法,更适合研究战略问题。但是,LLM现有问题,无法分析复杂问题,对于噪声和不确定性缺乏稳定性。
改进方法:
- Dominant Strategy Search. 确定对手的行为确定自己的回报。
- Backward Induction. 反向推理,博弈论的经典方法。
- Bayesian Belief Updating. agent通过观察完善对于其他玩家的信念。
3、相关工作
关于LLM结合game theory的研究,自2023年开始就大规模出现。很多研究是构建一个平台,然后观察LLM的反应。常见的一个现象是,LLM会出现利他(altruistic)和顺从(submissive),从而导致次优行为的出现。另外,常见实验结果中,LLM普遍对于数字扰动的表现不佳。
有很多工作是构建传统game theory中常见的实验,通过模拟来收集结果并进行评估。包括,Battle of Sexes, Prisoner’s Dilemma, Rock-Paper-Scissors, Stag Hunt, Ultimatum Game, Deal-or-No-Deal, Multi-Round Auction, Schedule-a-Meeting, Trading Fruit, Public Debate, Avalon, Pokémon, Chess and Bargaining. 这些论文的数据在正式写论文的时候可以进行参考。
基于LLM构建的workflow还会出现的问题有,输出的随机性而导致的不可靠性,错误在推理过程中的传播。因此,一个自然的做法是,认为设置行为算法,从而运行LLM对于信息进行额外的控制和分析,进而增强LLM解决问题的能力。
4、必要定义
实验需要进行的基础:rule, payoff。这是一场实验的配置,agent需要理解规则,然后根据规则做出行动(action)。博弈论实验有个好处是,可以通过分析均衡(analytical equilibria),来指导agent表现的优化。
实验的基础自然是完全信息博弈,只要有足够的指导,那么LLM应该根据已有信息做出理性的决策。而常见的情况是不完全信息博弈,即存在agent并不知道完整信息的payoff或者action。那么,agent需要在缺失信息的情况下在不确定性下制定策略。可以用的方法有使用Bayesian principle来不断更新相关的belief。
实验的顺序也有2种,1是同时进行,即所有action是同时进行的,这个通常agent是独立完成,无法与其他agent进行协调。2是顺序进行,agent对于其他agent的行为有一定的了解,然后做出自己的action。可以用的方法有,游戏树和反向归纳。
