Scene-Dependent Prediction in Latent Space for Video Anomaly Detection and Anticipation
视频异常检测(VAD)在智能监控中起着至关重要的作用。然而,一种名为场景依赖异常的重要异常类型却被忽视了。此外,视频异常预测(VAA)任务也值得关注。为了填补这些空白,我们构建了一个名为西北工业大学校园(NWPU Campus)的综合数据集,它是最大的半监督 VAD 数据集,也是首个用于场景依赖 VAD 和 VAA 的数据集。同时,我们引入了一种新颖的用于场景依赖 VAD 和 VAA 的前向 -

中文标题:视频异常检测与预测的潜在空间场景依赖方法
类型:VAD
发布于:TPAMI2024(CCF-A)
源码地址:https://github.com/zugexiaodui/campus_vad_code
Abstract
视频异常检测(VAD)在智能监控中起着至关重要的作用。然而,一种名为场景依赖异常的重要异常类型却被忽视了。此外,视频异常预测(VAA)任务也值得关注。为了填补这些空白,我们构建了一个名为西北工业大学校园(NWPU Campus)的综合数据集,它是最大的半监督 VAD 数据集,也是首个用于场景依赖 VAD 和 VAA 的数据集。同时,我们引入了一种新颖的用于场景依赖 VAD 和 VAA 的前向 - 后向框架,其中前向网络单独解决 VAD 问题,并与后向网络共同解决 VAA 问题。特别地,我们为前向和后向网络提出了一种潜在空间的场景依赖生成模型。首先,我们提出了一种分层变分自编码器来提取场景通用特征。接下来,我们在潜在空间中设计了一个基于分数的扩散模型,以使这些特征更紧凑地适应任务,并通过一个场景信息自编码器生成场景依赖特征,从而对视频事件和场景之间的关系进行建模。最后,我们从关键帧开发了一个时间损失来约束视频片段的运动一致性。大量实验表明,我们的方法能够很好地处理场景依赖异常检测和预测,在上海科技大学、香港中文大学大道以及提出的西北工业大学校园数据集上达到了最先进的性能。
I. INTRODUCTION
视频异常检测(VAD)是视频监控中的一项关键任务。由于异常的无界性和稀有性,VAD 通常被设定为一个半监督任务,在训练数据中只有无特定标签的正常事件 [1,2]。半监督 VAD 已经被研究了多年,其长期目标是训练一个单类分类器,能够忠实地学习正常数据分布,同时避免对异常的不期望泛化。为此,近年来,基于重建的 [3,4,5] 和基于预测的 [6,7,8] 深度学习方法涌现并取得了很大进展。
然而,视频异常检测(VAD)领域主要致力于寻找一种通用的场景方法来检测视频中的异常,而不考虑关键的场景信息[2]。如图 1 所示,现有的与场景无关的方法通常依赖深度自编码器从视频中对象的正常运动特征中学习。因此,这些方法对场景的理解有限。对于像图 1 中所示的骑自行车者这样的场景依赖异常(在道路上正常但在广场上异常),与场景无关的方法无法检测到这种场景依赖异常。相比之下,我们建议提取并使用场景信息作为帧重建或预测的条件,使我们的模型能够准确区分场景依赖异常。除了检测各种正在发生的异常外,用于预测即将到来的未来异常的视频异常预测(VAA)也是一项值得研究人员关注的实际任务。如果我们能在异常发生前发出预警,就很有可能避免巨大的生命和财产损失。然而,根据我们的调查,在这个任务上没有相关工作或数据集。
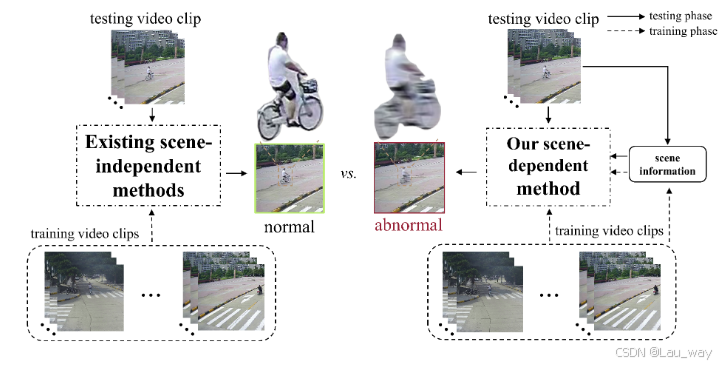
图 1. 不同视频异常检测(VAD)范式的比较。图中的骑自行车者是一个场景依赖型异常,在这个广场场景中是异常的,但在像道路等其他场景中是正常的。现有的与场景无关的 VAD 方法忽略了场景背景,因此它们无法检测到场景依赖型异常。我们的场景依赖型方法是根据场景条件定制的,使我们的模型能够准确区分场景依赖型异常。
有几个方面使得场景依赖的视频异常检测(VAD)和视频异常预测(VAA)成为艰巨的任务。首先,在 VAA 中未来的帧是不可见的,因此无法计算预测误差。其次,大多数基于重建和基于预测的 VAD 方法[6,7,8,9,10]依赖深度自编码器,然而这些模型保留关键输入信息的能力有限,常常阻碍了它们的性能。此外,现有的方法[11,12,13,14]专注于从正常数据中学习,却忽视了位于低概率密度区域的异常[1,15],导致了一个过于简化的单类分类器,无法全面适应这些任务。当模型过度关注局部信息或陷入过于简化的单类分类器时,结合场景信息的难度就会增加。最后但同样重要的是,静态场景信息和动态视频信息的分布差异很大,基于场景信息对视频帧进行有效可控的预测没有明确的约束条件。
为了解决未来帧不可用的问题,我们提出了一种新颖的用于视频异常检测(VAD)和视频异常预测(VAA)的前向 - 后向框架。该框架包含一个前向和一个后向基于预测的网络,两者具有相同的架构。前向网络通过基于先前帧预测当前帧来单独解决 VAD 任务,而后向网络则根据前向网络生成的未来帧和一部分观测帧反向预测一个观测帧。我们用过去观测帧的误差来替代计算未来帧的预测误差,从而解决了 VAA 任务。
