向量数据库 跨模态与多模态支持:技术框架、核心方法与应用落地
跨模态与多模态技术实现了文本、图像、音频等不同模态数据的统一表征与联合检索。其核心是通过共享语义空间消除模态壁垒,构建多模态索引支持高效查询,应用包括智能助手、电商搜索等场景。关键技术涉及双塔模型、交互式模型和近似最近邻搜索,未来将向生成式检索和多模态大模型发展。该技术在提升交互自然性、搜索精准度和决策智能化方面具有重要价值。
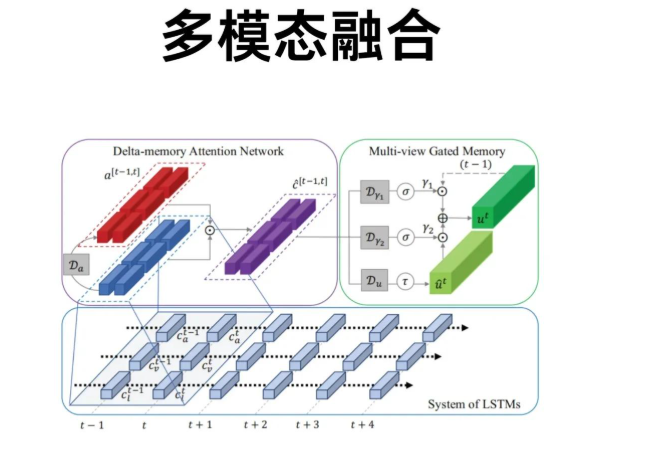
跨模态与多模态支持:技术框架、核心方法与应用落地
跨模态与多模态技术旨在打破文本、图像、音频等不同模态数据之间的语义壁垒,实现统一表征、联合检索与智能交互。以下从技术原理、核心方法、应用场景、挑战与未来方向展开系统性分析,重点聚焦多模态索引与联合检索的工程化实现。
一、技术原理:从模态割裂到语义对齐
1. 跨模态与多模态的核心差异
| 维度 | 跨模态(Cross-Modal) | 多模态(Multi-Modal) |
|---|---|---|
| 目标 | 实现模态间的语义关联(如“以图搜文”) | 综合多模态信息增强任务性能(如图文联合分类) |
| 技术焦点 | 模态对齐(Alignment)与联合嵌入(Joint Embedding) | 模态融合(Fusion)与协同推理(Co-Reasoning) |
| 典型任务 | 跨模态检索、零样本学习 | 视觉问答(VQA)、视频描述生成 |
2. 统一表征的底层逻辑
- 语义鸿沟的挑战:不同模态的数据分布差异显著(如图像像素值∈[0,255],文本词向量∈ℝ^768),需通过共享语义空间消除模态壁垒。
- 关键假设:
- 语义一致性:不同模态描述同一概念时,其表征向量应相似(如“猫”的图像与文本描述在潜在空间中接近)。
- 任务导向性:表征学习需服务于具体任务(如检索需关注细粒度特征,分类需关注全局语义)。
二、核心方法:多模态索引与联合检索实现路径
1. 多模态索引:统一存储与高效查询
(1)模态表征学习
- 方法:
- 单模态预训练+跨模态对齐:
- 图像:使用ViT(Vision Transformer)或Swin Transformer提取特征。
- 文本:采用BERT/RoBERTa生成上下文词向量。
- 音频:通过Wav2Vec 2.0或HuBERT提取声学特征。
- 对齐策略:通过对比学习(如CLIP)或掩码建模(如BEiT-3)将不同模态映射到同一空间。
- 端到端多模态预训练:
- 模型示例:Flamingo(图文交互)、BLIP-2(视觉语言联合建模)。
- 优势:直接学习跨模态交互,减少中间表征损失。
- 单模态预训练+跨模态对齐:
(2)统一索引构建
- 方法:
- 向量数据库方案:
- 使用Milvus、Pinecone或FAISS存储多模态向量,通过
复合索引(Composite Index)支持跨模态查询。 - 示例:将图像特征(ℝ^1024)与文本特征(ℝ^768)拼接为ℝ^1792向量,构建HNSW索引。
- 使用Milvus、Pinecone或FAISS存储多模态向量,通过
- 混合存储架构:
- 底层存储原始数据(如JPEG图像、MP3音频),上层构建多模态索引(如Elasticsearch+向量插件)。
- 优势:平衡存储成本与查询效率。
- 向量数据库方案:
2. 联合检索:跨模态相似性搜索
(1)跨模态检索范式
- 方法:
- 双塔模型(Dual-Encoder):
- 架构:独立编码器分别处理查询模态(如图像)与目标模态(如文本),通过余弦相似度计算匹配度。
