Vision-text Enhancement Network For Weakly Supervised Video Anomaly Detection
近期的视觉-语言预训练模型ImageBind在广泛的视觉任务中取得了显著成功,在视觉或文本表示中,展示了其在不同模态间联合嵌入空间的卓越能力。如何利用这样一个强大的模型进行弱监督视频异常检测(WSVAD)是一个值得研究的问题。以往的大多数工作仅使用单一的视觉模态,并将异常检测定义为简单的视频分类任务。然而,这类解决方案忽略了数据集中的文本信息以及异常事件的定位问题。为解决这些问题,本文提出了视觉-

ICASSP 2025(CCF-B)
https://ieeexplore.ieee.org/abstract/document/10890027
摘要
近期的视觉-语言预训练模型ImageBind在广泛的视觉任务中取得了显著成功,在视觉或文本表示中,展示了其在不同模态间联合嵌入空间的卓越能力。如何利用这样一个强大的模型进行弱监督视频异常检测(WSVAD)是一个值得研究的问题。以往的大多数工作仅使用单一的视觉模态,并将异常检测定义为简单的视频分类任务。然而,这类解决方案忽略了数据集中的文本信息以及异常事件的定位问题。为解决这些问题,本文提出了视觉-文本增强网络(VTENet)。对于文本特征,它直接采用冻结的ImageBind模型,无需任何微调过程。对于视频特征,它通过所提出的时序增强图卷积模块(TGC)来增强视觉特征表示。VTENet充分利用视觉与文本之间的关联,包含两个分支以完成粗粒度和细粒度的视频异常检测。其中一个分支利用视觉特征进行粗粒度二分类,而另一个分支则将文本特征与整个数据集中的视频特征进行比较,以完成细粒度的视频异常检测。在XD-Violence和UCF-Crime数据集上的大量实验证明了所提方法在粗粒度和细粒度任务上的优越性。
I. INTRODUCTION
