云平台一键部署【Step-Audio-EditX】迭代音频编辑
Step-Audio-EditX是一款基于LLM的3B参数音频模型,专注于表达性音频编辑和零样本TTS功能。核心创新包括:1)支持情感(愤怒/喜悦等)、风格(童声/耳语等)和副语言(笑声/叹气等)的多维度编辑;2)无需样本的文本转语音能力;3)支持迭代优化和跨模型编辑。采用大边距数据训练和两阶段学习策略(SFT+PPO),性能超越闭源模型。该模型已在趋动云平台上线,提供一键部署功能,并附有详细教程

Step-Audio-EditX,这是一个强大的基于LLM的音频模型,具有 3B参数,专门用于表达性和迭代音频编辑。它在编辑情感、说话风格和副语言方面表现出色,并且还具有强大的零样本文本转语音 (TTS) 功能。
核心功能:像编辑文本一样编辑声音
1. 多维度情感与风格控制
- 情感编辑
- 支持愤怒、喜悦、悲伤等数十种标签,强度可迭代增强或减弱。例如,将平淡的问候升级为“热情洋溢的推销语气”。
- 风格编辑
- 提供童声、耳语、老人等十余种风格,支持叠加(如“撒娇+严肃”)。
- 副语言插入
- 精准添加呼吸声、笑声、叹气等10类自然token,增强真实感。
2. 零样本TTS
无需录音样本,仅凭文本即可生成语音。
3. 迭代式编辑与跨模型泛化
支持多轮微调,逐步优化效果(如“再温柔一点→延长笑声0.3秒”)。
可编辑闭源模型生成的音频(如GPT-4o-mini-TTS),突破平台限制。
技术原理:大边距数据驱动的范式革命
- 大边距合成数据训练
