在Qwen3-235B-A22B和Qwen3-30B-A3B等MoE(混合专家)模型中,网络的不同部分阿里Qwen3震撼发布!开源生态再升级,开启通用人工智能新纪元
这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。轻量级模型的训练则涉及对基础模型的蒸馏。更重要的是,这些模型完全开放试用,开发者可以自由调用,打造惊艳的应用。大模型的发展是当前人工智能时代科技进步的必然趋势,我
01
引言
通义千问正悄然接二连三地推出新模型。其每个模型都具备令人无法忽视的强悍功能与极致量化体积——继今年发布QvQ、Qwen2.5-VL和Qwen2.5-Omni之后,Qwen团队最新推出了Qwen3系列。这次他们一次性发布了八款不同规格的模型,参数规模从6亿到2350亿不等,直接对标OpenAI的o1、Gemini 2.5 Pro、DeepSeek R1等顶尖模型。本文将深入解析Qwen3系列,全面剖析其特性、架构、训练过程、性能表现及实际应用场景。
02
Qwen3是什么?
由阿里巴巴集团开发的Qwen3是通义千问第三代模型,专精于编程、推理与语言处理等多领域任务。该系列包含2350亿、300亿、320亿、140亿、80亿、40亿、17亿及6亿参数共八款不同规格模型。所有模型均支持多模态输入(文本/音频/图像/视频),并已全面开放免费使用。
