自动驾驶VLM最新论文笔记:AgentThink,DriveMoE
AgentThink,DriveMoE详解
·
【如果笔记对你有帮助,欢迎关注&点赞&收藏,收到正反馈会加快更新!谢谢支持!】
论文1:AgentThink: A Unified Framework for Tool-Augmented Chain-of-Thought Reasoning in Vision-Language Models for Autonomous Driving [清华]
- Motivation(VLMs面临的挑战)
- Hallucinations and Inconsistencies:VLMs 在处理复杂场景时,常常生成幻觉
- Lack of Dynamic Verification:大多数现有方法依赖于从预定义轨迹中学习,缺乏对知识不确定性的检测能力,也无法调用工具进行中间验证
- Static Nature of Reasoning:VLMs 通常将推理视为静态的输入-输出映射,缺乏动态调整和验证推理路径的能力
- Contribution
- Structured Data Generation:建立工具库,自动生成结构化的、自验证的推理数据
- A Two-stage Training Pipeline:SFT + GRPO
- Agent-style Tool-Usage Evaluation:引入一种新的多工具评估协议,严格评估模型的工具调用和使用
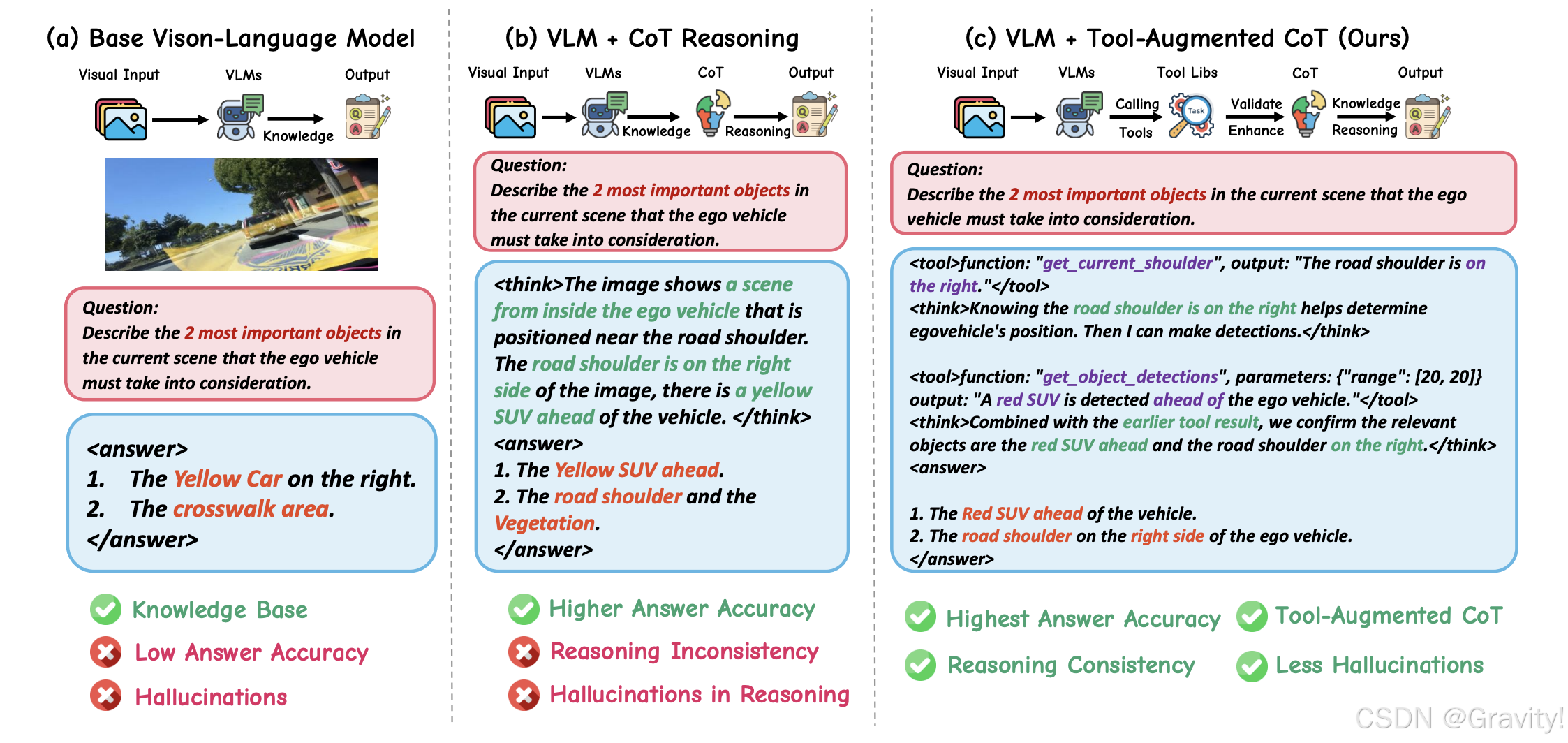
- Architecture
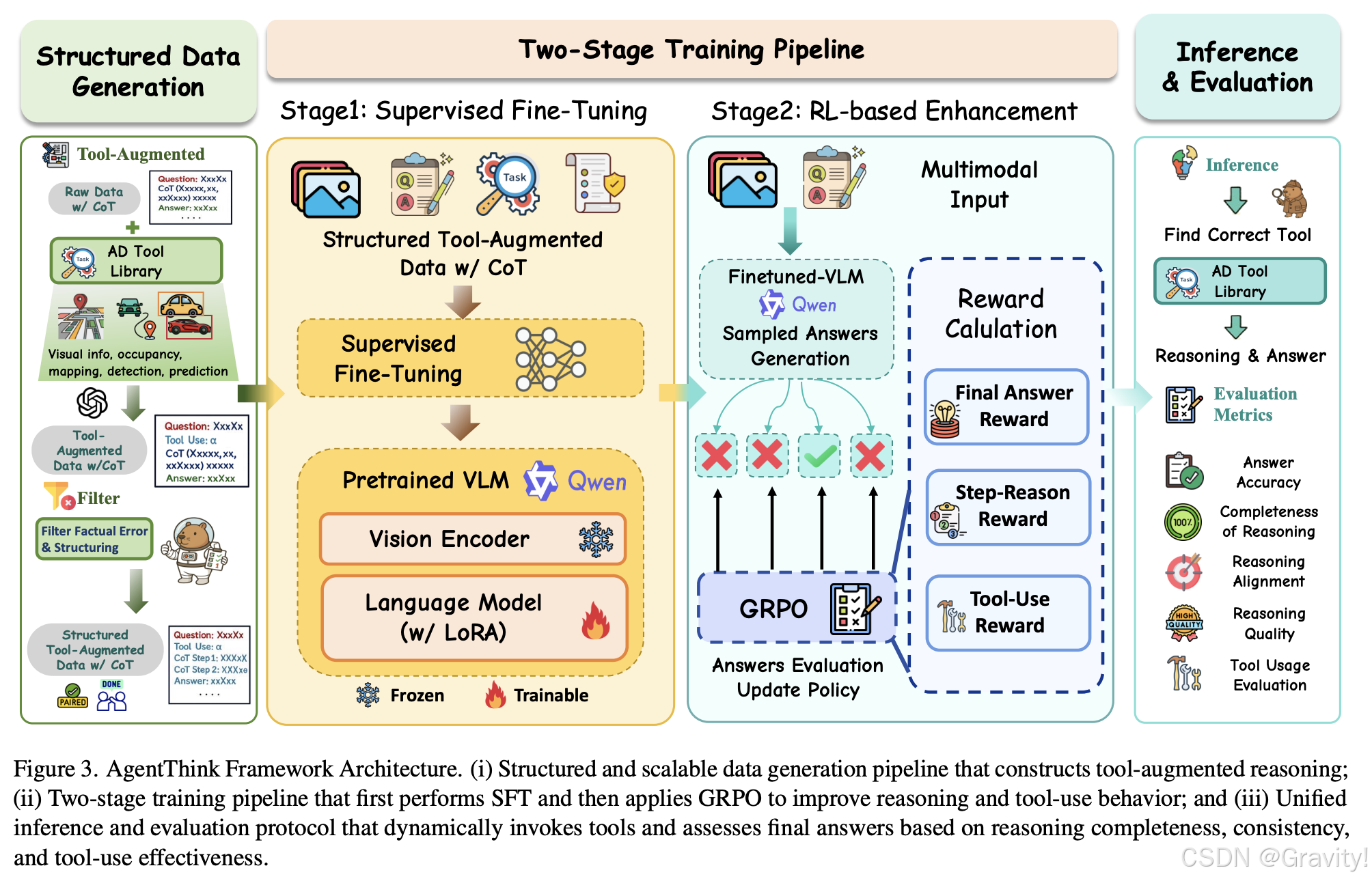
