第一章 相位编码器(Phase Vocoder)
开篇先留一个问题,现在TTS大模型、音乐生成大模型的“电音”/“机器音”/“合成音”、“金属感”、以及清晰度低在信号层面该如何解释?
第一章 相位编码器(Phase Vocoder)
开篇先留一个问题,现在TTS大模型、音乐生成大模型的“电音”/“机器音”/“合成音”、“金属感”、以及清晰度低在信号层面该如何解释?
在音乐效果器、音乐合成、视频倍速播放、实时通话场景中音视频同步等常常需要用到变速、变调的需求,而Phase Vocoder就是其中一种技术,相位编码器可以实现时频伸缩,即改变声音的速度而不改变音高,或改变音高而不影响时长,但当伸缩的尺度较大时,会使得伸缩之后的音频存在明显的“相位感”和“混响感”,可以通过“锁相”的方式改善伸缩之后音频的自然度,所以很多后续技术集中在如何提升变换之后声音的质量上。
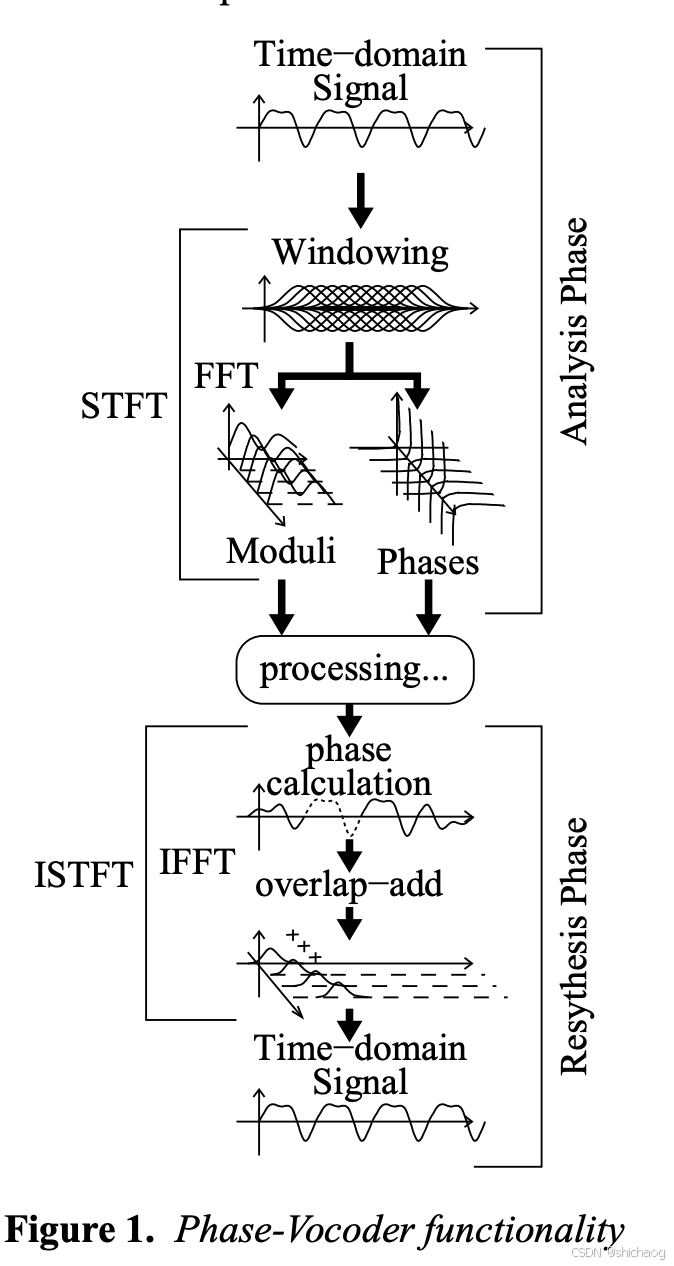
该方法的核心思想是通过傅里叶变换将信号从时域转换到频域,再对频域中的各个组分进行伸缩、位移等操作,最后通过逆傅里叶变换将其转换回时域,即分析-修改-合成处理过程,通过使用不同的时间步长进行STFT分析和合成,但这可能引起相位失真,因此相位声码器的主要挑战是STFT相位的校正。目前如Aubio、SuperCollider等音频处理库提供相位声码器工具。
为了解决相位失真,1999年J. Laroche, M. Dolson提出了锁相技术[1]。在这之后有很多学者提出了更优的峰值检测和相位连续性处理方法,比如2022年Zdenek Pruša等人提出的相位梯度估计及其积分的相位校正方法[2]。
变调的基本思想