针对视频异常检测(VAD)模型的能力有限或过度简化问题,在该框架中,我们为前向和后向网络设计了一个生成式帧预测模型,即基于分数的场景依赖自动编码器(SSAE)。具体而言,为了设计一个能够强大到保留输入关键信息的模型,我们引入了一个强大的分层变分自动编码器(HVAE)来尽可能多地提取场景通用特征。接下来,为了更好地区分位于低概率密度区域的异常,我们实施了一个基于分数的扩散模型(SDM),在潜在空间中对 HVAE 提取的特征进行优化,通过分数匹配将我们的场景通用特征集中在高概率密度区域。
为了对视频事件和场景之间的关系进行建模,我们构建了一个小型自动编码器来获取场景条件的潜在表示。我们通过场景重建来优化场景表示的质量。受到基于扩散模型的条件合成成功案例[16, 17]的启发,我们将此场景条件嵌入到 SDM 中以生成场景依赖的潜在特征,使我们的模型能够区分场景依赖的异常。此外,我们基于关键帧之间的分布差异添加了一个时间相干损失,以确保我们的模型能够有效捕捉视频中的时空相关性。所提出的 SSAE 的整体架构如图 2 所示。
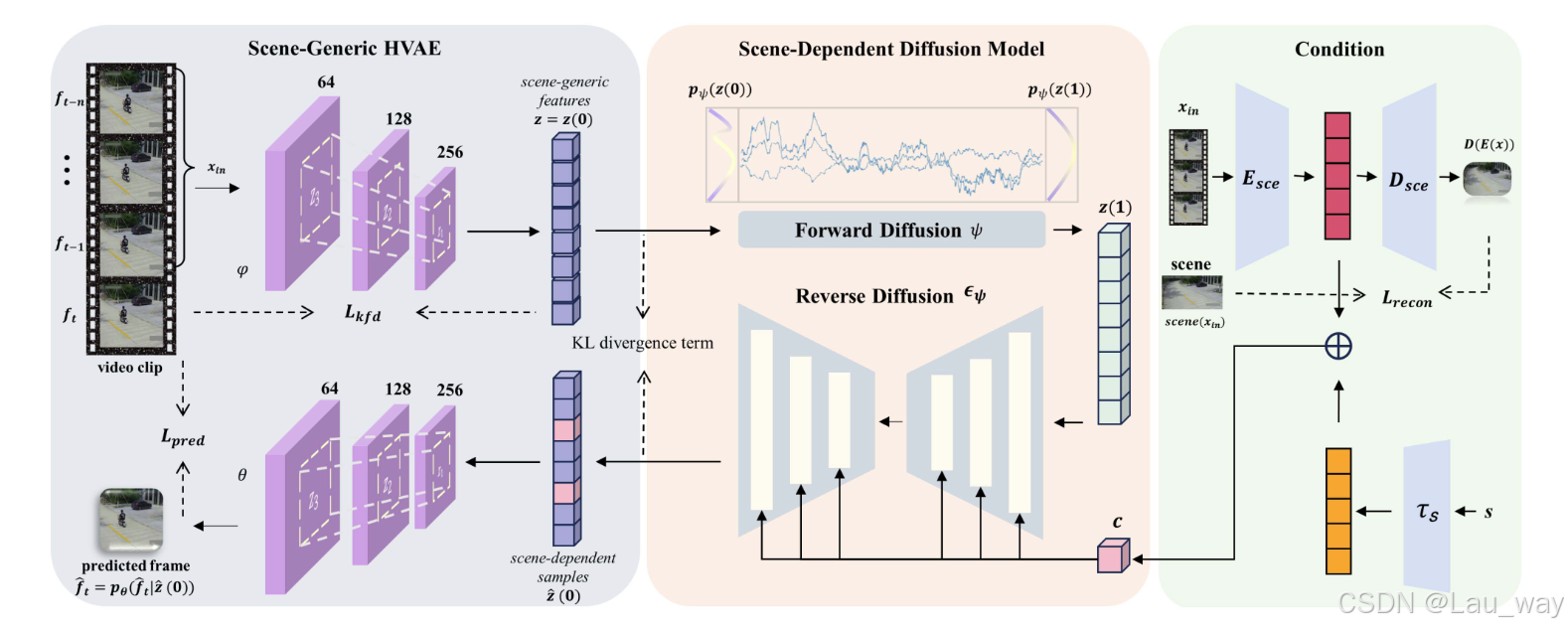
图 2. 我们基于分数的场景依赖自动编码器模型的示意图。它由三个组件组成:一个带有编码器
和解码器
的分层变分自编码器(VAE)、一个带有去噪器
的基于分数的扩散过程
,以及一个带有小型编码器
和解码器
的场景调节模块。为了控制噪声水平,扩散时间步长 s 通过编码器
进行嵌入。当给定一个视频序列时,我们的 HVAE 编码器首先将输入编码为场景通用特征,场景调节编码器提取输入的场景信息。然后,我们的 SDM 扰乱场景通用特征的分布,并基于场景信息采样场景依赖特征。最后,场景依赖特征由我们的 HVAE 解码器解码为预测帧。
除了改进方法创新之外,我们注意到单场景数据集无法包含任何场景依赖型异常,而现有的多场景数据集(例如上海科技大学数据集 [18]、UBnormal 数据集 [19])仅涵盖跨场景的一般异常。因此,我们提出了一个新的综合数据集——西北工业大学校园(NWPU Campus)数据集,用于场景依赖的视频异常检测(VAD)和视频异常预测(VAA)。我们有意考虑了场景依赖型异常以及异常事件的完整趋势。据我们所知,我们的 NWPU Campus 数据集是首个针对场景依赖的 VAD 和 VAA 提出的数据集。在帧数、场景多样性和异常类型方面,它也是最大的半监督 VAD 数据集。
最后,我们在多个基准数据集上进行了大量实验,包括上海科技大学数据集 [18]、香港中文大学大道数据集 [20]、印度理工学院孟买分校走廊数据集 [21] 以及我们提出的西北工业大学校园数据集。在这些基准数据集上进行的大量实验表明,我们的方法优于其他方法,并达到了最先进的性能。我们的贡献如下:
- 一个新的数据集——西北工业大学校园(NWPU Campus)数据集,它是最大的多场景半监督视频异常检测(VAD)数据集,也是首个不仅包含场景依赖异常,还考虑到适用于预测的异常的数据集。
- 一个用于场景依赖的视频异常检测(VAD)和视频异常预测(VAA)的有效前向 - 后向框架,在该框架中,前向网络单独解决 VAD 任务,并与后向网络共同解决 VAA 任务。
- 一种用于前向和后向网络的新颖生成模型 SSAE,它是一个潜在空间中的 SDM(基于分数的扩散模型),借助强大的 HVAE(分层变分自动编码器)为场景依赖的 VAD 和 VAA 生成场景依赖特征。
- 一种新颖的条件策略,它基于场景重建,在学习到的分布下有条件地生成场景依赖特征。
- 一种有用的时间损失,它基于关键帧来约束视频片段的运动一致性。
- 在上海科技大学、香港中文大学大道、印度理工学院孟买分校走廊以及我们的西北工业大学校园数据集上进行了全面验证,在这些数据集上我们的模型在 RGB 域中达到了最先进的性能,充分证明了其有效性。
本文是我们之前工作[8]的扩展。我们在以下几个方面对初步版本进行了扩展:1) 本文中的模型是一种新型 SDM(基于分数的扩散模型)和 HVAE(分层变分自动编码器)的耦合模型。我们通过多尺度分层架构增强了初步版本的 VAE,并应用基于分数的扩散模型以获得更具表现力的模型。2) 我们改进了场景调节策略。与之前使用条件 VAE 和独热编码的工作相比,我们利用 SDM 实现了条件生成,并通过一个小型自动编码器提取了更具表现力的场景表示,这能更好地对视频事件和场景之间的关系进行建模。3) 我们引入了基于关键帧的运动一致性损失,以优化视频序列中的运动信息。4) 本文进行了更多的消融研究和对比实验,结果表明我们的方法在上海科技大学、香港中文大学大道、印度理工学院孟买分校走廊以及提出的西北工业大学校园数据集上分别取得了 1.3%、3.4%、2.2%和 7.4%的性能提升。
II. RELATED WORK
A. Video Anomaly Detection Methods