弱监督视频异常检测因其广泛的应用前景而受到越来越多的关注。其目标是在仅提供视频级标注的情况下,生成帧级的异常置信度。目前,有许多针对异常检测的弱监督工作[3] [4],其中大多数基于多示例学习(MIL)范式。具体而言,这些工作首先使用预训练模型(如C3D [23]、VIT [18] [10])提取帧级视觉特征,然后将提取的特征送入基于MIL的二分类器中训练模型。这些二分类器将视频的每个片段视为一个实例,并利用排序损失来最大化异常视频与正常视频异常分数之间的间隔。最后一步是基于预测的异常置信度(粗粒度)来检测异常事件。然而,这种范式限制了其实际应用。一方面,它是为视频分类任务而设计的,忽略了异常事件的定位,且无法将算法泛化到未修剪视频中的暴力检测。不仅如此,大多数先前的工作都忽略了多模态信息的使用,例如视觉与文本之间的跨模态关联。
在这项工作中,本文提出了一种基于ImageBind的弱监督视频异常检测(WSVAD)新范式,命名为VTENet。如图1所示,VTENet采用双分支结构设计,其中分支利用视觉特征进行粗粒度二分类,而分支则同时利用视觉和文本特征进行细粒度分类和异常事件定位。具体来说,对于分支,本文提出了一种时序增强图卷积模块(TGC),使其能够有效地捕获视频片段之间的时序依赖关系。对于分支,VTENet利用预训练模型ImageBind [15]的文本编码器来获取视频标签的文本查询。之后,VTENet将文本查询与数据集中的所有视频进行比较,以挖掘最佳匹配片段,同时忽略不相关的部分。这样一来,所有视频中相同类别的片段和文本查询会相互拉近,而不同类别的则被推远,从而增强了类间差异,提高了分类结果。
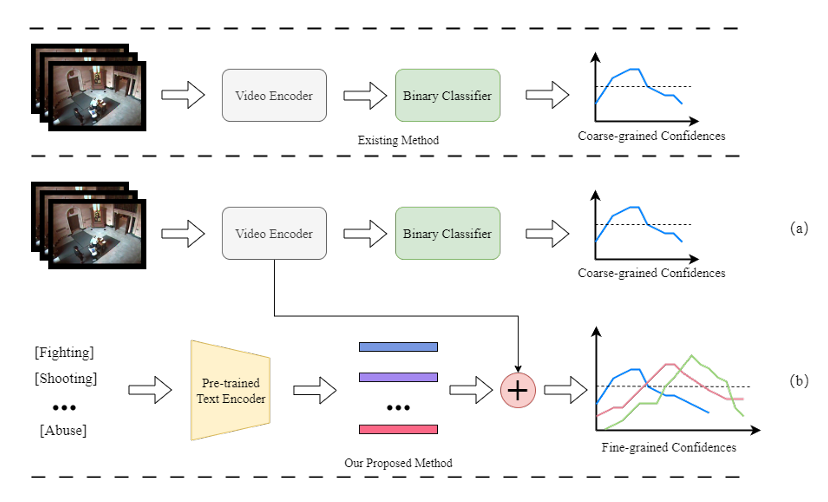
图 1. 本文提出的框架与现有WSVAD方法的比较。
综上所述,本文的主要贡献如下:
• 据我们所知,VTENet 是第一种利用 ImageBind 的文本知识来提升弱监督视频异常检测(WSVAD)性能的方法。通过采用双分支结构,VTENet 实现了粗粒度和细粒度的 WSVAD。