基础理论的定义都是基于payoff matrix,在这种描述下追求nash equilibrium和pareto optimality。
5、完全信息
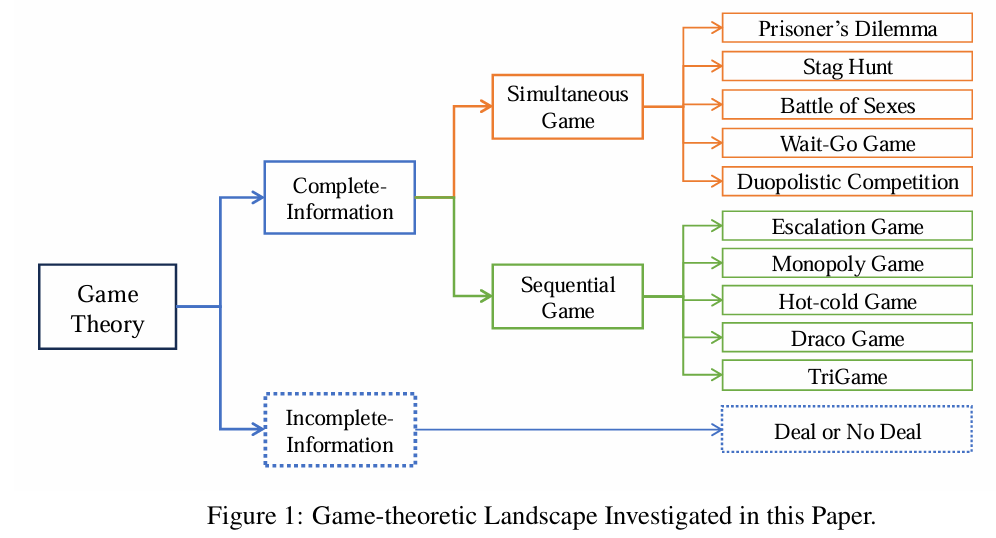
完全信息的条件下,相关的实验很适合评价一个LLM是否能够作为理性的决策者。实验为2大类,同步or顺序。同步实验又分为2大类,是否需要协调。
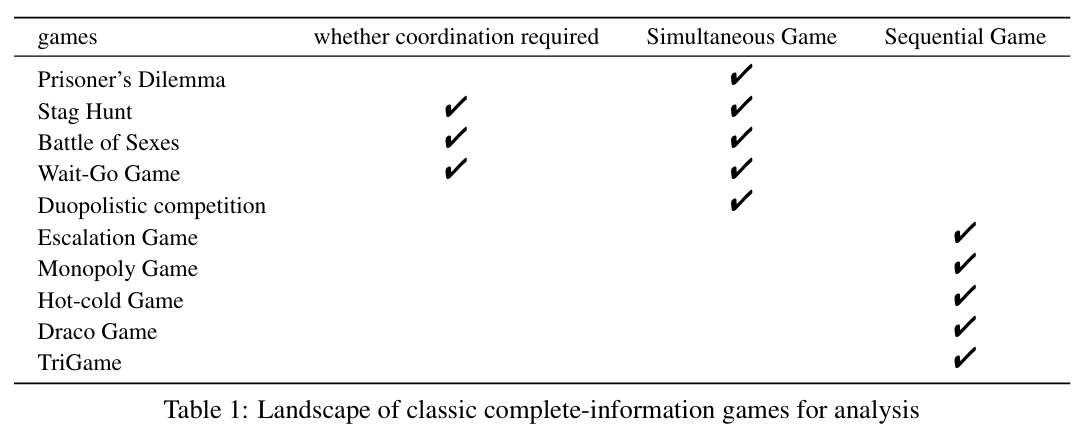
以上是经典的博弈论实验。通常而言,同时游戏用matrix表示payoff,而顺序游戏用tree表示payoff。
实验结果评价有2个方式,是否达到nash equilibrium以及进一步的是否是pareto optimal nash equilibrium。实验方法有2种,即是否agent之间进行协调。
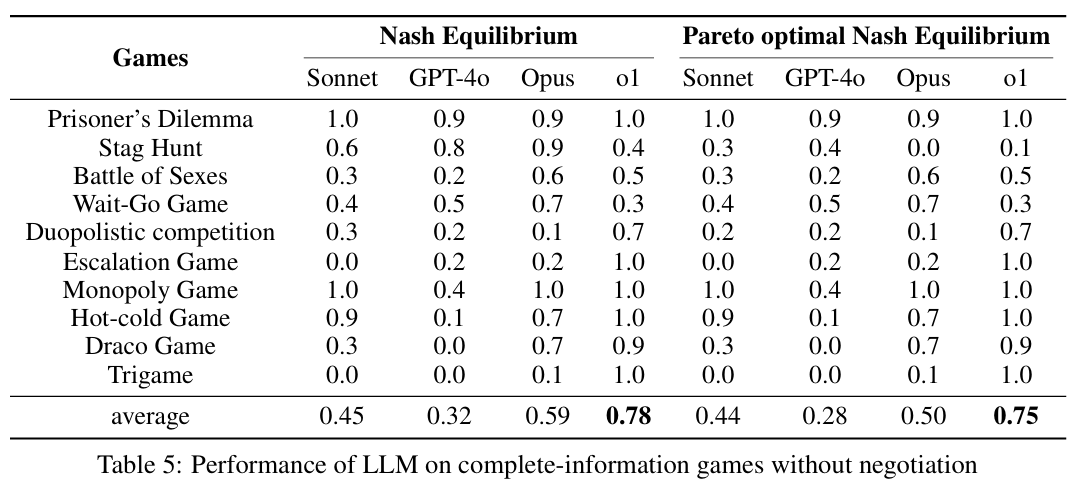
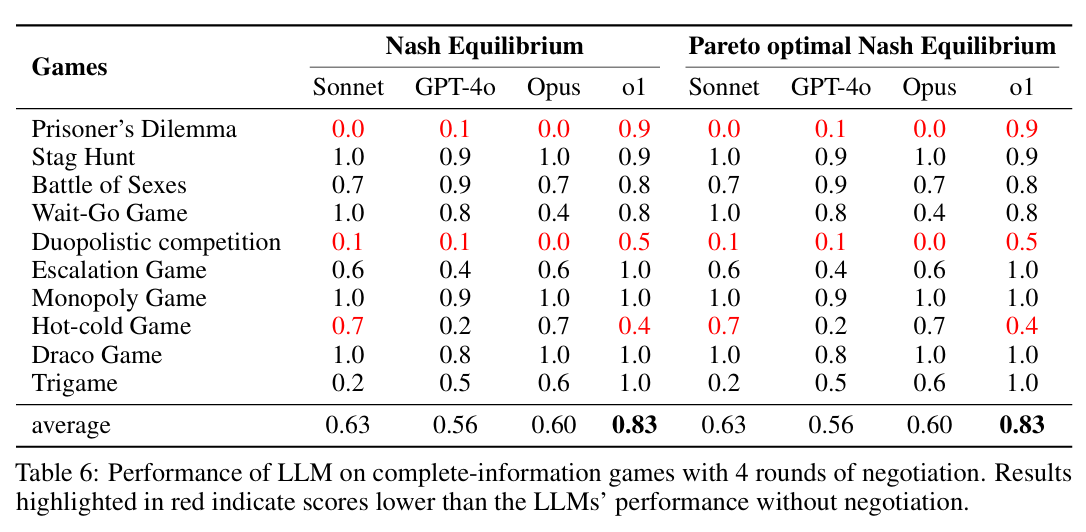
即使是类似思考方式的实验,LLM的表现也很不相同。并且,有一点特殊的地方在于,对于有些实验,整体均衡的表现会在agent之间进行协调之后变差。这种情况下,谈判的过程破坏原本的均衡,尤其是一些情况下将pareto optimal nash equilibrium降低为非最优的nash equilibrium。
