当算力遇上情感:用RTX 4090复现B站IndexTTS2声音魔法
RTX 4090 不再只是游戏卡,它成了跑前沿 TTS 模型的硬核搭档。IndexTTS2 能零样本模仿音色,还能把情感、语速玩出花,4090 的 24G 显存和 Tensor Core 保证训练推理都稳得很。动手配置环境、准备数据,到最后训练和推理,整套流程顺滑高效。视频配音、AI 助手、游戏 NPC 都能立刻用上带感情的声音,技术和创意在桌面级算力下真正结合起来。
引言:AI创世纪的桌面革命
我们正处在一个激动人心的时代。曾经束之高阁、仅存于顶尖实验室和庞大服务器集群中的人工智能技术,正以前所未有的速度“飞入寻常百姓家”。这场AI民主化的浪潮中,NVIDIA RTX 4090不仅仅是一块游戏显卡,它更像一把钥匙,为广大的开发者、创作者和技术爱好者打开了通往专业级AI应用的大门。技术的浪潮瞬息万变,就在我们惊叹于基础声音合成时,Bilibili Index团队开源了其突破性的 IndexTTS2 模型,将情感表现力和时长控制这两个长期以来的行业难题,带入了Zero-Shot语音合成领域。
一、 解锁潜能的关键:为什么RTX 4090是IndexTTS2的理想伴侣?
高质量的TTS模型,特别是结构复杂的自回归 (Auto-Regressive) 模型如IndexTTS2,对硬件的要求极为苛刻。选择RTX 4090并非单纯追求极致性能,而是其多项关键特性共同构成了运行此类前沿模型的坚实基础。
RTX 4090 核心优势一览表
| 核心特性 | 价值摘要 | 关键影响 |
|---|---|---|
| 24GB GDDR6X海量显存 | 硬性门槛 | 允许更大的Batch Size,避免OOM,加速收敛。 |
| 第四代Tensor Cores | 效率核心 | 硬件加速混合精度训练,数倍提升训练速度。 |
| 16384个CUDA核心 | 通用算力 | 保障数据预处理等非核心计算任务不拖后腿。 |
| DLSS 3 & 光流加速器 | 未来潜力 | 为实时语音驱动数字人等多模态应用铺路。 |
监控硬件性能:nvidia-smi