在本文中,我们专注于半监督视频异常检测(VAD)。常见的半监督VAD方法主要包含基于距离的[22, 23, 24]、基于重建的[3, 4, 5, 25]以及基于预测的[6, 7, 8, 9, 10, 11, 12, 13, 14, 17, 26, 27, 28, 29]方法。尤其是基于预测的方法近年来受到了广泛关注。基于预测的方法的典型流程是根据先前帧预测当前帧,并计算当前的异常分数[6, 7, 9, 11, 13, 14, 26, 27]。为了区分异常运动和正常运动,一系列方法[7, 9, 14]使用光流,而其他一些方法[30, 31]直接去除背景以增强帧预测效果。结合能够存储并利用正常模式的记忆模块[14, 26, 27, 28]也是提升模型能力的一种常用方式。除了预测当前帧之外,基于诸如扩散模型等强大的生成模型,预测运动[10]或特征[17]也能取得令人瞩目的成果。此外,一些基于预测的方法通过双向帧预测来补全中间帧[12, 29]。最后但同样重要的是,数据增强也是一种迫使模型全面覆盖正常模式的有效方式。研究人员会生成更多样的正常数据用于训练[17, 32],或者通过多尺度变形场增强正常模式的多样性[33]。
与上述所有忽视场景信息甚至去除背景来检测视频异常的工作[30, 31]不同,我们的方法是根据场景条件定制的,能使我们的模型区分出依赖场景的异常情况。除了视频异常检测(VAD)之外,我们的方法利用一个前向 - 后向框架,基于正向预测出的未来帧反向预测过去的帧,从而解决视频异常预测(VAA)任务。
B. Score-Based Generative Models
近年来,生成式模型取得了重大进展,其中结合朗之万动力学用于分数匹配的扩散模型[34] [35] [36]展现出了显著优势。分数函数被定义为对数密度相对于输入的梯度。朗之万动力学算法[35]利用这些梯度的方向,将随机样本朝着高密度区域的样本移动。因此,训练基于分数的扩散模型可以被理解为训练一个分数匹配器[37] [38] [39] [40]。基于条件的分数扩散模型一直备受关注。卡拉斯等人[40]试图将基于分数的扩散模型拆分成各个独立的组件,这样就可以在不影响其他单元的情况下修改单个部分。他们提出了一种条件采样过程,该过程使用休恩方法[41]作为常微分方程(ODE)求解器,在保持性能的同时减少了对神经函数的评估次数。何等人[39]引入了一种基于源自贝叶斯规则的隐式引导的调节策略。它只需要一个有条件和无条件的版本,二者共享同一个模型来学习相应情况。
与那些利用去噪扩散模型[34]来预测特征[10]或运动[17]以进行视频异常检测(VAD)的相关工作不同,我们提出了一种基于场景条件的分数扩散模型,以便有条件地预测帧,用于依赖场景的视频异常检测及预测。训练一个分数匹配器更适合这些任务,因为它恰好满足在低概率密度区域检测异常值时异常检测及预测的基本要求[1, 15]。
C. Video Anomaly Detection Datasets
常用的半监督视频异常检测(VAD)数据集包括加州大学圣地亚哥分校行人1号和行人2号数据集(UCSD Ped1 & Ped2)[42]、地铁出入口数据集(Subway Entrance & Exit)[43]、明尼苏达大学数据集(UMN)[44]、香港中文大学大道数据集(CUHK Avenue)[20]、上海科技大学数据集(ShanghaiTech)[18]、街景数据集(Street Scene)[45]、印度理工学院孟买分校走廊数据集(IITB Corridor)[21]以及UBnormal数据集[19]。由于我们专注于半监督VAD,诸如加州大学欧文分校犯罪数据集(UCF-Crime)[46]和XD - 暴力数据集(XD-Violence)[47]等弱监督VAD数据集将不在讨论范围内。 加州大学圣地亚哥分校行人1号和行人2号数据集(UCSD Ped1 & Ped2)[42]中,每个数据集都包含一个俯瞰行人通道的摄像头,其中的异常大多是静态的异常物体。因此,在这些数据集上的性能已接近饱和(行人1号数据集上达到97.4% [48],行人2号数据集上达到99.2% [49])。 地铁出入口数据集(Subway Entrance & Exit)[43]着重呈现了两个室内地铁场景中的异常人类行为,比如走错方向或翻越闸机。 明尼苏达大学数据集(UMN)[44]描绘了三个室外场景,它只刻画了异常的人群疏散事件,且没有官方的数据划分。 香港中文大学大道数据集(CUHK Avenue)[20]包含一个对着建筑物侧面以及旁边行人通道的摄像头,其中的异常行为包括跑步、扔包、小孩蹦跳等。 上海科技大学数据集(ShanghaiTech)[18]涵盖了13个室外校园场景以及不少异常物体。然而,上海科技大学数据集中的异常事件在各个场景中是通用的,该数据集并不包含依赖场景的异常情况。 街景数据集(Street Scene)[45]引入了位置异常情况,比如违规停车。 印度理工学院孟买分校走廊数据集(IITB Corridor)[21]据我们所知是最大的单场景半监督VAD数据集,它聚焦于由志愿者造成的破坏走廊秩序的异常活动。 UBnormal数据集[19]是通过动画生成的,包含29个虚拟场景以及22种异常事件类型。然而,动画视频和真实录制的视频之间存在领域差异。阿斯辛托等人[19]不得不使用一个额外的模型(循环生成对抗网络,CycleGAN [50])来缩小这种领域差异。