这种情况下,一个改进是对于agent进行指导,增强其选择最佳策略以及保持稳健理性。
(a)同步游戏
条件推理,生成思维链,并将其总结为一个整体的策略。
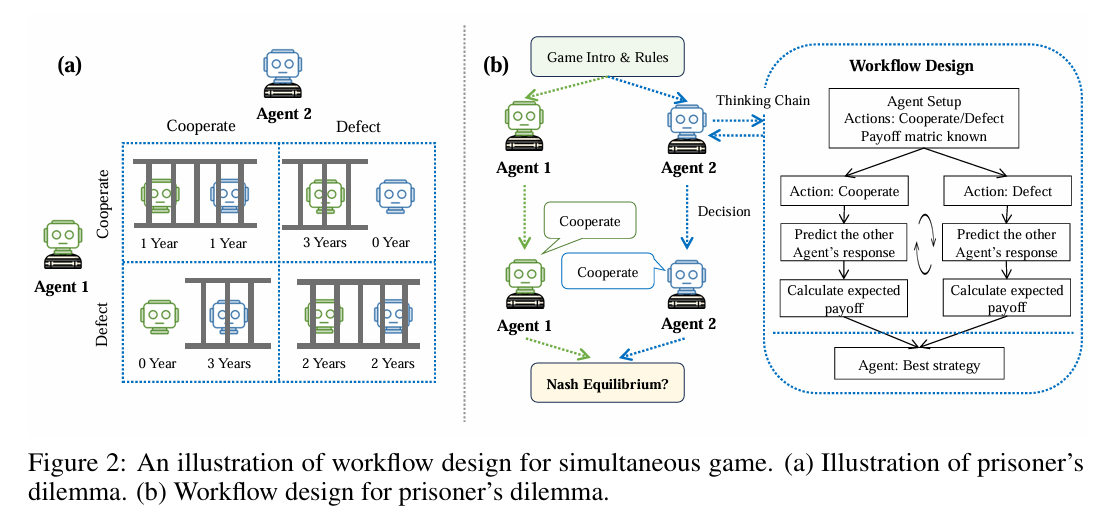
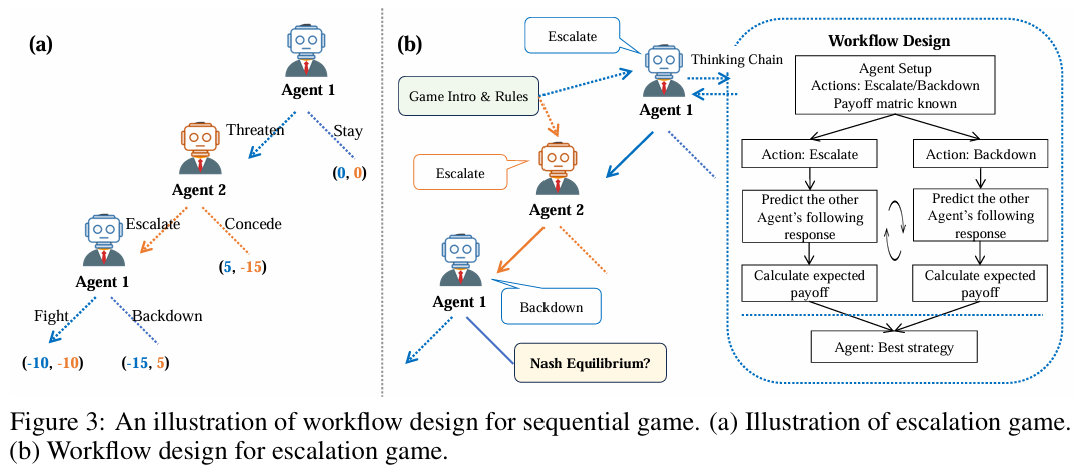
(b)顺序游戏
向后归纳,从头到尾分析,考虑当前行动对于未来的影响。
在使用了构建后的workflow,不同的LLM的表现如下:
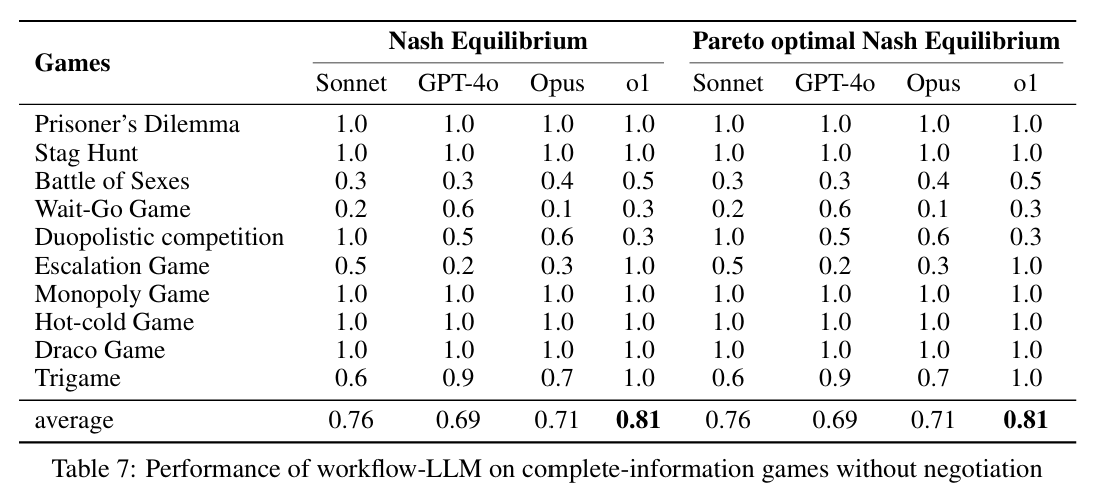
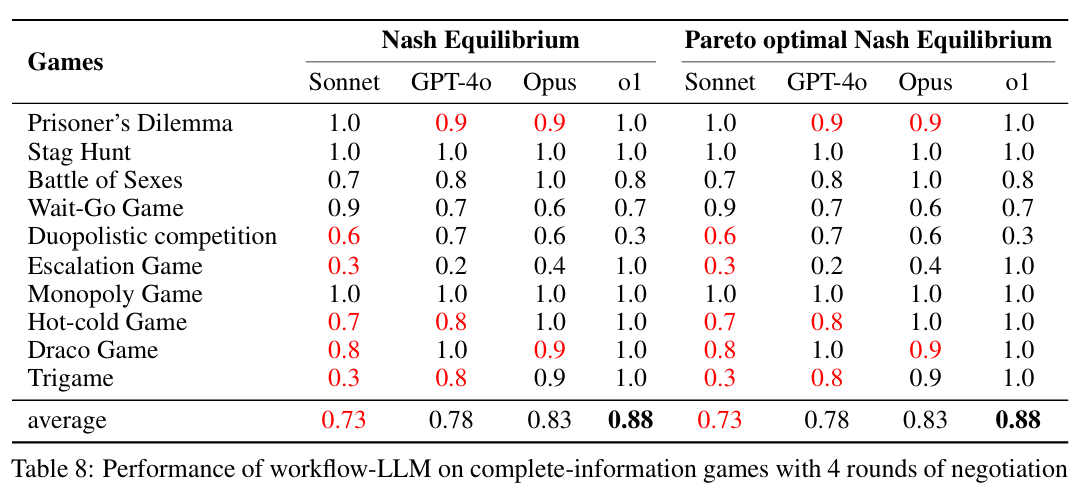
这2种游戏的具体策略的形成方式依然是CoT,区别只是,LLM出发的payoff的数据结构不同,但是搜索方式都是尝试性选择,然后思考下一步对手的选择,最后到达均衡进行判断和实际决策。
即使构建了workflow实现了更好的结果,但是LLM依然存在的问题有:
- 本身复杂战略推理能力。
- 计算能力。
- 推理结果的遵循。
6、不完全信息
不完全信息是更加现实的场景,但是也更加复杂。通常情况下,不完全信息和资源分配相关,环境中同时存在私有和共享资源,同时共享资源与多个玩家相关。本文研究的问题是"Deal or Not Deal",研究的规模是2个agent,3个交易对象。"Deal or Not Deal"相关的研究较多,这是个经典问题,并且有大量相关的数据集可以使用。而只研究2个agent的情况是这篇论文自身的限制。
