【AI 大模型】大模型行业融合与技术落地探索 ( 百度千帆模型 模型广场 | Hugging Face 模型广场 | 模型类型简介 | 文本生成模型 | 图像理解模型 | 深度推理模型 )
一、大模型类型 简介1、百度千帆模型 模型广场2、千帆模型类型 简介二、 文本生成模型1、模型简介2、文本生成 相关技术领域3、文本生成模型 落地方向三、 深度推理模型四、图像理解模型1、图像理解大模型2、图像理解大模型 落地方向3、图像理解案例

一、大模型类型 简介
1、百度千帆模型 模型广场
百度 的 文心千帆 大模型 的 模型广场 ( https://console.bce.baidu.com/qianfan/modelcenter/model/buildIn/list ) 中 可以看到如下几个类型的大模型 ;
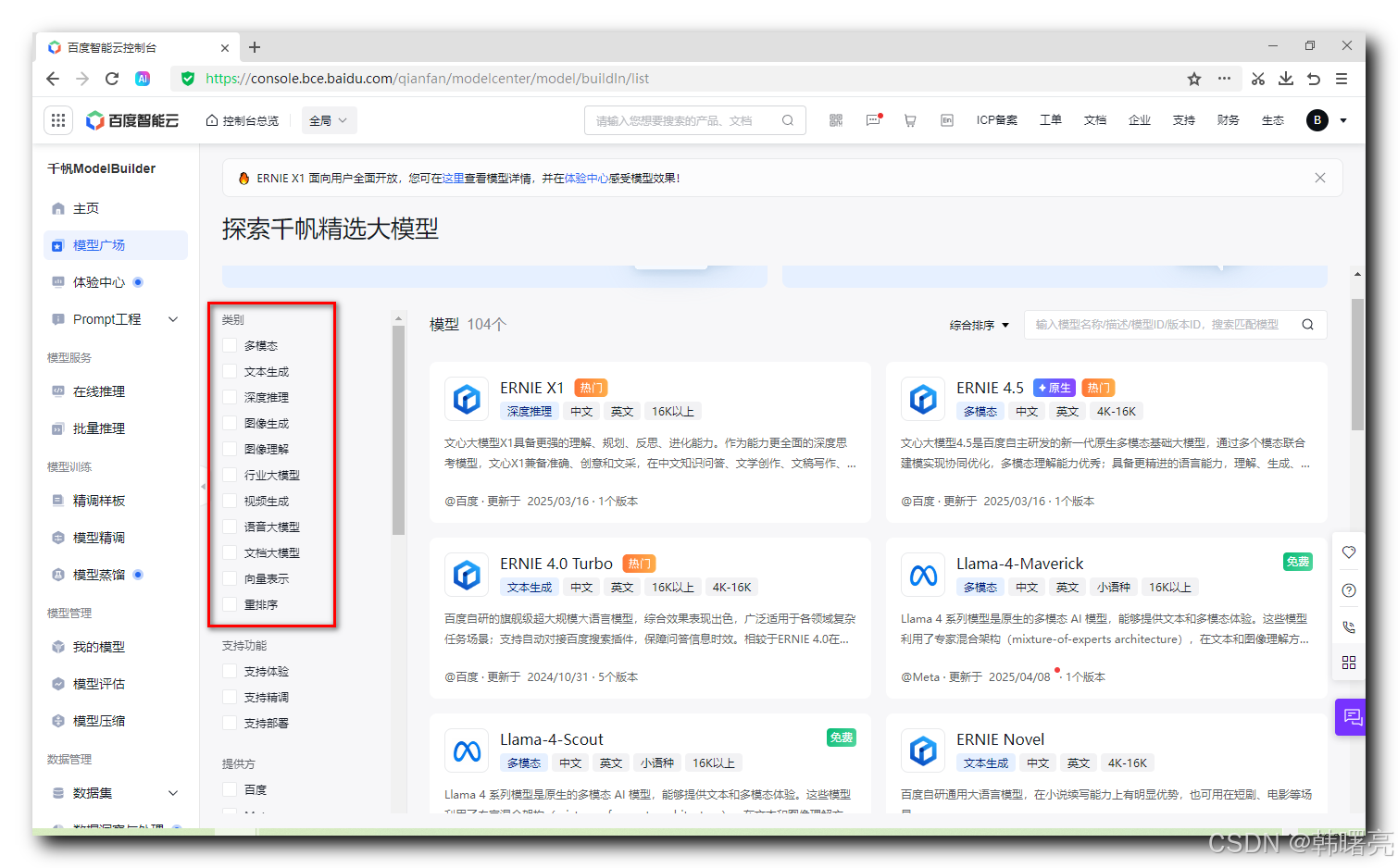
下面对 上述 大模型类型 进行简单介绍 , 这些大模型类型收集的比较全 ;
2、千帆模型类型 简介
大模型类型 简介 :
- 多模态 : 整合 文本 、 图像 、 音频 、 视频 等多种模态信息 , 实现跨模态理解与生成 ;
- 文本生成 : 基于 上下文 生成 连贯文本 , 支持创作、问答、摘要等任务 ;
- 深度推理 : 解决 复杂逻辑 推理问题 ( 数学计算、因果分析、多步决策 ) ;
- 图像生成 : 从 文本 或 图像 输入 生成 高质量图像 ;
- 图像理解 : 识别 图像内容 ( 物体、场景、情感 ) 、 分析语义信息 ;
- 行业大模型 : 针对 垂直领域 ( 金融、医疗、法律 ) 定制化训练 , 解决专业问题 ;
- 视频生成 : 从 文本 / 图像 生成视频 , 或 编辑 现有视频内容 ;
- 语音大模型 : 语音识别 ( ASR ) 、合成 ( TTS ) 、情感分析 ;
- 文档大模型 : 处理 长文本 ( 合同、论文 ) , 实现摘要、问答、结构化提取 ;
- 向量表示 : 将 文本 / 图像 映射为 低维向量 , 用于相似性计算 ;
- 重排序 : 对 检索结果 ( 如搜索、推荐列表 ) 进行 优化排序 ;
深度推理 , 行业大模型 , 文档大模型 , 向量表示 , 重排序 这几个 模型 都是 服务于 文本生成 大模型的 ;
多模态 是 服务于 图像理解 大模型的 ;
语音大模型 可用于 语音识别 和 语音合成 ;
图像生成 , 视频生成 服务于 设计领域 ;
二、Hugging Face 模型类型 简介
在 https://huggingface.co/models 页面 , 可以查看 Hugging Face 的 一系列 开源模型 ;
使用上述模型 , 需要 导入如下 Python 软件包 , 在本地部署使用模型 ;
1、Multimodal ( 多模态 )
该类型 大模型 支持多种数据模态联合处理与信息融合 ;
Multimodal (多模态) 类型 :
- Audio-Text-to-Text (音频-文本 到 文本) : 将 音频与文本结合 生成 新文本 ;
- Image-Text-to-Text (图像-文本 到 文本) : 基于 图像和文本输入 生成 文本结果 ;
- Visual Question Answering (视觉问答) : 回答 与 图像内容相关 的 自然语言问题 , 图像理解 ;