在整个训练和推理过程中,持续监控RTX 4090的状态至关重要。
# 持续监控GPU状态,每2秒刷新一次
watch -n 2 nvidia-smi
通过 nvidia-smi 的输出,我们可以实时看到:
Fan: 风扇转速,判断散热是否正常。Temp: GPU核心温度,长时间高负载下应保持在85°C以下。Pwr:Usage/Cap: 功耗,4090在训练时功耗会非常高。Memory-Usage: 最重要的指标。可以直观看到24GB显存的占用情况。GPU-Util: GPU利用率,应尽可能接近100%,表示算力被充分利用。
二、 项目解析:Bilibili IndexTTS2的革命性突破
根据其GitHub仓库 (https://github.com/index-tts/index-tts) 和官方介绍,IndexTTS2是“一个在情感表现力和时长控制上取得突破的自回归、零样本TTS模型”。
核心亮点解读:
零样本:无需为每个新声音都重新训练。只需一小段参考音频,模型就能立即模仿其音色。
情感表现力:最大的进步。不仅合成音色,更能捕捉并复现参考音频中的情感、韵律和停顿。
时长控制:允许用户在一定程度上控制合成语音的语速,对视频配音等场景非常实用。
情感与音色解耦:可以独立控制音色和情感,使用A的音色,却表现出B的情感。
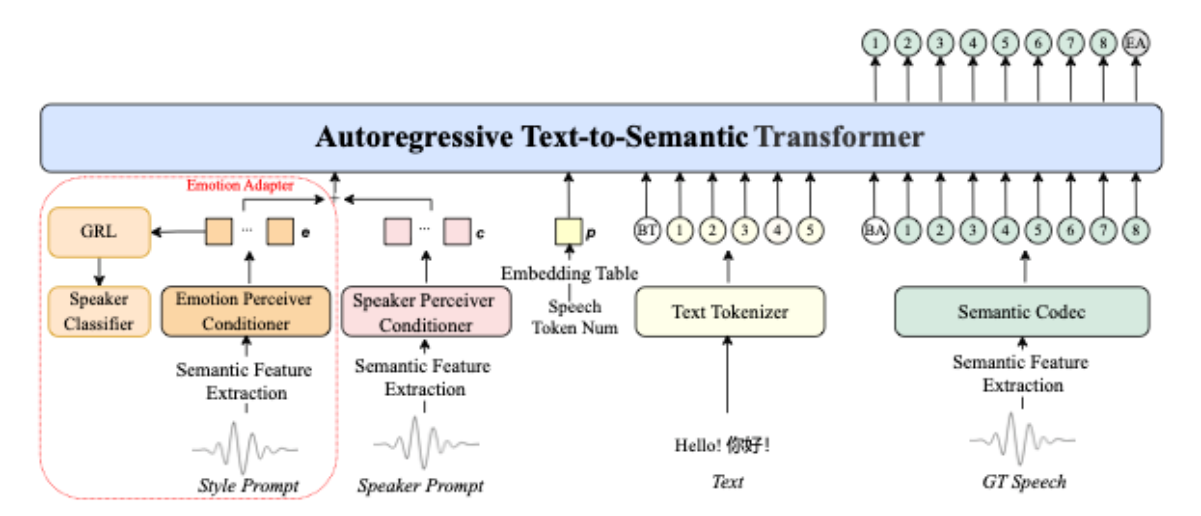
IndexTTS2 核心架构组件深度解析
1.Speaker Prompt / Speaker Perceiver
这个组件的任务是识别“说话人是谁”
它会分析你提供的一段音色参考音频,然后从中提取出这个人的声音特质。它背后使用的技术叫 Perceiver,这是一种很厉害的注意力机制变体,特别擅长处理像音频这样很长的信息流。它的最终目标是把一段可变长度的音频信号压缩成一个固定维度的“声音身份证”,也就是说话人嵌入向量 (Speaker Embedding)。这个向量包含了音色最核心的信息,是整个模型实现音色模仿的基础。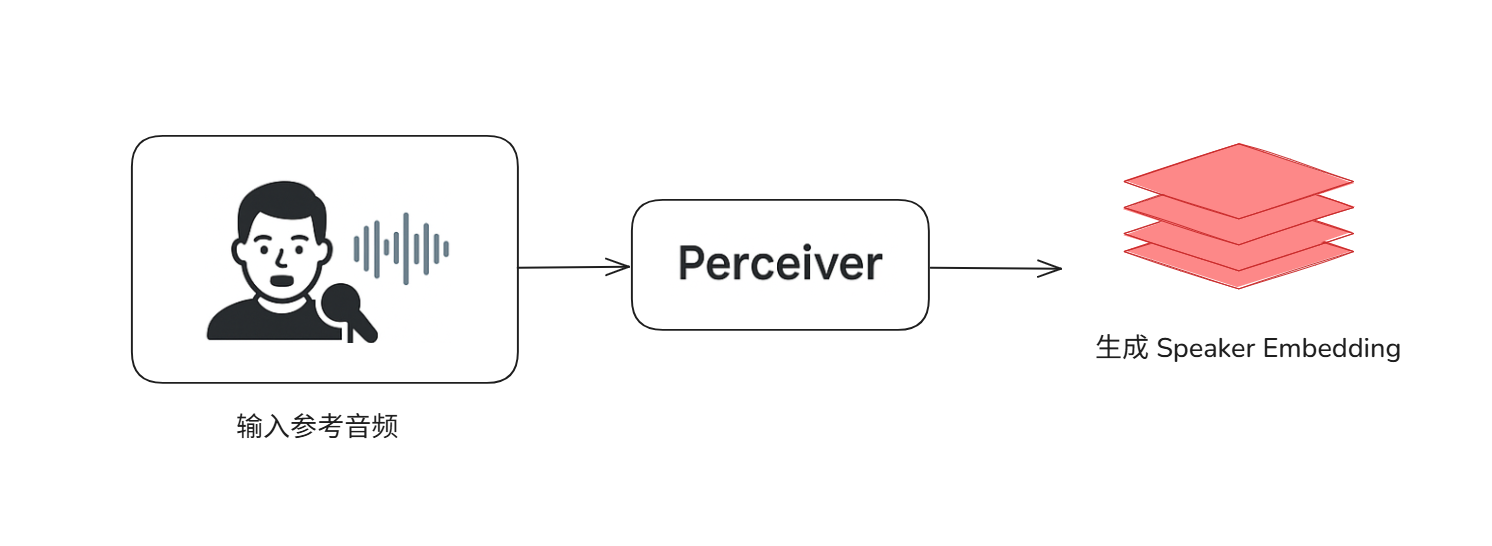