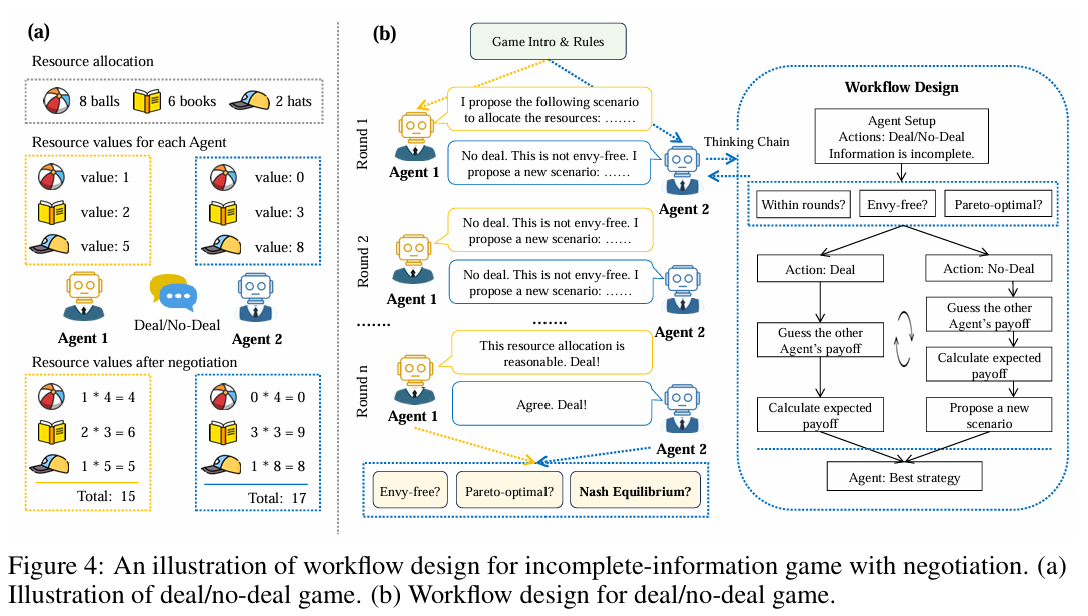
"Deal or Not Deal"容易陷入最后通牒博弈的nash equilibrium,这篇论文中的实验使用了额外的设置保证额外的公平性。
相关的,完全信息博弈通常已有充足的研究和足够好的设计来,而不完全信息博弈缺乏标准的解决方案。因此,这部分的研究是该文章自行设计的算法。
(a)算法设计
首先,每个agent都有自己的估值的随机向量。每个agent只知道自己的估值,而缺乏其他agent的估值,一个目标便是去估计其他agent的估值。每个agent最终获得的效用,就是分配方案和各自实际估值两个向量的点积。
对于每轮谈判,如果一个agent拒绝,那么他就需要在下一轮中提出更好的分配方案,能够同时提高双方的效用。每一轮提案被拒绝,使用bayesian update来更新对于全体空间中所有估值的随机向量。当然,这样的方法显然对于初始的估值很敏感,并且对于欺骗的现象不稳定。
(b)实验
谈判的难度与玩家之间的估值相似程度有关,这里的定义基于L1范数。
有现实人类的实验结果为:
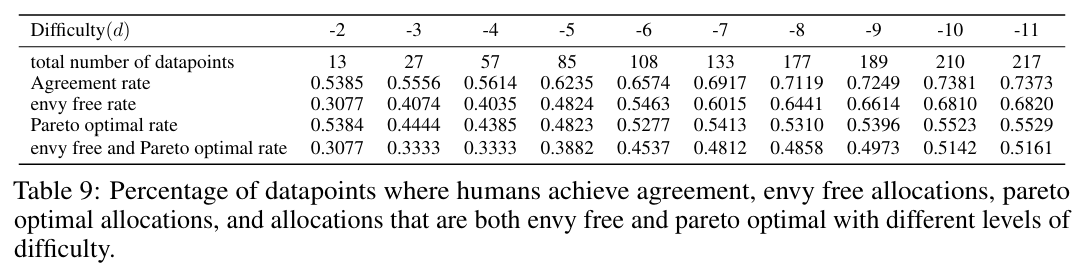
