LlamaIndex 混合检索实战:自定义检索器实现语义与关键词的高效融合
python"""支持AND/OR模式的混合检索器,实现语义与关键词检索结果的集合运算"""self,mode: str = "AND" # 默认使用交集模式,精确性优先) -> None:raise ValueError("仅支持AND/OR检索模式,当前模式无效")"""核心检索逻辑:执行双检索器查询并按模式合并结果"""# 1. 分别执行向量检索和关键词检索# 2. 提取节点ID用于集合运算
在构建智能问答系统时,我们常常会遇到这样的困境:单纯使用向量检索可能返回语义相关但关键词不匹配的结果,而仅依靠关键词检索又会错过语义相似的内容。有没有一种方法能将两者的优势结合起来?本文将从查询引擎层面,通过自定义检索器实现向量与关键词的混合检索,帮助你快速掌握这一核心技术。
一、混合检索的核心原理与应用价值
1. 为什么需要混合检索?
- 向量检索的优势:基于语义相似度匹配,能捕捉自然语言的模糊表达(如 "人工智能发展" 与 "AI 趋势" 视为相似查询)
- 关键词检索的优势:精准匹配字面术语,适合明确指定条件的查询(如必须包含 "机器学习算法" 的文档)
- 混合检索的价值:通过 "语义 + 关键词" 双重过滤,既保证召回率又提升精确性,减少无关结果干扰
2. 核心模式解析
- AND 模式:取向量检索与关键词检索结果的交集,仅返回同时满足语义相似和关键词匹配的内容(精确性优先)
- OR 模式:取两者的并集,扩大检索范围,适合信息探索类查询(召回率优先)
3. 典型应用场景
- 企业知识问答:通过部门关键词(如 "财务部")+ 语义检索定位内部政策文档
- 法律案例检索:用法律条款编号(关键词)+ 案例情节(语义)双重过滤
- 学术文献查询:学科关键词(如 "自然语言处理")+ 研究方向语义匹配
二、环境搭建与双索引体系构建
1. 依赖安装与配置
python
!pip install llama-index # 安装LlamaIndex核心库
python
import os
os.environ["OPENAI_API_KEY"] = "sk-..." # 配置OpenAI API密钥(实际使用时替换为真实密钥)
2. 示例数据准备
python
# 下载示例文档(Paul Graham论文)
!mkdir -p 'data/paul_graham/'
!wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/paul_graham/paul_graham_essay.txt' -O 'data/paul_graham/paul_graham_essay.txt'
3. 构建向量索引与关键词索引
python
from llama_index.core import SimpleDirectoryReader, StorageContext, Settings
from llama_index.core import VectorStoreIndex, SimpleKeywordTableIndex
# 加载文档并分割为节点
documents = SimpleDirectoryReader("./data/paul_graham").load_data()
nodes = Settings.node_parser.get_nodes_from_documents(documents)
# 初始化存储上下文(默认内存存储)
storage_context = StorageContext.from_defaults()
storage_context.docstore.add_documents(nodes)
# 构建向量索引(处理语义检索需求)
vector_index = VectorStoreIndex(nodes, storage_context=storage_context)
# 构建关键词表索引(处理精确关键词匹配)
keyword_index = SimpleKeywordTableIndex(nodes, storage_context=storage_context)
4. 双索引工作原理解析
- 向量索引:通过 OpenAI 等模型生成文本嵌入向量,计算查询与文档的余弦相似度,适合处理语义模糊的查询
- 关键词索引:将文本分解为关键词建立倒排索引,适合精确匹配特定术语的查询
- 组合优势:向量索引覆盖语义空间,关键词索引缩小检索范围,两者结合形成互补
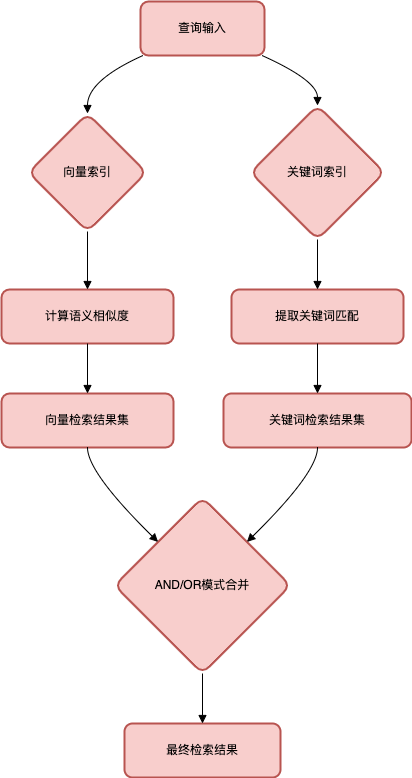
三、核心实现:自定义混合检索器
1. 检索器核心代码实现
python
from llama_index.core import QueryBundle
from llama_index.core.schema import NodeWithScore
from llama_index.core.retrievers import BaseRetriever, VectorIndexRetriever, KeywordTableSimpleRetriever
from typing import List
class HybridRetriever(BaseRetriever):
"""支持AND/OR模式的混合检索器,实现语义与关键词检索结果的集合运算"""
def __init__(
self,
