LLM工作流API开发全攻略:LangGraph+FastAPI实战(建议收藏学习)
文章详解如何使用LangGraph构建多步骤LLM工作流,并通过FastAPI封装为生产级REST API。内容包括环境配置、工作流构建、错误处理、输入验证、日志记录,以及API测试与部署。通过结合LangGraph的有状态工作流能力和FastAPI的高性能API服务,开发者可轻松构建可扩展的AI智能体服务,适用于聊天机器人、文档处理等多种应用场景。
简介
文章详解如何使用LangGraph构建多步骤LLM工作流,并通过FastAPI封装为生产级REST API。内容包括环境配置、工作流构建、错误处理、输入验证、日志记录,以及API测试与部署。通过结合LangGraph的有状态工作流能力和FastAPI的高性能API服务,开发者可轻松构建可扩展的AI智能体服务,适用于聊天机器人、文档处理等多种应用场景。
Large Language Models (LLMs) 擅长推理,但现实世界的应用往往需要有状态、多步骤的工作流。这就是 LangGraph 的用武之地——它让你可以通过由 LLM 驱动的节点图来构建智能工作流。
但如果你想把这些工作流暴露为 APIs,让其他应用(或用户)可以调用呢?这时候 FastAPI 就派上用场了——一个轻量级、高性能的 Python Web 框架。
在这篇指南中,你将学习如何将 LangGraph 工作流封装在 FastAPI 中,变成一个生产就绪的 endpoint。
为什么选择 LangGraph + FastAPI?
- • LangGraph:创建多步骤、有状态的 LLM 工作流(例如,多智能体推理、数据处理)。
- • FastAPI:轻松将这些工作流暴露为 REST APIs,以便与 Web 应用、微服务或自动化流水线集成。
- • 结合两者:构建可从任何地方访问的可扩展 AI 智能体。
1. 项目设置
创建一个新项目文件夹并安装依赖:
mkdir langgraph_fastapi_demo && cd langgraph_fastapi_demo
python -m venv .venv
source .venv/bin/activate # 在 Windows 上:.venv\Scripts\activate
pip install fastapi uvicorn langgraph langchain-openai python-dotenv
创建一个 .env 文件来存储你的 API 密钥:
OPENAI_API_KEY=你的_openai_密钥_在此
2. 构建一个简单的 LangGraph 工作流
让我们构建一个简单的 LangGraph,它接收用户的问题并返回 AI 生成的答案。
# workflow.py
from langgraph.graph import StateGraph, START, END
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
import os
from dotenv import load_dotenv
load_dotenv()
llm = ChatOpenAI(model="gpt-4o") # 可以切换到 gpt-4o-mini 以降低成本
# 定义状态
defanswer_question(state: dict) -> dict:
user_input = state["user_input"]
response = llm.invoke([HumanMessage(content=user_input)])
return {"answer": response.content}
# 构建图
workflow = StateGraph(dict)
workflow.add_node("answer", answer_question)
workflow.add_edge(START, "answer")
workflow.add_edge("answer", END)
graph = workflow.compile()
这个图:
- • 接收 user_input
- • 将其发送到 GPT-4o
- • 返回 AI 生成的响应
3. 让它生产就绪
在向全世界开放之前,让我们为真实用例加固它。
错误处理与重试
LLM APIs 可能会失败或超时。用 try/except 包装调用:
from tenacity import retry, wait_exponential, stop_after_attempt
@retry(wait=wait_exponential(multiplier=1, min=2, max=10), stop=stop_after_attempt(3))
def safe_invoke_llm(message):
return llm.invoke([HumanMessage(content=message)])
def answer_question(state: dict) -> dict:
user_input = state["user_input"]
try:
response = safe_invoke_llm(user_input)
return {"answer": response.content}
except Exception as e:
return {"answer": f"错误:{str(e)}"}
输入验证
我们不想让别人发送巨大的数据负载。添加 Pydantic 约束:
from pydantic import BaseModel, constr
class RequestData(BaseModel):
user_input: constr(min_length=1, max_length=500) # 限制输入大小
日志记录
添加日志以提高可见性:
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def answer_question(state: dict) -> dict:
logger.info(f"收到输入:{state['user_input']}")
response = safe_invoke_llm(state['user_input'])
logger.info("已生成 LLM 响应")
return {"answer": response.content}
4. 使用 FastAPI 暴露工作流
现在,让我们将这个工作流封装在 FastAPI 中。
# main.py
from fastapi import FastAPI
from workflow import graph, RequestData
app = FastAPI()
@app.post("/run")
async def run_workflow(data: RequestData):
result = graph.invoke({"user_input": data.user_input})
return {"result": result["answer"]}
运行服务器:
uvicorn main:app --reload
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

5. 测试 API
你可以使用 curl 测试:
curl -X POST "http://127.0.0.1:8000/run" \
-H "Content-Type: application/json" \
-d '{"user_input":"什么是 LangGraph?"}'
或者在浏览器中打开 http://127.0.0.1:8000/docs —— FastAPI 会自动为你生成 Swagger UI!