这些模型直接对标o1、o3-mini、Grok 3、Gemini 2.5 Pro等顶尖产品。实际上,Qwen3新系列不仅在性能上超越主流模型,相较同参数级别的既往Qwen模型亦有显著提升。例如Qwen-30B-A3B模型(300亿总参数/30亿激活参数)的表现就优于全参数激活的QwQ-32B模型(320亿参数)。
- Qwen3模型架构概览
该系列包含8款模型,其中2款采用混合专家系统(MoE)架构,其余6款为稠密模型。具体规格如下表所示:
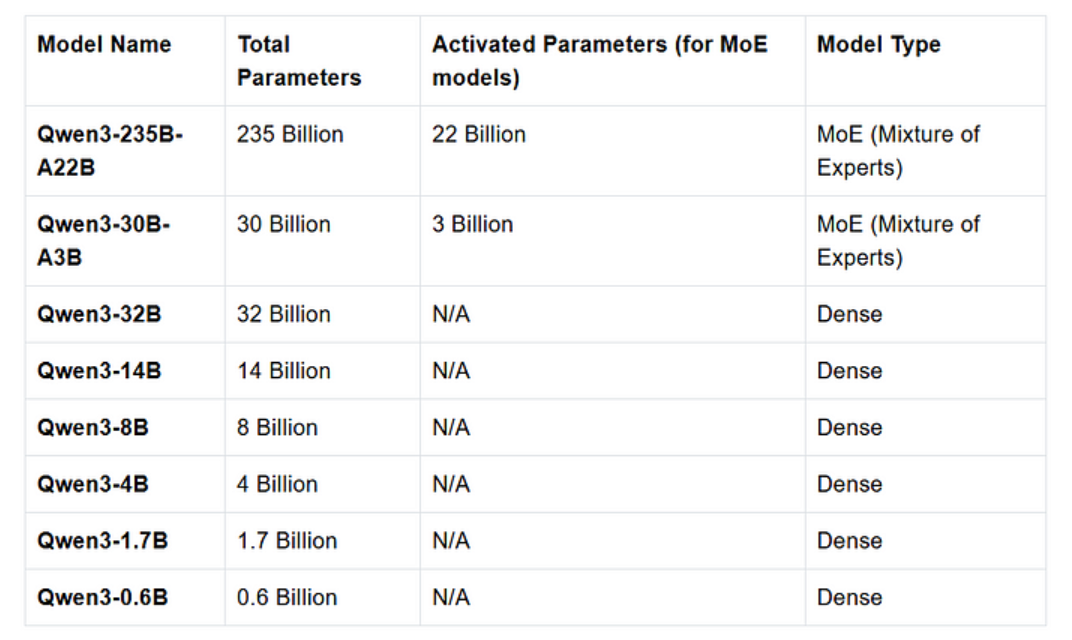
在Qwen3-235B-A22B和Qwen3-30B-A3B等MoE(混合专家)模型中,网络的不同部分(即"专家"模块)会根据输入内容动态激活,从而显著提升计算效率。相比之下,Qwen3-14B等稠密模型在处理每个输入时都需要激活全部网络参数。
03
**Qwen3的技术亮点
**
-
混合推理模式
-
**思考模式:**适用于需要多步推理、逻辑演绎或复杂问题求解的任务。该模式下,Qwen3模型会将问题拆解为多个可处理的子步骤,逐步推导出最终答案。
-
**非思考模式:**适合需要快速响应的场景,如实时对话、信息检索或简单问答。此模式下,Qwen3模型能基于既有知识或简单网络搜索即时生成回复。
这种混合策略目前已成为高性能大语言模型的主流方案,既能充分发挥模型潜力,又可实现计算资源的精准调配。
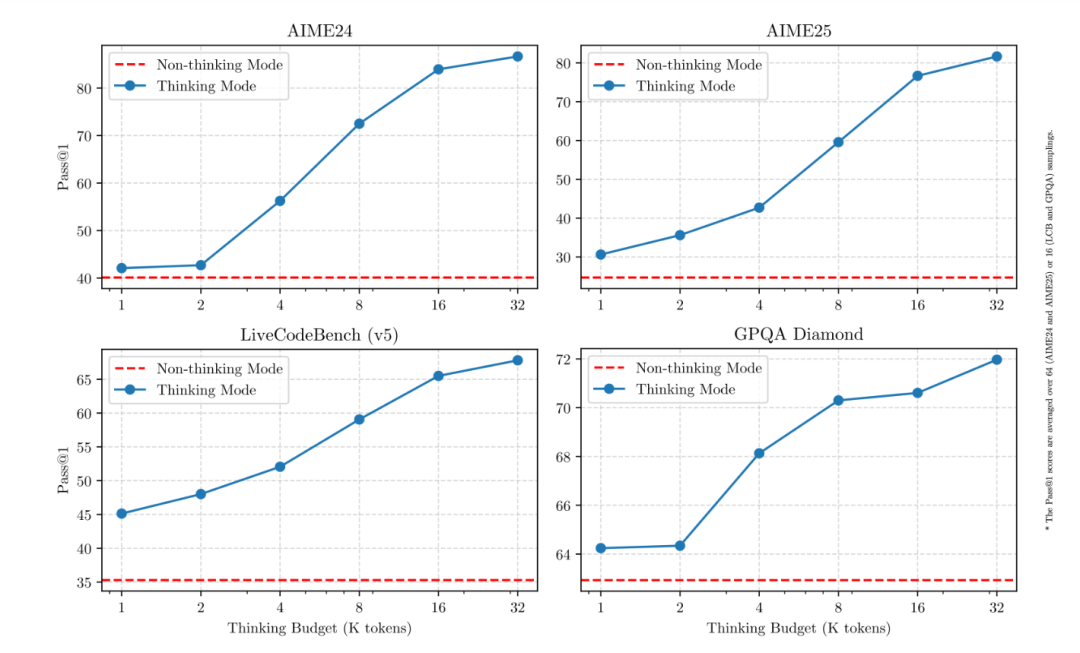