我们注意到,上述所有数据集都没有考虑到场景依赖型异常以及异常预测情况。我们的西北工业大学校园(NWPU Campus)数据集是一个大规模数据集,涵盖了43个场景以及28种异常情况。它是首个包含场景依赖型异常并考虑到适用于预测的异常的数据集,满足了用于评估视频异常检测(VAD)和视频异常预测(VAA)的新基准的要求。
III. METHOD
我们基于分数的场景依赖自动编码器(SSAE)会积极学习在带有场景条件的潜在空间中,通过基于分数的扩散,依据过往视频序列来预测目标帧,这构成了我们用于视频异常检测(VAD)和视频异常预测(VAA)解决方案的核心。
视频异常检测(VAD)和视频异常预测(VAA)的基本概念在第三节A部分予以介绍。
用于视频异常检测(VAD)和视频异常预测(VAA)的前向 - 后向框架的流程在第三节B部分进行描述。
我们会在第三节C部分介绍分层变分自动编码器(HVAE),在第三节D部分介绍基于分数的扩散模型(SDM),并在第三节E部分介绍场景调节模块。
随后,我们会在第三节F部分描述所提出的用于训练的时间损失。
最后,异常分数的推理过程及计算方法在第三节G部分予以介绍。
A. Problem Formulation
视频异常检测(VAD)旨在检测当前时刻是否正在发生异常事件。我们将视频异常预测(VAA)任务定义为预测在未来一段时间内是否会发生异常事件,鉴于准确预测异常事件的发生时间既困难又无必要,所以进行这样的预测对于异常事件的早期预警是有意义且有用的。视频异常检测(VAD)和视频异常预测(VAA)任务如图3所示。
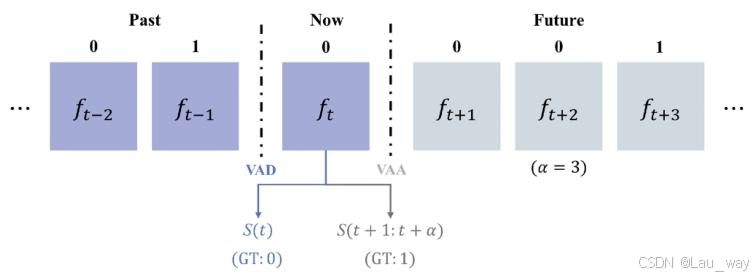
图3. 视频异常检测(VAD)和视频异常预测(VAA)示意图。
是在时刻t的帧。“0”表示正常,“1”表示异常。SO表示异常分数。
是预测时间。“GT”代表真实情况(标注)。紫色方块和灰色方块分别代表已观测到的帧和未观测到的帧。
1) 视频异常检测:假设当前时间步为t,输入的视频片段包含n个帧,即。视频异常检测(VAD)的目标是基于输入帧
为当前帧
计算一个异常分数
。我们将视频的帧级标签表示为
,其中
表示帧
是正常(0)还是异常(1),T为视频的长度。在图3中,
是一个正常帧,因此期望异常分数S(t)尽可能接近正常情况(0)。
2) 视频异常预测:对于视频异常预测(VAA)而言,在当前时刻t,我们要预测在尚未观测到的时间段内的任意未来帧中是否会出现异常,其中
为预测时间。我们使用分数
来表示在t + 1到
帧期间出现异常的预测概率。在图3中,以
为例,由于
是异常帧,所以
的真实情况标注为1,表示在
这些帧中将会出现异常情况。因此,我们期望异常分数
尽可能接近异常情况(1),这与
的情况恰好相反。由此可见,视频异常检测(VAD)和视频异常预测(VAA)的真实情况标注可能是不同的。基于
(前文提到的视频的帧级标签),预测时间为
的视频异常预测(VAA)的帧级标签可以通过以下公式计算:
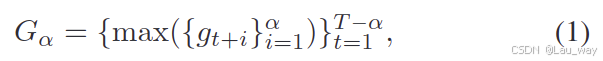
其中max()表示集合中的最大值。
由于不存在可用于监督式训练的异常数据及标签,所以动作预测模型(例如[51]、[52]、[53])不适用于半监督的视频异常预测(VAA)。因此,我们将在接下来的小节中提出一种用于半监督视频异常检测(VAD)和视频异常预测(VAA)的新方法。
B. Forward-Backward Frame Prediction Framework
我们的方法基于常用的帧预测范式[6]。然而,在视频异常预测(VAA)中,未来的真实情况帧是不可见的,因此无法计算预测误差。为解决这一问题,我们提议利用一个前向 - 后向帧预测框架来估算未来帧的预测误差。如图4所示,该框架包含一个用于视频异常检测(VAD)的前向帧预测网络以及一个额外的用于视频异常预测(VAA)的后向帧预测网络。前向网络依据先前的帧来预测当前帧,而后向网络则基于前向网络生成的未来帧以及一部分已观测到的帧来反向预测一个已观测帧。前向和后向网络共享相同的基于分数的场景依赖自动编码器(SSAE)模型架构(如图2所示),这是一个基于扩散的模型,它针对视频异常检测(VAD)和视频异常预测(VAA)学习带有场景条件的正常视频序列的分布。后续内容中将提供更多细节。
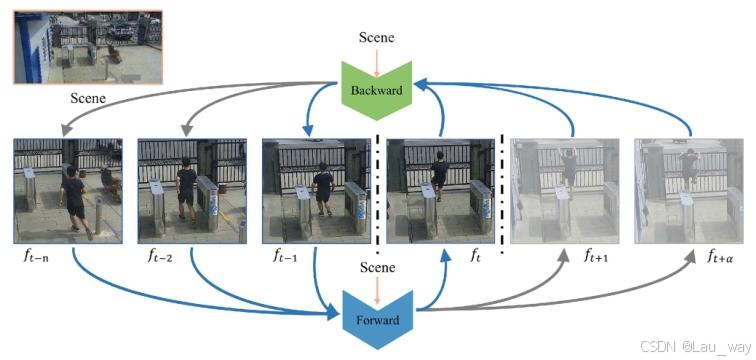
图4. 前向 - 后向帧预测框架的流程。它由一个前向帧预测网络和一个后向帧预测网络组成。前向网络依据先前的帧来预测当前帧,而后向网络则基于前向网络生成的未来帧以及一部分已观测到的帧来反向预测已观测帧。
我们首先介绍基于分数的场景依赖自动编码器(SSAE)的流程。如图2所示,在当前时间步t,令为包含n帧的输入序列,
为要预测的目标帧,
为预测出的目标帧。前向网络将
作为输入。我们的分层变分自动编码器(HVAE)编码器
首先将输入