- Document Question Answering (文档问答) : 解析文档内容 并回答相关问题 , 文档大模型 ;
- Video-Text-to-Text (视频-文本 到 文本) : 通过 视频 和 文本输入 产生 文本输出 ;
- Visual Document Retrieval (视觉文档检索) : 根据 视觉信息 检索相关文档 ;
- Any-to-Any (任意到任意) : 实现 任意模态 间的 数据转换与生成 ;
2、Computer Vision ( 计算机视觉 )
Computer Vision (计算机视觉) 类型 :
- Depth Estimation (深度估计) : 预测 图像中 物体 的 三维深度信息 ;
- Image Classification (图像分类) : 识别 图像 所属 预设类别 , 如 : 是否 瞌睡 ;
- Object Detection (目标检测) : 定位 并 识别 图像中的 多个物体 ;
- Image Segmentation (图像分割) : 对 图像 像素 进行 语义或实例级划分 ;
- Text-to-Image (文本到图像) : 根据 文本描述 生成对应图像 ;
- Image-to-Text (图像到文本) : 将 图像内容 转换为文字描述 , 图像理解 ;
- Image-to-Image (图像到图像) : 实现 图像风格 / 内容 的 转换 与 增强 ;
- Image-to-Video (图像到视频) : 基于 静态图像 生成 动态视频 ;
- Unconditional Image Generation (无条件图像生成) : 无需 条件输入 随机生成图像 ;
- Video Classification (视频分类) : 识别 视频内容 的 类别标签 ;
- Text-to-Video (文本到视频) : 通过 文本描述 生成 对应视频片段 ;
- Zero-Shot Image Classification (零样本图像分类) : 无需训练 直接识别未知类别图像 ;
- Mask Generation (掩码生成) : 生成图像中特定区域的掩码标识 ;
- Zero-Shot Object Detection (零样本目标检测) : 无需训练检测未知类别物体 ;
- Text-to-3D (文本到3D) : 根据文本生成三维模型或场景 ;
- Image-to-3D (图像到3D) : 将二维图像转换为三维模型 ;
- Image Feature Extraction (图像特征提取) : 提取图像的深层语义特征 ;
- Keypoint Detection (关键点检测) : 检测图像中物体的关键结构点 ;
3、Natural Language Processing ( 自然语言处理 )
Natural Language Processing (自然语言处理) 类型 :
- Text Classification (文本分类) : 对文本进行情感/主题等分类 ;
- Token Classification (标记分类) : 识别文本中特定标记的语义角色 ;
- Table Question Answering (表格问答) : 基于结构化表格数据回答问题 ;
- Question Answering (问答) : 根据上下文回答自然语言问题 ;
- Zero-Shot Classification (零样本分类) : 无需训练直接进行文本分类 ;
