MonkeyOCR?实测PDF解析效果
PDF解析有两种方法,基于pipeline的方法和基于端到端的方法。基于pipeline的方法将PDF解析任务拆解为多个小任务,针对性得优化每个小任务,但容易受到错误累积的影响。比如常拆解的任务流程:布局识别、区域分割、文本识别、表格识别、公式识别、结构重组,每个任务使用独立模型,这种设计哲学累积早期阶段的错误,后面任务的的模型再强也无法弥补。基于端到端的方法直接从PDF文档推断出markdown
PDF解析有两种方法,基于pipeline的方法和基于端到端的方法。
基于pipeline的方法将PDF解析任务拆解为多个小任务,针对性得优化每个小任务,但容易受到错误累积的影响。比如常拆解的任务流程:布局识别、区域分割、文本识别、表格识别、公式识别、结构重组,每个任务使用独立模型,这种设计哲学累积早期阶段的错误,后面任务的的模型再强也无法弥补。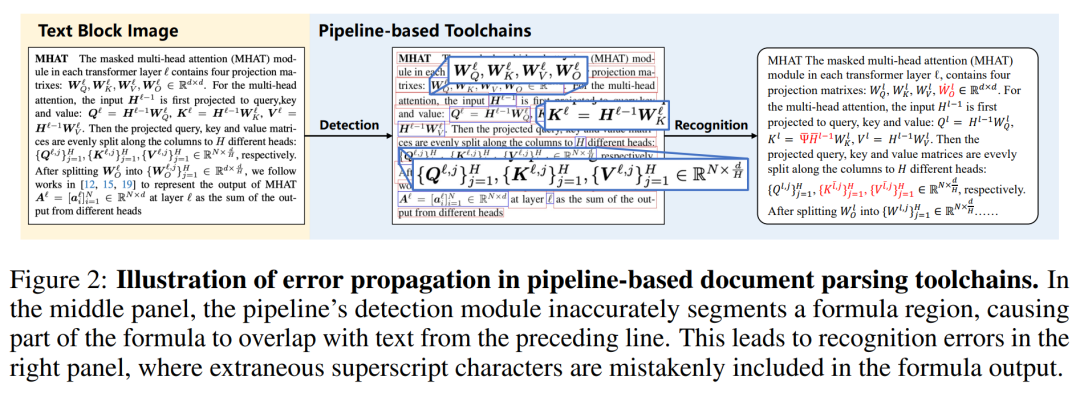
基于端到端的方法直接从PDF文档推断出markdown解析结果,缺乏中间过程,不具备可解释性;一般采用多模态大模型实现,需要的计算资源较大。
MonkeyOCR 则是一种居中的设计,Structure-Recognition-Relation (SRR)三元组方式:文档以目标检测(使用的YOLO)的形式被切分为块(Structure),每一块输入到端到端的大模型中进行识别(Recognition)(分块后会使得LLM推理计算量大大下降),然后结合文档结构和识别到的具体内容来预测多个块内容之间的关系(Relation)。
- 文章:https://arxiv.org/abs/2506.05218
- 代码:https://github.com/Yuliang-Liu/MonkeyOCR
- 体验:http://vlrlabmonkey.xyz:7685/
PDF解析评测指标
在OmniDocBench上,对比整体效果如下:
| Model Type | Methods | Overall Edit↓ | Text Edit↓ | Formula Edit↓ | Formula CDM↑ | Table TEDS↑ | Table Edit↓ | Read Order Edit↓ | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EN | ZH | EN | ZH | EN | ZH | EN | ZH | EN | ZH | EN | ZH | EN | ZH | ||
| Pipeline Tools | PP-StructureV3 | 0.145 | 0.206 | 0.058 | 0.088 | 0.295 | 0.535 | - | - | - | - | 0.159 | 0.109 | 0.069 | 0.091 |
| MinerU | 0.150 | 0.357 | 0.061 | 0.215 | 0.278 | 0.577 | 57.3 | 42.9 | 78.6 | 62.1 | 0.180 | 0.344 | 0.079 | 0.292 | |
| Marker | 0.336 | 0.556 | 0.080 | 0.315 | 0.530 | 0.883 | 17.6 | 11.7 | 67.6 | 49.2 | 0.619 | 0.685 | 0.114 | 0.340 | |
| Mathpix | 0.191 | 0.365 | 0.105 | 0.384 | 0.306 | 0.454 | 62.7 | 62.1 | 77.0 | 67.1 | 0.243 | 0.320 | 0.108 | 0.304 | |
| Docling | 0.589 | 0.909 | 0.416 | 0.987 | 0.999 | 1 | - | - | 61.3 | 25.0 | 0.627 | 0.810 | 0.313 | 0.837 | |
| Pix2Text | 0.320 | 0.528 | 0.138 | 0.356 | 0.276 | 0.611 | 78.4 | 39.6 | 73.6 | 66.2 | 0.584 | 0.645 | 0.281 | 0.499 | |
| Unstructured | 0.586 | 0.716 | 0.198 | 0.481 | 0.999 | 1 | - | - | 0 | 0.06 | 1 | 0.998 | 0.145 | 0.387 | |