Qwen3系列最新模型首创"思考深度"调控功能,用户可根据任务需求自主分配计算资源。这项突破性特性让使用者能在成本与质量之间取得最优平衡,实现精准的算力预算管理。
Qwen3模型经过优化,具备出色的编码和智能体能力。这些模型还增强了对模型上下文协议(MCP)的支持。通过展现更强的与外部环境交互能力,Qwen3模型表现更加出色。同时,它们还配备了改进的“工具调用”功能,非常适合构建智能体。实际上,团队还发布了“Qwen-Agent”——一种专门的工具,用于利用Qwen模型创建智能体。
-
增强的预训练和后训练****技术
-
**预训练:**其预训练过程为三个步骤。第一步是在4K上下文长度下,训练超过30万亿个Tokens。第二步是在STEM、编码和推理任务中进行训练,而最后一步则利用长上下文数据,将上下文长度扩展至32K个Tokens。
-
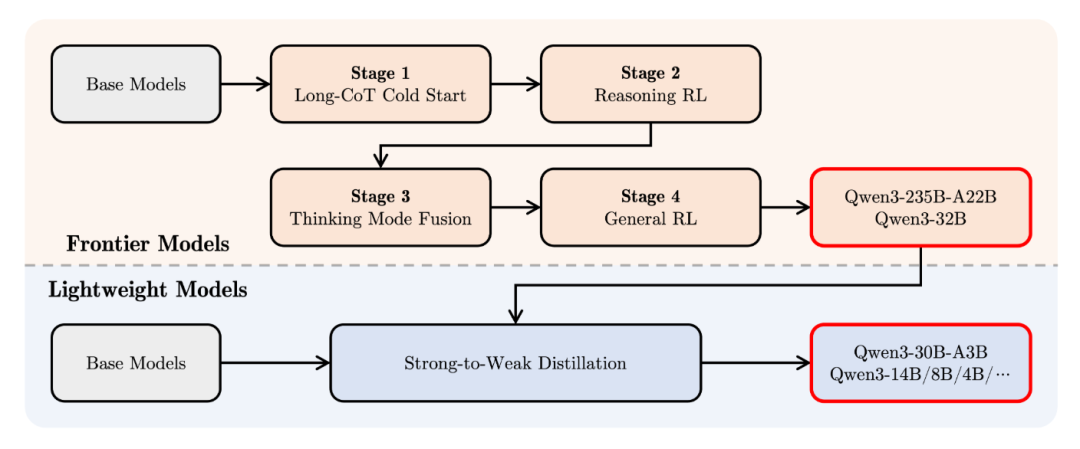
**后训练:**支持混合“思考”方法的Qwen3模型采用四步推理过程。四个步骤包括长链式思考(CoT)冷启动、基于推理的强化学习(RL)、思考模式融合,以及最终的通用强化学习。轻量级模型的训练则涉及对基础模型的蒸馏。
-
其他特性
-
**开放权重:**所有Qwen3模型均采用Apache 2.0许可证开放权重。这意味着用户可以不受重大限制地下载、使用甚至修改这些模型。
-
**多语言支持:**该模型目前支持119种以上的语言和方言,是最新大型语言模型中少数专注语言包容性的代表之一。
04
