SenseVoice部署,并调用api接口
摘要:本文详细介绍了SenseVoice语音识别系统的部署流程。首先需要安装Python并配置pip镜像源,然后下载项目代码并创建虚拟环境。接着安装项目依赖,通过modelscope下载语音识别和VAD模型。为启用Web界面,需修改webui.py的端口配置并运行。若需API调用,则通过uvicorn启动api.py服务,开放指定端口后即可访问/api/v1/asr接口。整个过程包括环境配置、模型
安装Python
这个网上找下教程安装下就可以,版本应该没有什么要求,我装的是3.10.7
记得设置pip镜像,不然后面下载包会很慢。
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
代码下载
GitHub网址:https://github.com/FunAudioLLM/SenseVoice
可以通过git下载或者直接在github下载zip包:
git clone https://github.com/FunAudioLLM/SenseVoice.git
解压出来文件夹是这样子的:
虚拟环境
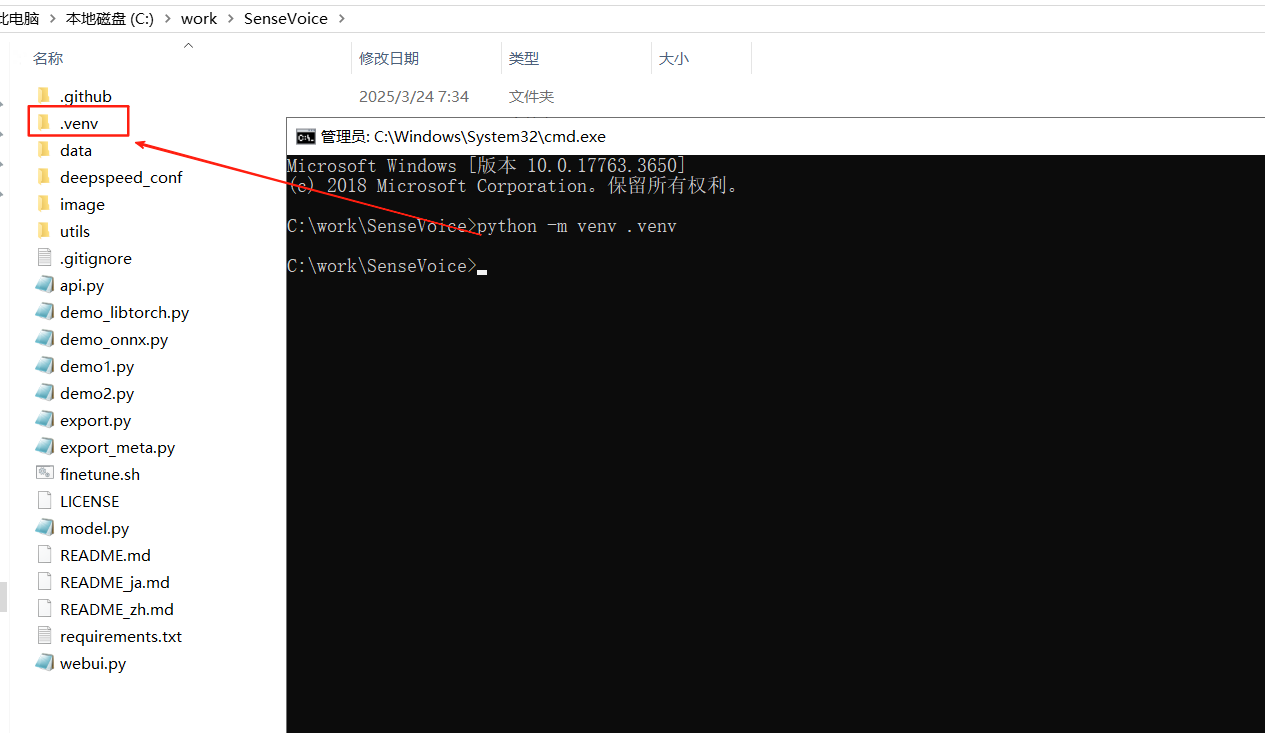
- 进入项目根文件夹 ,运行cmd命令:
创建虚拟环境(出现.venv文件夹就算成功了)
python -m venv .venv
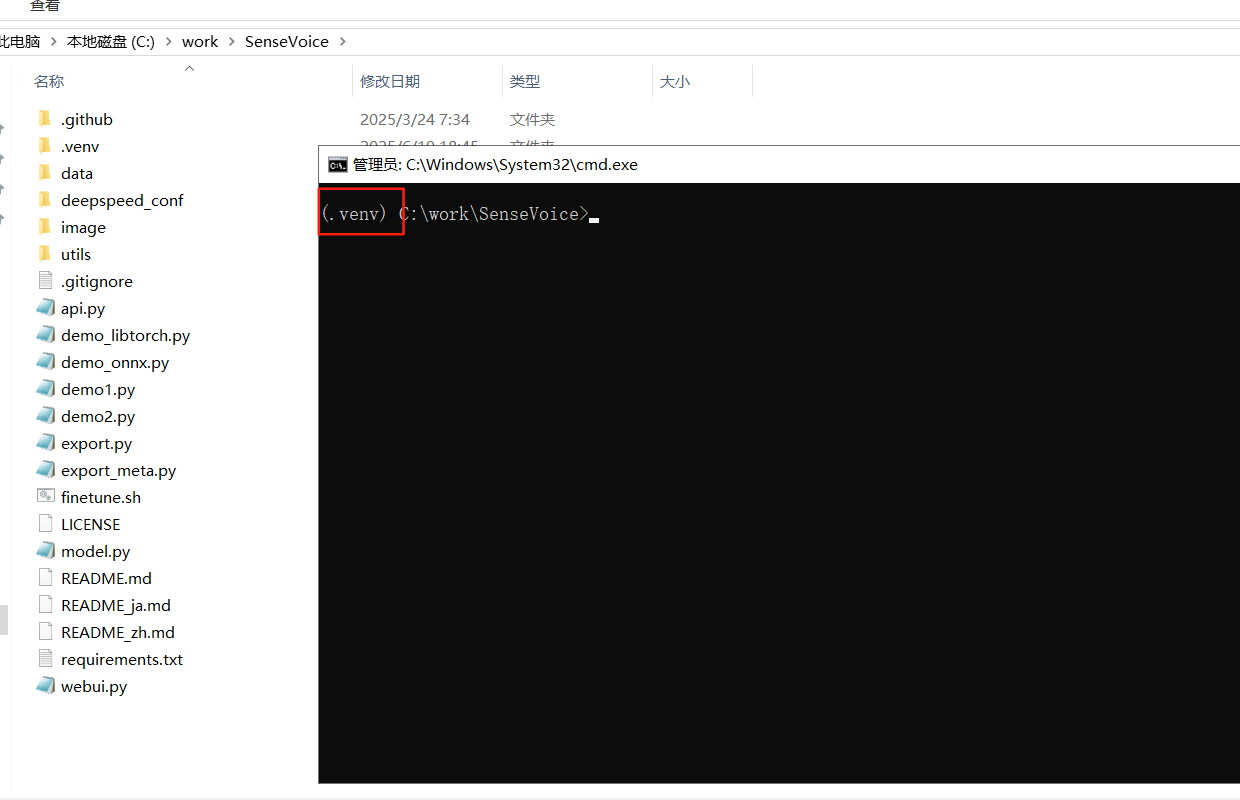
- 激活虚拟环境(命令行前面出现.venv就算成功了):
.venv\Scripts\activate
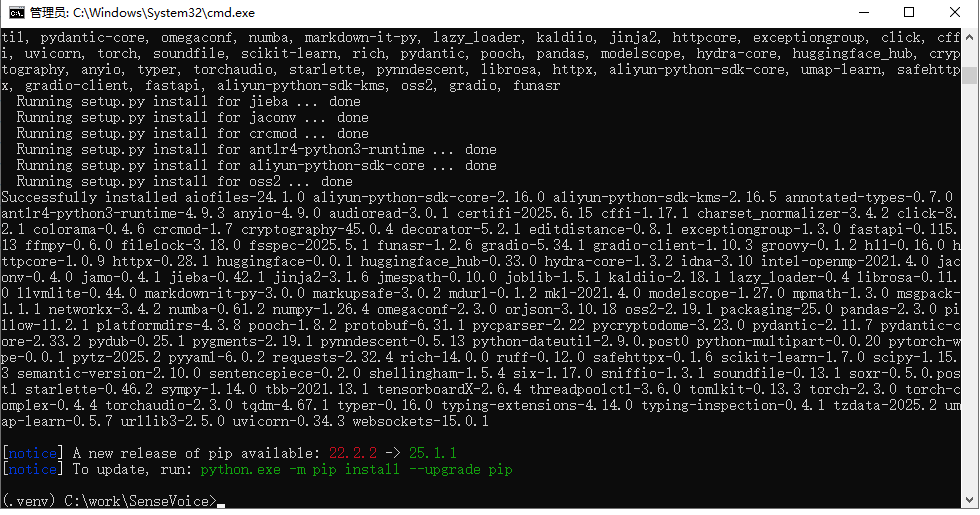
安装依赖
pip install -r requirements.txt
下载模型