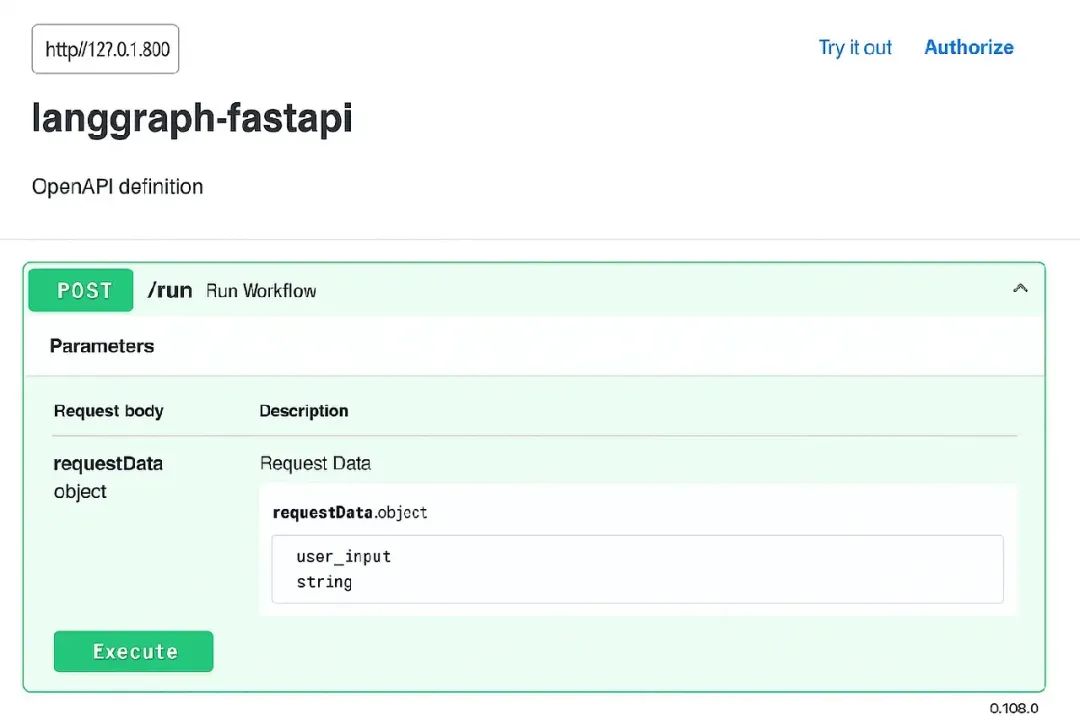
这个交互式 UI 让你直接在浏览器中测试你的 endpoint。
6. 扩展与部署
为生产环境做准备的几个步骤:
- • 异步执行:FastAPI 是异步原生的。对于多个 LLM 调用,让函数变成异步的。
- • 工作进程:使用多进程运行以实现并发:
uvicorn main:app --workers 4 - • Docker 化:
FROM python:3.11-slim WORKDIR /app COPY . . RUN pip install -r requirements.txt CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"] - • 认证:使用 API 密钥或 JWT tokens 来保护 endpoints(第二部分即将推出)。
7. 架构概览
以下是整体连接方式:
POST /run
Client
FastAPI
LangGraph
OpenAI_API
Response
这个简单的架构让你可以将任何 LangGraph 变成一个 API。
8. 结论
通过几个简单的步骤,我们:
- • 构建了一个 LangGraph 工作流
- • 使用 FastAPI 将其暴露为 REST API
- • 添加了生产就绪的功能(验证、重试、日志)
- • 为可扩展的 AI 微服务奠定了基础
这个设置可以支持从聊天机器人到文档处理器再到 AI SaaS 产品的各种应用。
下一步是什么?
我计划推出本教程的第二部分,但我想听听你的意见。
👉 你希望我接下来讲哪一个?
- • 流式响应(实时聊天)
- • 认证与安全性
- • Docker 与云部署
- • 错误监控与可观察性
在下方评论你的选择!
Large Language Models (LLMs) 擅长推理,但现实世界的应用往往需要有状态、多步骤的工作流。这就是 LangGraph 的用武之地——它让你可以通过由 LLM 驱动的节点图来构建智能工作流。
但如果你想把这些工作流暴露为 APIs,让其他应用(或用户)可以调用呢?这时候 FastAPI 就派上用场了——一个轻量级、高性能的 Python Web 框架。
在这篇指南中,你将学习如何将 LangGraph 工作流封装在 FastAPI 中,变成一个生产就绪的 endpoint。
为什么选择 LangGraph + FastAPI?