应用示例
在详细探讨了所有特性之后,现在让我们深入了解 Qwen3 模型的强大能力。我们将针对以下三个模型进行测试:Qwen3–235B-A22B、Qwen3–30B-A3B 和 Qwen3–32B,并评估它们在以下三大任务上的表现:
- 复杂逻辑推理 *
*** - 代码生成与理解
- 图像分析
现在,测试正式开始!
- 复杂逻辑推理
Prompt: 一名宇航员以 0.8c(光速的80%,以地球为参考系)从地球飞往 8光年 外的遥远恒星。在旅程的中途点,宇航员绕行至一个黑洞附近,此处存在极强的 引力时间膨胀效应。绕行过程在宇航员的参考系中持续了 1年,但由于引力影响,该区域的时间流逝速度仅为外界的 1/10(即时间慢10倍)。
宇航员声称,包括绕行时间在内,整个旅程对其而言仅过去了6年。
请结合 狭义相对论 和 引力时间膨胀效应,逐步分析宇航员的“仅经历6年”这一说法是否符合已知相对论效应。需分别考虑 匀速运动阶段 和 黑洞附近区域 的时间流逝差异。
Model: Qwen3–30B-A3B
输出如下:
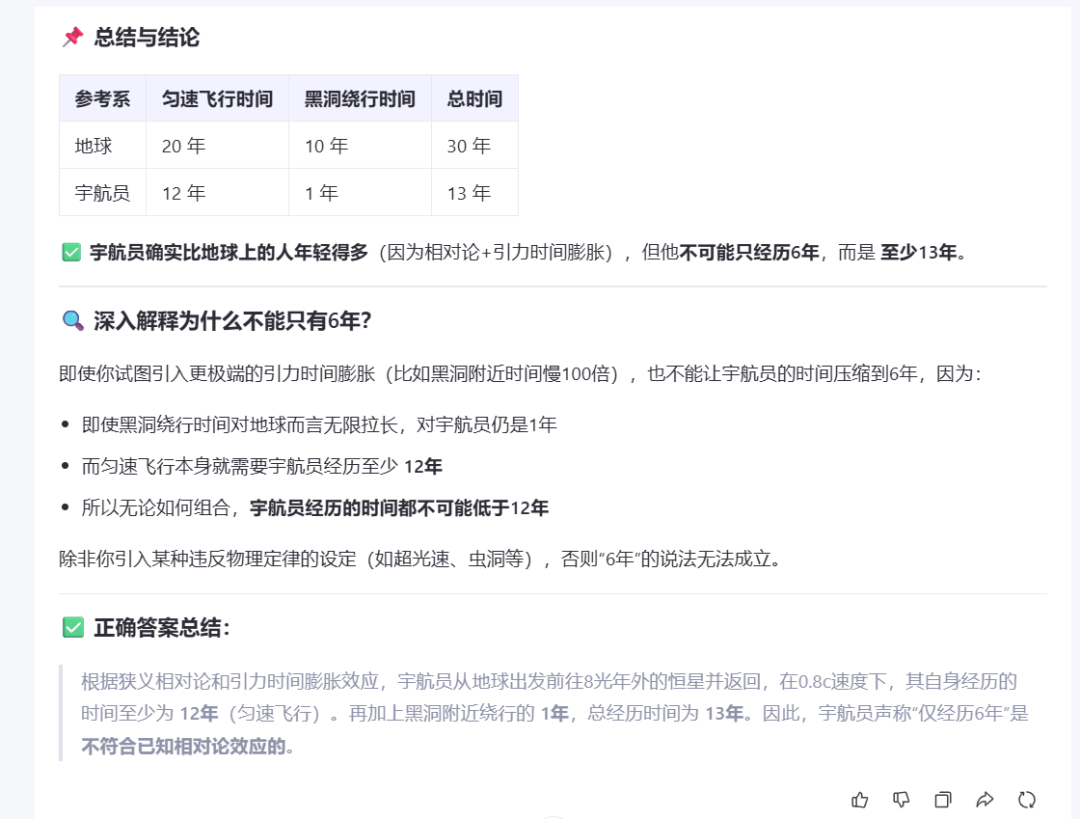
这个模型的运行速度令人惊叹!它能逐步解决问题,并用简洁的语言解释每个步骤。随后,模型会针对问题陈述进行详细计算,并最终生成结论。更值得一提的是,它还会进一步分析结果,确保所有要点都得到有效覆盖。
05
*Coding*
提示词如下:
Create a web page that helps users suggest the best outfit for them based on the weather, occasion, time of the day, and the price range.
输出如下:
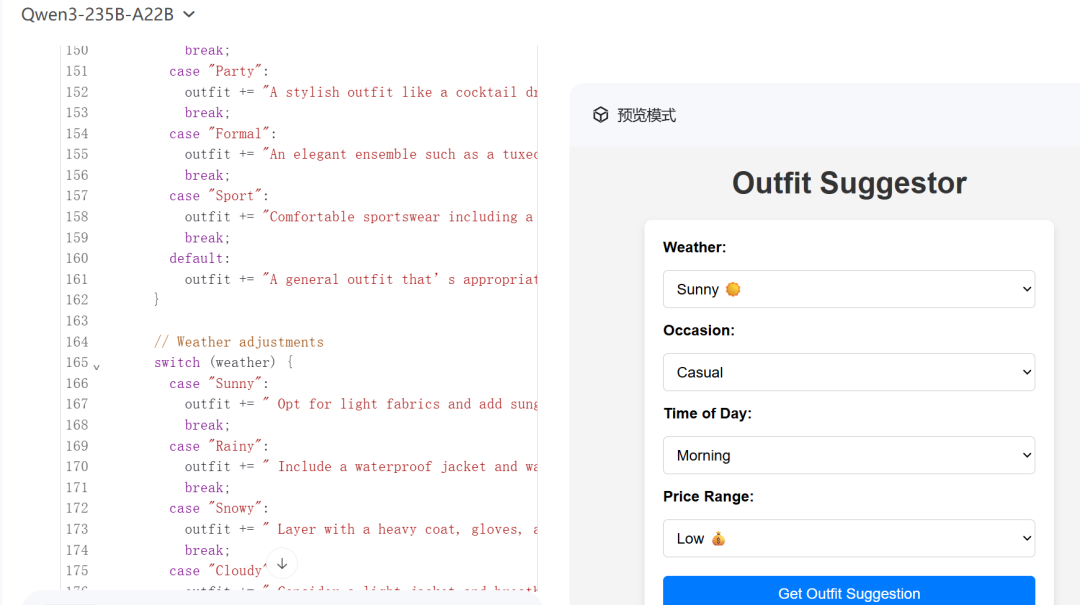
06
Benchmark Performance
在上一节中,我们观察了三款不同Qwen3模型在三个任务中的表现。所有模型都展现出优异性能,其解题思路令我感到惊喜。现在让我们将Qwen系列模型与其他顶尖模型及前代产品进行基准测试对比。相较于OpenAI-o1、DeepSeek-R1、Grok 3、Gemini 2.5 Pro等顶级模型,Qwen-235B-A22B以明显优势拔得头筹——这完全名副其实,其在编程和多语言支持基准测试中均呈现卓越表现。
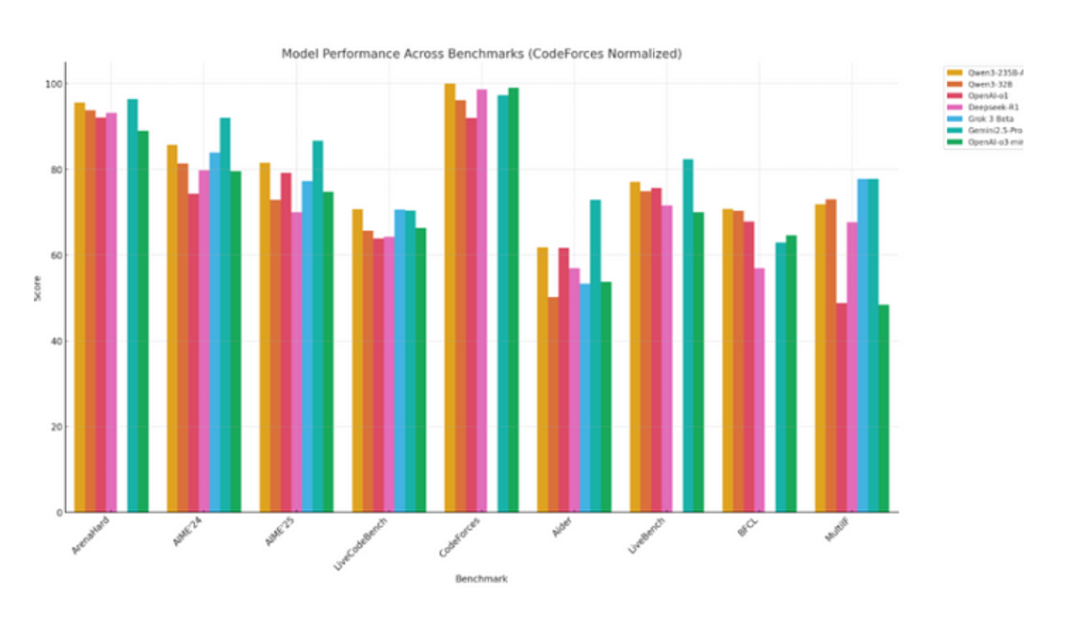
事实上,紧凑型的Qwen3-32B模型也成功超越多款竞品,使其成为诸多任务中极具性价比的选择。
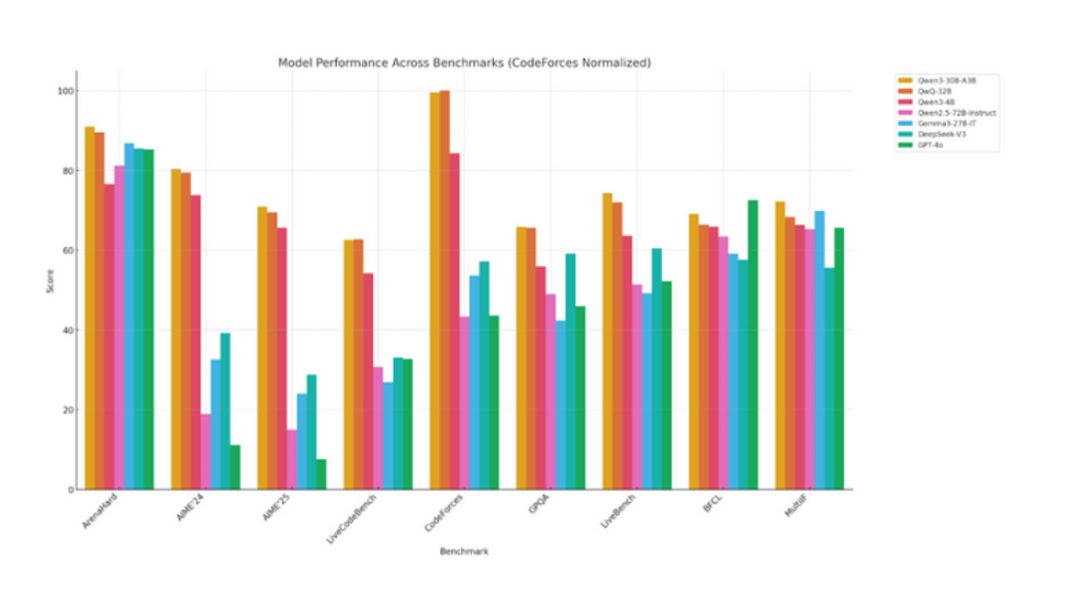
与前代产品相比,Qwen3系列中的Qwen3-30B-A3B和Qwen3-4B模型在性能上超越了大多数现有模型。这些模型不仅表现更出色,凭借其高性价比的定价策略,Qwen3系列确实实现了对前代版本的全面升级。
07
如何访问?
