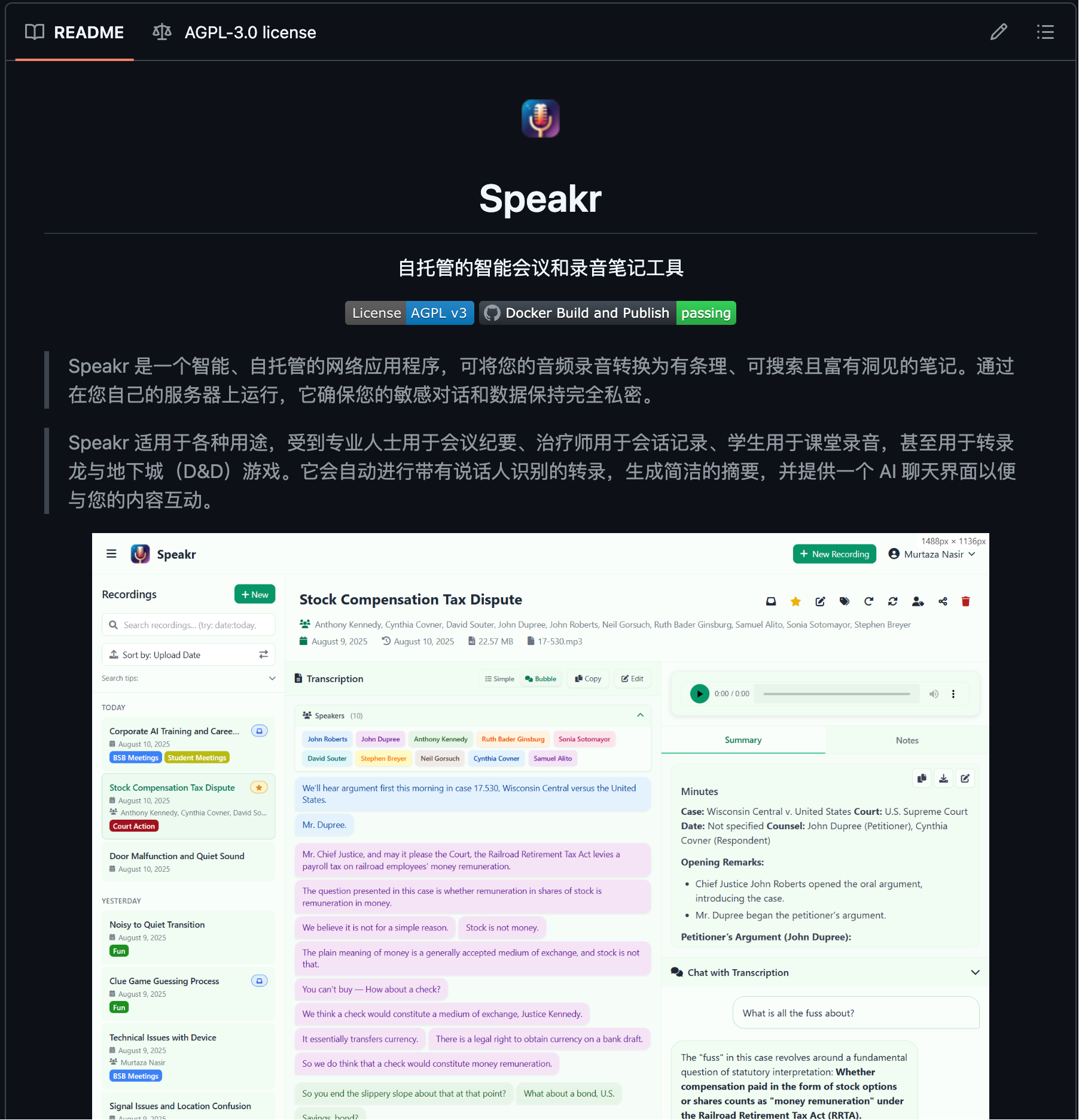
【GitHub项目推荐--Speakr:轻量级文本转语音工具】
Speakr 是一个简单易用的开源文本转语音(TTS)工具,由Murtaza Nasir开发。该项目基于Python构建,提供了简洁的API和命令行界面,能够将文本转换为自然语音输出,支持多种语言和语音引擎。
简介
Speakr 是一个简单易用的开源文本转语音(TTS)工具,由Murtaza Nasir开发。该项目基于Python构建,提供了简洁的API和命令行界面,能够将文本转换为自然语音输出,支持多种语言和语音引擎。
🔗 GitHub地址:
https://github.com/murtaza-nasir/speakr
🗣️ 核心价值:
文本转语音 · 轻量级 · 多语言支持 · 简单易用 · 开源免费
项目背景:
-
无障碍需求:辅助技术需求
-
教育应用:语言学习辅助
-
内容消费:多模式内容消费
-
开发工具:开发者工具需求
-
开源替代:商业TTS替代方案
项目特色:
-
🏗️ 轻量级:轻量级设计
-
🌍 多语言:多语言支持
-
🎛️ 简单API:简单易用API
-
🖥️ CLI支持:命令行界面
-
🔓 开源:完全开源免费
技术亮点:
-
PyTTSx3:基于pyttsx3
-
跨平台:跨平台支持
-
可扩展:易于扩展功能
-
离线工作:离线工作能力
-
配置灵活:灵活配置选项
主要功能
1. 核心功能体系
Speakr提供了一套完整的文本转语音解决方案,涵盖语音合成、语音控制、配置管理、多语言支持、格式转换、流处理、音量调节、速率控制、音高调整、保存输出等多个方面。
语音合成功能:
基础合成:
- 文本输入: 文本输入支持
- 语音输出: 语音输出生成
- 即时播放: 即时语音播放
- 流式处理: 流式文本处理
- 批量处理: 批量文本处理
语音控制:
- 播放控制: 播放暂停控制
- 停止功能: 停止语音输出
- 队列管理: 语音队列管理
- 中断处理: 中断处理机制
- 状态查询: 语音状态查询
输出保存:
- 文件保存: 保存为音频文件
- 格式支持: 多种音频格式
- 质量设置: 输出质量设置
- 批量导出: 批量语音导出
- 元数据: 音频元数据支持语音配置功能:
语音参数:
- 音量调节: 音量大小调节
- 速率控制: 语速快慢控制
- 音高调整: 语音音高调整
- 音色选择: 语音音色选择
- 效果设置: 语音效果设置
语音引擎:
- 引擎选择: 语音引擎选择
- 引擎配置: 引擎参数配置
- 引擎切换: 语音引擎切换
- 引擎状态: 引擎状态查询
- 引擎扩展: 引擎扩展支持
语言支持:
- 语言选择: 多语言支持
- 方言支持: 方言口音支持
- 自动检测: 语言自动检测
- 切换流畅: 语言流畅切换
- 特殊字符: 特殊字符处理2. 高级功能
API服务功能:
Web API:
- REST接口: RESTful API支持
- 实时合成: 实时语音合成
- 批量处理: 批量语音合成
- 状态管理: API状态管理
- 文档完善: API文档完善
集成能力:
- Python集成: Python应用集成
- 脚本调用: 脚本语言调用
- 应用嵌入: 应用内嵌支持
- 服务部署: 服务化部署
- 扩展开发: 扩展开发支持
安全控制:
- 访问控制: API访问控制
- 速率限制: 请求速率限制
- 身份验证: 身份验证支持
- 日志记录: 详细日志记录
- 监控统计: 使用监控统计命令行功能:
基础命令:
- 文本合成: 文本转语音命令
- 文件处理: 文件内容转语音
- 流式输入: 流式输入处理
- 参数设置: 命令行参数设置
- 帮助文档: 完整帮助文档
高级命令:
- 批量转换: 批量文本转换
- 配置管理: 语音配置管理
- 引擎控制: 语音引擎控制
- 效果设置: 语音效果设置
- 脚本支持: 脚本自动化支持
输出控制:
- 输出格式: 输出格式选择
- 保存位置: 文件保存位置
- 播放控制: 播放控制选项
- 质量设置: 输出质量设置
- 元数据: 元数据编辑扩展功能:
插件系统:
