NanoVLA:面向Nano-大小通才机器人策略的解耦视觉-语言理解路由
25年10月来自加拿大UBC、加拿大 Alberta大学、小米电动汽车和加拿大东北大学的论文 “NanoVLA: Routing Decoupled Vision-Language Understanding For Nano-Sized Generalist Robotic Policies ”。视觉-语言-动作 (VLA) 模型通过将视觉-语言模型 (VLM) 和动作解码器集成到统一的架构中,
25年10月来自加拿大UBC、加拿大 Alberta大学、小米电动汽车和加拿大东北大学的论文 “NanoVLA: Routing Decoupled Vision-Language Understanding For Nano-Sized Generalist Robotic Policies ”。
视觉-语言-动作 (VLA) 模型通过将视觉-语言模型 (VLM) 和动作解码器集成到统一的架构中,显著提升机器人操作的性能。然而,由于计算需求高,尤其是在功耗、延迟和计算资源至关重要的实际应用场景中,将其部署到资源受限的边缘设备(例如移动机器人或嵌入式系统,如 Jetson Orin Nano)上仍然面临挑战。为了弥补这一差距,本文提出Nano大小视觉-语言-动作 (NanoVLA),这是一系列轻量级 VLA 架构,能够在资源占用极低的情况下实现高性能。其核心创新包括:(1) 视觉-语言解耦,将 VLM 中传统的早期视觉和语言输入融合移至后期阶段,从而在实现更高性能的同时,还能启用缓存并降低推理开销和延迟;(2) 长-短动作分块,以确保流畅、连贯的多步骤规划,同时不牺牲实时响应能力; (3) 动态路由可根据任务复杂度自适应地分配轻量级或重量级主干网络,进一步优化推理效率。在多个基准测试和实际部署中的实验结果表明,与以往最先进的VLA模型相比,NanoVLA在边缘设备上的推理速度最高可提升52倍,参数量减少98%,同时保持甚至超越其任务精度和泛化能力。