vector_retriever: VectorIndexRetriever,
keyword_retriever: KeywordTableSimpleRetriever,
mode: str = "AND" # 默认使用交集模式,精确性优先
) -> None:
self._vector_retriever = vector_retriever
self._keyword_retriever = keyword_retriever
if mode not in ("AND", "OR"):
raise ValueError("仅支持AND/OR检索模式,当前模式无效")
self._mode = mode
super().__init__()
def _retrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:
"""核心检索逻辑:执行双检索器查询并按模式合并结果"""
# 1. 分别执行向量检索和关键词检索
vector_nodes = self._vector_retriever.retrieve(query_bundle)
keyword_nodes = self._keyword_retriever.retrieve(query_bundle)
# 2. 提取节点ID用于集合运算
vector_ids = {n.node.node_id for n in vector_nodes}
keyword_ids = {n.node.node_id for n in keyword_nodes}
# 3. 合并节点到字典,便于通过ID快速查找
combined_dict = {n.node.node_id: n for n in vector_nodes}
combined_dict.update({n.node.node_id: n for n in keyword_nodes})
# 4. 根据模式执行集合运算(交集或并集)
if self._mode == "AND":
# 仅返回同时满足向量相似和关键词匹配的节点
retrieve_ids = vector_ids.intersection(keyword_ids)
else:
# 返回满足任意条件的节点
retrieve_ids = vector_ids.union(keyword_ids)
# 5. 根据最终ID集合获取检索结果
return [combined_dict[rid] for rid in retrieve_ids]
2. 模式选择最佳实践
| 应用场景 | 推荐模式 | 核心优势 |
|---|---|---|
| 精确问答 | AND | 避免语义模糊导致的错误回答 |
| 信息探索 | OR | 扩大检索范围,发现潜在相关内容 |
| 专业领域检索 | AND | 通过关键词过滤无关语义结果 |
| 跨语言检索 | OR | 结合翻译后的关键词与语义匹配 |
四、集成查询引擎与实战验证
1. 组装完整查询流程
python
from llama_index.core import get_response_synthesizer
from llama_index.core.query_engine import RetrieverQueryEngine
# 初始化向量检索器(限制返回前2个最相似结果)
vector_retriever = VectorIndexRetriever(index=vector_index, similarity_top_k=2)
# 初始化关键词检索器
keyword_retriever = KeywordTableSimpleRetriever(index=keyword_index)
# 创建混合检索器(默认使用AND模式)
hybrid_retriever = HybridRetriever(vector_retriever, keyword_retriever)
# 初始化响应合成器
response_synthesizer = get_response_synthesizer()
# 组装混合检索查询引擎
hybrid_query_engine = RetrieverQueryEngine(
retriever=hybrid_retriever,
response_synthesizer=response_synthesizer,
)
# 用于对比的单一检索引擎(仅向量检索)
vector_query_engine = RetrieverQueryEngine(
retriever=vector_retriever,
response_synthesizer=response_synthesizer,
)
2. 有效查询测试:作者在 YC 期间的工作
python
# 执行混合检索查询
response = hybrid_query_engine.query("What did the author do during his time at YC?")
print("混合检索结果:")
print(response)
输出结果:
"在 YC 期间,作者参与了多个项目的开发,包括撰写技术文章和构建 YC 内部软件。他使用 Arc 语言编写了所有内部工具,并处理了大量与 Hacker News 相关的紧急问题。作者提到,约 60% 的紧急问题与 HN 相关,其余 40% 涉及创业公司的各类需求..."