- Translation (翻译) : 实现不同语言间的自动翻译 ;
- Summarization (摘要生成) : 生成文本内容的精简摘要 ;
- Feature Extraction (特征提取) : 提取文本的语义特征向量 ;
- Text Generation (文本生成) : 根据提示生成连贯的自然语言文本 ;
- Text2Text Generation (文本到文本生成) : 将输入文本转换为新形式文本 ;
- Fill-Mask (填充掩码) : 预测文本中被遮蔽部分的合理内容 ;
- Sentence Similarity (句子相似度) : 计算语句间的语义相似度 ;
- Text Ranking (文本排序) : 对文本相关性进行排序评估 ;
4、Audio ( 音频 )
Audio (音频) 类型 :
- Text-to-Speech (文本到语音) : 将文本转换为自然的人类语音 ;
- Text-to-Audio (文本到音频) : 根据文本生成非语音类音频信号 ;
- Automatic Speech Recognition (自动语音识别) : 将语音内容转写为文字 ;
- Audio-to-Audio (音频到音频) : 实现音频信号的转换与增强 ;
- Audio Classification (音频分类) : 识别音频内容的类别标签 ;
- Voice Activity Detection (语音活动检测) : 检测音频中的人声存在区间 ;
5、Tabular ( 表格 )
Tabular (表格) 类型 :
- Tabular Classification (表格分类) : 基于表格数据进行分类预测 ;
- Tabular Regression (表格回归) : 对表格数值型字段进行回归预测 ;
- Time Series Forecasting (时间序列预测) : 预测时间序列数据的未来趋势 ;
6、Reinforcement Learning ( 强化学习 )
Reinforcement Learning (强化学习) 类型 :
- Reinforcement Learning (强化学习) : 通过试错机制优化决策策略 ;
- Robotics (机器人学) : 应用于机器人运动控制与环境交互 ;
7、Graph Machine Learning ( 图机器学习 )
Graph Machine Learning (图机器学习) : 处理 图结构数据 的 表示学习与推理 ;
三、 文本生成模型
文本生成模型 是 大语言模型 最基本 也是 最重要的功能 ;
1、模型简介
文本生成模型 : 基于 上下文 生成连贯文本 , 支持创作、问答、摘要等任务 ;
- 输入 : 提示词 , 如 : 问题、关键词、指令 ;
- 输出 : 生成的文本内容 , 文章、对话、代码等 ;
文本生成 模型 可实现的领域很多 , 通过提示词 可实现 几乎所有 语言类的 功能 ;
2、文本生成 相关技术领域
文本生成 涉及到的 相关技术 :
- 提示工程 : 编写 提示词 , 可以得到几乎 任意领域的答案 ;
- NLU 自然语言理解 / NLP 自然语言处理 : 使用 提示词 + 大模型 可 实现 NLU / NLP 的所有功能 ;
- 编写代码 : 直接给出 代码的详细需求 和 必要的编程信息 , 可以 直接生成准确的代码 , 需要自己调试 ;