• 本文提出了一种时序增强图卷积模块,用于解决初始视觉特征时序建模能力不足的问题。所提出的特征增强模块可以利用不同感受野尺寸下的时序依赖关系。
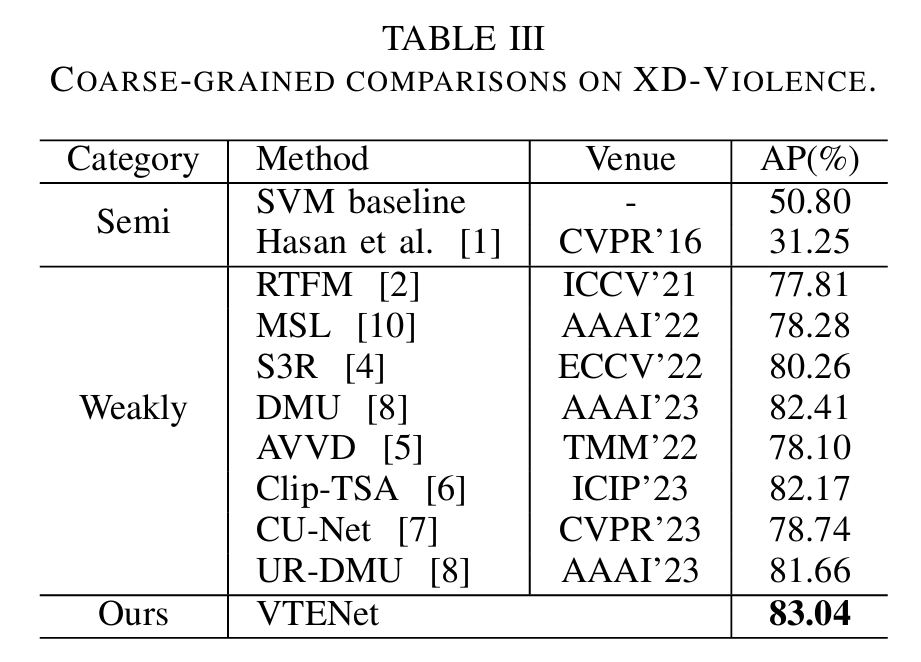
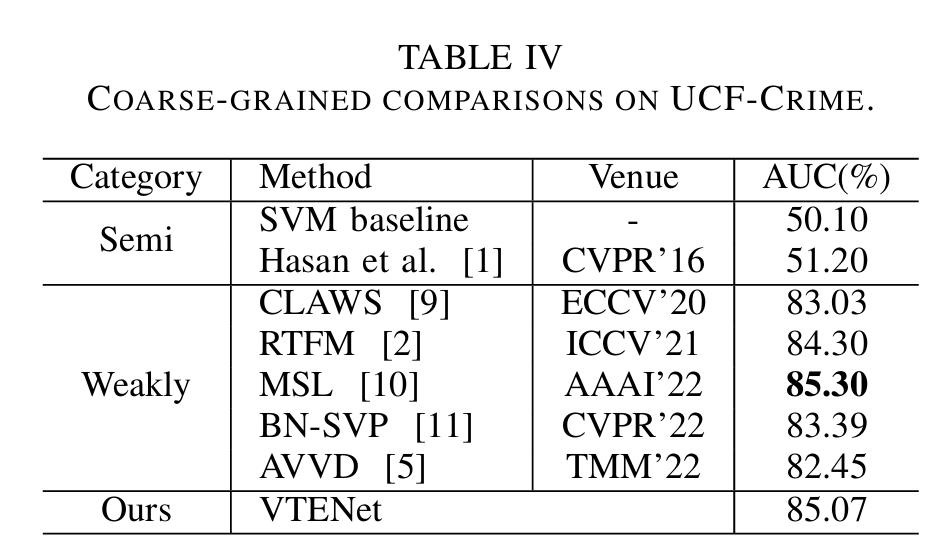
• 本文在两个大型流行基准数据集(XD-Violence 和 UCF-Crime)上验证了 VTENet 的强大功能和有效性,在细粒度任务上取得了最先进的性能,在粗粒度任务上也取得了相当的结果。
II. RELATED WORK
A. Vision-language Pre-training
近年来,视觉-语言预训练 [25] [24] [17] 取得了显著进展。作为一项代表性工作,CLIP [16] 在一系列视觉-语言下游任务上表现出卓越的性能。CLIP4Clip [19] 将CLIP模型的知识迁移到视频-文本检索任务中,一些工作 [20] 尝试利用CLIP进行视频识别,此外,CLIP也被用于处理更复杂的视频动作定位任务 [22] [21]。近期的视觉-语言预训练模型ImageBind [15] 展现出了更大的应用潜力。ImageBind 利用图像与其他多种模态(如文本、音频、深度和IMU)的配对数据来学习一个共享的表示空间。通过借助图像/视频模态,ImageBind 能够将其他模态的数据进行绑定。这使得ImageBind能够将文本嵌入到与其他模态(如图像)隐式对齐的空间中。与CLIP [16] 相比,ImageBind 极大地丰富了特征嵌入的类型,并展示了强大的表示学习能力以及视觉与语言之间的关联。本文深入探讨了如何有效地将ImageBind的预训练视觉-语言知识从图像级别适配到视频级别的下游WSVAD任务中。
III. METHOD
A. Method Overview