紧凑高效的 VLAs。近年来,研究重点集中在设计更小的 VLA 模型,以在保持泛化能力的同时降低部署的计算成本。RT-1(Brohan ,2022)率先提出仅包含 3500 万个参数的通用机器人模型。Octo-Base(Team,2024b)引入一种轻量级的、包含 9000 万个参数的 Transformer 策略,该策略基于 80 万条轨迹进行训练,可作为面向效率的基准模型。SmolVLA(Shukor,2025a)更进一步,将大型 VLA 的知识提炼到一个紧凑的 5 亿个参数模型中,证明缩小模型规模可以在降低推理成本的同时保留大部分泛化能力。这些工作表明,人们越来越认识到,实际的 VLA 部署必须解决计算效率和边缘硬件限制问题,而不仅仅是数据中心 GPU 的性能。
如图所示,NanoVLA 并非简单地缩减模型参数,而是围绕三个互补的理念重构推理过程,从而在边缘设备上实现了低延迟和鲁棒性: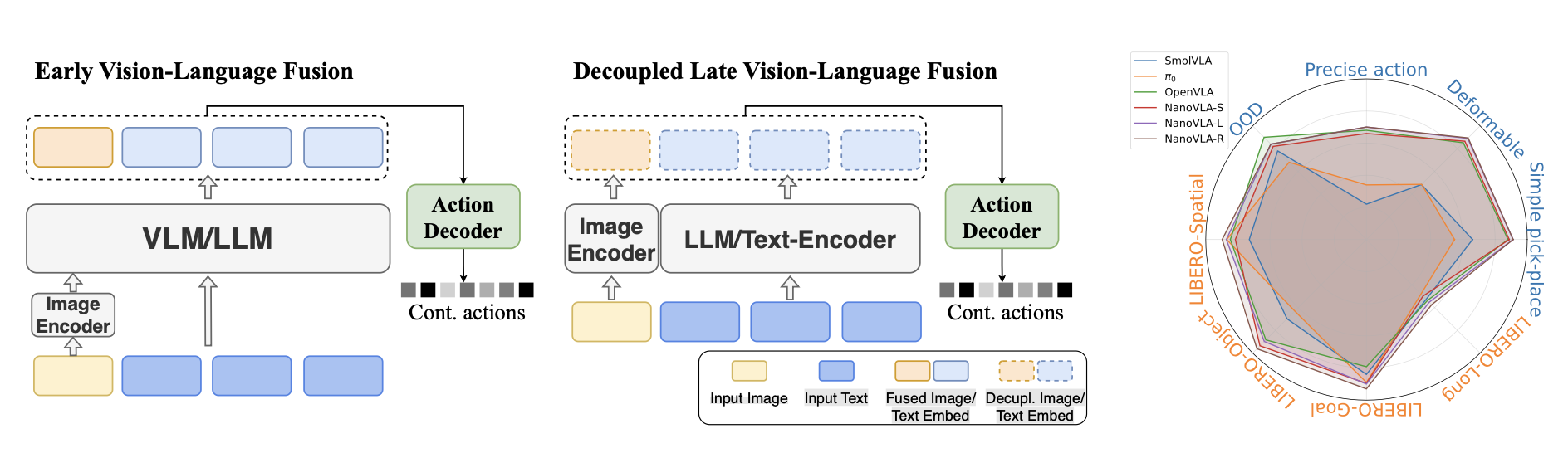
• 视觉-语言解耦(缓存不变的信息)。大多数视觉-语言-动作 (VLA) 模型会反复交错视觉和语言信息,并大量使用交叉注意机制,导致语言主干网络在每个控制步骤都需要重新计算,即使指令保持不变。NanoVLA 将视觉和语言信息分离到最后阶段,因此指令特征可以编码一次并重复使用,而每帧仅更新图像嵌入和动作模块,从而减少计算量。值得注意的是,预训练的视觉和语言编码器已经独立学习高度抽象且语义丰富的表征;延迟融合有助于避免早期跨模态干扰,同时保留每种模态的独特性(Shukor,2025b)。实验结果表明,这种设计在保持性能竞争力的同时提高效率。
• 长-短动作分块(规划长动作,但是执行短动作)。逐步预测器反应灵敏,但往往不够稳定;较长的固定动作块虽然流畅,但响应速度较慢(Bharadhwaj et al., 2024; Zhao et al., 2023)。NanoVLA 策略力求平衡:它生成较长的动作块,但仅在较短的时间窗口内执行,之后便会根据新的观测结果重规划。这既能将昂贵的规划成本分摊到多个控制步骤中,又能保持行为的流畅性和对新视觉证据的适应性。
• 动态路由(默认使用小型主干网,按需使用大型主干网)。NanoVLA 集成一个轻量级路由器,将简单的任务(例如,短时抓取)定向到紧凑的语言主干网,仅在任务难度增加时才升级到更大的主干网。这种自适应方法在保持复杂任务性能的同时,还能维持较低的平均延迟。
基于缓存的视觉-语言解耦