- Data Generation Pipeline
- 作用:创建一个结构化的数据集,将工具使用明确整合到推理过程中
- 组成:
- Tool Library(函数集合):获取环境信息,包括视觉信息提取、目标检测、轨迹预测、占用查询和地图信息等
- Prompt Design:引导模型生成包含工具调用的推理链,而不是直接生成答案 选择的工具 → 生成的子问题 → 不确定性标志 → 猜测的答案 → 下一步操作选择(继续推理或得出结论)
- Data Assessment:一个独立的 LLM 对每个sample进行事实准确性和逻辑一致性检查
- 两阶段的训练Pipeline
- Stage1 SFT:预热模型的推理能力,使其能够生成合理的推理链和适当的工具调用
- Stage2 GRPO 强化学习
- Final Answer Reward:验证最终答案是否与真实答案一致逐步推理奖励
- Step Reasoning Reward:评估中间步骤的逻辑性和结构
- Step Matching:与参考步骤对齐并惩罚不正确的顺序
- Coherence:步骤之间的平滑、逻辑过渡
- Tool Use Reward:促进适当且有意义的工具使用
- Format Compliance:遵守预期的输出结构(E.g. “Tool”,“Step Reasoning”)
- 整合质量(Integration Quality):将工具输出有效地、连贯地整合到推理中
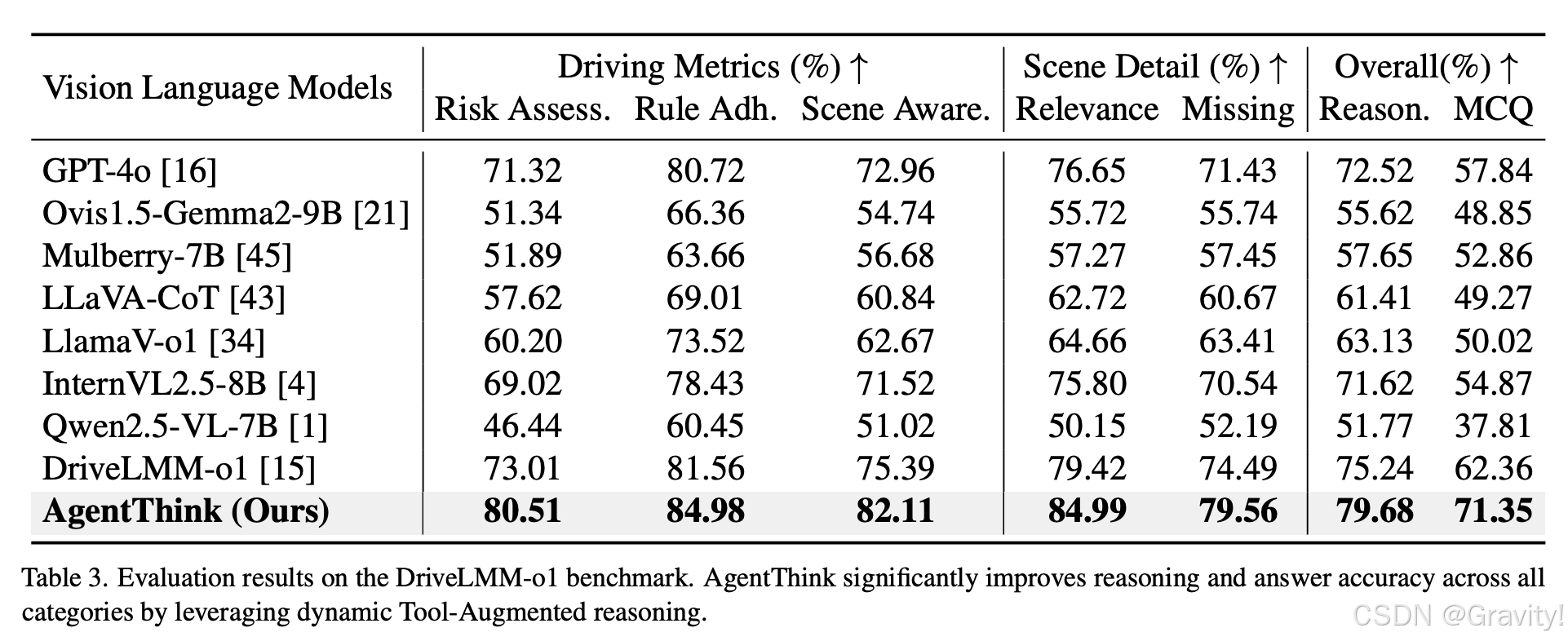
- 实验