如图2所示,本文提出的VTENet由两个分支组成,它们分别完成粗粒度和细粒度的视频异常检测任务。对于视觉分支,原始的视觉特征被输入到时序增强图卷积模块中,其中采用了多层扩张卷积网络来扩大特征的感受野。之后,这些特征被输入到图卷积网络中,以更好地捕捉视觉特征的时序依赖关系。然后,增强后的视觉特征被输入到基于多示例学习(MIL)的二分类器中,该分类器预测粗粒度视频异常检测的置信度。受ImageBind的启发,视觉-语言分支利用ImageBind的文本编码器来提取视频标签特征。获得文本特征后,视频-文本匹配模块将文本查询与所有视频片段进行比较,生成查询响应以挖掘语义相关的视频片段。因此,它获得了异常事件的类别预测和定位预测。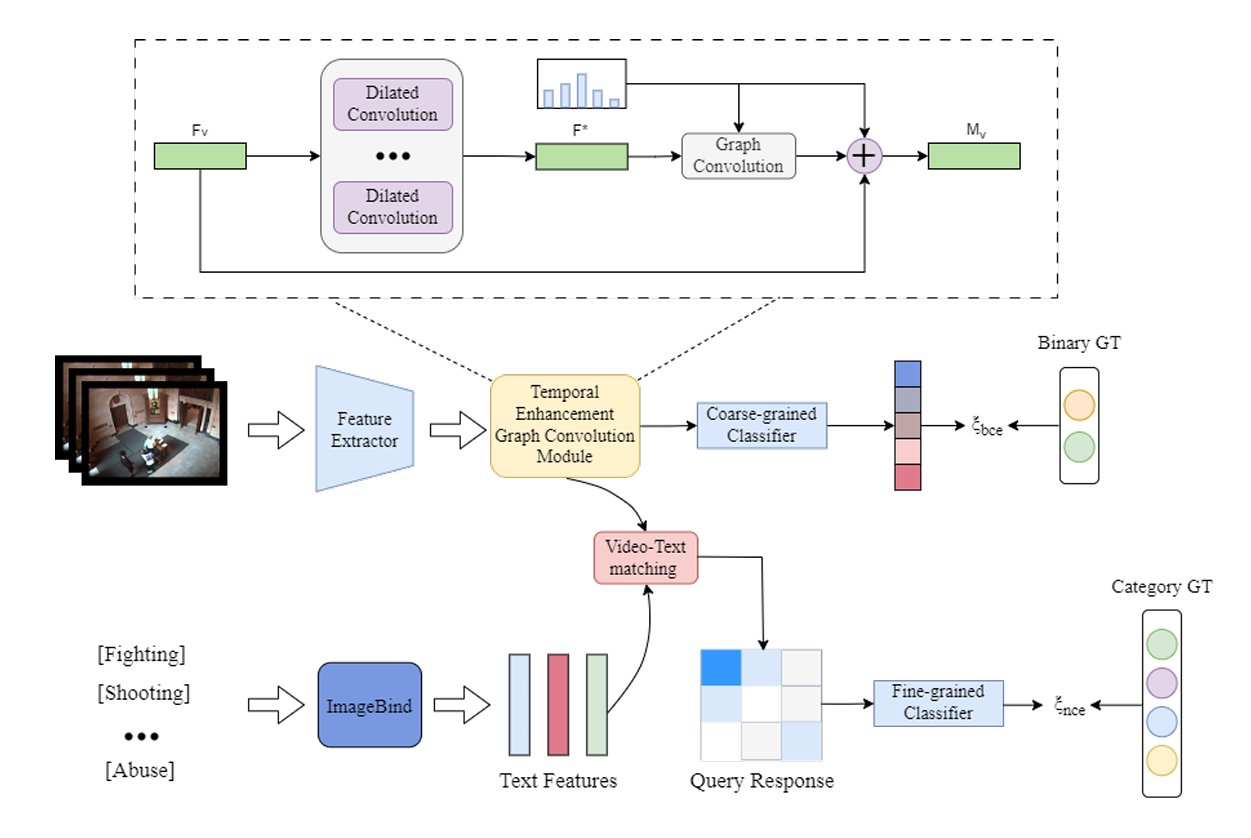
图 2. 本文提出的VTENet模型的整体框架。查询响应中的颜色深浅表示视频-文本匹配后视觉和文本之间的关联程度。
B. Visual Branch
通常,一个完整的动作实例跨越一个相对较长的时间窗口,而片段中的帧覆盖范围相对有限,不足以观察完整的动作实例。考虑到时序信息完整性在识别单个片段时的重要性 [8],我们采用时序增强图卷积模块来捕捉视觉特征的时序依赖关系。具体来说,通过使用多层扩张卷积网络,可以扩大特征的感受野,从而更好地反映片段间的长距离依赖关系,有利于模型充分学习时序信息。首先,该分支将初始视觉特征 FvF_vFv 输入到多层扩张卷积中并输出 Fv∗F^*_vFv∗。增强后的特征可以覆盖完整的动作片段,并观察动作的整个动态过程。该过程可表述如下:
Fv∗=S(ϕ(Fv))⊗Fv(1)F^*_v = S(\phi(F_v)) \otimes F_v \quad (1)Fv∗=S(ϕ(Fv))⊗Fv(1)
其中,ϕ\phiϕ 是多层扩张卷积网络,SSS 是 sigmoid 函数,⊗\otimes⊗ 表示逐元素乘法。