编码为高质量的通用场景特征z,并且我们的场景调节编码器
提取场景信息
,其中z遵循近似后验分布
。然后,在潜在空间中实施一个扩散过程
来扰动z的初始分布(即
)。接下来,将场景信息和扩散时间步s合并为条件c,该条件被嵌入到去噪器
中,以便从受扰动的分布
中有条件地采样依赖场景的特征
。最后,生成的特征通过我们的分层变分自动编码器(HVAE)解码器
解码为预测的目标帧
。换句话说,我们的基于分数的场景依赖自动编码器(SSAE)利用分层变分自动编码器(HVAE)基于基于分数的扩散模型(SDM)先验来生成样本。可以通过计算预测帧
和真实帧
之间的差异来计算异常分数
,以此检测当前是否正在发生异常事件。
在针对视频异常检测(VAD)训练完基于已观测帧来预测目标帧的前向网络之后,我们开始训练后向网络。如图4所示,在训练阶段,我们将前向视频序列反转,并将输入到后向网络中,以预测
。后向网络的流程与前向网络的流程是一致的。我们针对视频异常预测(VAA)设置后向网络的动机在于,如果在前向预测中未来帧是异常的,那么预测出的图像将会不准确。当我们把这个不准确的图像作为后向帧预测模型输入的一部分时,与已观测到的真实帧相比,输出帧也将会有较大的误差(因为真实帧是已被观测到的,所以可以获取)。因此,在测试阶段,我们可以基于预测出的
帧来预测第i(
,
为预测时间)个未来帧的异常分数S(t + i)。
是由后向网络通过前向网络生成的未来帧
以及一部分已观测帧
来进行预测的。对于不同的时间步长i,后向网络共享相同的权重。
C. Scene-Generic Hierarchical VAE
对于视频异常检测(VAD)和视频异常预测(VAA),我们需要将对象的通用场景时空特性封装到我们的模型中,以确保模型具备处理视频中复杂关联关系的能力。在这种情况下,像我们之前的初步版本[8]那样,仅训练一个带有各向同性高斯分布假设[54]的简单变分自动编码器(VAE),其表现力并不足以学习视频序列中复杂的正常行为。因此,我们提出了一种分层变分自动编码器(HVAE)来增强近似后验和先验的表现力[55, 56]。 分层变分自动编码器(HVAE)由一个似然函数、一个先验
以及一个近似后验
组成。我们分别将
和
定义为编码器和解码器。z是潜在空间中的特征。我们所设计的分层变分自动编码器(HVAE)的架构如图5所示。它将帧编码为通用场景特征,然后再将这些特征解码为预测帧。 具体来说,我们的分层变分自动编码器(HVAE)按组发射潜在变量
,其中N是组数,同时也是层级数量(在图5中N = 3)。潜在变量以不同分辨率的特征图形式呈现。在这里,
表示网络顶部一组分辨率最低的变量。相反,
表示网络底部的一组潜在变量,对应着最高分辨率。 先验和近似后验可以表示为:
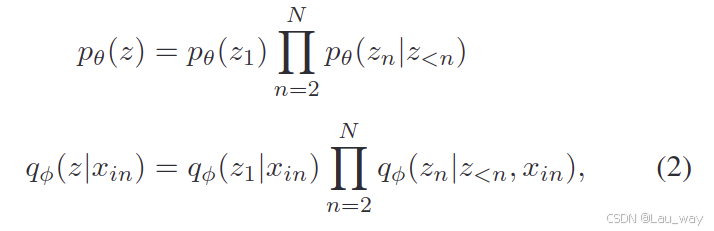
其中,先验和近似后验
中的每个变量都由乘积正态分布表示。
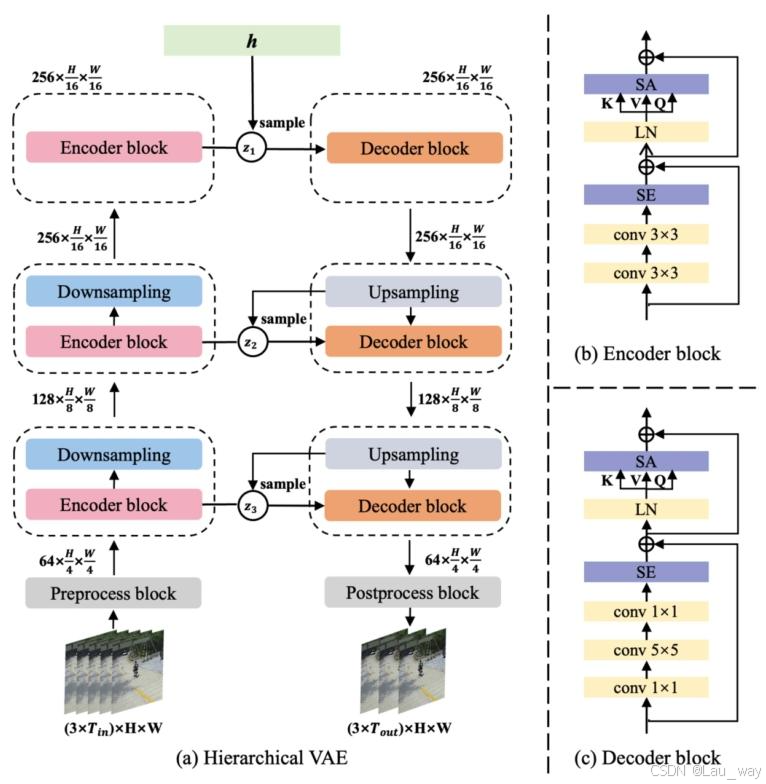
图5. 我们的通用场景分层变分自动编码器(HVAE)架构示意图。实现编码器模块和解码器模块的神经网络分别如(b)和(c)所示。SA表示自注意力模块,SE表示挤压与激励层。LN表示层归一化,h是一个可训练参数。下采样和上采样模块均由二维卷积层构成。预处理模块和后处理模块是由二维卷积层组成的残差块。
和
分别是输入帧数量和输出帧数量。
我们首先从编码环节开始进行详细介绍。如图5所示,我们的分层变分自动编码器(HVAE)编码器首先接收一个视频序列\(x_{in}\)作为输入。然后,将输入的视频序列送入一个预处理模块进行预处理。预处理模块是一个由两个3×3卷积层构成的残差块。我们使用Swish函数[57]对每个卷积层进行激活。 编码过程通过一系列编码器单元来执行,每个编码器单元包含一系列残差编码器块和下采样层。在每个编码器块中,输入\(x_{in}\)首先被送入若干个3×3卷积层,同样使用Swish函数对每个卷积层进行激活。接着,我们运用挤压与激励(SE)层[58],通过自适应地调整特征通道的重要性来增强网络对重要特征的关注度,并抑制不重要的特征。挤压与激励(SE)层已被证明有助于训练变分自动编码器(VAE)[59]。 接下来,我们将多头自注意力(SA)模块[60]应用于这些经过处理的特征上,这有着显著的益处,尤其对于需要理解复杂时空关联性的视频异常检测(VAD)任务领域而言。同时,我们使用均由二维卷积层构成的下采样层,在最后一个编码器块之前对编码后的特征进行压缩。最终,我们得到遵循近似后验分布的高质量通用场景特征。 在编码过程之后,我们的分层变分自动编码器(HVAE)解码器对潜在变量\(z_{1}, \ldots, z_{N}\)进行解码。解码过程与编码过程大致相同,不过解码器块相较于编码器块拥有更多不同尺度的卷积层。我们使用同样由二维卷积层构成的上采样层,在第一个解码器块之后对解码后的特征进行解压缩。最后,我们使用一个后处理模块对解码过程的输出进行后处理。后处理模块是一个由两个5×5和一个1×1且通过Swish函数激活的卷积层构成的残差块。通过逐层级自回归解码,我们最终能够生成预测的目标帧