论文2:DriveMoE: Mixture-of-Experts for Vision-Language-Action Model in End-to-End Autonomous Driving [上交]
- Mixture-of-Experts (MoE) :模型由多个“专家”模型组成,每个“专家”负责其特定领域;由门控网络Router来控制哪个“专家”来回答问题
- 灵活性:每个专家模块可以专注于处理特定的任务或数据子集
- 效率:通过动态选择相关的专家模块,MoE 可以减少不必要的计算
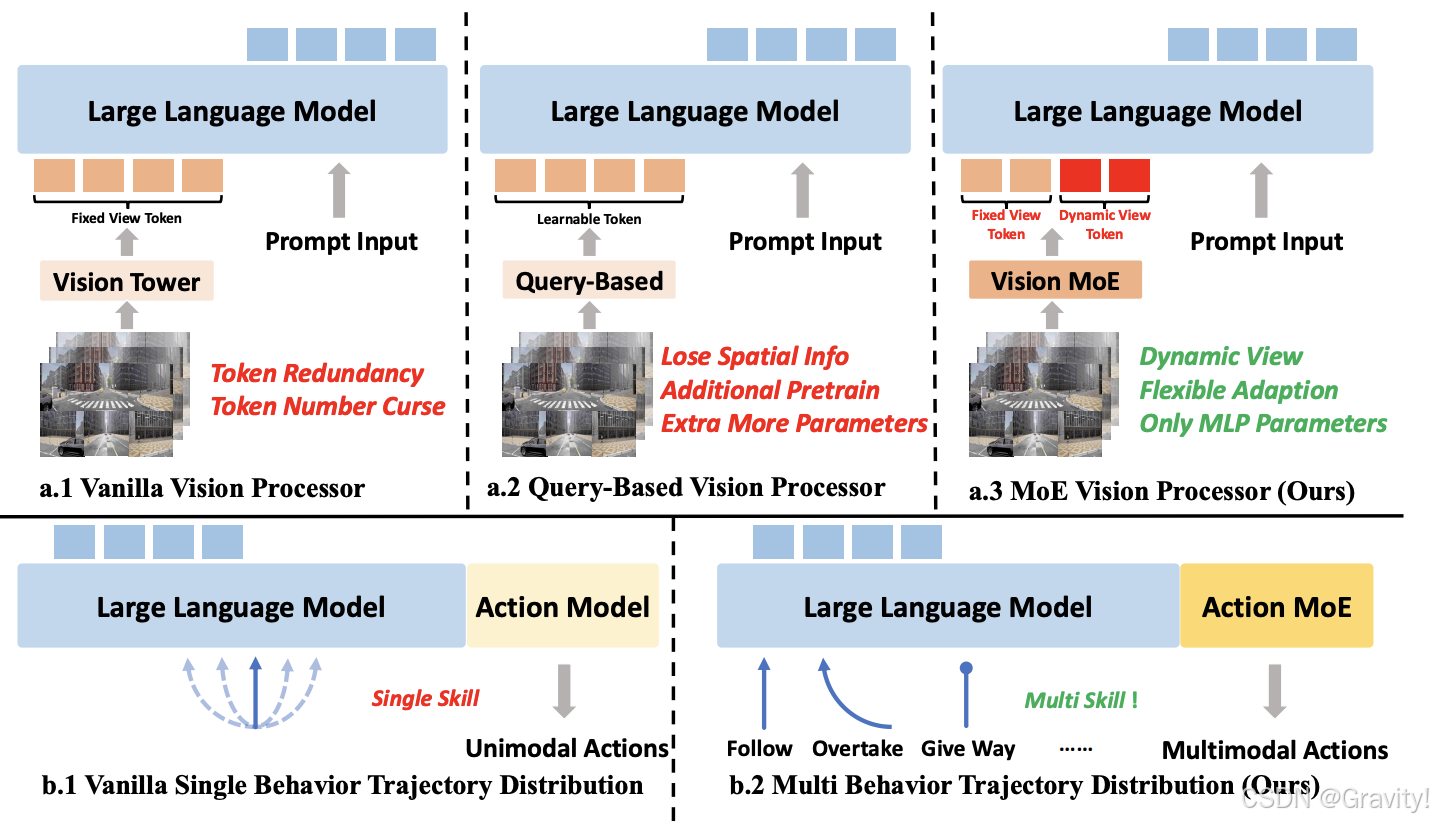
- 传统多视角视觉输入处理策略:
- 普通视觉处理器(Naïve Visual Processor):用所有的vision tokens,计算负担大,引入大量冗余信息,导致模型效率低下,难以扩展至实时系统