为了进一步捕获全局时序依赖关系,本研究在扩张卷积后引入了一个轻量级GCN模块。由于GCN在弱监督视频异常检测(WSVAD)中被广泛采用且性能已得到验证,它采用GCN从相对特征距离的角度来建模全局时序依赖关系。该模块基于片段之间的距离进行定义,片段间距离越远,分配的权重越大。这有助于相距较远的片段之间信息传递。该过程表示如下:
A=∑i=12[gelu(GCi(Fv∗W))](2)A = \sum_{i=1}^{2} [gelu(GC_i(F^*_v W))] \quad (2)A=i=1∑2[gelu(GCi(Fv∗W))](2)
其中 WWW 是可学习权重,GCGCGC 是轻量级GCN模块。之后,通过全连接层 FCFCFC 获得最终的视觉特征。具体细节如下:
Mv=FC(τ∗Fv∗+γ∗A)(3)M_v = FC(\tau * F^*_v + \gamma * A) \quad (3)Mv=FC(τ∗Fv∗+γ∗A)(3)
其中 τ\tauτ 和 γ\gammaγ 是控制残差权重的超参数。
C. Vision-language Branch
在视觉-语言分支中,文本标签(例如,辱骂、暴乱、斗殴等)不再被编码为独热向量,相反,它们使用 ImageBind 的文本编码器被编码为类别嵌入。我们利用 ImageBind 的冻结的预训练文本编码器,因为文本编码器可以为视频异常检测提供先验语言知识,其表示如下:
Ft=emb(Lq)(4)F_t = \text{emb}(L_q) \quad (4)Ft=emb(Lq)(4)
其中,emb 指的是视觉-语言预训练模型 ImageBind 的文本编码器,LqL_qLq 代表视频标签列表,而 qqq 表示类别数量。
视频-文本特征匹配模块用于匹配语义相关的文本查询和视频片段特征,获得对齐映射MMM。具体来说,我们对视频嵌入特征MvM_vMv和文本查询FtF_tFt进行内积操作,生成片段级视频-文本相似度矩阵MMM。每个输入的文本标签代表一类异常事件,从而自然地实现细粒度视频异常检测。总而言之,可以描述如下:
M=einsum(Mv,Ft)(5)M = \text{einsum}(M_v, F_t) \quad (5)M=einsum(Mv,Ft)(5)