。
神经编码器\(\phi\)和解码器\(\theta\)可以进行端到端的训练,其损失可以写成如下形式:
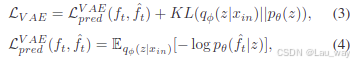
其中,KL是库尔贝克 - 莱布勒(Kullback - Leibler,简称KL)散度,它用于衡量先验分布和近似后验分布
之间的差异。我们使用负对数似然
来估计预测损失
,其目的是保持目标帧和预测帧之间的一致性。 分层变分自动编码器(HVAE)的KL散度项可以进一步写成:
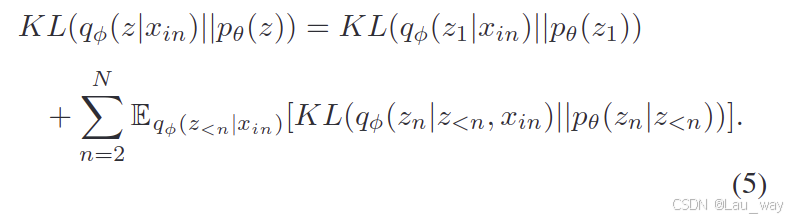
最后,我们的分层变分自动编码器(HVAE)被构建为组间的自回归高斯模型。我们能够通过分层采样,从小的潜在变量到大的潜在变量
来预测高质量的帧。因此,我们的分层变分自动编码器(HVAE)中较高层级能够捕捉整体的空间关联性,而较低层级则可以检测局部的细粒度特征。
D. Score-Based Diffusion in Latent Space
从根本上来说,异常情况存在于低概率密度区域[1] [15]。因此,我们提出了一种基于分数的扩散模型(SDM),通过分数匹配来对正常事件的通用场景特征进行优化,并使其集中于高概率密度区域。由于我们预先使用正态先验对分层变分自动编码器(HVAE)进行了训练,所以我们能够有效地引导所提取特征的分布朝着这个正态先验的方向发展。重要的是,这个正态先验同时还充当基于分数的扩散模型(SDM)的基础分布,从而极大地简化了训练过程。 此外,以N组的形式生成潜在变量使得我们能够仅针对分辨率最小的组实施扩散过程,并假定其余组都服从标准正态分布。基于分数的扩散模型(SDM)只需对剩余的不匹配情况进行建模即可,这样就形成了一个复杂度更低的模型,在该模型中我们能够从
进行自回归采样。
遵循基于连续时间分数的生成模型[35, 36],扩散过程由连续时间变量
来索引,其中z(0)是起始变量,z(s)是扩散时间为s时的扰动。这个扩散过程可以被建模为伊藤(Kiyosi Ito)随机微分方程(SDE)的解:
![]()
其中,是一个向量值函数,被称作z(s)的漂移系数,而
是一个标量函数,被称为z(s)的扩散系数。
是标准维纳过程(也称作布朗运动),它代表一个时间连续的随机过程。可以对f(z, s)和g(s)进行设计,使得
,即在扩散过程结束时服从正态分布。

式(6)中的随机微分方程(SDE)可以转换为一个生成模型,方法是先从服从正态分布
的z(1)中进行采样,然后通过逆时随机微分方程来逆转该过程:
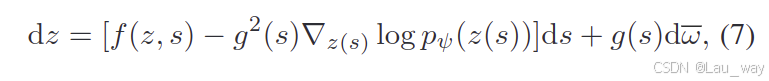
其中,是一个逆时标准维纳过程,ds是一个无穷小的负时间步长。
是在正向扩散的时间s下边际分布的得分函数。
这个生成模型能够按照相应的概率机制和动态变化规则来生成我们所需要的数据或者特征等内容,在整个基于分数的扩散模型等相关理论体系中起着承上启下的关键作用。
如图2所示,我们的基于分数的扩散模型(SDM)的主要工作是将变分自动编码器(VAE)的先验分布细化为基于分数的扩散模型(SDM)的先验分布
。在对分层变分自动编码器(HVAE)的编码器
和解码器
进行预训练之后,我们可以利用逆随机微分方程(SDE)从带有与时间相关的得分函数
的
中进行采样。之后,分层变分自动编码器(HVAE)的解码器
会将合成的特征
映射到视频数据空间。形式上,生成过程可以描述为:
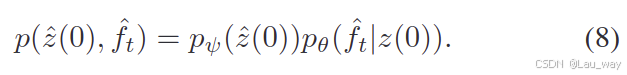
基于分数的扩散模型(SDM)是通过噪声条件得分网络(NCSN)[35]来实现的。我们基于扩散时间步长s对网络进行训练,以此来控制噪声水平(通过一个多层感知机进行嵌入)。生成过程可以等效地看作是分层变分自动编码器(HVAE)使用基于分数的扩散模型(SDM)的先验进行采样。因此,我们通过最小化负对数似然的变分上界来联合训练分层变分自动编码器(HVAE)和基于分数的扩散模型(SDM)(即分层变分自动编码器(HVAE)的编码器
、解码器
以及学习得分函数
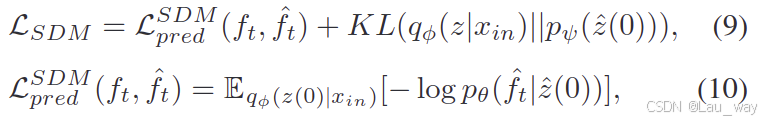
其中,是预测损失。我们可以通过将基于分数的扩散模型(SDM)的KL散度项分解为其熵项和交叉熵项[61]来对其进行优化,其中,在扩散时间步长s时得分网络
对数据得分的预测误差包含在交叉熵项中。分解公式可以写成:
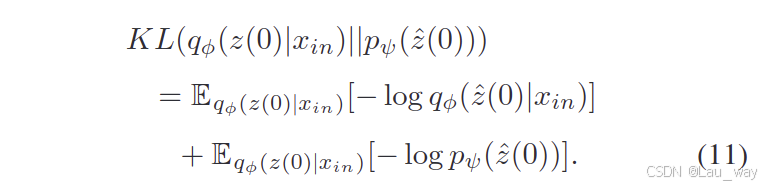
逆过程的连续监督能够有效保证潜在空间中特征的高质量,同时这些特征仍然是通用场景的。在下一小节中,我们将创建一个潜在条件部分,以使这些通用场景的潜在特征变为依赖场景的特征。
E. Scene-Conditional Latent Diffusion Model
我们的场景调节模块旨在将条件因子嵌入到去噪器中,以实现从操作 到
的转变,其中c是扩散时间步长s与由一个可训练的场景信息提取器所提取的场景条件的组合。我们设计了一个场景信息提取器
,以便将条件传递到去噪器
的所有隐藏层。我们的场景信息提取器的目标是将输入视频序列