2.Style Prompt / Emotion Perceiver
这个组件的任务是识别“说话人用的是什么情绪/风格”
它的工作方式和上面那个很像,但关注点不同。它会分析你提供的风格/情感参考音频,但它不会去关心说话人是谁,而是专注于专注于捕捉声音里的韵律、语速、音高变化这些超语言学特征。最后,它会生成一个代表情绪的“风格说明书”,也就是情感嵌入向量 (Emotion Embedding)。这是让合成语音实现情感表达的关键。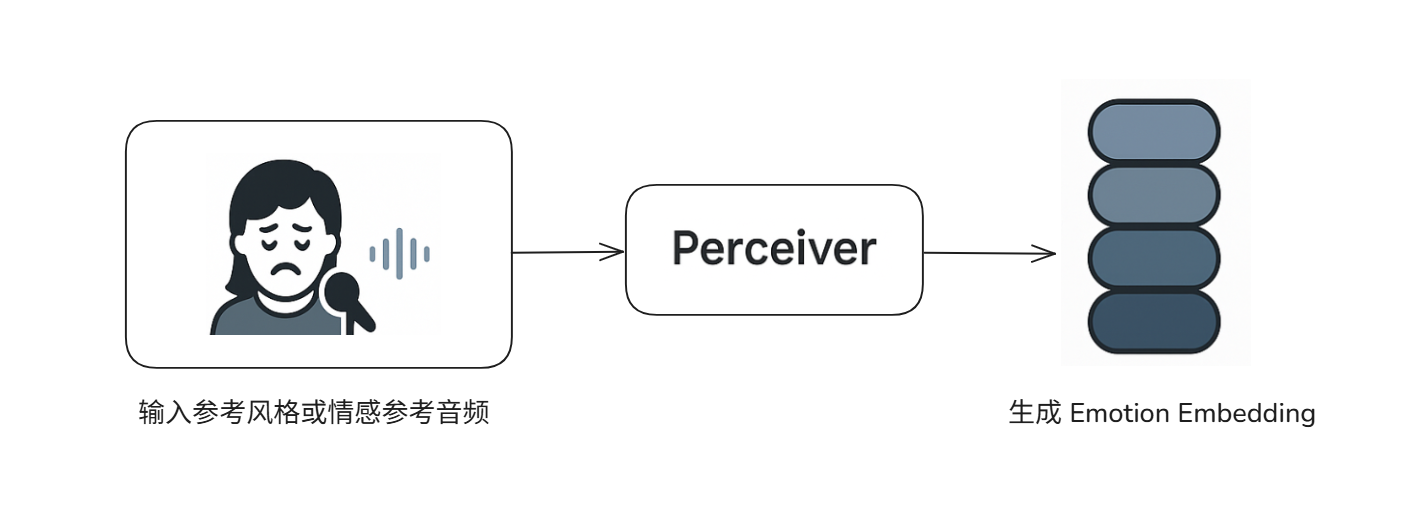
3. GRL
这个组件是一个非常聪明的“训练小技巧”,它的全称是梯度反转层
在训练模型时,我们希望 Emotion Perceiver 只学习情感,不要学到音色。GRL 就在这里发挥作用。它会反转一部分梯度信号,这是一种叫做领域对抗训练的技术。你可以把它想象成一个“捣蛋鬼”:当 Emotion Perceiver 试图根据音色去区分说话人时,GRL 就会给它一个错误的、相反的信号来“惩罚”它。这样一来,就迫使 Emotion Perceiver 不得不放弃学习音色特征,从而只学习那些纯粹与情感相关、与音色无关的特征,最终实现了情感与音色的有效解耦。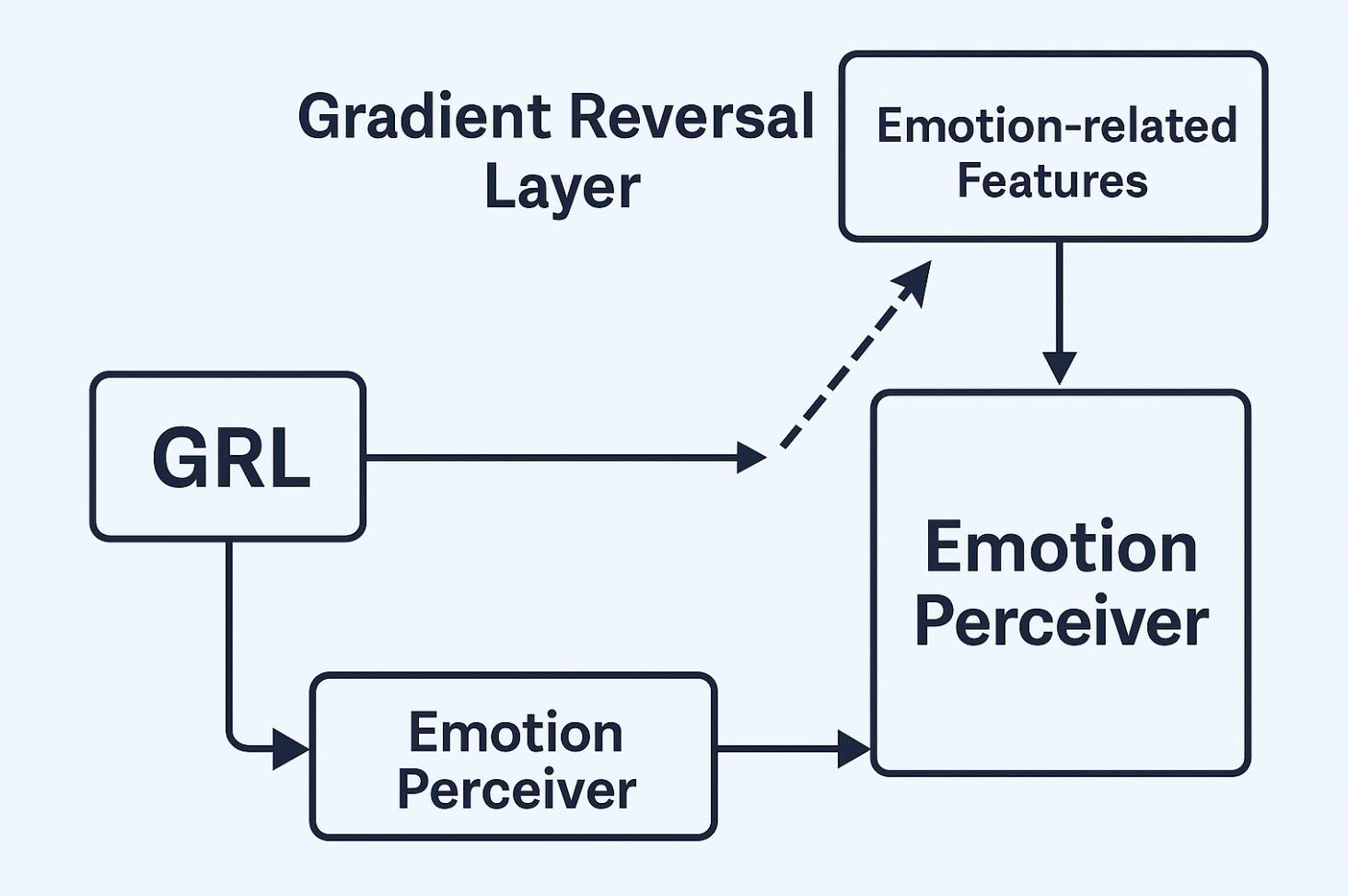
4. Emotion Adapter
这个组件像一个“转接头”或“调味包”,它的作用是把情感特征优雅地融入主模型
它是一种轻量级的神经网络模块,被巧妙地插入到核心Transformer模型的层与层之间。这样做的好处是,它允许情感信息以一种温和且非侵入性的方式“注入”到语义生成的过程中, subtly 影响最终语音的风格,而不会破坏模型原有的文本理解能力。
5.Autoregressive Text-to-Semantic Transformer
这是整个系统的大脑和引擎,是自回归的Transformer
它接收所有的输入信息:文本内容、前面提取的音色特征和情感特征。然后,利用强大的自注意力机制来捕捉文本中的长距离依赖关系(理解上下文)。“自回归”的意思是它会逐个地生成语义Token(一种代表声音含义的中间代码),并且当前Token的生成依赖于之前所有已生成的Token。这保证了生成的语音在语义上是连贯和自然的,但缺点是逐字生成,所以也是其计算量巨大的原因。