- 插件架构: 插件系统架构
- 插件开发: 插件开发支持
- 插件管理: 插件安装管理
- 插件市场: 插件市场支持
- 核心扩展: 核心功能扩展
语音引擎:
- 引擎扩展: 语音引擎扩展
- 自定义引擎: 自定义引擎支持
- 质量优化: 语音质量优化
- 性能调优: 引擎性能调优
- 兼容性: 多引擎兼容
格式扩展:
- 输入格式: 多种输入格式
- 输出格式: 多种输出格式
- 转换工具: 格式转换工具
- 流式支持: 流式格式支持
- 元数据: 丰富元数据实用工具功能:
文本处理:
- 文本清洗: 输入文本清洗
- 格式转换: 文本格式转换
- 编码处理: 文本编码处理
- 分段处理: 长文本分段
- 特殊处理: 特殊文本处理
音频处理:
- 音频合并: 音频文件合并
- 音频分割: 音频文件分割
- 格式转换: 音频格式转换
- 质量调整: 音频质量调整
- 效果处理: 音频效果处理
实用工具:
- 书签功能: 语音书签支持
- 笔记功能: 语音笔记支持
- 提醒功能: 语音提醒支持
- 朗读辅助: 阅读辅助工具
- 学习工具: 语言学习工具安装与配置
1. 环境准备
系统要求:
硬件要求:
- 内存: 2GB+ RAM
- 存储: 500MB+ 可用空间
- CPU: 现代处理器
- 声卡: 音频输出支持
平台要求:
- Windows: Windows 7+
- macOS: macOS 10.12+
- Linux: 主流Linux发行版
- 其他: 其他Python支持平台
软件要求:
- Python: 3.6+
- pip: 最新版本
- 音频驱动: 系统音频驱动
- 开发工具: 可选开发工具依赖要求:
核心依赖:
- pyttsx3: 文本转语音引擎
- pydub: 音频处理支持
- six: 兼容性支持
- 其他: 其他必要依赖
可选依赖:
- gTTS: Google TTS支持
- pygame: 高级音频支持
- pyaudio: 实时音频处理
- 其他: 其他扩展功能
开发依赖:
- pytest: 测试框架
- flake8: 代码检查
- tox: 测试环境
- sphinx: 文档生成
- 其他: 其他开发工具2. 安装步骤
pip安装:
# 基础安装
pip install speakr
# 或指定版本
pip install speakr==0.1.0
# 开发版本安装
pip install git+https://github.com/murtaza-nasir/speakr.git
# 或从源码安装
git clone https://github.com/murtaza-nasir/speakr.git
cd speakr
pip install -e .系统包管理器安装:
# 使用系统包管理器
# 具体根据操作系统选择
# macOS (Homebrew)
brew install speakr
# Linux (Snap)
snap install speakr
# Linux (AUR)
yay -S speakr
# Windows (Scoop)
scoop install speakrDocker安装:
# Docker方式运行
docker pull murtaza/speakr
# 运行容器
docker run -it --rm murtaza/speakr speakr "Hello World"
# 或使用Docker Compose
git clone https://github.com/murtaza-nasir/speakr.git
cd speakr
docker-compose up开发环境安装:
# 开发环境设置
git clone https://github.com/murtaza-nasir/speakr.git
cd speakr
# 创建虚拟环境
python -m venv .venv
source .venv/bin/activate
# 安装开发依赖
pip install -e ".[dev]"
# 或使用pipenv
pipenv install --dev离线安装:
# 离线安装方式
# 下载whl或tar.gz包
pip install speakr-0.1.0-py3-none-any.whl
# 或从源码安装
tar -zxvf speakr-0.1.0.tar.gz
cd speakr-0.1.0
python setup.py install3. 配置说明
基本配置:
# config.yaml 基础配置
speakr:
engine: "pyttsx3" # 语音引擎
language: "en" # 默认语言
voice: "default" # 默认语音
rate: 150 # 语速(词/分钟)
volume: 0.8 # 音量(0.0-1.0)
pitch: 1.0 # 音高(0.5-2.0)
save_path: "./output" # 保存路径
file_format: "mp3" # 文件格式语音引擎配置:
# 语音引擎配置
engines:
pyttsx3:
driver: "sapi5" # Windows
# driver: "nsss" # macOS
# driver: "espeak" # Linux
voices:
- id: "en"
name: "English"
gender: "female"
- id: "zh"
name: "Chinese"
gender: "male"
properties:
rate: 150
volume: 0.8
pitch: 1.0
gtts:
lang: "en"
tld: "com"
slow: false
timeout: 10
proxies: {}音频输出配置:
# 音频输出配置
audio:
format: "mp3"
bitrate: "128k"
channels: 1
sample_width: 2
frame_rate: 44100
codec: "libmp3lame"
metadata:
title: "Speakr Output"
artist: "Speakr"
album: "Generated Speech"
year: "2023"
comment: "Generated by Speakr"高级配置:
# 高级配置
advanced:
cache:
enabled: true
path: "./cache"
max_size: "100MB"
ttl: 86400
logging:
level: "INFO"
path: "./logs"
max_files: 5
max_size: "10MB"
performance:
threads: 2
buffer_size: "1MB"
timeout: 30
security:
allowed_hosts: []
max_request_size: "5MB"
rate_limit: "100/1minute"使用指南
1. 基本工作流
使用Speakr的基本流程包括:环境准备 → 软件安装 → 配置设置 → 文本准备 → 语音合成 → 播放控制 → 输出保存 → 批量处理 → 参数调整 → 扩展使用 → 性能优化 → 持续使用。整个过程设计为完整的文本转语音工作流。
2. 基本使用
Python API使用:
基础使用:
1. 导入库: from speakr import Speaker
2. 创建实例: speaker = Speaker()
3. 设置参数: speaker.set_rate(150)
4. 合成语音: speaker.speak("Hello")
5. 保存文件: speaker.save("output.mp3")
高级功能:
- 批量处理: 批量文本处理
- 流式输入: 流式文本输入
- 回调函数: 合成回调函数
- 事件监听: 合成事件监听
- 错误处理: 错误处理机制
集成开发:
- Web应用: Web应用集成
- 桌面应用: 桌面应用集成
- 移动应用: 移动应用集成
- 自动化: 自动化脚本集成
- API服务: API服务开发命令行使用:
基础命令:
# 基本合成
speakr "Hello World"
# 文件处理
speakr -f input.txt