映射为包含明显场景信息的特征,从而促使去噪器
依靠
来进行依赖于场景的生成操作。
理想的场景特征应当在不同场景之间保持显著差异,同时在同一场景内的各个对象之间保持良好的一致性。然而,仅对输入视频序列应用编码器往往会以牺牲背景信息为代价,侧重于前景对象的区分。因此,我们引入了一个解码器 ,它负责场景信息的重建,即
,其中
是输入
所属的场景图像。通过重建场景信息,我们能够迫使提取器
整合背景信息,进而提高场景特征的一致性。 我们为提取器使用了三个带有LeakyReLU激活函数[62]的卷积层,为解码器使用了五个带有相同激活函数的卷积层。我们通过重建损失对这个小型的自动编码器进行预训练,该重建损失可写为:
![]()
其中,是
所属的场景图像。
此外,我们采用无分类器扩散引导[39]策略来训练我们的去噪器,这是一种在条件扩散模型中平衡样本质量和多样性的方法。该方法涉及从有条件分布和无条件分布中进行学习,并按如下方式实现线性组合:
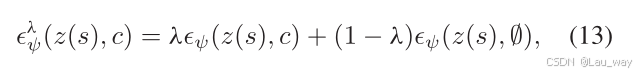
其中,是引导尺度,它能够增强引导效果。c是扩散时间步长s与所提取的场景信息
的组合。在经过条件去噪的交互逆向过程之后,我们的模型能够从去噪后的
高效地预测目标帧
。
F. Temporal Loss Function for Training
我们提出了一个额外的时间连贯性项,以确保预测帧与真实视频序列保持时间上的一致性。我们注意到,一些视频异常检测(VAD)方面的工作会计算相邻帧的差异[63, 64, 65]来提升运动的一致性。这种相邻帧损失通过约束相邻帧像素之间的差异来促进运动一致性。与复杂的光流方法[9, 14]相比,计算帧间损失能以更少的计算资源产生类似的效果。
受关键帧理论[63, 66, 67]的启发,我们提议对目标帧与关键帧(即视频序列的首帧和尾帧)之间的差异进行优化,这能够进一步降低计算成本。我们的时间连贯性项的目的在于,如果预测的目标帧与已观测的输入序列保持较强的一致性,那么目标帧与后续序列之间的一致性应该大致相同。 具体而言,在训练阶段,令为一个视频片段,其中
是输入视频序列,
是要预测的目标帧。为了计算关键帧之间的损失,我们将后续的
帧纳入考量范围。我们可以选取
,
作为
中的关键帧,并选取
、
作为
中的关键帧。 除了使用L1或L2损失来获取RGB差异之外,我们注意到,将特征解码为关键帧并基于特征层面的负对数似然来计算它们的分布差异能够产生更多样性。基于关键帧差异的时间损失可以写成如下形式:
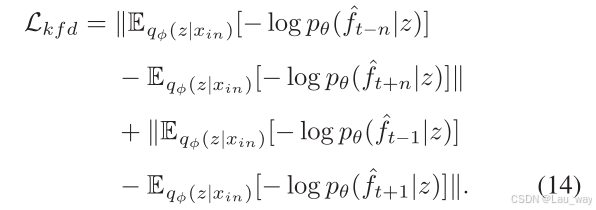
最后,考虑到我们的基于分数的场景依赖自动编码器(SSAE)涵盖了不同的训练阶段,我们设置了一个阶段标志来代表不同的训练阶段(分别对应小型场景自动编码器、通用场景分层变分自动编码器(HVAE)以及场景条件基于分数的扩散模型(SDM)阶段)。形式上,我们可以将总体损失函数描述如下:
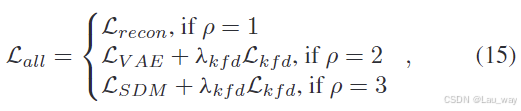
其中,是基于关键帧差异的时间损失
的权重。
我们也可以使用式(15)来训练后向网络。通过这种方式,我们的后向网络能够利用反转后的输入以及已观测到的信息来进行视频异常预测。
G. Anomaly Scoring for Inference
在视频异常检测(VAD)的推理阶段,我们将视频划分为具有T帧的个视频片段。我们注意到,预测帧与真实帧之间的误差非常小,这就导致了正常事件和异常事件之间区分度低的严重问题。因此,在视频中每个包含T帧的视频片段里,我们将具有最小峰值信噪比(PSNR)值的那一帧的分值作为该视频片段的分值,而非采用各预测帧
(
)的误差。为了量化异常发生的概率[8, 63, 68],我们对每个峰值信噪比(PSNR)值的分值score(t)进行归一化处理,以得到取值范围在[0, 1]内的异常分值S(t),其表达式如下:
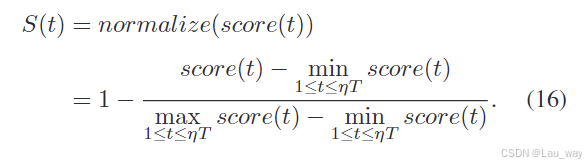
对于视频异常预测(VAA),后向网络将预测的前向未来帧以及已观测到的帧
作为输入,来预测一个已观测帧
。 我们首先使用预测帧
与观测到的真实帧
之间的峰值信噪比(PSNR)值作为第i个(
,
为预测时间)未来帧的异常分值。然后,我们选取这
个峰值信噪比(PSNR)值中的最小值作为预测值分值
。最后,我们对每个预测值进行归一化处理,以得到取值范围在[0, 1]内的异常分值
。整个流程在算法1中有所概述。

IV. PROPOSED DATASET
V. EXPERIMENTS
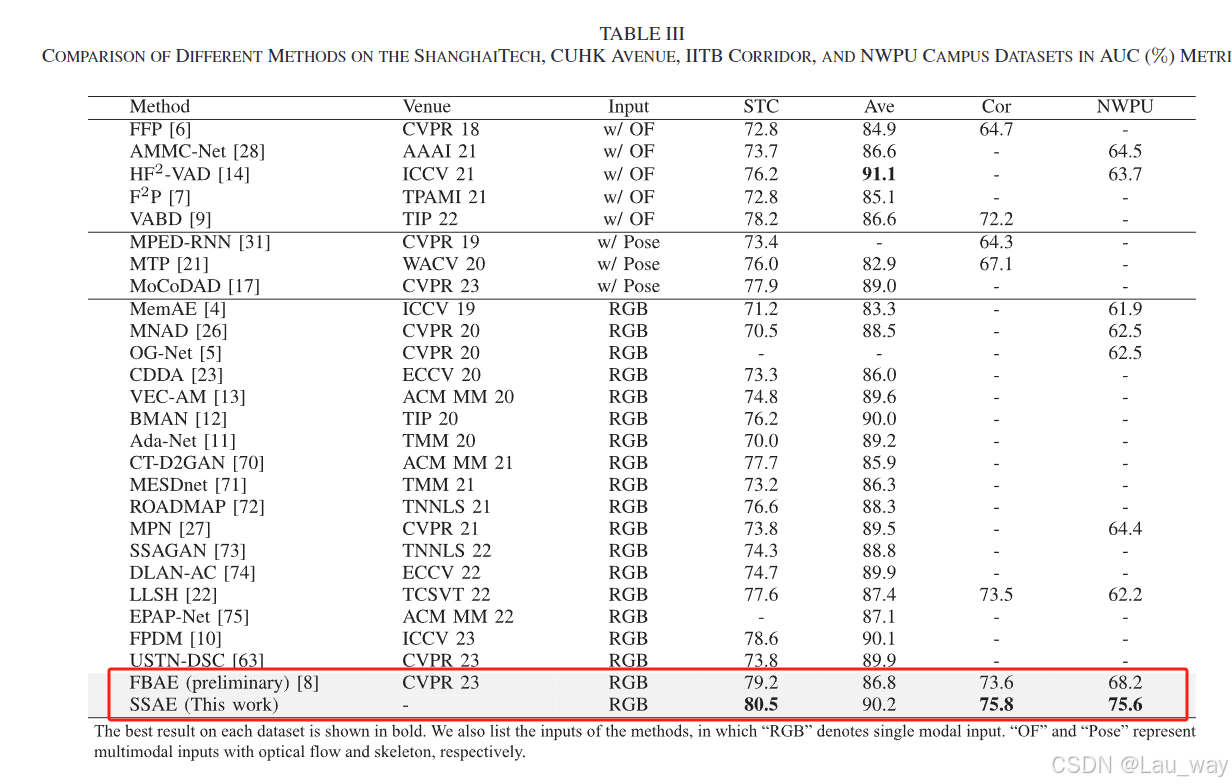
C. Video Anomaly Anticipation