modelscope download --model iic/SenseVoiceSmall --local_dir model/iic/SenseVoiceSmall
modelscope download --model iic/speech_fsmn_vad_zh-cn-16k-common-pytorch --local_dir model/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch
下载成功后model/iic中会出现这两个文件夹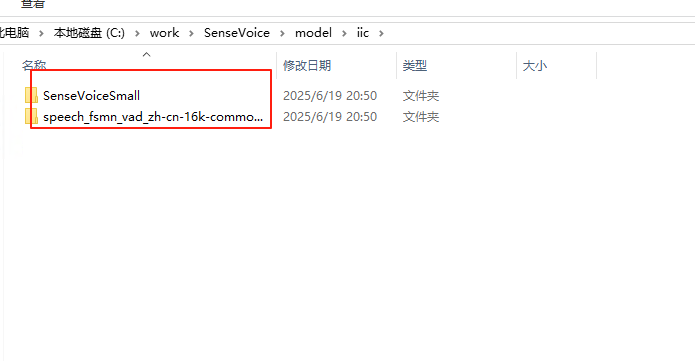
修改启用webui.py
默认启动只能本地访问,因为我是服务器部署想要公网访问并且想要修改他的默认端口,需要修改下webui.py文件
将最后的demo.launch()改为demo.launch(server_name=“0.0.0.0”, server_port=8888),后面该为自己想要的端口号就可以
