使用 Ollama 运行本地 LLM
在开始之前,让我们了解一下它是如何工作的:有多种工具可用于服务模式,Ollama 和 LM Studio 是广泛使用的工具:- Ollama 和(基于终端),请关注此博客这些模型服务应用程序可以从其提供商处下载开源模型,并允许您与这些模型进行交互。唯一值得注意的是,它运行在你的机器上,所以,你的机器应该有足够的资源(CPU、RAM、GPU)来运行这些模型所做的计算。1. 安装 Ollamacurl
在开始之前,让我们了解一下它是如何工作的:
有多种工具可用于服务模式,Ollama 和 LM Studio 是广泛使用的工具:
- Ollama 和(基于终端)
- LM Studio(基于 GUI):如果您喜欢使用 GUI
,请关注此博客这些模型服务应用程序可以从其提供商处下载开源模型,并允许您与这些模型进行交互。
唯一值得注意的是,它运行在你的机器上,所以,你的机器应该有足够的资源(CPU、RAM、GPU)来运行这些模型所做的计算。
接下来是模型格式
模型以各种优化格式提供,例如:
- GGUF(GPT 生成的统一格式):它是一种用于存储优化的大型语言模型 (LLM) 的格式,可以在 CPU 和 GPU 上高效运行。它主要由 LLAMA.cpp 使用,并得到 Ollama、KoboldCpp 和其他 AI 工具的支持。
- llama.cpp 一个库,允许您在自己的计算机上运行像 Llama 2 这样的大型语言模型 (LLM),即使没有强大的显卡也是如此。它旨在高效并且可以在 CPU 上运行,使其可供更广泛的用户使用
有哪些可用的开源 LLM 模型:
- Meta 的 LLaMA 模型
- Mistral, Mixtral
- DeepSeek(R1 等)
- OpenHermes
- Phi-2、Gemma 或 TinyLlama(用于轻量级设置)
设置 Ollama 以在本地运行 LLaMA:
小型模型的系统要求
- CPU:支持 AVX2 的 Modern x86_64 (Intel/AMD)
- 内存:16GB+
- 存储:10GB+ 模型文件的可用磁盘空间
- 作系统: Linux, macOS, or Windows (Can use WSL)
系统要求用于较大的型号,如 LLaMA-2 13B 或 Mixtral
- 显卡:英伟达 RTX 3060+ (8GB+ 显存)
- 内存:32GB+
- 存储: 具有 50GB+ 可用空间的 SSD
- CUDA(如果使用 NVIDIA GPU)
1. 安装 Ollama
curl -fsSL https://ollama.ai/install.sh |sh
检查是否安装正确ollama --version


2. 在本地下载并运行 LLaMA
ollama pull llama2
# 📝 This downloads Meta’s LLaMA-2 model (7B variant by default).
-- This is 3.8 GB in size 3. 在本地运行 Llama 模型
我键入了 ollama run llama2,但没有意识到这台机器中没有 llama 模型,但看起来它正在拉动然后运行模型。