# 保存输出
speakr "Hello" -o output.mp3
# 参数设置
speakr "Hello" --rate 150 --volume 0.8
高级命令:
# 批量转换
speakr -b inputs/ -o outputs/
# 流式输入
cat long_text.txt | speakr --stream
# 服务模式
speakr --serve --port 8080
参数选项:
--rate: 设置语速
--volume: 设置音量
--voice: 设置语音
--language: 设置语言
--output: 输出文件Web服务使用:
服务启动:
# 启动服务
speakr --serve --port 8080
# 或使用Docker
docker run -p 8080:8080 murtaza/speakr serve
API使用:
# 调用API
curl -X POST http://localhost:8080/speak \
-H "Content-Type: application/json" \
-d '{"text":"Hello","rate":150}'
功能端点:
- /speak: 语音合成
- /voices: 获取语音列表
- /languages: 获取语言列表
- /status: 服务状态
- /batch: 批量处理GUI界面使用:
界面操作:
1. 启动GUI: speakr-gui
2. 输入文本: 输入待转换文本
3. 设置参数: 调整语音参数
4. 试听效果: 点击试听按钮
5. 保存文件: 保存语音文件
功能区域:
- 文本输入: 文本输入区域
- 参数设置: 语音参数设置
- 语音选择: 语音选择区域
- 控制按钮: 播放控制按钮
- 文件操作: 文件保存操作3. 高级用法
批量处理使用:
批量转换:
1. 准备文本: 准备文本文件
2. 批量处理: 执行批量转换
3. 输出管理: 管理输出文件
4. 质量控制: 检查输出质量
5. 后处理: 文件后处理
应用场景:
- 电子书转语音
- 批量文档转换
- 多语言内容生成
- 教育材料准备
- 内容无障碍处理
高级功能:
- 并行处理: 多文件并行处理
- 进度跟踪: 批量进度跟踪
- 错误处理: 批量错误处理
- 元数据: 批量元数据管理
- 自动化: 自动化批量处理插件扩展使用:
插件安装:
1. 查找插件: 查找所需插件
2. 安装插件: 安装插件到系统
3. 配置插件: 配置插件参数
4. 启用插件: 启用插件功能
5. 使用功能: 使用插件功能
插件开发:
1. 了解API: 了解插件API
2. 创建插件: 创建插件项目
3. 实现功能: 实现插件功能
4. 测试调试: 测试插件功能
5. 发布分享: 发布插件分享
插件类型:
- 语音引擎: 语音引擎插件
- 音频处理: 音频处理插件
- 文本处理: 文本处理插件
- 格式支持: 格式支持插件
- 集成插件: 集成扩展插件性能优化使用:
引擎优化:
1. 引擎选择: 选择高效引擎
2. 参数调整: 调整引擎参数
3. 缓存设置: 启用语音缓存
4. 预加载: 语音预加载
5. 资源控制: 资源使用控制
系统优化:
1. 并行处理: 启用并行处理
2. 批处理: 优化批处理
3. 内存管理: 优化内存使用
4. 线程控制: 线程数量控制
5. 硬件加速: 硬件加速支持
音频优化:
1. 格式选择: 选择高效格式
2. 质量平衡: 质量性能平衡
3. 流式处理: 流式处理优化
4. 缓冲设置: 缓冲大小优化
5. 编码优化: 编码参数优化应用场景实例
案例1:电子书朗读
场景:电子书转语音朗读
解决方案:使用Speakr进行电子书朗读。
实施方法:
-
格式转换:电子书转文本
-
章节处理:分章节处理
-
语音合成:批量语音合成
-
质量检查:语音质量检查
-
使用享受:享受有声书
阅读价值:
-
无障碍:视觉障碍辅助
-
多任务:多任务处理
-
学习方式:多样化学习
-
便携性:便携式享受
-
个性化:个性化朗读
案例2:语言学习辅助
场景:语言学习发音辅助