| OpenParse | 0.646 | 0.814 | 0.681 | 0.974 | 0.996 | 1 | 0.11 | 0 | 64.8 | 27.5 | 0.284 | 0.639 | 0.595 | 0.641 | |
| Expert VLMs | GOT-OCR | 0.287 | 0.411 | 0.189 | 0.315 | 0.360 | 0.528 | 74.3 | 45.3 | 53.2 | 47.2 | 0.459 | 0.520 | 0.141 | 0.280 |
| Nougat | 0.452 | 0.973 | 0.365 | 0.998 | 0.488 | 0.941 | 15.1 | 16.8 | 39.9 | 0 | 0.572 | 1.000 | 0.382 | 0.954 | |
| Mistral OCR | 0.268 | 0.439 | 0.072 | 0.325 | 0.318 | 0.495 | 64.6 | 45.9 | 75.8 | 63.6 | 0.600 | 0.650 | 0.083 | 0.284 | |
| OLMOCR-sglang | 0.326 | 0.469 | 0.097 | 0.293 | 0.455 | 0.655 | 74.3 | 43.2 | 68.1 | 61.3 | 0.608 | 0.652 | 0.145 | 0.277 | |
| SmolDocling-256M | 0.493 | 0.816 | 0.262 | 0.838 | 0.753 | 0.997 | 32.1 | 0.55 | 44.9 | 16.5 | 0.729 | 0.907 | 0.227 | 0.522 | |
| General VLMs | GPT4o | 0.233 | 0.399 | 0.144 | 0.409 | 0.425 | 0.606 | 72.8 | 42.8 | 72.0 | 62.9 | 0.234 | 0.329 | 0.128 | 0.251 |
| Qwen2.5-VL-7B | 0.312 | 0.406 | 0.157 | 0.228 | 0.351 | 0.574 | 79.0 | 50.2 | 76.4 | 72.2 | 0.588 | 0.619 | 0.149 | 0.203 | |
| InternVL3-8B | 0.314 | 0.383 | 0.134 | 0.218 | 0.417 | 0.563 | 78.3 | 49.3 | 66.1 | 73.1 | 0.586 | 0.564 | 0.118 | 0.186 | |
| Mix | MonkeyOCR-3B [Weight] | 0.140 | 0.297 | 0.058 | 0.185 | 0.238 | 0.506 | 78.7 | 51.4 | 80.2 | 77.7 | 0.170 | 0.253 | 0.093 | 0.244 |
| MonkeyOCR-3B* [Weight] | 0.154 | 0.277 | 0.073 | 0.134 | 0.255 | 0.529 | 78.5 | 50.8 | 78.2 | 76.2 | 0.182 | 0.262 | 0.105 | 0.183 | |
在MonkeyOCR公布的榜单中,第一行添加PP-StructureV3的结果,从Overall Edit指标结果看:
- 英文数据上,MonkeyOCR(0.140)优于PP-StructureV3(0.145) 0.005
- 中文数据上,MonkeyOCR(0.277)差于PP-StructureV3(0.206) 0.071
PDF解析实测
在体验链接上MonkeyOCR,实测PDF解析结果。![![[Pasted image 20250706145642.png]]](https://i-blog.csdnimg.cn/direct/d2a525c5716d40bb9edcdf53ca514c79.png)
其中模型配置均选择默认模式
表格
中文多栏表格![![[Pasted image 20250706142848.png]]](https://i-blog.csdnimg.cn/direct/86a10123b9a14d3aa4a451301f12a5e4.png)
MonkeyOCR解析结果:
英文多栏表格:![![[Pasted image 20250706143052.png]]](https://i-blog.csdnimg.cn/direct/47d64d6abe234405b045346f526b9e32.png) MonkeyOCR解析结果:
MonkeyOCR解析结果:![![[Pasted image 20250706143129.png]]](https://i-blog.csdnimg.cn/direct/d0449c6155a8488eb9c297bf4ad841fe.png)
MonkeyOCR对多栏表格的结构识别的不准
代码
C++代码:![![[Pasted image 20250706143241.png]]](https://i-blog.csdnimg.cn/direct/ef8dfb113ab34726aa0d7f49fab74aba.png)
MonkeyOCR解析结果:![![[Pasted image 20250706143306.png]]](https://i-blog.csdnimg.cn/direct/2059bd76976d4ac8b228cc789a98512c.png)
Python代码:![![[Pasted image 20250706143353.png]]](https://i-blog.csdnimg.cn/direct/e553d91dc03d4c3d963f0034b3c8f16b.png)
![![[Pasted image 20250706143416.png]]](https://i-blog.csdnimg.cn/direct/5f603320ac774850a99036f13b56d8e2.png) MonkeyOCR解析结果:
MonkeyOCR解析结果:![![[Pasted image 20250706143502.png]]](https://i-blog.csdnimg.cn/direct/15b92e4dcd8c4e71a5f6a73a05932d3b.png)

MonkeyOCR对代码识别能力较弱,没有做针对性优化
公式
输入PDF:![![[Pasted image 20250706143720.png]]](https://i-blog.csdnimg.cn/direct/32a2f0b4aeef4bc89ec8a18943efc639.png)
MonkeyOCR解析结果:![![[Pasted image 20250706143807.png]]](https://i-blog.csdnimg.cn/direct/5a7f227364c74c61bdfdd5da8844f83e.png)
MonkeyOCR在公式识别方面较强
多栏识别
Neurocomputing论文多栏识别![![[Pasted image 20250706143950.png]]](https://i-blog.csdnimg.cn/direct/b84b932827584f349eaf61fb572d6609.png)
MonkeyOCR解析结果:![![[Pasted image 20250706144048.png]]](https://i-blog.csdnimg.cn/direct/a8709a26c7f24b1e89fa0ea36378f7f8.png)
仅考虑多栏识别,MonkeyOCR解析结果的顺序是正确的,从上到下分别是标题、作者、abstract及introduction。
印刷版识别
印刷体数学试卷识别:![![[Pasted image 20250706144301.png]]](https://i-blog.csdnimg.cn/direct/70154104aa55465c8bcada0ce735a7ef.png)
MonkeyOCR解析结果:![![[Pasted image 20250706144334.png]]](https://i-blog.csdnimg.cn/direct/7d82cdae09694964867673333e52b430.png)
整体识别还是不错的
结论
- 在多栏表格方面,MonkeyOCR容易对多栏结构识别错误
- 在代码方面,MonkeyOCR效果一般
- 在公式、多栏识别、印刷体识别方面,效果整体还是不错的
以上评测是在笔者挑选的数据上进行的,以上数据仅供参考。
若希望将MonkeyOCR用于自身场景,建议用自身场景数据进行实测对比。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 37
37 0
0- 0



 已为社区贡献60条内容
已为社区贡献60条内容

所有评论(0)