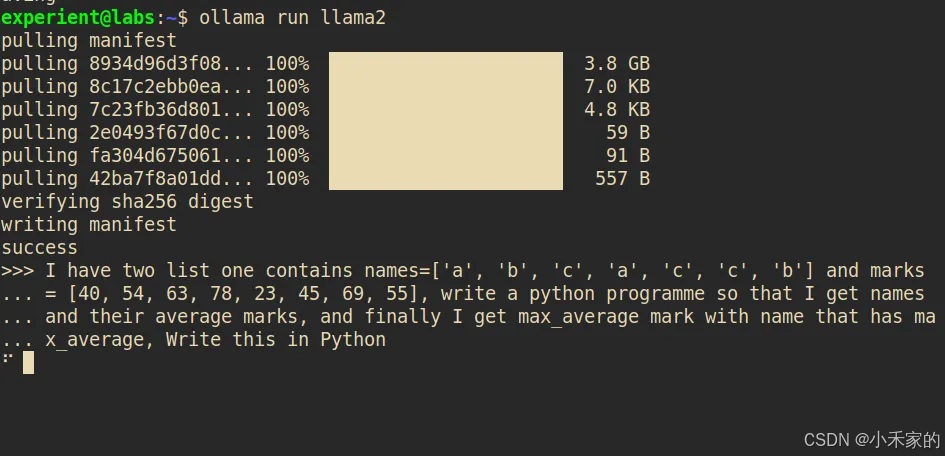
现在我要求它用 python 编写一个程序:
我有两个列表,一个包含 names=['a', 'b', 'c', 'a', 'c', 'c', 'b'] 和 marks = [40, 54, 63, 78, 23, 45, 69, 55],编写一个 python 程序,这样我就可以得到名字
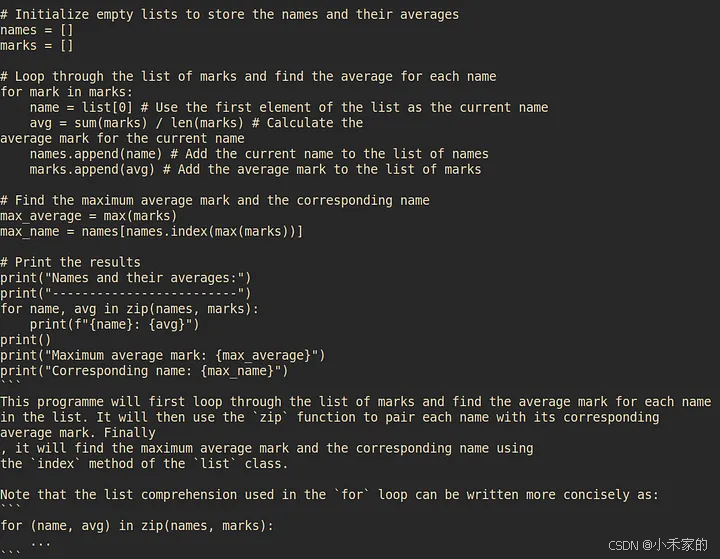
和它们的平均分数,最后我得到max_average带有 max_average 标记的 name 的标记。

CPU 和内存利用率
花了 10 分钟才生成可供评估的回复 ;-)
4. 使用 python 程序与 Llama 交互
import requests
response = requests.post(
"http://localhost:11434/api/generate",
json={"model": "llama2", "prompt": "What is AI?", "stream": False},
)
print(response.json()["response"])Ollama 在
http://localhost:11434
如果您有 NVIDIA GPU,Ollama 会自动使用 CUDA。要检查 GPU 加速是否正常工作:
OLLAMA_DEBUG=true ollama run llama2然后查找日志中的消息Using GPU: CUDA
5. 运行更大的模型(LLaMA-2 13B 或 Mixtral)
ollama pull llama2:13b
ollama run llama2:13b
# For Mistral(better performance than LLaMA-2)
ollama pull mixtral
ollama run mixtral在 Docker 容器中运行 Ollama。
docker run --rm -it --gpus all ollama/ollama run llama2由于我的 LlaMA 对编程的反应缓慢且含糊不清,我打算找到一个编程模型。
以下是一些:
编程模型:
- Code Llama 7B、13B、34B,Meta 的编码训练模型,适用于 Python,大小 3.8GB
- DeepSeek-Coder 6.7B、33B,在 Python 和通用编码方面更强大。
- StarCoder 7B 适合一般编码 轻量级。
- WizardCoder 7B、13B Python Heavey、指令调优
- Phi-2 2.7B Tiny Model 不错的 Python 功能。
选择最佳 ModelS
- Python脚本和代码片段
- 大型 Python 项目 DeepSeek-Coder
- Python Phi-2 的微型模型
- 通用编码和调试 StarCoder
- Instruction-Tuned Python 帮助WizardCoder

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)