解决方案:使用Speakr辅助语言学习。
实施方法:
-
文本准备:准备学习材料
-
语音生成:生成标准发音
-
对比学习:发音对比学习
-
重复练习:重复跟读练习
-
效果评估:学习效果评估
学习价值:
-
标准发音:标准发音学习
-
重复练习:无限重复练习
-
自主学习:自主学习能力
-
多语言:多语言支持
-
效率提升:学习效率提升
案例3:内容无障碍
场景:内容无障碍访问
解决方案:使用Speakr实现内容无障碍。
实施方法:
-
内容识别:识别文本内容
-
语音转换:转换语音输出
-
界面集成:集成到界面
-
控制支持:播放控制支持
-
用户体验:优化用户体验
无障碍价值:
-
包容性:增强包容性
-
独立性:用户独立性
-
法规合规:合规无障碍
-
用户体验:更好体验
-
社会责任:社会责任
案例4:智能设备交互
场景:智能设备语音反馈
解决方案:使用Speakr提供设备语音反馈。
实施方法:
-
状态识别:设备状态识别
-
文本生成:生成反馈文本
-
语音合成:合成语音反馈
-
播放控制:播放反馈语音
-
用户体验:优化交互体验
交互价值:
-
自然交互:更自然交互
-
多模态:多模态反馈
-
可访问性:增强可访问性
-
品牌形象:提升品牌形象
-
用户满意:提高满意度
案例5:自动化语音通知
场景:自动化语音通知系统
解决方案:使用Speakr构建语音通知系统。
实施方法:
-
事件识别:识别通知事件
-
模板选择:选择语音模板
-
个性化:个性化内容
-
语音生成:生成语音通知
-
分发播放:分发播放通知
通知价值:
-
及时性:及时通知
-
可靠性:可靠传达
-
灵活性:灵活配置
-
成本效益:成本效益高
-
集成性:易于集成
总结
Speakr作为一个功能丰富的开源文本转语音工具,通过其轻量级设计、多语言支持、简单易用、灵活配置和开源免费等特性,为各种文本转语音需求提供了理想的解决方案。
核心优势:
-
🏗️ 轻量级:轻量级设计
-
🌍 多语言:多语言支持
-
🎛️ 简单API:简单易用API
-
🖥️ CLI支持:命令行界面
-
🔓 开源免费:开源免费使用
适用场景:
-
电子书朗读
-
语言学习辅助
-
内容无障碍
-
智能设备交互
-
自动化语音通知
立即开始使用:
# pip安装
pip install speakr
# 基本使用
speakr "Hello World"资源链接:
-
📚 项目地址:GitHub仓库
-
📖 文档:详细使用文档
-
🎓 示例:使用示例
-
💬 社区:社区支持
-
🔧 配置:配置指南
通过Speakr,您可以:
-
文本转语音:文本转语音功能
-
多语言:多语言支持
-
灵活配置:灵活语音配置
-
批量处理:批量处理能力
-
扩展开发:扩展开发支持
特别提示:
-
💻 环境要求:需要Python环境
-
🗣️ 语音质量:依赖系统引擎
-
🔌 扩展功能:可选插件扩展
-
👂 音频输出:需要音频设备
-
📖 长文本:长文本处理能力
通过Speakr,让文本发声!
未来发展:
-
🚀 更多功能:持续添加功能
-
🤖 更智能:更智能的合成
-
🌍 更广泛:更广泛的支持
-
🔧 更易用:更简单的使用
-
📊 更强大:更强大的功能
加入社区:
参与方式:
- GitHub: 提交问题和PR
- 文档: 贡献文档改进
- 示例: 贡献使用示例
- 插件: 开发功能插件
- 反馈: 提供使用反馈
社区价值:
- 技术交流学习
- 问题解答支持
- 功能建议讨论
- 经验分享交流
- 共同推动发展通过Speakr,共同推动开源TTS发展!
许可证:
开源许可证
允许商业使用致谢:
特别感谢:
- 开发团队: Murtaza Nasir
- 贡献者: 代码贡献者
- 社区: 社区支持者
- 用户: 用户反馈支持
- 依赖项目: 依赖项目团队免责声明:
重要提示:
语音合成仅供参考
注意隐私保护
遵守相关法规通过Speakr,体验文本转语音的便捷!
更多好内容请参考以下链接:

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献258条内容
已为社区贡献258条内容

所有评论(0)