Step-Audio-EditX通过零样本语音克隆生成“同文本、异属性”音频对 (如同一句话的平静版与愤怒版),结合LLM评分筛选高质量样本。 - 两阶段后训练策略
- 监督微调(SFT):在混合文本-音频数据上训练,支持零样本TTS和基础编辑。
- 强化学习(PPO):引入人类标注和LLM-as-a-Judge生成的偏好数据,优化复杂编辑任务(如从快乐生成悲伤语音)。
- 性能对比:超越闭源模型
官方链接:
- https://huggingface.co/stepfun-ai/Step-Audio-EditX
- https://huggingface.co/stepfun-ai/Step-Audio-Tokenizer
【Step-Audio-EditX】模型已经在趋动云『社区项目』上线,无需自己创建环境、下载模型,一键即可快速部署,快来体验【Step-Audio-EditX】带来的精彩体验吧!
项目入口
- 【Step-Audio-EditX】迭代音频编辑:
https://open.virtaicloud.com/web/project/detail/645910285378613248
类似语音合成项目:
- 【maya-research/maya1】:
https://open.virtaicloud.com/web/project/detail/644440064230912000
- 【Supertone/supertonic】超小文本合成语音模型:
https://open.virtaicloud.com/web/project/detail/648371162766106624
视频教程
云平台一键部署【Step-Audio-EditX】迭代音频编辑_哔哩哔哩_bilibili
启动开发环境
【Step-Audio-EditX】项目主页中,点击运行一下,将项目一键克隆至工作空间,『社区项目』推荐适用的算力规格,可以直接立即运行,省去个人下载数据、模型和计算算力的大量准备时间。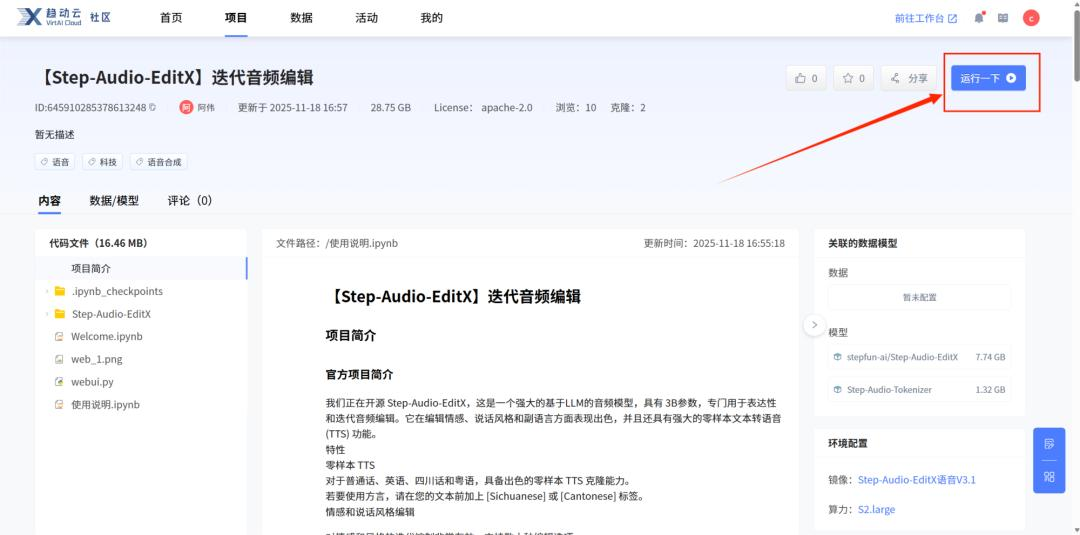
配置完成,点击进入开发环境,根据主页项目介绍进行部署。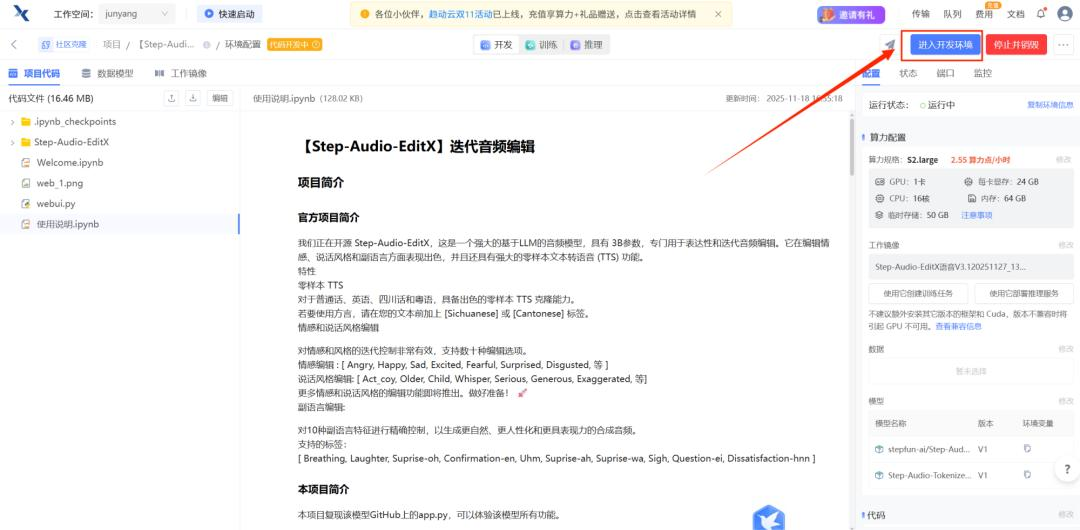
使用方法
在gemini/code中找到使用说明,选中使用说明单元格,点击运行。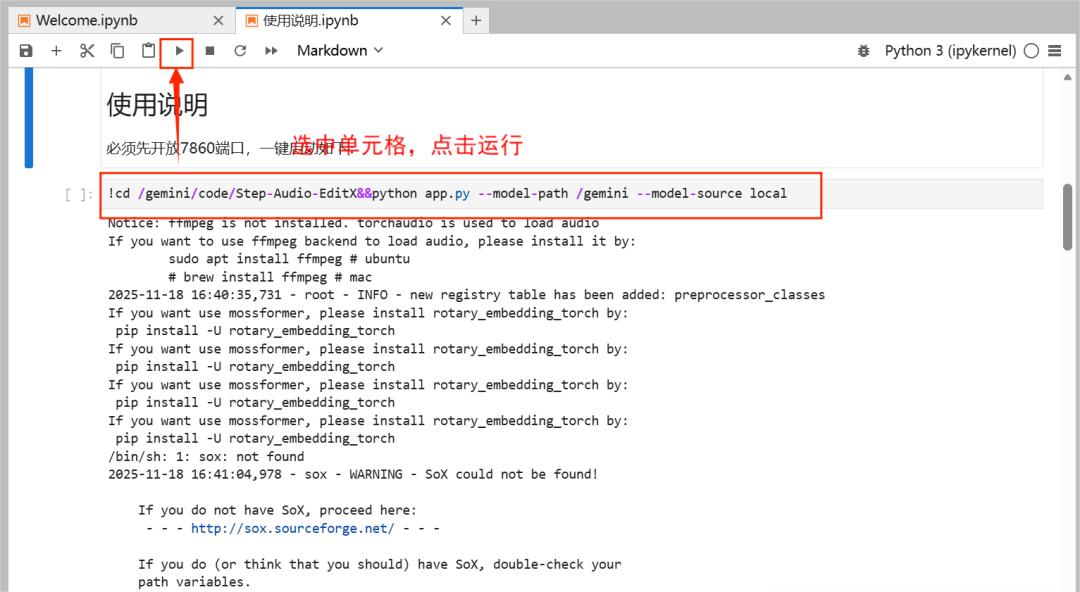
等待生成local URL,右侧添加端口7860。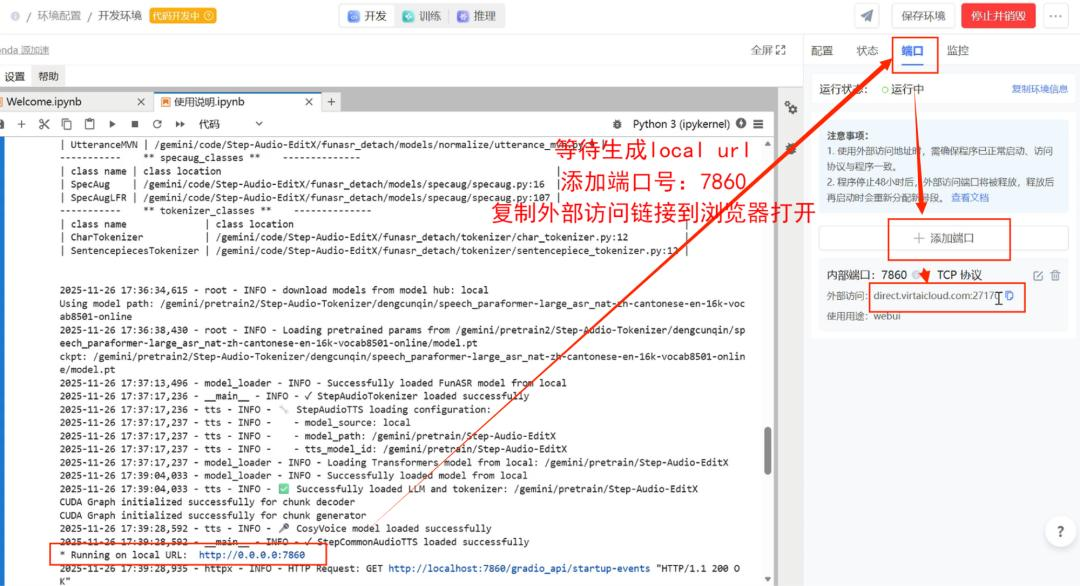
项目使用方法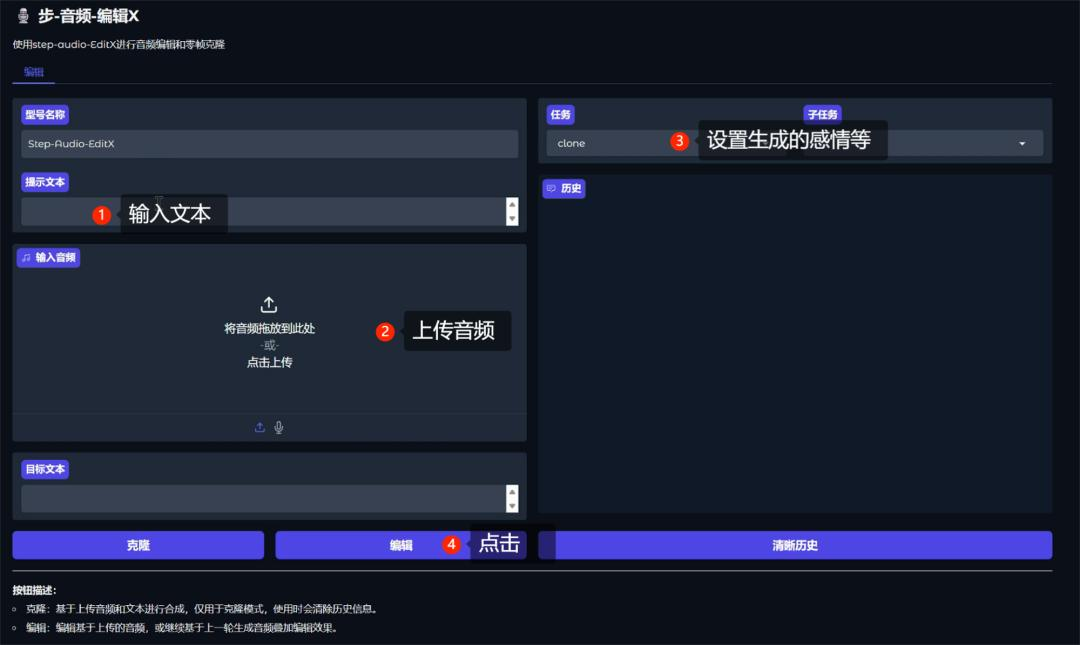
示例展示:(音频示例可在趋动云公众号查看:https://mp.weixin.qq.com/s/ll7coGEU1P4ufsbZQnZQ8A)
➫温馨提示: 完成项目后,记得及时关闭开发环境,以免继续产生费用!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 29
29 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)