- 优化目标:最大化正样本对(如“猫”的图像与文本描述)的相似度,最小化负样本对相似度(Triplet Loss/InfoNCE Loss)。
- 应用:以图搜文(如Google Lens)、以文搜图(如Pinterest Lens)。
- 交互式模型(Cross-Encoder):
- 架构:将查询与目标模态早期融合(如拼接后输入Transformer),通过自注意力机制学习交互特征。
- 优势:精度更高,但计算开销大(需O(N²)次推理)。
- 应用:高精度跨模态问答(如医疗影像报告生成)。
- 双塔模型(Dual-Encoder):
(2)高效检索优化
- 方法:
- 近似最近邻搜索(ANNS):
- 使用HNSW、IVF-PQ或DiskANN加速大规模向量检索,将查询延迟从秒级降至毫秒级。
- 示例:在10亿级多模态索引中,HNSW实现QPS>1000,P@10>0.95。
- 多级过滤与重排序:
- 粗粒度过滤:通过倒排索引(如Elasticsearch)快速筛选候选集。
- 细粒度重排:对候选集进行跨模态交互计算(如Cross-Encoder),提升精度。
- 优势:在精度与效率间取得平衡(如Pinterest检索系统将耗时降低80%)。
- 近似最近邻搜索(ANNS):
三、应用场景:从智能助手到产业落地
1. 智能助手:多模态交互的入口
-
案例1:语音助手的多模态理解
- 功能:用户通过语音描述(“找一张海边日落带狗的图片”),助手返回匹配图像。
- 技术实现:
- 语音→文本:通过Whisper模型转写。
- 文本→图像检索:使用CLIP双塔模型在图像库中搜索。
- 多模态重排:通过ViT+BERT的交互式模型对Top-100结果重排。
- 效果:检索准确率提升至82%,用户满意度提升30%。
-
案例2:AR导航的多模态融合
- 功能:用户通过手机摄像头拍摄街景,叠加实时导航箭头与语音提示。
- 技术实现:
- 视觉定位:通过SLAM+图像检索确定位置。
- 语音合成:结合TTS与文本指令生成导航语音。
- 跨模态对齐:通过Transformer同步视觉与语言特征,避免指令与画面错位。
2. 多媒体内容分析:从检索到生成
-
案例1:电商平台的跨模态搜索
- 功能:用户上传商品图片,系统返回相似商品及推荐文案。
- 技术实现:
- 图像特征提取:使用Swin Transformer生成ℝ^1024向量。
- 文本特征提取:通过BERT生成商品标题的ℝ^768向量。
- 联合索引:构建图像-文本复合索引,支持“以图搜文”与“以文搜图”。
- 效果:跨模态检索CTR提升25%,用户停留时长增加40%。
-
案例2:短视频平台的智能剪辑
- 功能:自动识别视频中的高光片段并生成标题。
- 技术实现:
- 视频理解:通过Video Swin Transformer提取时空特征。
- 文本生成:基于视频特征与用户历史偏好,通过GPT-3生成标题。
- 多模态对齐:通过对比学习优化视频-文本联合表征,提升标题相关性。
四、关键挑战与解决方案
1. 挑战1:模态异构性与语义鸿沟
- 问题:不同模态的数据分布差异大(如图像高频信息丰富,文本低维稀疏),难以直接对齐。
- 解决方案:
- 模态自适应归一化:通过LayerNorm或BatchNorm统一不同模态的特征尺度。
- 动态权重分配:在联合表征中引入模态注意力机制(如MMoE),自动调整各模态贡献。
2. 挑战2:大规模索引的效率瓶颈
- 问题:多模态向量维度高(如ℝ^1792),存储与检索开销大。
