英伟达开源基于Qwen2.5-Math-7B的数学和代码推理模型:AceReason-Nemotron-1.1-7B
AceReason-Nemotron 1.1-7B是一款通过监督微调(SFT)和强化学习(RL)协同训练的数学代码推理模型。基于Qwen2.5-Math-7B,该模型在数学(AIME)和代码(LCB)基准测试中表现优异,较前代模型提升显著:AIME2024提升10.6%,AIME2025提升16.4%,LCBv5提升8.4%。研究表明更强的SFT模型经过大规模RL训练后仍能保持性能优势。使用建议包
AceReason-Nemotron 1.1:通过监督微调和强化学习协同提升数学和代码推理能力
一、模型概述
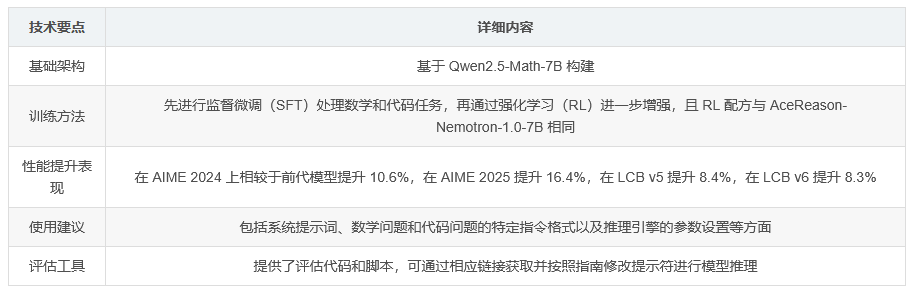
AceReason-Nemotron 1.1-7B 是一款基于 Qwen2.5-Math-7B 的数学和代码推理模型。该模型首先通过监督微调(SFT)在数学和代码任务上进行训练,然后利用与 AceReason-Nemotron-1.0-7B 相同的强化学习(RL)配方进一步增强。研究发现,从不同的 SFT 模型开始进行 RL 训练时,更强的 SFT 模型在经过大规模 RL 训练后仍然能持续产生更好的结果,尽管在 RL 训练期间性能差距会缩小。
二、模型性能表现
AceReason-Nemotron 1.1-7B 在数学和代码推理基准测试中表现卓越,相较于前代模型和其他同尺寸竞争模型均有显著提升。在 AIME 2024、AIME 2025 以及 LiveCodeBench(LCB)v5 和 v6 的评估中,AceReason-Nemotron 1.0-7B 在 RL 训练后,相较于其起始的 SFT 模型 DeepSeek-R1-Distill-Qwen-7B,在 AIME24 提升了 13.5%,AIME25 提升了 14.6%,LCB v5 提升了 14.2%,LCB v6 提升了 10.0%。而 AceReason-Nemotron-1.1-7B 在相同的 RL 配方加持下,在 AIME24 提升了 10.6%,AIME25 提升了 16.4%,LCB v5 提升了 8.4%,LCB v6 提升了 8.3%。
| 模型 | AIME 2024 (avg@64) | AIME 2025 (avg@64) | LCB v5 (avg@8) | LCB v6 (avg@8) |
|---|---|---|---|---|
| Skywork-OR1-7B | 70.2 | 54.6 | 47.6 | 42.7 |
| MiMo-7B-RL | 68.2 | 55.4 | 57.8 | 49.3 |
| o3-mini (low) | 60.0 | 48.3 | 60.9 | - |
| OpenMath-Nemotron-7B | 74.8 | 61.2 | - | - |
| OpenCodeReasoning-Nemotron-7B | - | - | 51.3 | 46.1 |
| Magistral Small (24B) | 70.7 | 62.8 | 55.8 | 47.4 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 39.0 | 37.6 | 34.1 |
| AceReason-Nemotron-1.0-7B | 69.0 | 53.6 | 51.8 | 44.1 |
| ur SFT-7B (RL 的起点) | 62.0 | 48.4 | 48.8 | 43.8 |
| AceReason-Nemotron-1.1-7B | 72.6 | 64.8 | 57.2 | 52.1 |
三、模型使用方法
使用 AceReason-Nemotron 1.1-7B 模型时,可以参考以下代码示例:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = 'nvidia/AceReason-Nemotron-1.1-7B'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
prompt = "Jen enters a lottery by picking $4$ distinct numbers from $S=\\{1,2,3,\\cdots,9\\}$. What is the probability that she wins the lottery?"
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to("cuda")
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768,
temperature=0.6,
top_p=0.95
)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
使用建议
-
系统提示词建议使用:“You are a helpful and harmless assistant. You should think step-by-step.”
-
数学问题的指令格式:
-
math_question = "MATH_QUESTION" -
math_instruction = "Please place your final answer inside \\boxed{}." -
system_instruction = "You are a helpful and harmless assistant. You should think step-by-step." -
最终提示符为:
"<|im_start|>system\n" + system_instruction + "<|im_end|>\n<|im_start|>user\n" + math_question + "<|im_end|>\n<|im_start|>assistant\n" + math_instruction + "<|im_end|>"
-
-
代码问题的指令格式:
-
code_question = "CODE_QUESTION" -
starter_code = "STARTER_CODE"(若无起始代码函数头则设为空字符串"") -
若
starter_code不为空,则code_instruction_hasstartercode = "Please place the solution code in the following format:\n\n" + starter_code + "\n...",并将code_question += "\n\n" + "Solve the problem starting with the provided function header:" + code_instruction_hasstartercode -
若
starter_code为空,则code_instruction_nostartercode = "Write Python code to solve the problem. Please place the solution code in the following format:\n\ndef solve()\n ...",并将code_question += "\n\n" + code_instruction_nostartercode -
最终提示符为:
"<|im_start|>system\n" + system_instruction + "<|im_end|>\n<|im_start|>user\n" + code_question + "<|im_end|>\n<|im_start|>assistant\n" + code_instruction + "<|im_end|>"
-
-
推理引擎建议使用 vLLM==0.7.3,参数设置为 top-p=0.95,temperature=0.6,max_tokens=32768。
四、模型评估工具包
可以参考 https://huggingface.co/nvidia/AceReason-Nemotron-14B/blob/main/README_EVALUATION.md 中的评估代码和脚本。在进行模型推理时,根据 “使用建议” 部分的指南修改提示符。
AceReason-Nemotron 1.1 核心技术总结

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献145条内容
已为社区贡献145条内容

所有评论(0)