现代 VLA 模型需要大量的计算资源,因为它们通过重复的交叉注意机制紧密交织不同模态,迫使视觉和语言主干网络在每个时间步都进行重计算。这种设计阻碍边缘设备的实时部署,因为在边缘设备上,指令通常保持不变,而只有视觉观测数据会发生变化。现有研究表明,冻结大型预训练编码器并使用轻量级适配器可以在降低计算量的同时保持精度(Li et al., 2023)。基于此,NanoVLA 引入一种解耦架构,该架构在融合阶段之前独立处理视觉和语言数据。
方法。 NanoVLA 将每种输入模态分离到各自的编码器中:视觉编码器(例如 ResNet (He et al., 2016)、ViT (Dosovitskiy et al., 2020))提取紧凑的场景特征,而语言编码器(例如 BERT (Devlin et al., 2019)、Qwen (Yang et al., 2025a))编码任务指令。这两个编码器在训练过程中保持冻结状态,从而保留其预训练的语义知识并避免灾难性遗忘。其他模态(例如本体感觉)通过轻量级 MLP 投影引入,并融合自注意机制。在动作生成阶段,用轻量级 Transformer 融合特定模态的嵌入。每一层首先对输出 token应用自注意机制,使模型能够捕获多模态特征中的依赖关系。然后,它应用交叉注意机制,融合视觉和语言特征以生成动作。由于跨模态注意仅在后期阶段执行一次,因此该设计显著减少冗余计算。这种后期融合设计绕过视觉-语言模型(VLM)中常见的计算密集型早期跨模态纠缠。NanoVLA 的概览如图所示: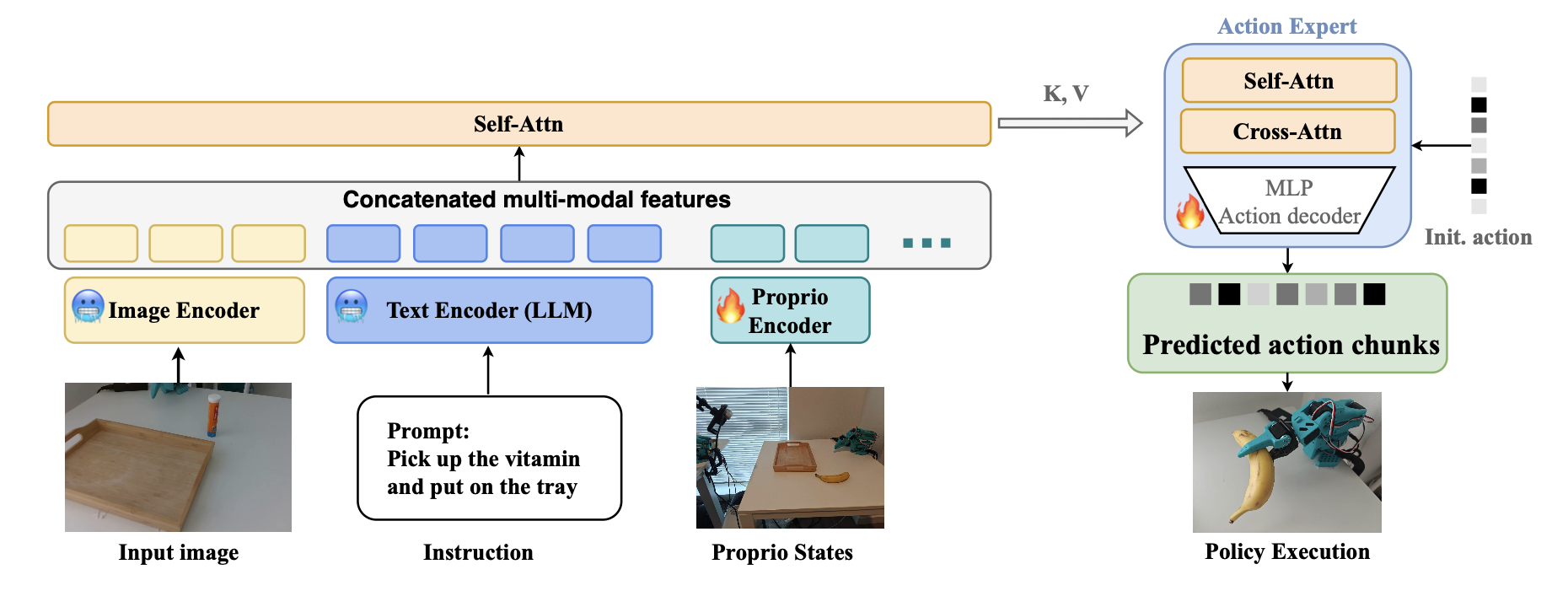
缓存以提高效率。这种分离的关键优势在于能够缓存中间特征。例如,在交互式机器人环境中,指令嵌入只需计算一次即可在多个时间步中重复使用,而视觉嵌入则在每一帧都进行更新。这种缓存消除冗余计算,并显著降低设备端延迟,使得在资源受限的硬件上进行推理成为可能。
预训练的视觉和语言编码器生成丰富且高级的语义表示,正如在 FrEVL(Bourigault & Bourigault,2025)中所观察的那样,轻量级解码器可以有效地融合这些表示,从而实现准确的动作预测。通过将计算与模态动态相结合,在刷新不断变化的视觉特征的同时重用稳定的指令特征,NanoVLA 以更少的训练参数和更快的推理速度实现具有竞争力的准确率。
长-短动作分块