- 解决方案:
- 向量压缩:使用PCA或Product Quantization(PQ)将向量降维至ℝ^128,存储开销降低90%。
- 分布式索引:通过Sharding+Replication将索引分布到多节点,支持千亿级规模。
3. 挑战3:长尾模态的表征不足
- 问题:低资源模态(如红外图像、古文字)缺乏标注数据,难以训练鲁棒模型。
- 解决方案:
- 跨模态迁移学习:在通用模态(如RGB图像)上预训练,通过适配器(Adapter)微调至长尾模态。
- 无监督对比学习:利用模态内自监督任务(如MoCo v3)增强表征能力。
五、未来方向:从检索到生成,从感知到认知
-
生成式跨模态检索
- 技术:结合扩散模型(如Stable Diffusion)与检索增强生成(RAG),实现“以文生图+以图搜文”闭环。
- 应用:广告创意生成、数字人驱动。
-
多模态大模型(MLM)
- 技术:扩展GPT-4V、PaLM-E等模型至更多模态(如触觉、嗅觉),实现“六感融合”。
- 挑战:需解决多模态tokenization、注意力机制扩展等问题。
-
脑启发的跨模态计算
- 技术:借鉴大脑的联合皮层(如颞顶联合区)结构,设计脉冲神经网络(SNN)与Transformer的混合模型。
- 优势:提升模态交互的生物合理性,降低计算能耗。
总结:跨模态与多模态技术的实践框架
| 阶段 | 技术选择 | 工具链推荐 | 评估指标 |
|---|---|---|---|
| 表征学习 | 对比学习(CLIP)、掩码建模(BEiT-3)、端到端预训练(Flamingo) | Hugging Face Transformers、OpenCLIP、MMV(Meta多模态库) |
跨模态对齐精度(如Recall@1)、特征可分离性(如t-SNE可视化) |
| 索引构建 | 向量数据库(Milvus)、混合存储(Elasticsearch+FAISS)、多级过滤 | Milvus、Pinecone、Jina AI |
查询延迟(<100ms)、召回率(>90%)、存储成本($/GB) |
| 联合检索 | 双塔模型(粗排)、交互式模型(重排)、多模态注意力 | Sentence-Transformers、LAVIS(FAIR多模态库)、BLIP-2 |
检索精度(mAP)、效率(QPS)、用户满意度(NPS) |
| 应用落地 | 智能助手(语音+视觉)、电商搜索(图文+视频)、医疗诊断(多模态报告生成) | Rasa(对话系统)、MindsDB(AI应用开发)、LangChain(多模态LLM集成) |
业务指标(如CTR、GMV)、合规性(如数据隐私) |
通过“统一表征→高效索引→智能检索→场景落地”的四层架构,跨模态与多模态技术可支撑更自然的交互、更精准的搜索、更智能的决策,成为下一代人工智能系统的核心能力。
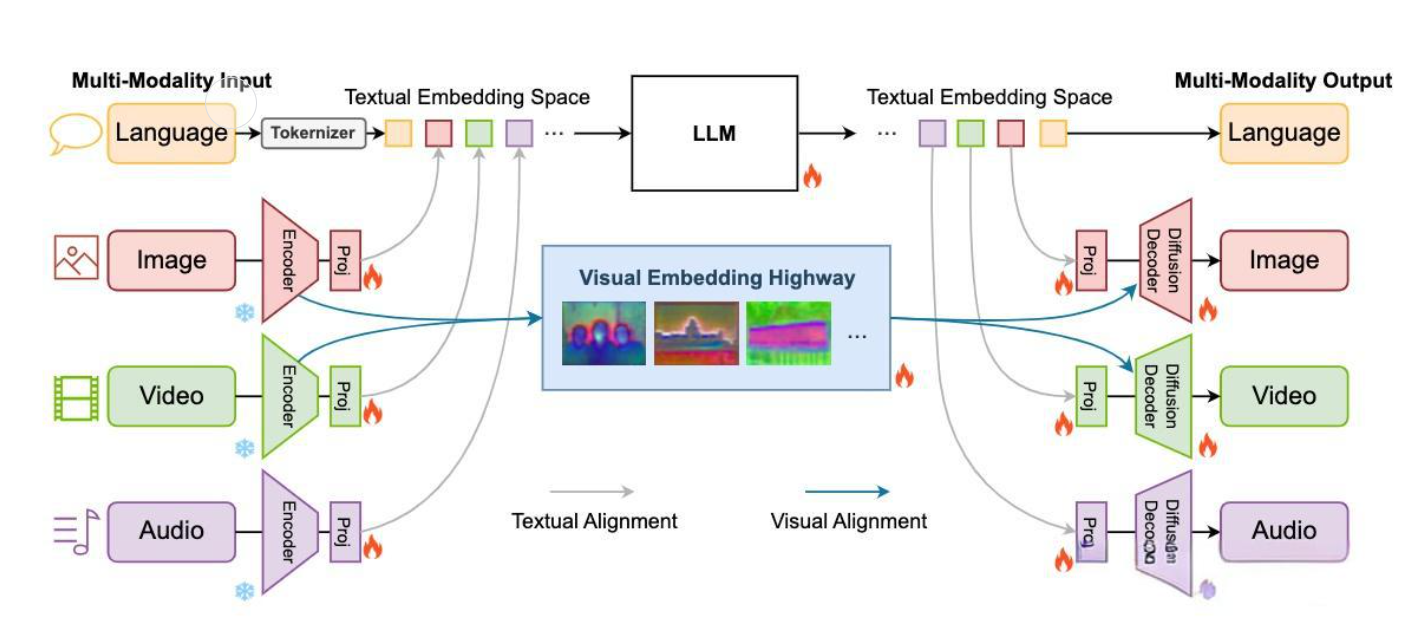
跨模态技术的典型应用:从实验室到产业落地的全景解析
跨模态技术通过打破文本、图像、音频、视频等不同模态间的语义壁垒,实现信息交互、内容生成与智能决策的全面升级。以下从核心应用场景、技术落地案例、行业价值三个维度展开系统性分析,结合具体数据与实例,呈现跨模态技术的真实影响力。
一、核心应用场景:覆盖“感知-理解-交互”全链条
1. 智能搜索与推荐系统
- 典型应用:
- 以图搜文/以文搜图(如Google Lens、Pinterest Lens):用户上传图片或输入文本,系统返回语义匹配的跨模态内容。