访问Qwen3模型的方法如下:
-
打开QwenChat 网址: https://chat.qwen.ai/
-
进入QwenChat。
-
选择模型 在屏幕左侧中间的下拉菜单中,选择您希望使用的模型。
-
访问后训练和预训练模型
如果需要访问后训练模型及其预训练版本,大家可以前往Hugging Face、Modelscope和Kaggle。
-
部署模型
在部署方面,可以使用诸如SGLang和vLLM等框架。
-
本地访问模型
要在本地访问这些模型,可以使用Ollama、LMStudio、MLX、llama.cpp和KTransformers等工具。
08
相关应用
Qwen3模型表现惊艳,能在以下场景中发挥强大作用:
-
智能体开发
Qwen3模型升级了函数调用能力,是构建AI智能体的理想选择。这类智能体可应用于金融、医疗、人力资源等多个领域,协助完成各类任务。 -
多语言任务
Qwen3支持多语言处理,能为实时翻译、语言分析和多语言文本处理等任务提供强大支持,是多语言工具开发的绝佳选择。 -
移动端应用
Qwen3的小尺寸模型性能远超同类轻量级模型(SLMs),可赋能移动端应用,为其集成大语言模型能力。 -
复杂问题决策支持
Qwen3具备"思考模式",能有效拆解复杂问题,如市场预测、资产规划和资源管理等,提供系统性决策支持。
09
结论
当OpenAI、谷歌等巨头的最新大模型都在堆砌参数时,Qwen3系列却连最小规格的模型都做到了高效精炼。更重要的是,这些模型完全开放试用,开发者可以自由调用,打造惊艳的应用。
这些模型具有颠覆性吗?或许不算。但****它们更好用吗?
应用,为其集成大语言模型能力。
- 复杂问题决策支持
Qwen3具备"思考模式",能有效拆解复杂问题,如市场预测、资产规划和资源管理等,提供系统性决策支持。
09
结论
当OpenAI、谷歌等巨头的最新大模型都在堆砌参数时,Qwen3系列却连最小规格的模型都做到了高效精炼。更重要的是,这些模型完全开放试用,开发者可以自由调用,打造惊艳的应用。
这些模型具有颠覆性吗?或许不算。但****它们更好用吗?
答案绝对是肯定的!更难得的是,凭借灵活的"思考"能力,这些模型能让用户根据任务复杂度动态分配算力资源。每次Qwen系列发布都让我充满期待——因为它们总能用更精简的架构,实现许多顶级模型至今未能达成的效果。
如何学习AI大模型?
大模型的发展是当前人工智能时代科技进步的必然趋势,我们只有主动拥抱这种变化,紧跟数字化、智能化潮流,才能确保我们在激烈的竞争中立于不败之地。
那么,我们应该如何学习AI大模型?
对于零基础或者是自学者来说,学习AI大模型确实可能会感到无从下手,这时候一份完整的、系统的大模型学习路线图显得尤为重要。
它可以极大地帮助你规划学习过程、明确学习目标和步骤,从而更高效地掌握所需的知识和技能。
这里就给大家免费分享一份 2025最新版全套大模型学习路线图,路线图包括了四个等级,带大家快速高效的从基础到高级!




如果大家想领取完整的学习路线及大模型学习资料包,可以扫下方二维码获取
👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

大模型教程
👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

电子书
👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,需要的扫描下方二维码领取 **

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献461条内容
已为社区贡献461条内容

所有评论(0)