(2024|CVPR|Meta,VistaLLM,图像分割,多任务 VLM)设计通用的粗到精视觉语言模型
本文提出 VistaLLM,一个通用视觉系统,能够在单图像和多图像输入的情况下,同时处理 粗粒度和细粒度的视觉-语言任务。该模型利用指令引导的图像编码器和梯度感知自适应采样技术来优化输入处理,并使用新构建的数据集(CoinIt) 进行训练
Jack of All Tasks, Master of Many: Designing General-purpose Coarse-to-Fine Vision-Language Model

目录
1. 引言
随着大语言模型(LLM)的发展,其在视觉领域的应用也越来越广泛。当前的通用视觉-语言(VL)模型通过指令调优(Instruction Tuning)来统一不同的视觉任务。然而,由于视觉任务在输入输出格式上的多样性,现有的通用模型难以在单一框架内集成 分割任务 和 多图像输入 的任务。
本文提出 VistaLLM,一个通用视觉系统,能够在 单图像和多图像输入 的情况下,同时处理 粗粒度和细粒度的视觉-语言任务。该模型利用 指令引导的图像编码器 和 梯度感知自适应采样技术 来优化输入处理,并使用 新构建的 6.8M 样本数据集(CoinIt) 进行训练。
关键词:通用视觉模型、多模态学习、指令调优、分割、视觉推理、目标检测、VistaLLM、CoinIt
2. 相关工作
近年来,多模态大模型(MLLM)被广泛应用于各种视觉和语言任务。其中,模型可以分为:
粗粒度 MLLMs:主要用于 图像级任务(如 图像分类、图像描述、视觉问答),不需要对图像局部信息进行建模,如 LLaVA、MiniGPT-4 等。
细粒度 MLLMs:能够处理 目标检测、区域级引用理解(REC)、分割(RES) 等任务,如 Shikra、GPT4RoI 等。
然而,现有的通用模型 无法在一个框架内同时集成分割和多图像推理任务。
3. 方法
3.1 模型架构
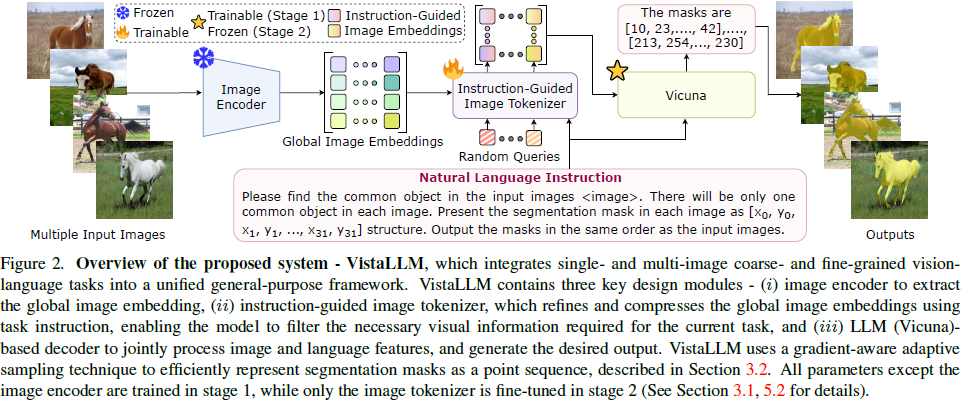
VistaLLM 由以下三部分组成:
图像编码器(EVA-CLIP):用于提取全局图像特征。
指令引导的图像分词器(Instruction-guided Image Tokenizer,QFormer):
- 通过任务描述提取相关信息,过滤不必要的视觉特征。
- 压缩图像嵌入,适应不同数量的输入图像。
- 使得多张不同尺寸的输入图像能够映射到相同的特征空间。
语言模型(LLM):
- 使用 Vicuna,一个 decoder-only 的 LLM,上下文长度为 2048,通过指令微调 LLaMa 构建