6. Semantic Codec
这是最后一步,负责发声的组件
它接收 Transformer 生成的语义Token,并将这些抽象的代码解码成最终的、我们可以听到的音频波形。这个组件通常是一个高效的声码器 (Vocoder),它是一个独立训练的神经网络,专门负责将高级的声学特征高效地转换成高质量的原始音频。
| 组件 | 核心功能 | 技术关键词 |
|---|---|---|
| Speaker Perceiver | 从参考音频中提取我是谁 (音色特征) | 注意力机制, 说话人嵌入向量 |
| Emotion Perceiver | 从参考音频中提取我什么心情 (情感风格) | 超语言学特征, 情感嵌入向量 |
| GRL | 训练时的“纠错员”,确保情感和音色不混淆。 | 梯度反转层, 领域对抗训练, 解耦 |
| Emotion Adapter | 像“调味包”一样,将情感特征注入到主模型中。 | 轻量级, 插入模块, 非侵入性 |
| Transformer (核心) | “大脑”,结合所有信息,逐字生成声音的语义蓝图。 | 自回归, 自注意力机制, 语义Token |
| Semantic Codec | “声带”,将语义蓝图转换成真实可听的音频。 | 声码器 (Vocoder), 原始音频波形 |
三、 实战工作流:在4090上复现IndexTTS2的声音魔法
以下是我严格按照官方文档,借助RTX 4090完成个性化语音合成的完整流程。
步骤一:环境配置
官方强烈推荐使用 uv 包管理器,以保证依赖环境的可靠性。
- 安装 Git-LFS 并下载代码:
git-lfs用于处理GitHub仓库中的大文件 (如模型权重)。
# (确保已安装 git 和 git-lfs)
git lfs install
git clone https://github.com/index-tts/index-tts.git