- 函数调用 : 可以自定义 函数调用 , 获取 本地数据库 中的知识 或者 RAG 知识库 中的文本数据 ;
- RAG 知识库 : 将本地知识库 存储到 RAG 向量数据库 中 ;
上述技术可以衍生很多应用领域 ;
3、文本生成模型 落地方向
文本生成模型 落地方向 :
- 自动化报告生成 : 根据 实时采集的 生产数据 ( 如开采量、设备状态、环境参数 ) 、 传感器日志 , 自动生成 每日生产报告 、 安全巡检总结 、 设备维护记录 ;
- 安全规程动态生成 : 根据 地质勘探数据、作业环境参数 ( 如瓦斯浓度、温湿度 ) 、历史事故案例 , 定制化 生成 安全操作指南、应急预案 ;
- 卡车指令助手 : 根据 卡车 GPS 定位数据 、 矿区地图 、 实时任务队列 , 输出 动态 路径规划指令 、 装卸任务优先级建议 ;
- 驾驶行为分析与报告 : 根据 驾驶行为数据 ( 急加速、急刹车 ) 、视频监控片段 , 生成 驾驶行为评分报告 、 个性化改进建议 ;
- 矿山制度文档自动化生成 : 根据 法规政策更新、企业内部管理需求、历史制度文件 , 生成 新版安全管理制度 、 操作手册 、 应急预案 ;
- 员工培训与考核 : 根据 岗位技能要求、历史事故数据、员工绩效记录 , 生成 个性化培训计划 、 模拟考核试题 、 安全教育材料 ;
- 动态知识库构建 : 根据 技术文档 、 专家经验 、 行业标准、实时生产数据 , 集成检索增强生成 ( RAG ) 技术 , 提升知识检索的准确性 , 构建 知识库 、 结构化知识图谱 、 FAQ 自动问答系统 ;
- 智能决策支持 : 根据 历史生产数据 、 市场趋势 、 政策文件 , 生成 战略规划建议、资源分配方案、风险评估报告 ;
四、 深度推理模型
深度推理模型 用于 解决 复杂 逻辑推理问题 , 如 : 数学计算、因果分析、多步决策 ;
- 输入 : 结构化 / 非结构化问题 , 如 : 数学题 、 策略规划 需求 ;
- 输出 : 推理过程 与 结论 , 步骤化解释或最终答案 ;
深度推理模型 基于 Transformer 深度学习架构 进行 复杂逻辑推理 , 能够处理 数学证明、因果推断、多步规划 等高复杂度任务 , 其核心是 通过 自注意力机制 捕捉 输入数据 的深层关联 , 并 生成可解释的推理链条 ;
行业落地方向 :
- 金融 : 投资决策 、 风险评估 ;
- 法律 : 合同审查 、 条款分析 ;
- 科研 : 数据分析 、 科学问题求解 ;
- 医疗 : 结合医学知识库 , 生成诊断依据链 , 如 : 从 症状 到 病因 的 多步推理 ;
深度推理模型 是 文本模型 的 更进一步 优化 , 还是处理文本信息 , 可以给出 推理思考 的过程 , 当前的 文本生成模型 默认集成 深度推理模型 ;
五、图像理解模型
1、图像理解大模型
图像理解大模型 可以 识别图像内容 , 如 : 物体、场景、情感等 , 分析 表情 、 语义信息 ;
- 输入 : 图像 或 视频帧 , 也可以附加 提示词 , 给出 图像理解 的方向 和 想要得到的 答案 ;
- 输出 : 标签、检测框、语义描述、情感分析 , 可根据提示词要求 , 输出 指定格式 的 文本信息 ;
2、图像理解大模型 落地方向
图像理解大模型 落地方向 :