- 通过输入 视觉特征 + 语言指令,生成任务所需的输出。
- 采用 序列到序列(seq2seq) 方式处理任务。
3.2 自适应采样技术
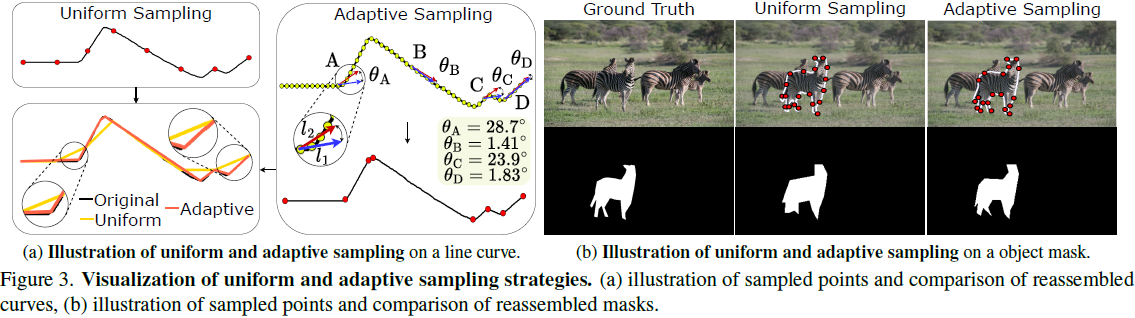
在分割任务中,传统的 均匀采样 方式难以精确表示复杂的目标轮廓。VistaLLM 提出了 梯度感知自适应采样(Adaptive Sampling):
- 首先 计算轮廓梯度,然后在 高曲率区域增加采样点,在 直线区域减少采样点,以更有效地表示分割边界。
- 在 RefCOCO 数据集 上,该方法使得分割精度(mIoU)提升 3~4%。
4. 数据集
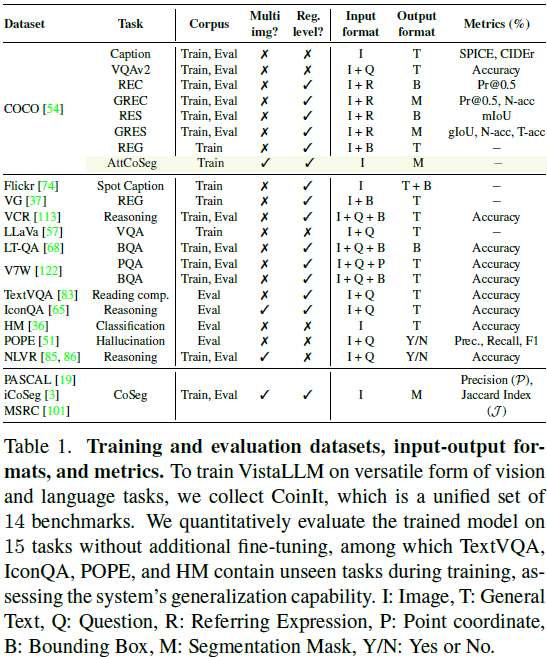
为支持 VistaLLM 的训练,本文构建了 CoinIt 数据集,共包含 6.8M 样本,涵盖 14 个基准数据集。CoinIt 任务类别:
- 单图像粗粒度任务(如 COCO Caption、VQA)。
- 单图像细粒度任务(如 目标检测、分割)。
- 多图像粗粒度任务(如 NLVR)。
- 多图像细粒度任务(如 共同分割 CoSeg)。
此外,新引入了 AttCoSeg(attribute-level co-segmentation,属性级共分割任务)
- 使用 Group-wise RES 注释来采样包含具有相似细粒度属性(形状、颜色、大小、位置)的对象的高质量图像
- 将此类图像称为正例,在训练 VistaLLM 时,输入这些正例图像对,要求模型分割具有共同特征的对象
- 该 Benchmark 包含 804K 训练样本,用于多图像分割场景。
5. 实验
5.1 主要实验结果
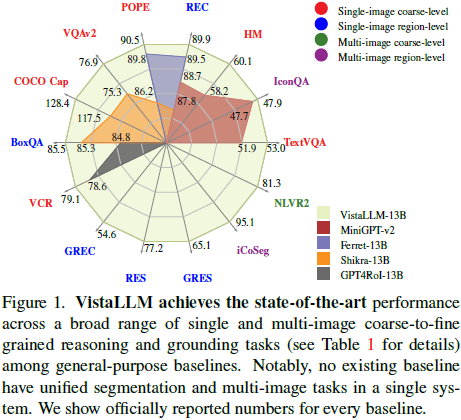
VistaLLM 在 15 个基准任务 上进行了评估,并在多个任务上超过了现有的 SOTA 模型。
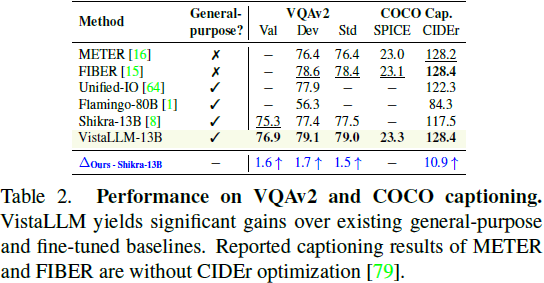
1)视觉问答(VQAv2):VistaLLM 在 VQA 任务 上提升精度 1.5%,在 COCO Caption 任务 上超越 Shikra-13B 10.9 CIDEr。
2)目标检测(REC/GREC):VistaLLM 在 GREC 任务 上相比 MDETR 提升 13.1%。
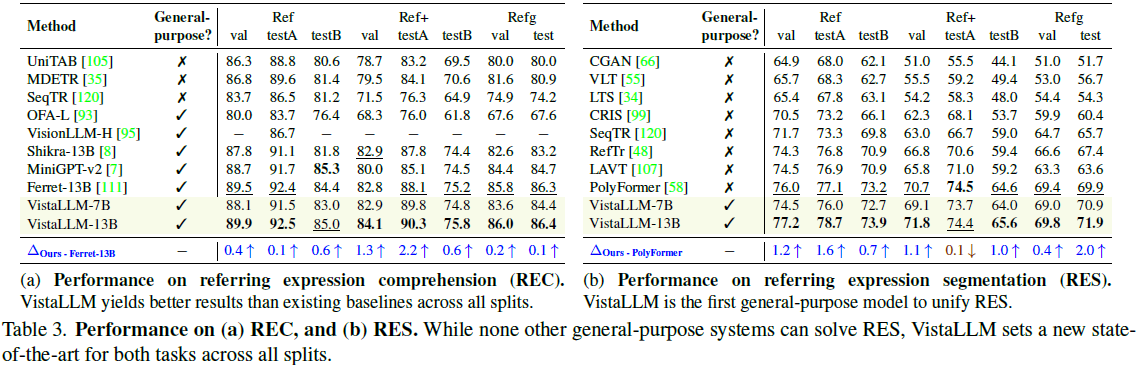
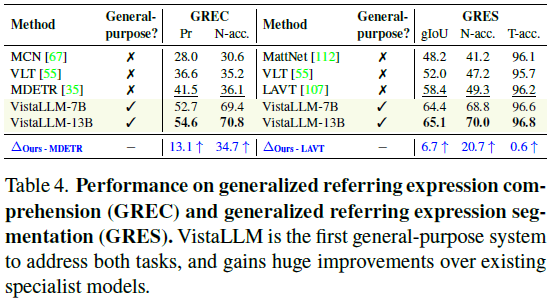