边缘部署的第二个瓶颈在于动作随时间生成的机制。传统的分块策略(Zhao et al., 2023; Kim et al., 2025)预测一系列动作,然后在开环中执行整个分块。虽然这减少前向传播的次数,但也引入一个关键缺陷:一旦某个分块被执行,机器人就无法纠正模型不匹配、感知延迟或环境变化,直到下一次重规划。因此,在长时程任务中,机器人的行为常常变得不流畅、不稳定或错位。通常,现实世界的控制需要两个相互矛盾的特性:时间一致性:动作在长时程内平滑展开;响应性:策略能够快速适应新的感知输入。
固定的分块大小无法同时满足这两个特性。如果分块过长,执行流畅但不稳定;如果分块过短,执行反应灵敏但抖动严重。目标是在保留长规划优势的同时,确保执行过程中的频繁反馈。
方法。为此提出长-短动作分块(LSAC)策略。在训练过程中,该策略经过优化,能够预测长序列的动作,并捕捉跨时间跨度的时间模式和依赖关系: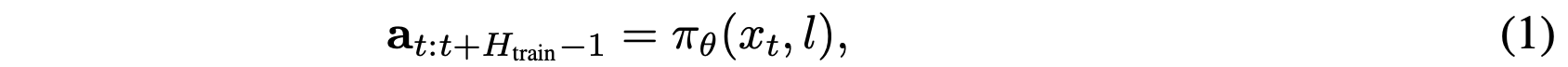
训练目标是对整个数据块进行监督回归: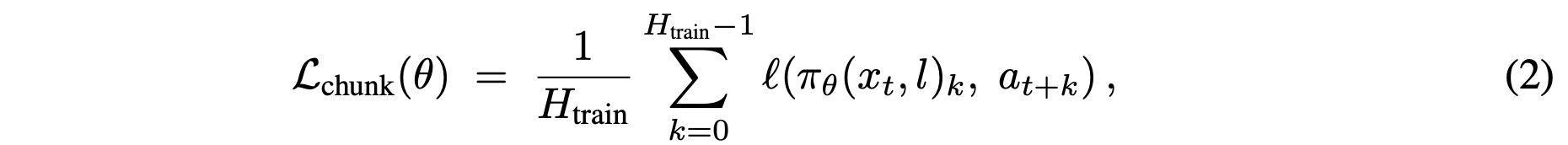
然而,在推理阶段,机器人只会执行每个预测块的前 h ≪ H_train 个动作,然后根据最新的观测结果重新进行规划: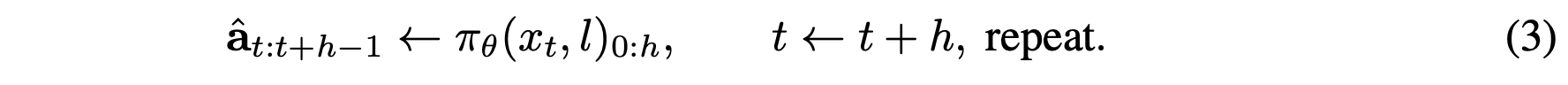
这导致长短不匹配:模型进行长范围规划,但行动却以短爆发形式进行,并频繁地重规划。总体而言,LSAC 在长范围控制中平衡连贯性和反应性。对长序列进行训练可以提高平滑性,执行短片段并进行重规划可以确保适应性,而每次遍历预测多个步骤并仅对少数步骤采取行动则可以提高效率。这些特性使得 LSAC 非常适合在边缘设备上进行实际的机器人控制。
动态路由
在边缘设备上高效部署 VLA 的最后一个挑战是任务难度与模型容量之间的不匹配。单个固定主干网络会将计算资源浪费在简单的指令(例如,短时抓取)上,但仍然难以应对复杂且推理密集型的任务。需要一种机制来自适应地分配计算资源,尽可能使用轻量级模型,仅在必要时才升级到更重的模型。
方法。NanoVLA 引入一个 VLA 路由器,该路由器在推理时从候选语言模型中进行选择。不依赖于硬标签进行路由(Ong,2024),而是估计模型之间考虑不确定性的获胜概率。对于每个任务 l 和模型 m,观察 n_m,l 次试验,其中 s_m,l 次成功,从而得出经验成功率 pˆ_m,l = s_m,l/n_m,l。路由器 R 为新任务 l 选择一个模型,权衡预测性能和成本。