cd index-tts
git lfs pull
- 安装
uv包管理器:uv是一个极快的Python包安装和虚拟环境管理器。
pip install -U uv
- 使用
uv安装依赖:uv会自动创建.venv虚拟环境并安装所有依赖,确保环境的纯净和可复现。
# 使用国内镜像加速
uv sync --all-extras --default-index "https://mirrors.aliyun.com/pypi/simple"
--all-extras: 安装全部可选功能,包括 WebUI 和 DeepSpeed 加速。
- 下载预训练模型:
# 安装 huggingface-cli
uv tool install "huggingface_hub[cli]"
# 设置镜像端点 (可选,用于加速)
export HF_ENDPOINT="https://hf-mirror.com"
# 下载 IndexTTS-2 模型到 checkpoints 目录
hf download IndexTeam/IndexTTS-2 --local-dir=checkpoints
- PyTorch GPU 加速检测:
运行官方提供的脚本,确保 PyTorch 能正确识别并使用 RTX 4090。
uv run tools/gpu_check.py
预期输出应明确指出找到了CUDA设备且PyTorch版本支持GPU。
步骤二:数据准备——高质量音频的艺术
这是决定合成效果上限的关键一步,也是最考验耐心的环节。
- 录制参考音频:我使用高质量麦克风录制了约10分钟的个人朗读音频,刻意包含了高兴、平静、疑问等多种情感。
- 音频处理:对录音进行降噪,并切分成5-15秒的短音频片段。所有音频必须转换为单声道、22050Hz采样率的WAV格式。
- 文本标注:为每一个音频片段精确标注对应的文本,并保存为项目要求的格式 (通常是
list.txt)。
./dataset/my_voice/001.wav|这是第一个音频片段的文本,要带有感情。
./dataset/my_voice/002.wav|这是第二个片段。
...