其中,einsum是用于计算内积的函数,它评估文本查询和视觉特征之间的相似性和相关性。
D. Loss Functions
对于视觉分支,本研究使用Top-K机制在异常和正常视频中选择K个高异常置信度作为视频级预测。然后,它使用视频级预测与真实标签之间的二元交叉熵来计算分类损失ζbce\zeta_{bce}ζbce。对于视觉-语言分支,本研究选择Top-K相似度并计算平均值,以衡量视频与当前类别之间的对齐程度。然后,它可以获得一个向量sss,表示视频与当前类别之间的对齐程度,从而与相应的文本查询具有最高的相似度。具体细节如下:
Pi=exp(si/α)∑jexp(sj/α)(6)P_i = \frac{\exp(s_i/\alpha)}{\sum_j \exp(s_j/\alpha)} \quad (6)Pi=∑jexp(sj/α)exp(si/α)(6)
其中,PiP_iPi是关于第iii类的预测,α\alphaα是用于缩放的温度超参数。最后,可以通过交叉熵计算对齐损失ζnce\zeta_{nce}ζnce。
IV. EXPERIMENTS
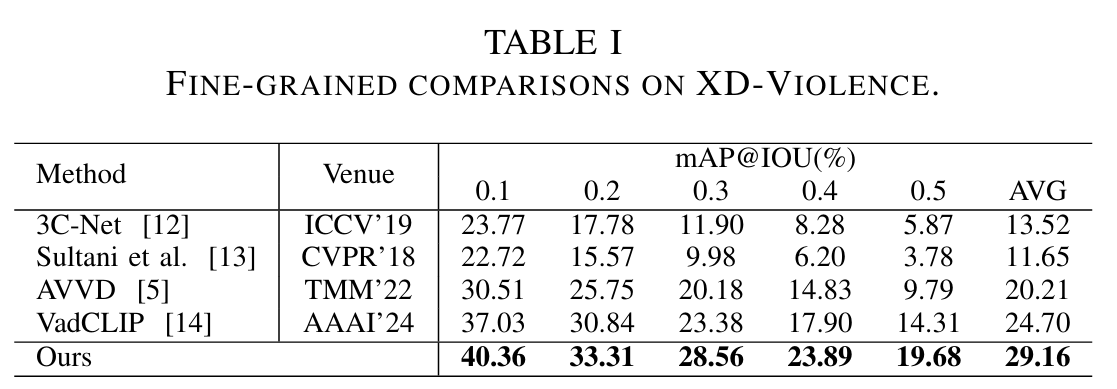
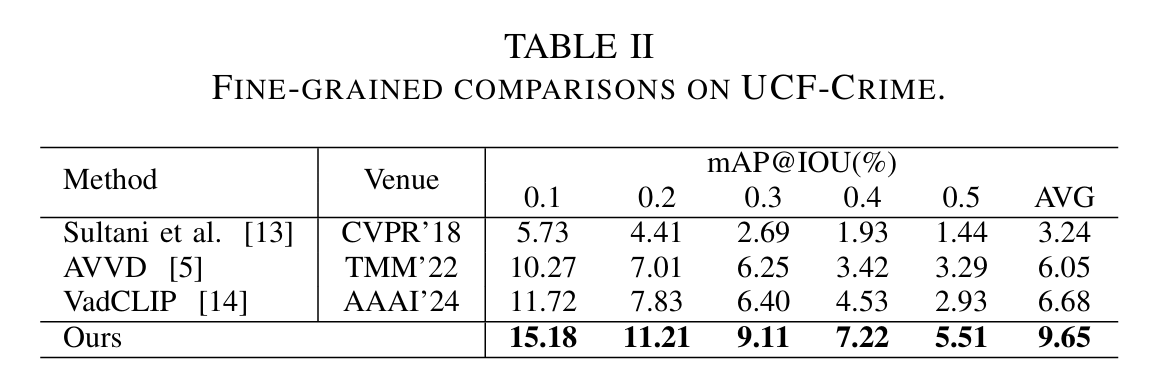
V. CONCLUSION
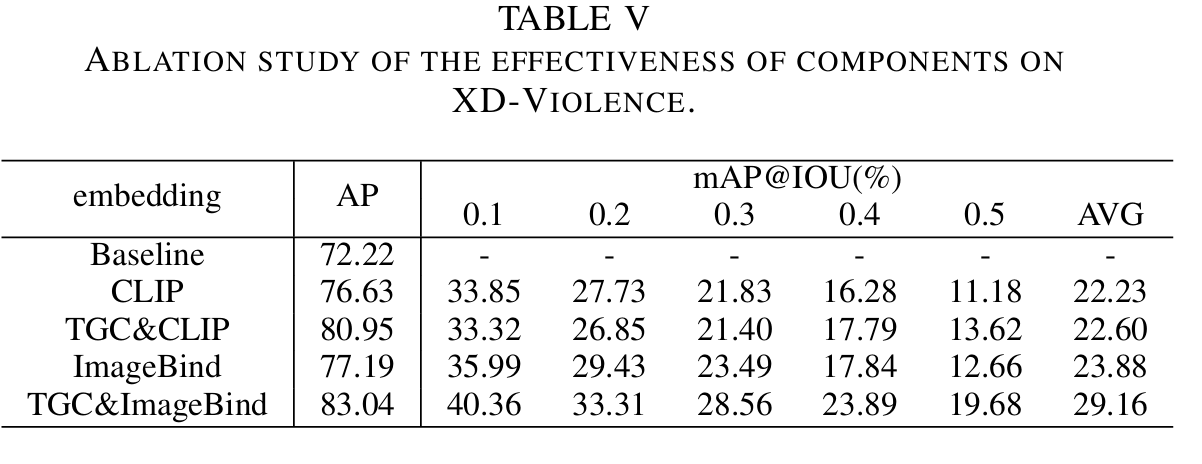
在这项工作中,我们提出了一种名为VTENet的弱监督视频异常检测方法。为了有效地利用视觉-语言关联,本文引入了时序增强图卷积模块,并首次采用了预训练模型ImageBind的语言知识来设计视觉-语言对齐,显著提升了模型的性能。本文通过在两个WSVAD基准数据集上进行大量的实验和消融研究,验证了VTENet的有效性。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)