相似程度越高,谈判成功比例越低,无羡慕率越低,而pareto optimal rate变化很小。也就是说,差异越大,谈判成功难度越小。
相比较人类实验,使用LLM进行实验可以获得和分析额外的字段,为达成协议或终止的轮数、预期和实际获得的效用、系统一共获得的效用。
2个agent都没有使用workflow:
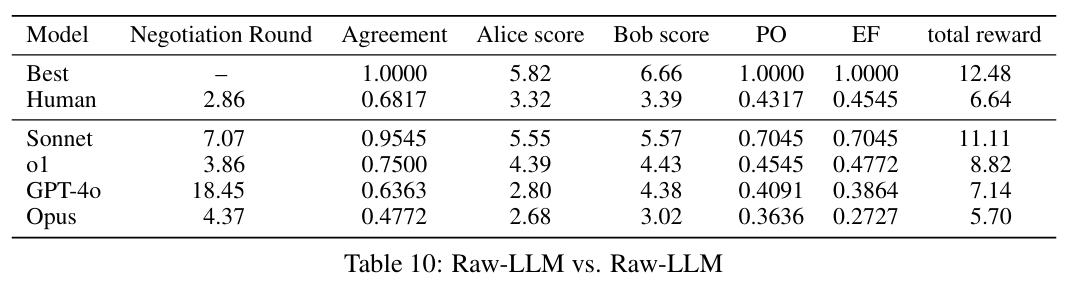

即使在没有使用设计的workflow的情况下,LLM的实验结果整体而言比人类要好很多。但是,LLM对于temperature的反应很敏感。
2个agent都使用workflow:


在使用了workflow之后,LLM的表现要更好,协商的轮数显著降低,同时到达的均衡也更好。同时,LLM对于temperature的反应很稳定。
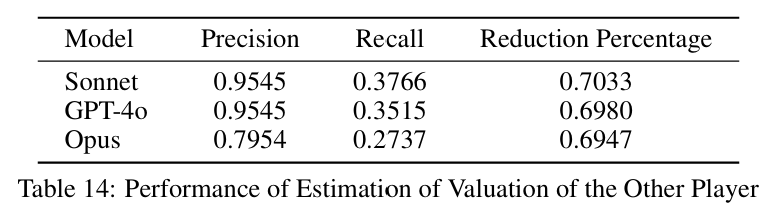
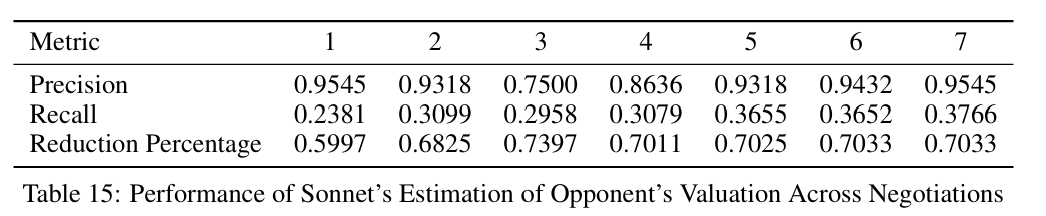

论文额外进行了数值分析,说明了更好的协商结果是通过更精确的估值来实现的。
1个agent使用workflow:


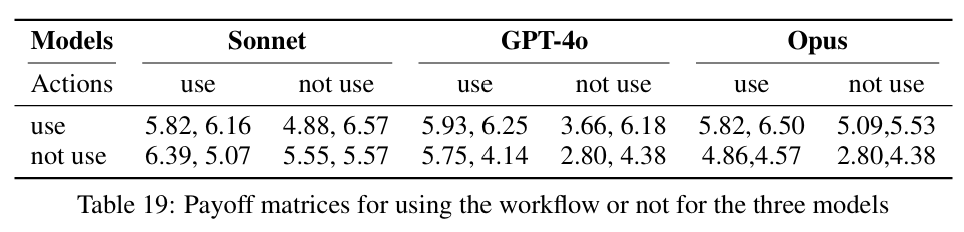