然后命令行运行(首次运行会下载一些东西):
python webui.py
出现这个代表运行成功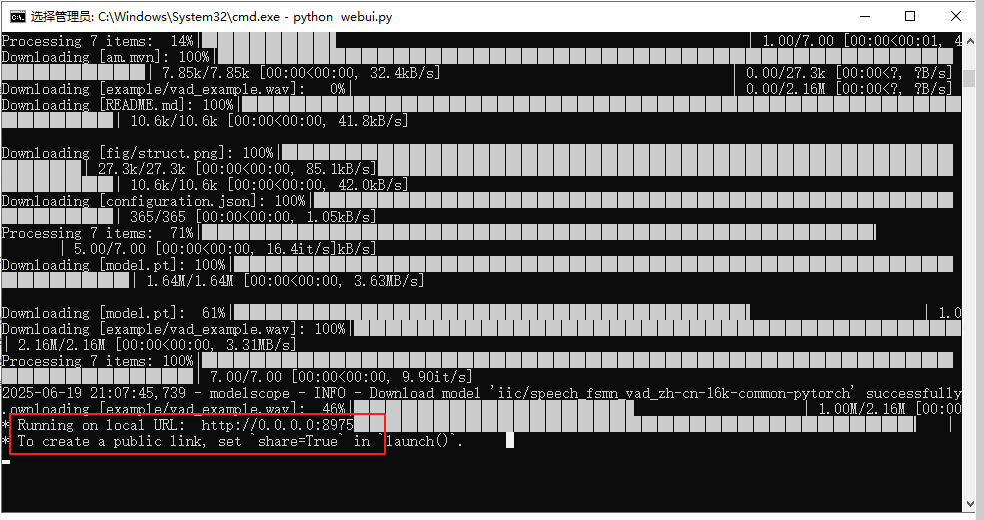
然后就可以访问网页了。
启用api.py
上面是启用的网页版,如果想要接口请求要启用api.py,9999改为自己想要的端口就可以
uvicorn api:app --host 0.0.0.0 --port 9999 --reload
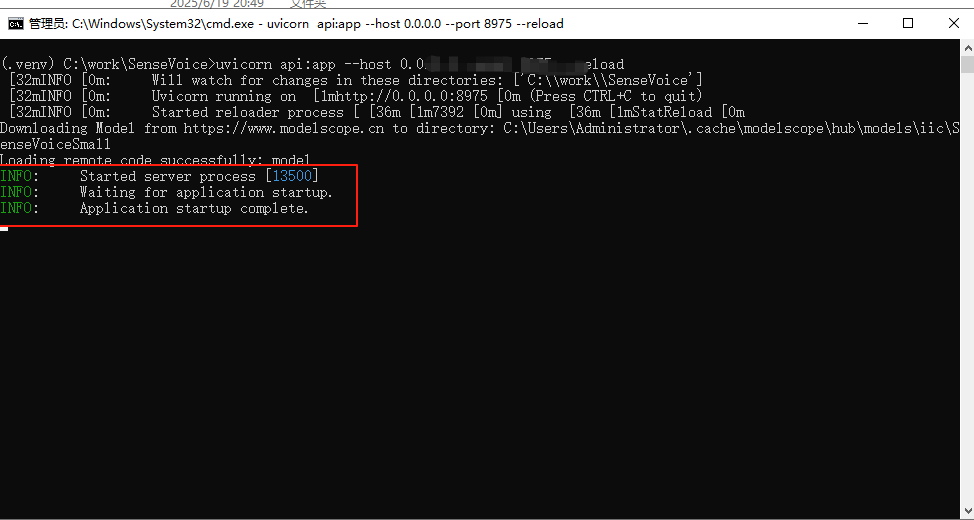
然后就可以通过/api/v1/asr接口访问了。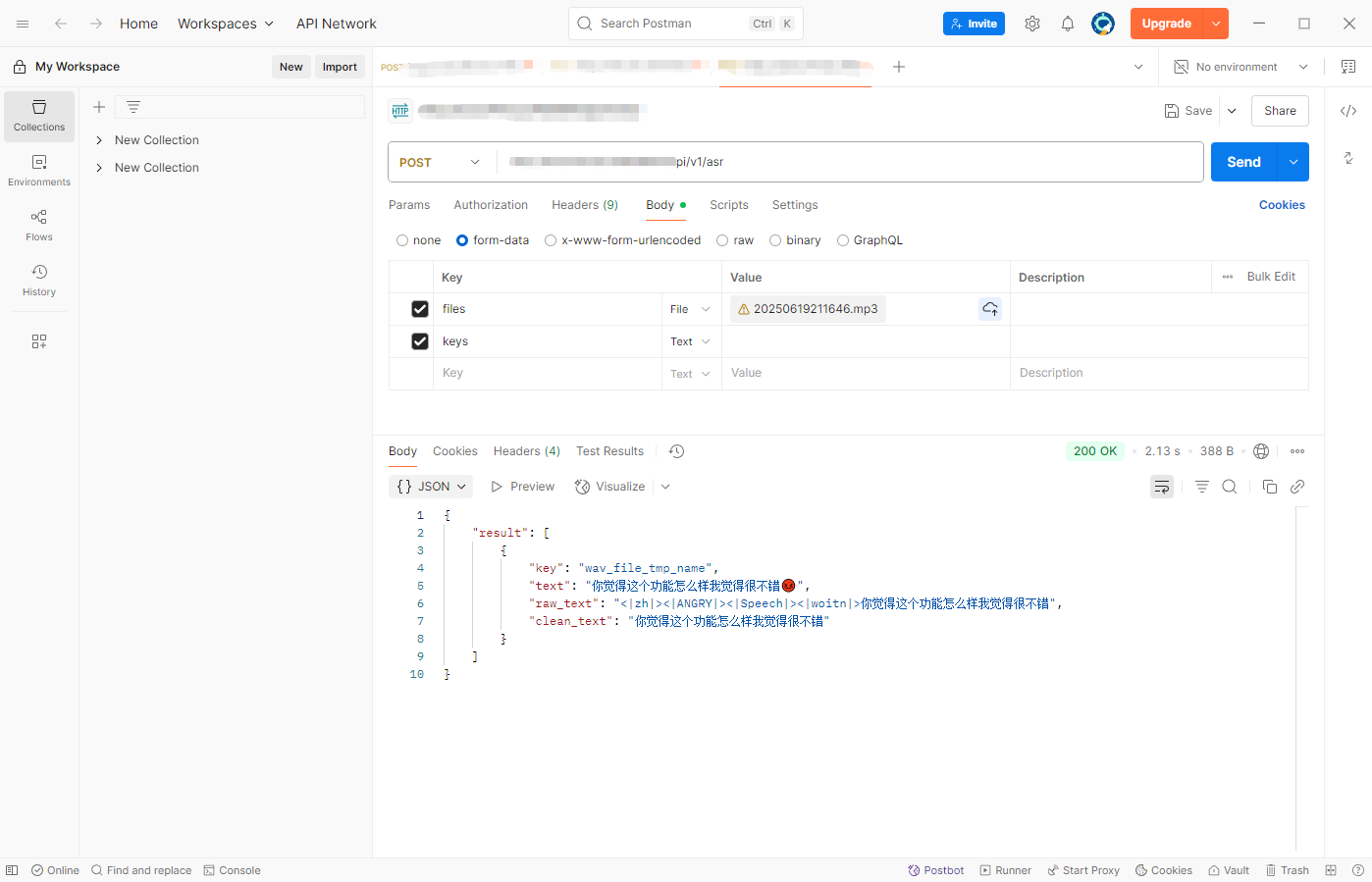

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)