- 基于查询的视觉处理器(Query-based Visual Processor):使用学习到的查询(如Q-former模块)压缩多视图信息为一组紧凑的视觉token。但丢失精确的几何和位置信息,需额外预训练,增加工程复杂度。
- DriveMoE的改进:通过轻量级路由器动态选择与当前驾驶场景最相关的视图
- Framework
- Drive-π0 Baseline:基于 VLA 框架的端到端基础模型
- 输入:多视角图像序列、固定文本提示、当前车辆状态(包括速度、偏航率和过去的轨迹)
- Paligemma VLM as backbone + Flow-matching planner
- From Drive-π0 to DriveMoE
- Drive-π0问题: 多视角处理的低效性(信息冗余和计算开销);多样化驾驶行为的不足(例如处理紧急制动或激进转弯时,表现不佳)
- 解决方案:引入 MoE 架构,动态选择相关的相机视图和激活特定的专家模块
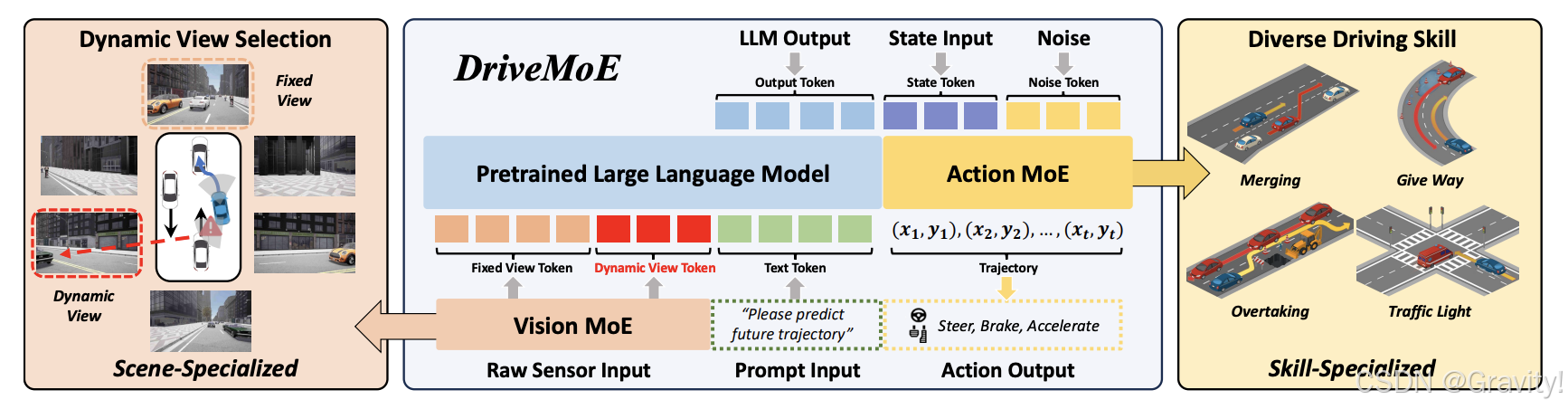
- Drive-π0 Baseline:基于 VLA 框架的端到端基础模型
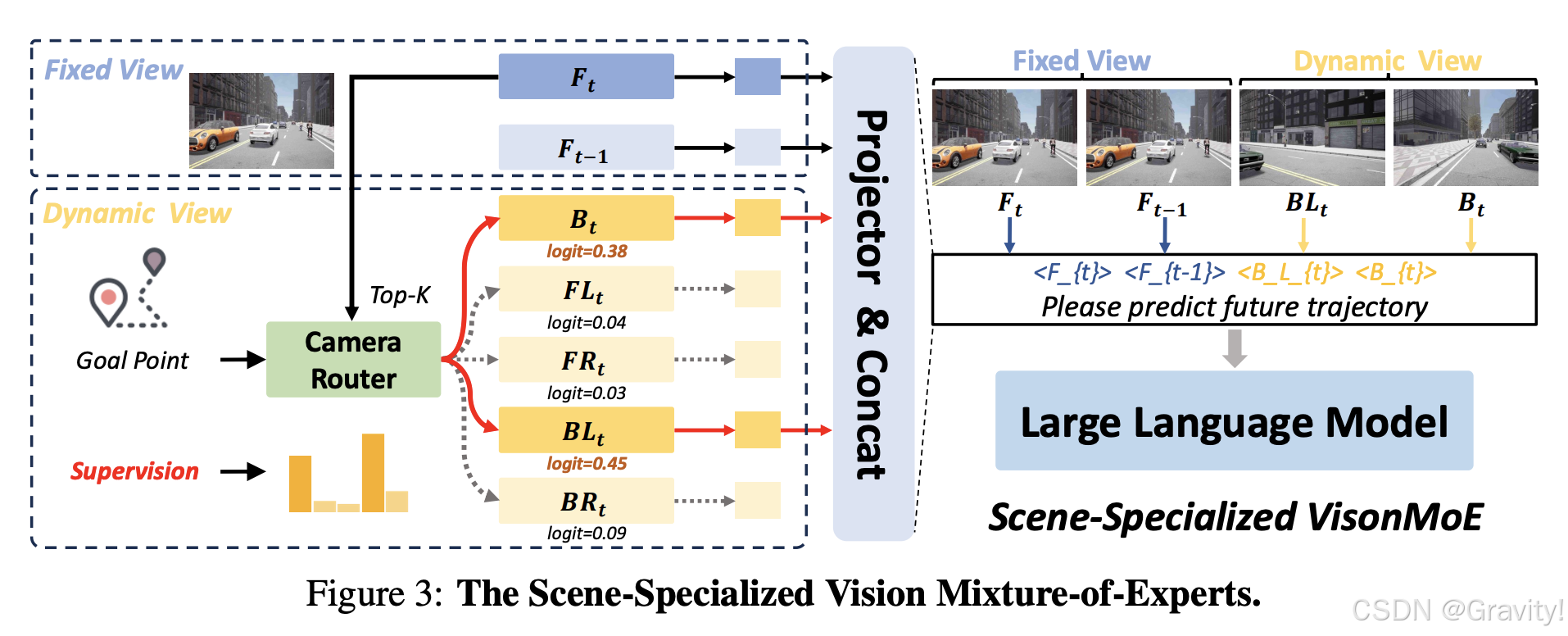
- Scene-Specialized Vision MoE
- Motivation: 模仿人类驾驶员在特定驾驶场景中优先关注关键视觉信息的行为,减少冗余的视觉输入
- 引入轻量级Vision Router,根据当前驾驶上下文和未来的导航目标点动态选择相关的相机视图