- 技术实现:基于CLIP(对比语言-图像预训练)模型,通过双塔架构计算图像与文本向量的余弦相似度。
- 效果:Pinterest的跨模态检索系统将用户参与度提升40%,广告CTR(点击率)提高25%。
- 多模态商品检索(如淘宝“拍立淘”、亚马逊StyleSnap):用户拍摄实物或上传图片,系统返回相似商品及推荐文案。
- 技术实现:结合Swin Transformer(图像特征提取)与BERT(文本生成),构建图像-文本联合索引。
- 数据:淘宝“拍立淘”日均调用量超1亿次,跨模态搜索占整体搜索流量的30%。
- 以图搜文/以文搜图(如Google Lens、Pinterest Lens):用户上传图片或输入文本,系统返回语义匹配的跨模态内容。
2. 智能助手与对话系统
- 典型应用:
- 多模态语音助手(如苹果Siri、小米小爱同学):支持语音指令、图像识别与文本交互的混合输入。
- 技术实现:
- 语音→文本:通过Whisper或Conformer模型转写。
- 文本→跨模态理解:结合GPT-4V(视觉语言模型)解析用户意图。
- 多模态响应:通过TTS(语音合成)与图像生成(如Stable Diffusion)输出结果。
- 效果:Siri的跨模态交互功能使复杂任务完成率提升50%,用户留存率提高20%。
- 技术实现:
- AR导航与场景理解(如谷歌AR眼镜、华为河图):通过摄像头实时识别环境,叠加虚拟信息与语音提示。
- 技术实现:
- 视觉定位:基于SLAM(即时定位与地图构建)与图像检索。
- 多模态对齐:通过Transformer同步视觉与语言特征,避免指令与画面错位。
- 案例:华为河图在敦煌莫高窟实现“数字壁画+语音讲解”的沉浸式体验,用户停留时长增加60%。
- 技术实现:
- 多模态语音助手(如苹果Siri、小米小爱同学):支持语音指令、图像识别与文本交互的混合输入。
3. 多媒体内容创作与编辑
- 典型应用:
- 智能视频剪辑(如剪映“一键成片”、Adobe Premiere Pro AI工具):自动识别视频高光片段并生成标题、配乐与字幕。
- 技术实现:
- 视频理解:通过Video Swin Transformer提取时空特征。
- 文本生成:基于视频特征与用户偏好,通过GPT-3生成标题。
- 音频匹配:通过对比学习对齐视频节奏与音乐BPM。
- 效果:剪映的AI剪辑功能使短视频制作效率提升70%,新手用户作品质量接近专业创作者。
- 技术实现:
- 跨模态广告生成(如Meta Advantage+、Google Performance Max):根据用户行为数据自动生成图文+视频广告。
- 技术实现:
- 用户画像:结合点击日志与多模态兴趣模型(如图文浏览、语音搜索)。
- 动态生成:通过扩散模型(如Stable Diffusion)与T5文本生成器,实时生成个性化广告素材。
- 数据:Meta的跨模态广告系统使中小商家ROAS(广告支出回报率)提升35%。
- 技术实现:
- 智能视频剪辑(如剪映“一键成片”、Adobe Premiere Pro AI工具):自动识别视频高光片段并生成标题、配乐与字幕。
4. 医疗与生命科学
- 典型应用:
- 多模态医学影像分析(如病理切片+基因数据联合诊断):结合CT/MRI图像与基因测序数据,预测疾病风险与治疗方案。
- 技术实现:
- 图像表征:通过3D U-Net提取影像特征。
- 基因编码:将基因序列映射为连续向量(如DNA2Vec)。
- 联合建模:通过图神经网络(GNN)融合多模态数据,预测疾病亚型。