而当仅一个agent使用workflow时,没使用workflow的agent的收益反而会更好。相关的分析结果是,这里提出的workflow是基于合作的均衡。在双方都理性的情况下,workflow是合理的。而未使用workflow的agent的更好的表现来自于对于使用workflow的agent的利用。
7、LLM理性
考察LLM是否理性的角度有:
- 不同payoff matrix中的选择是否一致。
- system prompt中人格指定的影响。
- 多轮对话的演变。
(a)payoff matrix值变动

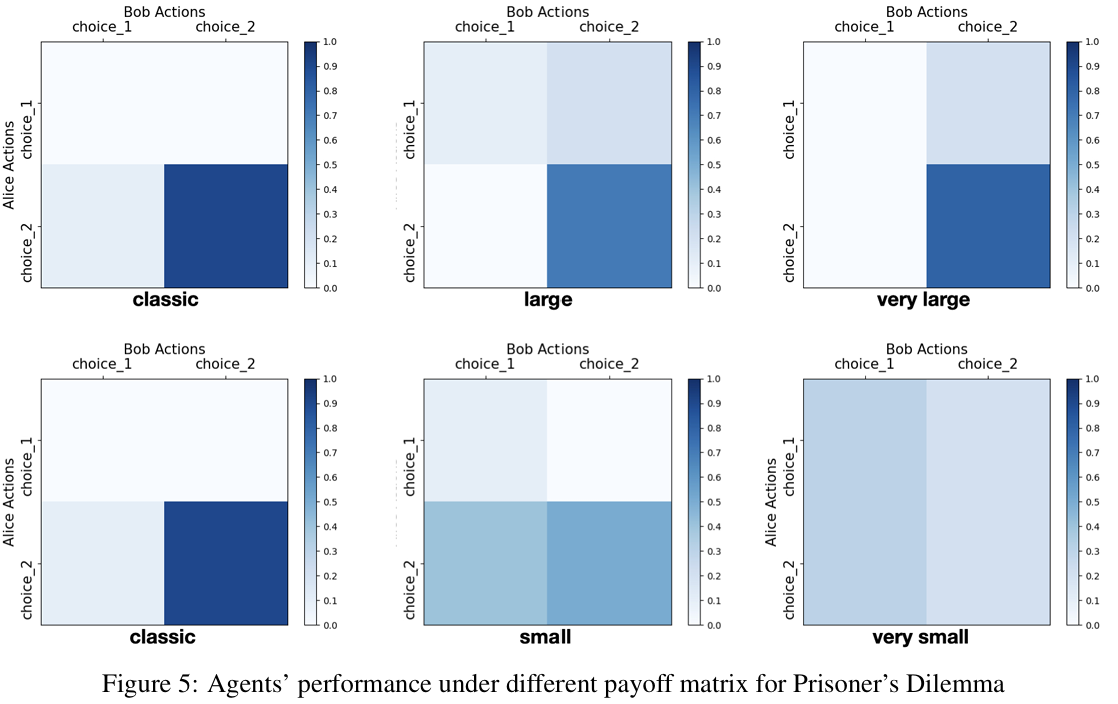
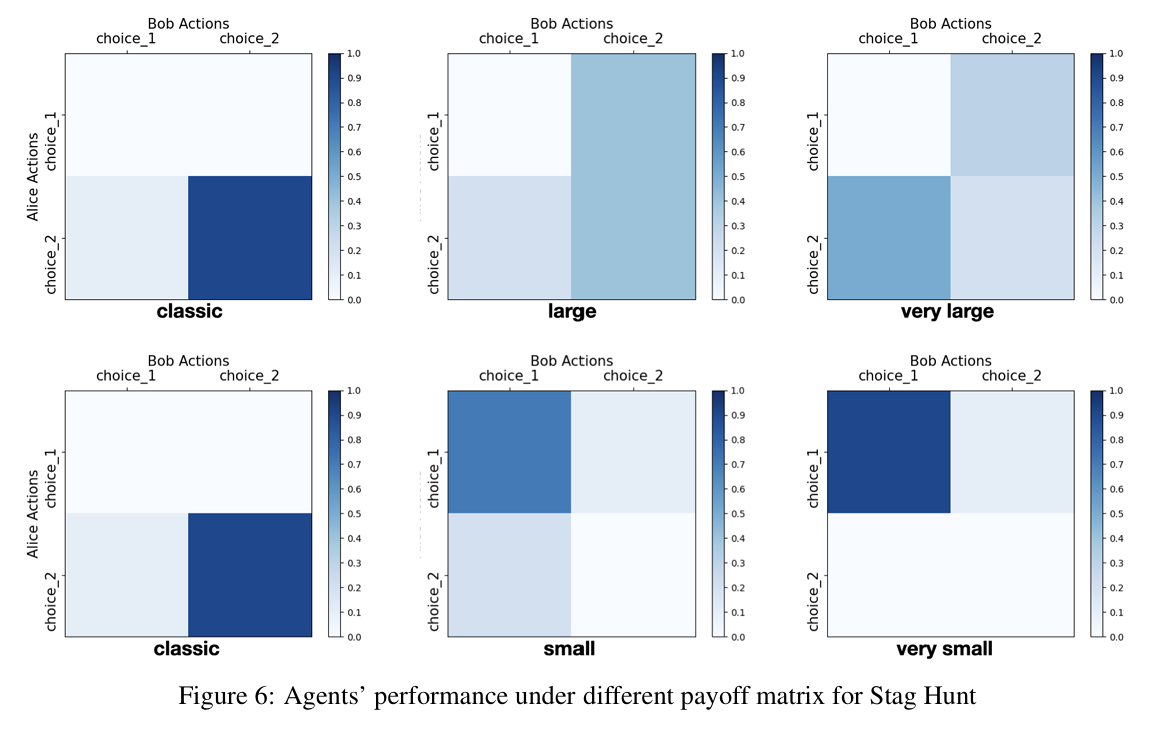
payoff matrix中的值变动,可是均衡不变时,LLM实际上并不能做出一致的选择。LLM在这方面的理性有限。
(b)人格变动
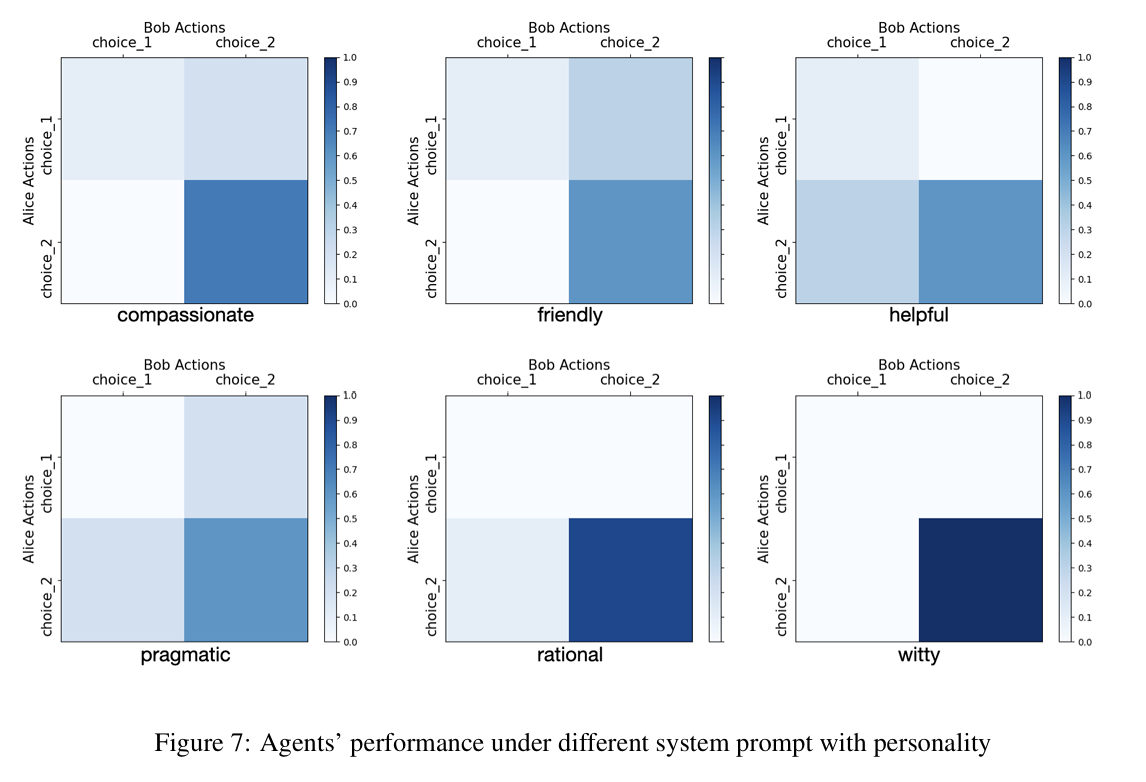
当使用不同的人格指定的时候,LLM的选择也会发生变化。LLm在这方面的理性有限。
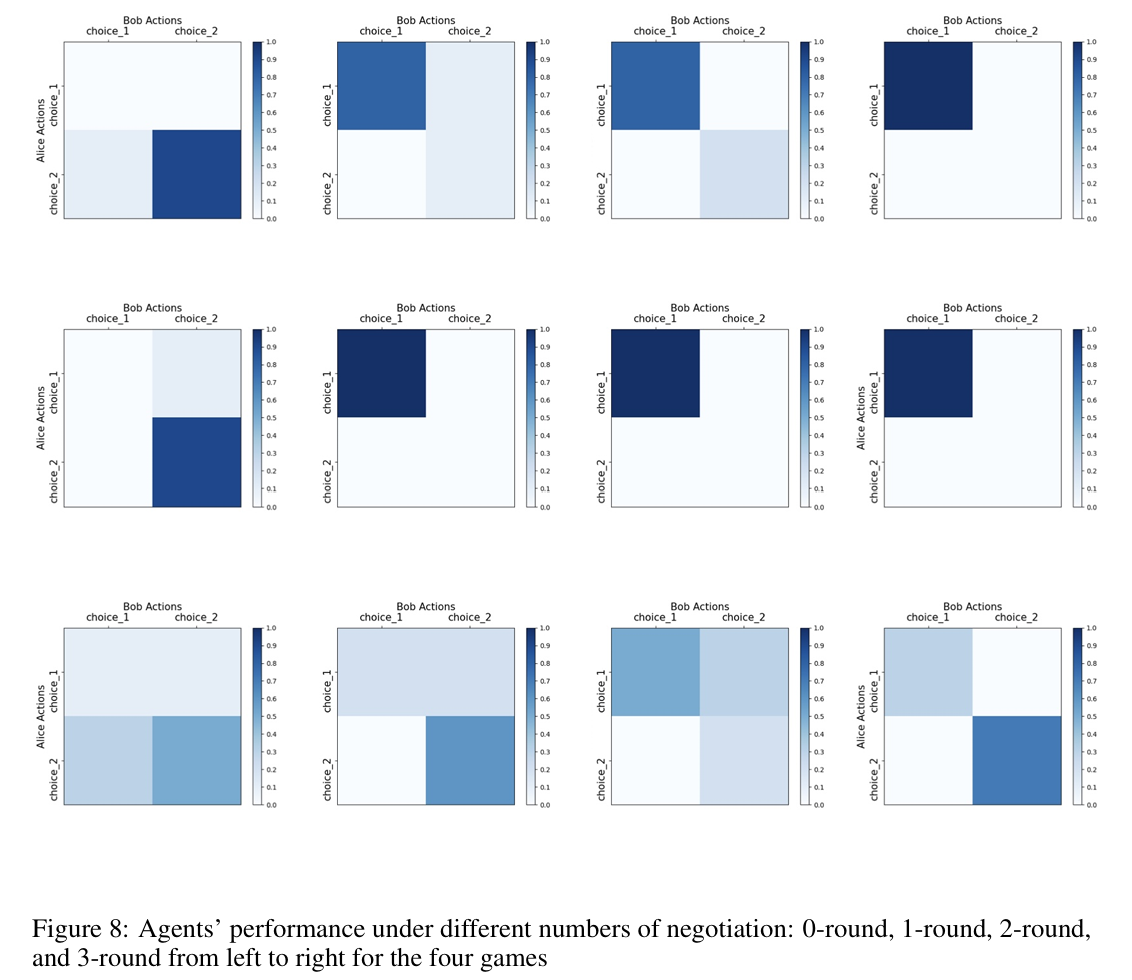
(c)谈判的影响

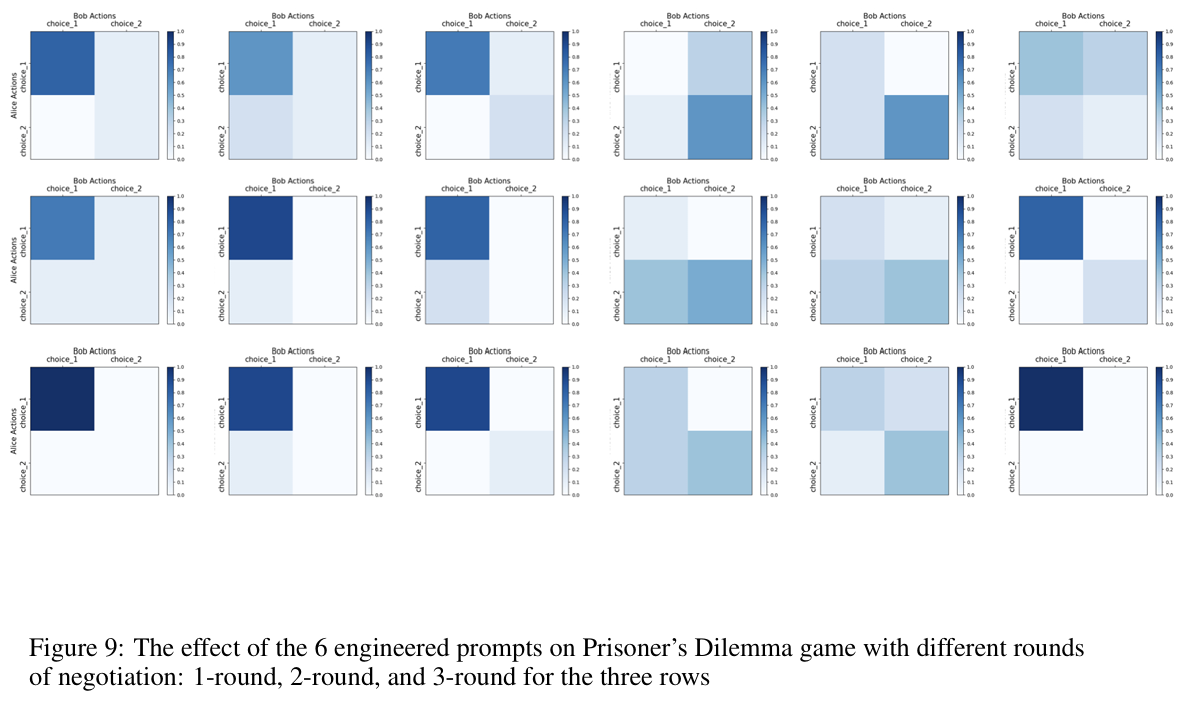
在每轮告知LLM该如何做决策的方式,不同LLM和不同实验场景因具体情况而定。
(d)与人类非理性对比