- 无人驾驶卡车智能调度 : 通过 车载摄像头 与 无人机图像 实时采集 矿区道路图像 , 动态识别 路面障碍物 ( 如落石、积水 ) 、 坡度变化 及 车辆位置 , 结合 GPS 数据优化路径规划 ;
- 爆破作业智能监测 : 分析 爆破前 岩体结构图像 , 预测 裂纹扩展方向 ; 爆破后通过无人机图像评估效果 , 识别未完全破碎区域 ;
- 边坡安全与地质风险预警 : 定期扫描 边坡图像 , 结合历史数据训练模型 识别 微小裂缝 或 位移迹象 , 预测滑坡风险 ;
- 设备状态监控 : 通过 固定摄像头与巡检机器人 采集 机械设备 、 皮带运输机 等图像 , 识别机械故障 ( 如轴承过热、皮带撕裂 ) ; 需要 提前 构建设备缺陷标注数据库 ;
- 人员安全与违规行为识别 : 实时监控 人员 是否佩戴安全装备、是否进入危险区域 , 并联动报警系统 ; 采用 视频时序分析模型 ( 如3D-CNN ) 识别动态违规行为 ( 如攀爬设备 ) ;
- 地质构造智能预测 : 结合 钻孔岩芯图像 与 地质雷达数据 , 预测 煤层厚度 、 断层位置 , 指导开采方案 ; ( 要求比较高 , 需要地质专家介入 )
- 驾驶员行为分析与疲劳监测 : 车内摄像头 捕捉驾驶员 面部表情与姿态 , 判断 疲劳等级 并触发警报 ;
- 运输过程货物状态监控 : 货厢图像 识别 矿石装载量 是否超限 、 是否有撒漏风险 , 联动称重系统校准数据 ;
3、图像理解案例
使用 DeepSeek-VL2-Small 图像理解 大模型 ;
给出一张图片 :

使用 多模态 输入 , 同时输入 一张图片 和 提示词 ;
下面对图片进行简单的描述 ;
① " 描述一下上述图片的内容 " 提示词 + 图片 提交给 DeepSeek-VL2-Small 大模型 ;
输出内容 :
图片中是一只可爱的卡通熊猫。它有着大大的黑色眼圈,白色的毛发和黑色的耳朵、四肢,脸上带着灿烂的笑容,显得非常开心。熊猫穿着一件橙色的连帽衫,衣服上有白色的拉链和袖口,脚上还穿着橙色和白色相间的袜子。背景是一个森林环境,有竹子和其他绿色植物,地上散落着一些光点,可能是落叶或灯光,营造出一种温暖、柔和的氛围。整个画面充满了童趣和温馨的感觉。
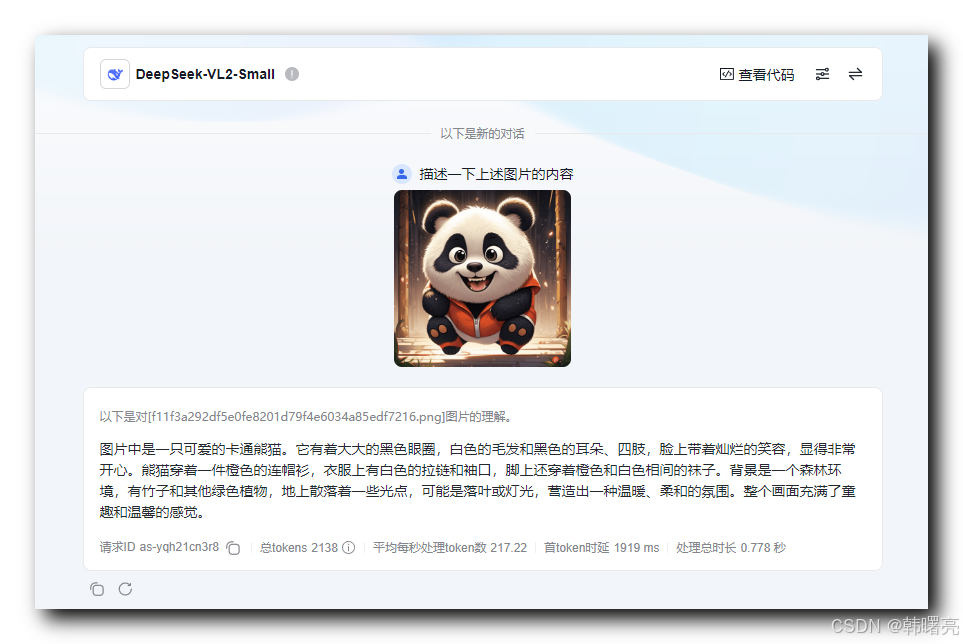
判断 图片中的 任务动作 , 图像理解大模型 可以准确的理解 该图片 中的 动作 和 表情 ;
② " 图像中的熊猫在睡觉吗 " 提示词 + 图片 提交给 DeepSeek-VL2-Small 大模型 ;
输出内容 :
图像中的熊猫看起来像是在坐着,而不是在睡觉。它穿着一件橙色的连帽衫,脸上带着微笑,眼睛睁得大大的,显得非常开心和活泼。背景似乎是一个森林环境,有一些光点漂浮在空中,增添了一种温暖和梦幻的氛围。熊猫的表情和姿势传达出一种愉快和好奇的感觉。
如果想要 格式化 的输出 , 可以限制 大模型的 输出内容 , 得到一个 格式化的 输出文本 ;
③ " 图像中的熊猫在打瞌睡吗 , 给出答案 是 或者 不是 , 不要输出其它内容 " 提示词 + 图片 提交给 DeepSeek-VL2-Small 大模型 ;
输出内容 :
不是

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 42
42 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)