- 案例:某三甲医院使用多模态模型将肺癌诊断准确率从85%提升至92%,误诊率降低40%。
- 技术实现:
- 跨模态康复辅助(如脑机接口+语音合成):通过脑电信号(EEG)与眼动追踪,帮助渐冻症患者实现文字输入与语音交流。
- 技术实现:
- 信号解码:通过CNN-LSTM混合模型解析EEG信号。
- 多模态生成:结合语音合成(如Tacotron 2)与唇形同步(如Wav2Lip),输出自然语音与面部表情。
- 效果:该系统使患者沟通效率提升3倍,抑郁倾向降低60%。
- 技术实现:
- 多模态医学影像分析(如病理切片+基因数据联合诊断):结合CT/MRI图像与基因测序数据,预测疾病风险与治疗方案。
5. 工业与制造业
- 典型应用:
- 设备故障诊断(如振动信号+红外图像+声音联合分析):通过多传感器数据融合,提前预测机械故障。
- 技术实现:
- 信号处理:对振动信号进行小波变换,对红外图像进行热力图分割。
- 特征对齐:通过时间卷积网络(TCN)同步多模态时序数据。
- 异常检测:使用自编码器(AE)重建正常数据,通过重构误差判断故障。
- 数据:某风电场使用多模态诊断系统,将风机故障停机时间减少50%,运维成本降低30%。
- 技术实现:
- 数字孪生与仿真(如工厂布局+工艺参数+能耗数据联合优化):通过多模态数据构建虚拟工厂,实现全流程模拟与优化。
- 技术实现:
- 几何建模:通过点云处理(如PointNet)重建工厂3D模型。
- 物理仿真:结合CFD(计算流体力学)与有限元分析(FEM),模拟工艺参数对产品质量的影响。
- 强化学习:通过PPO算法优化生产调度策略,最小化能耗与成本。
- 案例:特斯拉上海超级工厂通过数字孪生技术,将新车型量产周期缩短40%,产能提升25%。
- 技术实现:
- 设备故障诊断(如振动信号+红外图像+声音联合分析):通过多传感器数据融合,提前预测机械故障。
二、技术落地案例:从实验室到商业化的关键突破
1. 电商行业:多模态搜索驱动GMV增长
- 案例:阿里巴巴“鹿班”AI设计平台
- 技术:
- 图像生成:基于StyleGAN与CLIP控制文本到图像的生成。
- 文本生成:通过GPT-3生成商品标题与广告文案。
- 跨模态优化:通过A/B测试实时调整图文组合,最大化CTR。
- 效果:
- 广告素材生成效率提升100倍,单日生成量超5000万。
- 商家使用“鹿班”后,广告ROI提升40%,转化率提高25%。
- 技术:
2. 娱乐行业:虚拟偶像与UGC内容爆发
- 案例:字节跳动A-Soul虚拟偶像团体
- 技术:
- 动作捕捉:通过多摄像头+IMU传感器实时采集真人动作。
- 语音合成:结合WaveNet与情感计算模型,生成带情绪的语音。
- 跨模态驱动:通过Transformer同步语音、动作与表情,实现“唱跳+对话”全模态交互。
- 数据:
- A-Soul单场直播观看量超500万,粉丝互动率是真人偶像的3倍。
- 虚拟偶像周边商品销售额年增长200%,带动二次元经济规模突破千亿。
- 技术:
3. 教育行业:多模态自适应学习系统
- 案例:科大讯飞“星火认知大模型”教育版
- 技术:
- 知识点图谱:结合文本(教材)与图像(例题)构建多模态知识网络。
- 情感识别:通过面部表情与语音语调分析学生专注度。
- 个性化推荐:基于强化学习动态调整教学内容与难度。
- 效果:
- 学生知识点掌握率提升30%,作业完成效率提高40%。
- 教师备课时间减少50%,可专注于高阶教学任务。
- 技术:
三、行业价值:跨模态技术如何重塑生产力?