3)分割任务(RES/GRES):首次在 通用视觉框架 内支持 分割任务,在 RefCOCO 分割任务上 超越 SOTA 模型。
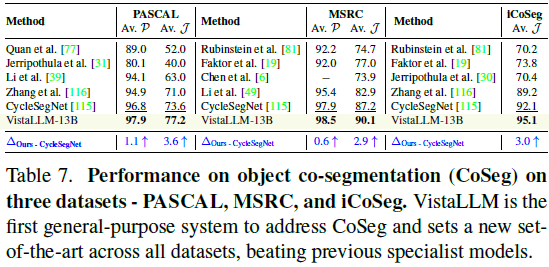
4)多图像任务(CoSeg、NLVR):首次支持 CoSeg 任务,并在 PASCAL、MSRC、iCoSeg 数据集上超越 特定优化的分割模型。
5.2 关键消融实验
自适应采样 vs. 均匀采样:使用 32 采样点时,自适应采样 mIoU 比均匀采样高 2.5%。
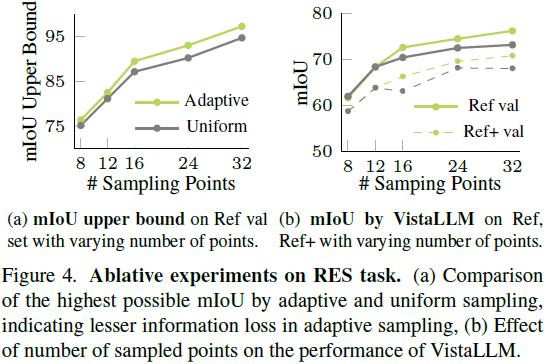
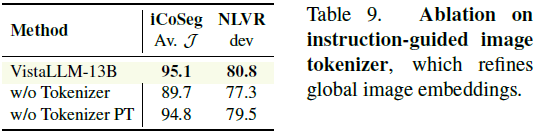
指令引导的图像分词器:如果去掉该模块,iCoSeg 任务的 J 指数下降 5.4%。

6. 视觉化分析
VistaLLM 在不同任务上的输出可视化展示了其多方面能力:
- 单图像推理:在 GRES 任务中 成功定位多个目标,并生成准确的分割掩码。
- 多图像推理:在 AttCoSeg 任务中 能够识别多个图像中的相似目标,并生成精确的分割结果。
但 VistaLLM 在 常识推理和知识性问答 方面仍然 落后于 GPT-4V。
7. 结论
主要贡献:
- 提出 VistaLLM,一个 通用的视觉-语言模型,能够同时处理 单/多图像任务、粗粒度/细粒度任务。
- 提出梯度感知自适应采样,提高分割任务的序列表达能力,使其可集成到通用 VL 模型中。
- 构建 CoinIt 数据集(6.8M 样本),涵盖多种 VL 任务,并引入 AttCoSeg 任务,填补 多图像分割数据集 的空白。
- 在 15 个基准任务上超越现有 SOTA 模型,特别是在 分割、目标检测、多图像推理 方面取得突破。
未来工作:
- 提升常识推理能力:VistaLLM 在知识问答方面仍有欠缺,未来可以结合 知识增强(knowledge augmentation) 进一步优化。
- 优化计算效率:VistaLLM 的 多图像处理 仍然较慢,未来可探索 轻量级特征压缩 技术。
- 更广泛的数据集适配:扩展到 医疗影像、遥感、自动驾驶等领域,使 VistaLLM 具备更强的通用性。
论文地址:https://arxiv.org/abs/2312.12423
项目页面:https://shramanpramanick.github.io/VistaLLM/
进 Q 学术交流群:922230617 或加 V:CV_EDPJ 进 V 交流群

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)