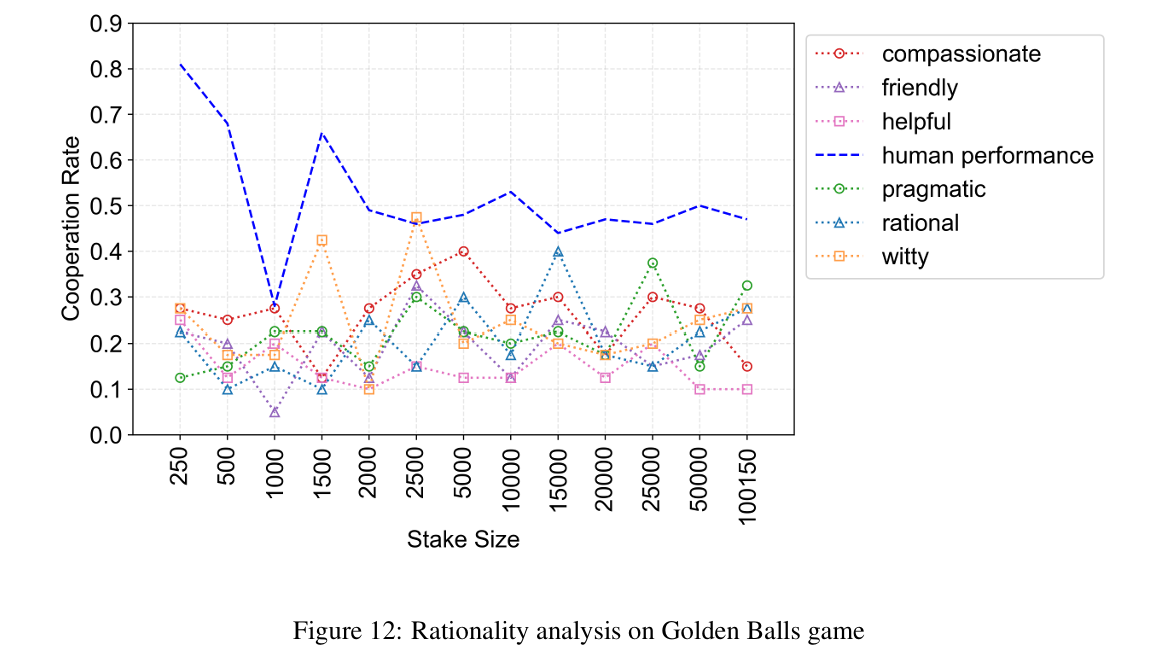
一个与前面实验都不相关的实验,同一个实验,数值发生变动,人类会有很大变化,而LLM反应很低。这说明LLM的非理性和人类不一样。
三、总结
我看这篇论文前有2个预期,1是想了解不完全信息的场景,2是想知道如何对于大规模multi-agent的实验进行项目管理。可是,这篇论文不完全信息的场景实际指的是Deal or Not Deal这一特定的场景,并且很多设置也同样被简化了。我查看了论文的源代码,整个实验居然没有使用multi-agent框架,从纯调API写起,大概写了5000行以上的代码。这对于独立科研者来讲,是很难做到的。这也是大概为什么,该论文的所有实验都是2个agent的情况。
整体而言,这篇论文作为综述是非常好的。对于完全信息的场景,论文中的研究非常透彻。我在此之前自己也做过足够的实验,这个方向没有继续深入研究的必要。论文中提出了很多的理论研究相关的论文,关于Deal or Not Deal以及其他相关的数据集也有很多,这个可以简化很多继续的工作。论文中进行的实验只是初步尝试,我认为这里有2个值得继续的方向,1是更高效的workflow,2是对于谈判的深入研究。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)