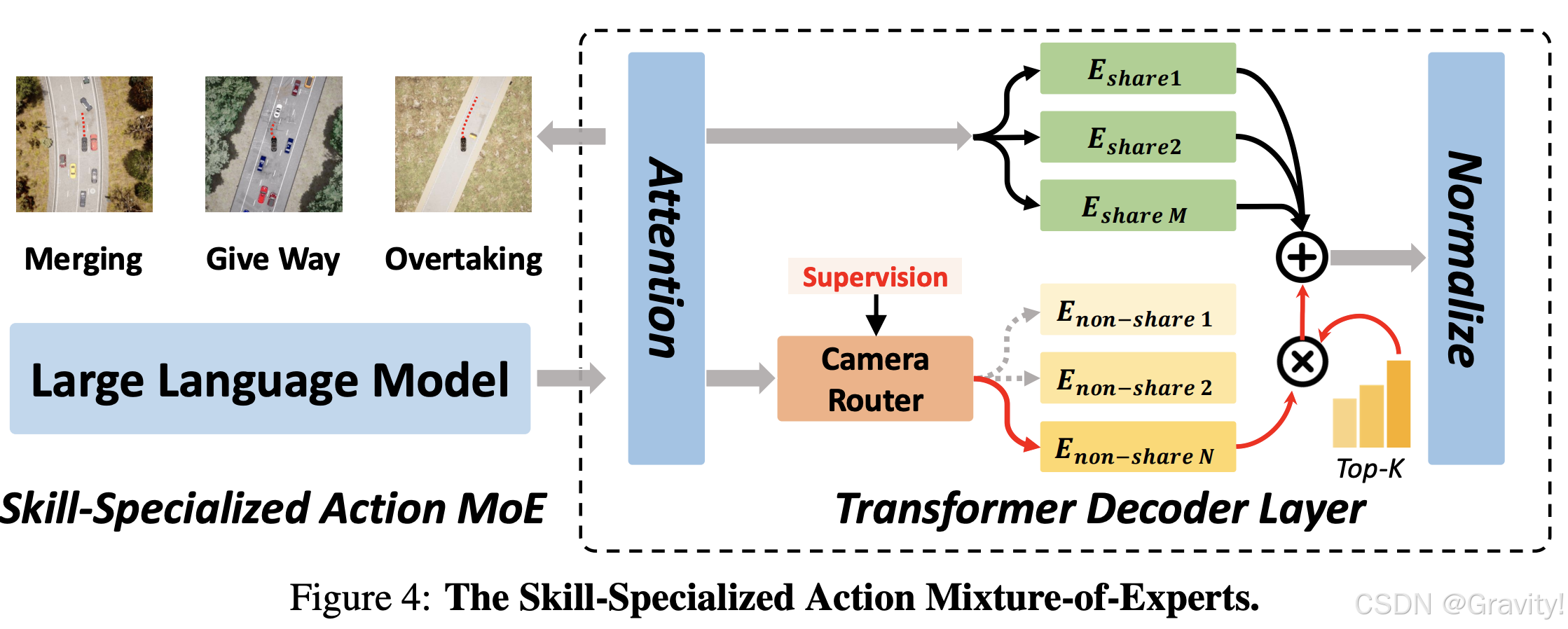
- Skill-Specialized Action MoE
- Motivation: 人类驾驶员在不同驾驶场景中会切换不同的驾驶技能
- 在Decoder中用包含多个技能专用专家的 MoE 层替换每个FFN
- 训练策略
- 第一阶段:依赖专家标签监督路由模块训练。
- 第二阶段:过渡到完全自适应路由,增强模型对实际推理中路由误差的鲁棒性。
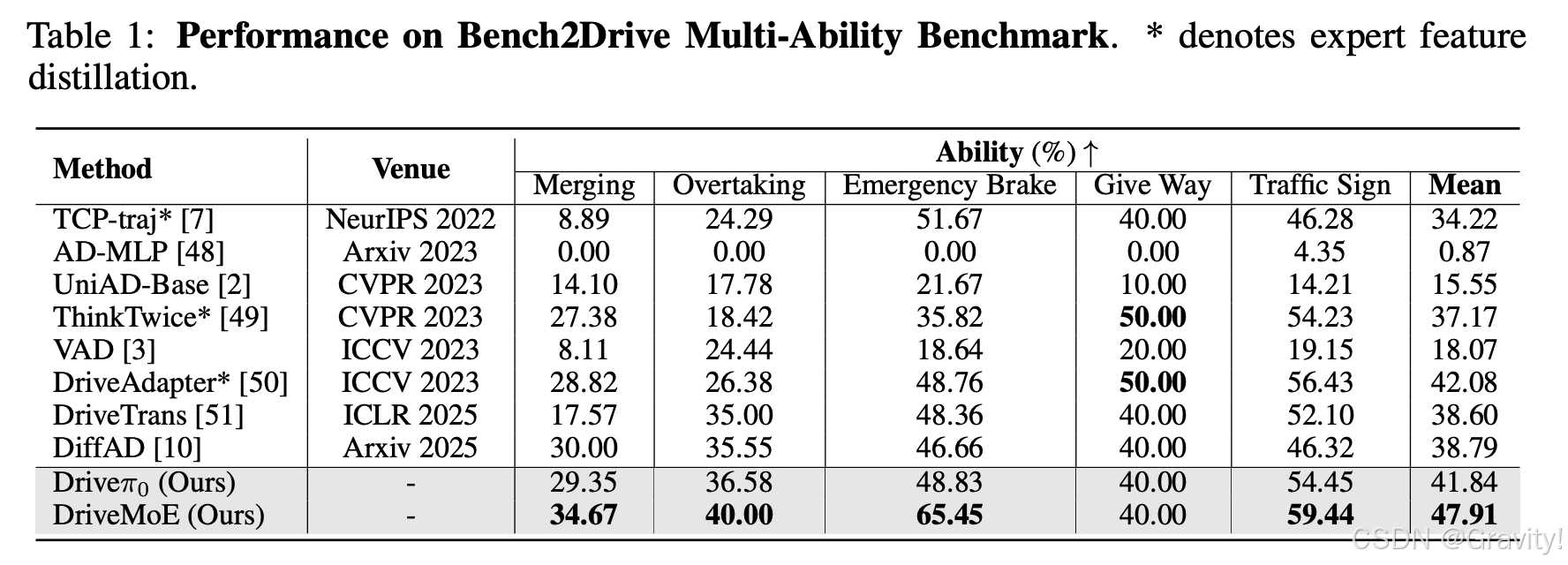
- 实验

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 8
8 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)