步骤三:模型训练——释放4090的全部力量
这是整个流程中对硬件性能的终极考验。
- 预处理:运行项目提供的脚本,将音频和文本转换为模型训练所需的特征。
uv run python preprocess.py
- 开始训练:执行训练命令。
uv run python train.py -c configs/config.json -m indextts2
在训练期间,RTX 4090的强大之处显露无遗:
- 显存占用:通过
nvidia-smi监控,显存占用峰值接近22GB。这再次证明了24GB显存对于运行此类SOTA (State-of-the-art) 模型是多么重要。 - 训练效率:第四代Tensor Cores的加持,使得训练过程中的迭代速度非常快。在4090上,我只用了几个小时就得到了一个效果相当不错的模型检查点,这在旧款显卡上是难以想象的。
- 稳定性:长时间的高强度计算下,4090的散热系统表现出色,核心温度始终在可控范围内,确保了训练的顺利完成。
步骤四:IndexTTS2 快速体验与推理
训练完成后,或直接使用下载的预训练模型,我们可以通过多种方式进行推理。
1. Web 演示 (WebUI):
官方提供了一个非常直观的 Web 界面。
uv run webui.py
浏览器访问 http://127.0.0.1:7860 即可打开演示页面。在这个界面上,可以方便地上传参考音频、输入文本、调整各种参数并实时生成语音。
2. Python 脚本调用与参数调优:
IndexTTS2 提供了极其丰富的推理参数,RTX 4090 的强大算力让我们可以从容地尝试各种组合。
IndexTTS2 核心推理参数调优表
| 参数 (Parameter) | 类型 (Type) | 作用与调优建议 |
|---|---|---|
spk_audio_prompt |
String (path) | 必需。指定音色参考。 |
emo_audio_prompt |
String (path) | 指定情感参考,实现情感与音色分离。 |
emo_alpha |
Float | 情感参考的权重 (0.0 - 1.0)。 |
use_emo_text |
Boolean | True则根据文本自动推断情感。 |
emo_text |
String | 提供独立的情感描述文本。 |
emo_vector |
List[Float] | 精确控制8维情感向量。 |
use_fp16 |
Boolean | 半精度推理,降低显存占用。 |
use_deepspeed |
Boolean | DeepSpeed加速,提升推理速度。 |
代码示例:指定情感参考音频```python
from indextts.infer_v2 import IndexTTS2
use_fp16=True 在 4090 上是很好的选择
tts = IndexTTS2(cfg_path=“checkpoints/config.yaml”, model_dir=“checkpoints”, use_fp16=True)
text = “酒楼丧尽天良,开始借机竞拍房间,哎,一群蠢货。”
使用我自己的音色,但模仿一个悲伤语调的音频
tts.infer(spk_audio_prompt=‘examples/my_voice.wav’,
text=text,
output_path=“gen_sad.wav”,
emo_audio_prompt=“examples/emo_sad.wav”,
emo_alpha=0.8) # 稍微降低情感强度
四、工作流重塑与未来展望
RTX 4090与IndexTTS2的结合,彻底重塑了我的创意工作流:
内容创作:可以为视频、播客生成带有情感的旁白,大大提升了内容的感染力。
游戏开发:独立游戏开发者可以为NPC生成大量高质量、带情感的对话,而无需昂贵的配音预算。
个性化体验:为个人AI助手、有声读物,甚至虚拟数字人,注入独特且富有情感的声音灵魂。
展望未来,随着4090级别算力的进一步普及,以及IndexTTS这类优秀开源模型的不断涌现,我们有理由相信,实时情感语音转换、多语种声音合成</-s>等更前沿的技术,将很快从实验室走进我们每个人的创作工具箱。
五、结论
这次通过RTX 4090复现Bilibili IndexTTS2的实践,是一次技术与创意的完美融合。4090的海量显存和澎湃算力,是驾驭此类前沿AI模型的坚实后盾。它不仅是性能的一次飞跃,更是赋予了开发者和创作者将最疯狂的想法变为现实的能力。对于每一个投身于AI浪潮的技术爱好者来说,这无疑是最激动人心的时代。

日期:2025年9月17日
专栏:开源模型

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 195
195 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)