- • LangGraph:创建多步骤、有状态的 LLM 工作流(例如,多智能体推理、数据处理)。
- • FastAPI:轻松将这些工作流暴露为 REST APIs,以便与 Web 应用、微服务或自动化流水线集成。
- • 结合两者:构建可从任何地方访问的可扩展 AI 智能体。
1. 项目设置
创建一个新项目文件夹并安装依赖:
mkdir langgraph_fastapi_demo && cd langgraph_fastapi_demo
python -m venv .venv
source .venv/bin/activate # 在 Windows 上:.venv\Scripts\activate
pip install fastapi uvicorn langgraph langchain-openai python-dotenv
创建一个 .env 文件来存储你的 API 密钥:
OPENAI_API_KEY=你的_openai_密钥_在此
2. 构建一个简单的 LangGraph 工作流
让我们构建一个简单的 LangGraph,它接收用户的问题并返回 AI 生成的答案。
# workflow.py
from langgraph.graph import StateGraph, START, END
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
import os
from dotenv import load_dotenv
load_dotenv()
llm = ChatOpenAI(model="gpt-4o") # 可以切换到 gpt-4o-mini 以降低成本
# 定义状态
defanswer_question(state: dict) -> dict:
user_input = state["user_input"]
response = llm.invoke([HumanMessage(content=user_input)])
return {"answer": response.content}
# 构建图
workflow = StateGraph(dict)
workflow.add_node("answer", answer_question)
workflow.add_edge(START, "answer")
workflow.add_edge("answer", END)
graph = workflow.compile()
这个图:
- • 接收 user_input
- • 将其发送到 GPT-4o
- • 返回 AI 生成的响应
3. 让它生产就绪
在向全世界开放之前,让我们为真实用例加固它。
错误处理与重试
LLM APIs 可能会失败或超时。用 try/except 包装调用:
from tenacity import retry, wait_exponential, stop_after_attempt
@retry(wait=wait_exponential(multiplier=1, min=2, max=10), stop=stop_after_attempt(3))
def safe_invoke_llm(message):
return llm.invoke([HumanMessage(content=message)])
def answer_question(state: dict) -> dict:
user_input = state["user_input"]
try:
response = safe_invoke_llm(user_input)
return {"answer": response.content}
except Exception as e:
return {"answer": f"错误:{str(e)}"}
输入验证
我们不想让别人发送巨大的数据负载。添加 Pydantic 约束:
from pydantic import BaseModel, constr
class RequestData(BaseModel):
user_input: constr(min_length=1, max_length=500) # 限制输入大小
日志记录
添加日志以提高可见性:
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def answer_question(state: dict) -> dict:
logger.info(f"收到输入:{state['user_input']}")
response = safe_invoke_llm(state['user_input'])
logger.info("已生成 LLM 响应")
return {"answer": response.content}
4. 使用 FastAPI 暴露工作流
现在,让我们将这个工作流封装在 FastAPI 中。
# main.py
from fastapi import FastAPI
from workflow import graph, RequestData
app = FastAPI()
@app.post("/run")
async def run_workflow(data: RequestData):
result = graph.invoke({"user_input": data.user_input})
return {"result": result["answer"]}
运行服务器:
uvicorn main:app --reload
5. 测试 API
你可以使用 curl 测试:
curl -X POST "http://127.0.0.1:8000/run" \
-H "Content-Type: application/json" \
-d '{"user_input":"什么是 LangGraph?"}'
或者在浏览器中打开 http://127.0.0.1:8000/docs —— FastAPI 会自动为你生成 Swagger UI!
这个交互式 UI 让你直接在浏览器中测试你的 endpoint。
6. 扩展与部署
为生产环境做准备的几个步骤:
- • 异步执行:FastAPI 是异步原生的。对于多个 LLM 调用,让函数变成异步的。
- • 工作进程:使用多进程运行以实现并发:
uvicorn main:app --workers 4 - • Docker 化:
FROM python:3.11-slim WORKDIR /app COPY . . RUN pip install -r requirements.txt CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"] - • 认证:使用 API 密钥或 JWT tokens 来保护 endpoints(第二部分即将推出)。
7. 架构概览
以下是整体连接方式:
POST /run
Client
FastAPI
LangGraph
OpenAI_API
Response
这个简单的架构让你可以将任何 LangGraph 变成一个 API。
8. 结论
通过几个简单的步骤,我们:
- • 构建了一个 LangGraph 工作流
- • 使用 FastAPI 将其暴露为 REST API
- • 添加了生产就绪的功能(验证、重试、日志)
- • 为可扩展的 AI 微服务奠定了基础
这个设置可以支持从聊天机器人到文档处理器再到 AI SaaS 产品的各种应用。
下一步是什么?
我计划推出本教程的第二部分,但我想听听你的意见。
👉 你希望我接下来讲哪一个?
- • 流式响应(实时聊天)
- • 认证与安全性
- • Docker 与云部署
- • 错误监控与可观察性
在下方评论你的选择!
如何学习AI大模型?
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献344条内容
已为社区贡献344条内容

所有评论(0)