3. 无效查询测试:作者在耶鲁大学的经历
python
# 混合检索(AND模式)
yale_response = hybrid_query_engine.query("What did the author do during his time at Yale?")
print("混合检索结果:")
print(str(yale_response)) # 输出空响应
# 向量检索结果
vector_yale_response = vector_query_engine.query("What did the author do during his time at Yale?")
print("向量检索结果:")
print(str(vector_yale_response)) # 输出"上下文信息未提供相关内容"
4. 结果对比分析
- 混合检索(AND 模式):由于文档未提及 "Yale",关键词检索无结果,最终返回空响应,避免了错误信息
- 单纯向量检索:虽未找到相关内容,但仍尝试生成响应,存在 "幻觉" 风险
- 核心价值:通过关键词过滤机制,混合检索能有效减少无关结果,提升回答准确性
五、进阶优化与场景扩展
1. 动态模式自适应检索器
根据查询特征自动切换 AND/OR 模式:
python
class AdaptiveHybridRetriever(HybridRetriever):
def _detect_mode(self, query_str: str) -> str:
"""根据查询关键词数量智能选择检索模式"""
# 提取有效关键词(长度>2的单词)
keywords = [k for k in query_str.split() if len(k) > 2]
# 关键词数量≥2时使用AND模式(精确性优先)
return "AND" if len(keywords) >= 2 else "OR"
def retrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:
"""重写检索方法,动态设置模式"""
self._mode = self._detect_mode(query_bundle.query_str)
return super().retrieve(query_bundle)
2. 加权融合检索器
为不同检索结果设置权重,优化排序逻辑:
python
class WeightedHybridRetriever(HybridRetriever):
def __init__(
self,
vector_retriever,
keyword_retriever,
mode="AND",
vector_weight: float = 0.6, # 向量检索结果权重
keyword_weight: float = 0.4, # 关键词检索结果权重
) -> None:
super().__init__(vector_retriever, keyword_retriever, mode)
self.vector_weight = vector_weight
self.keyword_weight = keyword_weight
def _retrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:
"""执行检索并重新计算加权分数"""
results = super()._retrieve(query_bundle)
# 遍历结果重新计算分数
for result in results:
# 获取向量检索分数(默认0.0)
vector_score = next(
(n.score for n in self._vector_retriever.retrieve(query_bundle)
if n.node.node_id == result.node.node_id), 0.0
)
# 关键词检索默认分数为1.0(视为完全匹配)
keyword_score = 1.0
# 加权计算最终分数
result.score = vector_score * self.vector_weight + keyword_score * self.keyword_weight
# 按分数降序排序
return sorted(results, key=lambda x: x.score, reverse=True)
3. 行业应用场景优化指南
| 应用领域 | 优化策略 | 实现要点 |
|---|---|---|
| 代码知识库 | AND 模式 + 编程关键词过滤 | 添加 "function"、"class" 等编程术语作为必选关键词 |
| 医疗问诊系统 | OR 模式 + 症状语义扩展 | 结合症状同义词(如 "头疼"="头痛")构建扩展词表 |
| 电商商品搜索 | AND 模式 + 品牌 + 品类关键词 | 向量检索匹配商品描述,关键词限定品牌和品类 |
| 法律文书检索 | AND 模式 + 法条编号 + 案例情节语义 | 关键词匹配具体法条,向量匹配案例事实描述 |
六、总结与互动
今天我们深入学习了 LlamaIndex 中自定义混合检索器的实现方法,通过向量检索与关键词检索的集合运算(AND/OR 模式),实现了语义与精确匹配的高效融合。这种方案具有代码简洁、原理透明的特点,非常适合新手快速掌握混合检索的核心逻辑。
在实际应用中,你可能会遇到更多复杂场景,比如需要结合外部向量数据库、处理多模态数据等,这些都可以在本文基础上进一步扩展。
如果本文对你有帮助,别忘了点赞收藏,关注我,一起探索更高效的开发方式~

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献249条内容
已为社区贡献249条内容

所有评论(0)