我们针对不同预测时间,在西北工业大学校园数据集上开展了视频异常预测(VAA)实验,相关情况如表四所示。我们给出了随机预测(“随机情况”)以及人类(“人类”)的相应结果。四位未参与该数据集构建的志愿者参与了异常预测的评估工作。由于人类无法精确感知时间,所以志愿者们仅预测在3秒内是否会发生异常事件。“人类”的结果是所有志愿者的平均表现情况。 我们的前向 - 后向框架按照第三节G部分所述来计算异常分值。与我们之前的研究[8]相比,我们的方法能够做出更准确的预测,平均性能提升了3.5%,这表明这个改进版本能够更好地对视频的时空相关性进行建模。不过,仍然存在很大的改进空间,这意味着所提出的数据集以及视频异常预测任务对于各类算法来说是极具挑战性的。
与我们所设定的预测在某一时间段内是否会发生异常情况(在第三节A部分有所提及)不同,另一项同期的研究[75]将一个类似的任务定义为预测未来帧中潜在的异常情况,并针对香港中文大学“大道”数据集上的这一任务使用了语义池。与我们的设定相比,这种多帧设定侧重于帧与帧之间更短期的、无时间间隔的异常预测。 我们遵循这种多帧设定[75]来进行直接对比,并取得了好得多的性能表现。如表五所示,随着时间间隔的增加,我们方法的性能几乎没有下降。我们发现,在香港中文大学“大道”数据集里,短期连续帧之间的差异非常微弱且模糊,因此我们的前向 - 后向框架凭借更强大的机制,显著优于与之竞争的方法[75]。我们建议将异常预测任务按照我们对视频异常预测(VAA)的定义那样设置为秒级别的,这样更具意义。
E. Ablation Study and Analysis
1) 所提组件的有效性: 在表七中,我们展示了我们的模型变体在上海科技大学和西北工业大学校园这两个多场景数据集上的性能表现。我们依次向原始的变分自动编码器(VAE)添加了层级结构、挤压与激励(SE)模块以及自注意力(SA)层,并且在潜在空间中实现了基于无条件和有条件分数的扩散。 如表七所示,多尺度层级架构对变分自动编码器(VAE)有益,因为在这两个数据集上平均提升了3.6%。这两个挤压与激励(SE)和自注意力(SA)注意力模块有效地协助处理视频中的时空相关性。其中,挤压与激励(SE)层还有助于稳定分层变分自动编码器(HVAE)[59]的训练,使得在这两个数据集上取得了超过3.1%的更显著提升。 尽管我们的分层变分自动编码器(HVAE)基线(即表七中的第五行)取得了有竞争力的结果,但通过基于分数的扩散模型(SDM)在潜在空间中对我们的分层变分自动编码器(HVAE)所提取的特征进行细化,能够进一步在这两个数据集上实现平均性能1.2%的提升,这证明了扩散模型强大的生成和表征能力。 最后但同样重要的是,在这两个数据集上平均1.3%的提升表明将场景条件融入扩散模型是有效的。这归因于考虑场景条件能使我们的模型更好地适应视频的复杂背景这一事实。

2) 损失函数: 表八展示了在香港中文大学“大道”数据集、上海科技大学数据集以及西北工业大学校园数据集上,使用和不使用基于关键帧差异(KFD)损失时的性能差异。可以看出,关键帧差异损失在这三个数据集上都能持续提升性能,尤其对于西北工业大学校园数据集而言,它使曲线下面积(AUC)提升了2.4%。这是因为西北工业大学校园数据集涉及多种场景,其前景物体有着复杂的运动模式,对运动动态的依赖性更高。这证明了我们所提出的关键帧差异损失在运动约束方面的有效性。 我们在RGB域和潜在空间中都计算了关键帧差异损失(分别对应表八中的KFDL - R和KFDL - L)。由于在这两个域中计算关键帧差异损失的性能与仅在潜在空间中计算它的性能几乎相同,所以仅在潜在空间中计算关键帧差异损失的效率更高,这表明从高维特征层面能够产生更多的多样性。
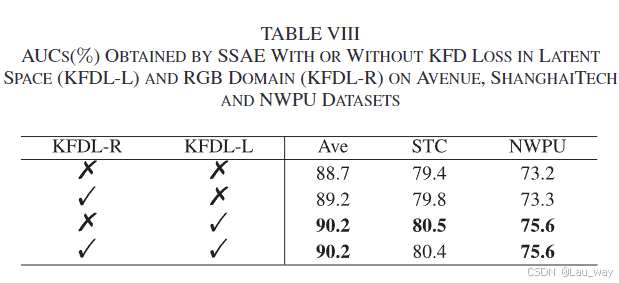
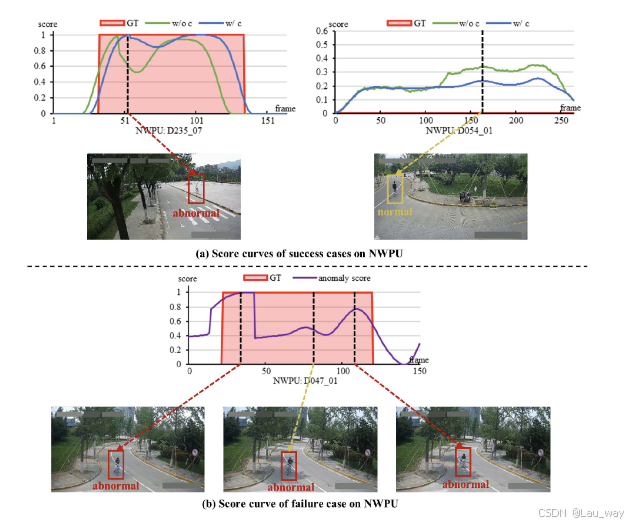
图8. 西北工业大学校园数据集可视化示意图。(a)西北工业大学校园数据集上成功案例的分值曲线。“含条件(w/ c)”和“不含条件(w/o c)”表示我们的模型是否使用了场景条件。“GT”代表真实情况(真值)。分值越高,表示出现异常的概率越大。(b)西北工业大学校园数据集上失败案例的分值曲线。中间的帧展示了我们方法的失败案例情况。
VI. CONCLUSION
在本文中,我们提出了一种新颖的用于视频异常检测(VAD)和视频异常预测(VAA)的前向 - 后向帧预测框架。基于该框架,我们设计了一种新型的基于分数的依赖场景的自动编码器(SSAE),它是一种基于扩散的模型,用于检测和预测依赖场景的异常事件。 在这个模型中,我们引入了一种更强大的分层变分自动编码器来提取通用场景特征,并在潜在空间中运用基于分数的扩散模型对这些特征进行细化,进而生成依赖场景的特征。我们将一种有效的调节策略应用于扩散模型,以引导合成朝着依赖场景的样本方向进行。 此外,我们提出了一种时间损失来约束视频序列中对象的运动一致性。最后,我们提出了一个新的综合性数据集——西北工业大学校园数据集,它是半监督视频异常检测领域规模最大的数据集,是唯一一个考虑依赖场景异常情况的数据集,也是首个针对视频异常预测(VAA)提出的数据集。在四个数据集上进行的大量实验表明,我们的方法能够很好地应对依赖场景的异常检测和异常预测任务。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)