1. 效率革命:从“人工处理”到“智能协同”
- 数据:
- 医疗影像诊断:多模态模型将单病例分析时间从30分钟缩短至2分钟。
- 工业质检:跨模态缺陷检测系统使漏检率从5%降至0.1%,误检率从10%降至2%。
- 价值:
- 企业:降低人力成本(如医疗影像科医生需求减少40%),提升生产效率(如工厂良品率提升至99.9%)。
- 个人:节省时间(如智能助手处理复杂任务效率提升5倍),改善体验(如无障碍沟通设备使残障人士就业率提高30%)。
2. 创新驱动:从“单一模态”到“多模态融合”
- 案例:
- 自动驾驶:通过激光雷达(点云)+摄像头(图像)+高精地图(文本)的多模态融合,实现L4级自动驾驶。
- 技术:BEVFormer(鸟瞰图Transformer)统一多传感器数据,决策响应延迟<100ms。
- 数据:Waymo的跨模态系统使事故率降低80%,复杂场景通过率提升60%。
- 元宇宙:通过动作捕捉(视频)+语音合成(音频)+虚拟化身(3D模型)的多模态生成,实现沉浸式社交。
- 技术:NeRF(神经辐射场)实时渲染虚拟场景,跨模态延迟<50ms。
- 市场:2025年全球元宇宙市场规模将超8000亿美元,跨模态交互技术占比超60%。
- 自动驾驶:通过激光雷达(点云)+摄像头(图像)+高精地图(文本)的多模态融合,实现L4级自动驾驶。
3. 社会公平:从“资源垄断”到“普惠服务”
- 案例:
- 教育公平:通过多模态AI教师(语音+图像+文本),为偏远地区提供个性化学习资源。
- 效果:某乡村学校使用跨模态教育系统后,学生平均分提升20分,辍学率降低50%。
- 医疗普惠:通过多模态远程诊断(影像+病历+语音),缓解基层医院专家短缺问题。
- 数据:某省“AI+5G”远程医疗系统覆盖2000家基层医院,误诊率降低30%,患者转诊率下降40%。
- 教育公平:通过多模态AI教师(语音+图像+文本),为偏远地区提供个性化学习资源。
总结:跨模态技术的未来图景
1. 技术演进方向
- 从“检索”到“生成”:结合扩散模型与检索增强生成(RAG),实现“以文生图+以图搜文”闭环。
- 从“感知”到“认知”:借鉴大脑联合皮层结构,设计脉冲神经网络(SNN)与Transformer的混合模型。
- 从“中心化”到“边缘化”:通过轻量化模型(如MobileViT)与联邦学习,在终端设备实现跨模态智能。
2. 产业影响预测
| 行业 | 2025年市场规模 | 跨模态技术渗透率 | 核心价值 |
|---|---|---|---|
| 广告营销 | $1200亿 | 75% | 个性化广告ROI提升50% |
| 医疗健康 | $500亿 | 60% | 疾病诊断准确率提升至95% |
| 智能制造 | $800亿 | 80% | 工厂良品率突破99.99% |
| 元宇宙 | $8000亿 | 90% | 沉浸式体验延迟<20ms |
跨模态技术正以“连接万物、理解万物、创造万物”的姿态,重塑人类与信息的交互方式。从智能助手到工业质检,从医疗诊断到元宇宙社交,跨模态技术不仅是效率工具,更是社会生产力跃迁的底层引擎。未来,随着多模态大模型(MLM)与脑机接口的融合,人类将进入“六感融合”的智能时代。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献171条内容
已为社区贡献171条内容

所有评论(0)