贝叶斯的成功率建模。不将 pˆ_m,l 视为点估计,而是对(未知的)单任务成功概率应用 Beta-二项分布模型来模拟不确定性,并采用弱信息先验(除非另有说明,否则 α_0 = β_0 = 1):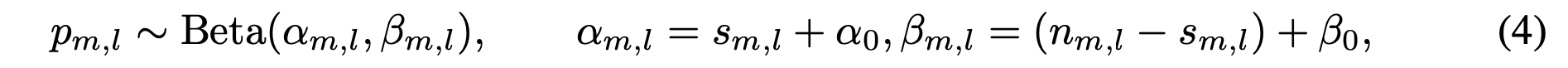
该后验分布反映试验次数的不确定性:试验次数较少时,后验分布更宽,并在成对比较中导致概率更接近 1/2。令 D 表示所有观察的试验。
训练目标。训练一个基于文本条件的二元分类器 f_θ,输入序列化为 (l, i, j),以预测 Pr(i ≻ j | l)。给定 MCB 目标 π^_i≻j (l),最小化伯努利对数-损失如下: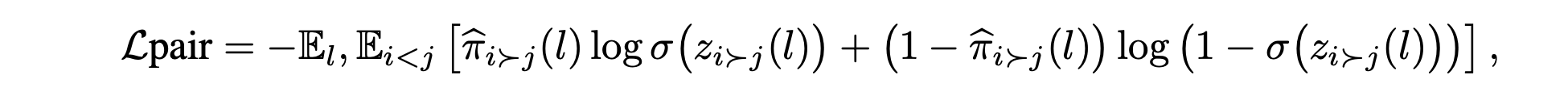
其中 z_i≻j(l) 是模型 logit,σ 是逻辑函数。获胜概率为训练文本条件二元分类器 f_θ 提供软标定的监督目标,以预测 Pr(i ≻ j | l)。
在推理阶段,路由器默认使用轻量级模型。只有当大模型对任务 l 的预测成功概率 pˆ_L(l) 超过阈值 τ 时,路由器才会升级到大模型。这样做可以提高简单任务的效率,并保持复杂指令的准确性。
仿真实验基准是 LIBERO。
真实实验评估采用LeRobot。
如图所示,组装 LeRobot So-arm 101 机器人,用于执行机器人操作任务。该机器人配备固定式第三人称视角摄像头,用于拍摄默认的 1280 × 720 RGB 图像。为每个任务采集 50 条演示轨迹,并将它们合并在一起进行微调。
实验使用LeRobot SoArm-101双臂系统(一个主导臂和一个跟随臂)。为了提供实验的第三人称视角,安装Intel RealSense D435i RGB-D摄像头。实验中,仅使用RGB图像。收集10个真实世界任务的演示轨迹,用于LeRobot远程操作的训练。根据任务的复杂程度,人类操作员完成每个回合需要9-18秒,在30Hz的控制频率下,这相当于300-600个时间步。每次测试中,随机化目标物体的初始位置,并重复实验50次,以匹配模拟设置。由于LeRobot未包含在预训练数据集中,因此模型预测新模型的动作难度更大,这使得本实验更具挑战性。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献215条内容
已为社区贡献215条内容

所有评论(0)