要在不改变音频长度的情况下调整音高,可以先使用音高变换技术改变音频的频率,然后通过时间伸缩技术调整音频时长以保持原长。这样处理后,音频的音高改变了,但播放时间保持不变,既达到了变调的目的,也保留了原有的节奏感。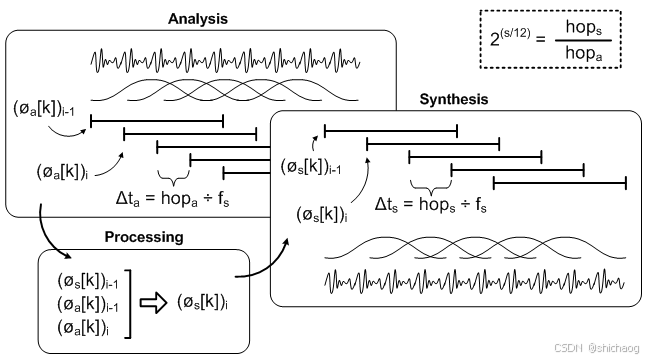
上面分析和合成信号时对音频帧进行加窗和重叠是非常重要的,这可以有效减少了频谱泄漏,并使沿时间轴的分析更加平滑。另外这使得对音频进行重新采样可行,这样可以在不改变其持续时间和时序而改变音频的音高而。但这会导致在衔接处若干频率成分相位互相之间以及连续的两帧之间存在明显的“拼接”痕迹,这会影响重构信号的质量,使得音频的稳定部分听起来有“相位感”,而瞬态部分听起来“涂抹”。
此外,上述的音高修改技术将改变信号的共振峰/频谱结构。共振峰是围绕特定频率的声学能量集中区域,这些区域自然会随着转换过程而移动,这会使得高音区的输出声音听起来非常人工化。因此锁相技术也要减少共振峰损失。
为了确保频率间相位的一致性,Laroche and Dolson提出scaled phase locking方法,即可以通过分析、跟踪频率通道中峰值的局部最大值来更新相位[3],此外此方法还使用基于倒谱的真实包络对每个信号帧的频谱包络进行预变形,从而保留了共振峰结构。但是,它通常仍然无法适应打击乐声音和瞬态事件。
变速的基本思想
为了伸缩时间,我们可以在执行短时傅立叶变换(STFT)和逆短时傅立叶变换时使用不同的跳跃大小(hop sizes)。虽然步长被伸缩,但窗口大小保持不变。但是,在重构时我们不能仅仅将帧累加起来。为了减少不连续性,我们需要进行一些频谱处理。这种技术称为相位声码器,它包括三个阶段:分析、处理和合成。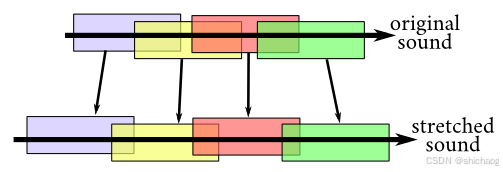
相位校正
在频域中,声波被解释为频率的幅度和相位。我们通常不会修改频率的幅度,因为幅度代表了频率成分的能量。因此,我们只对相位进行校正。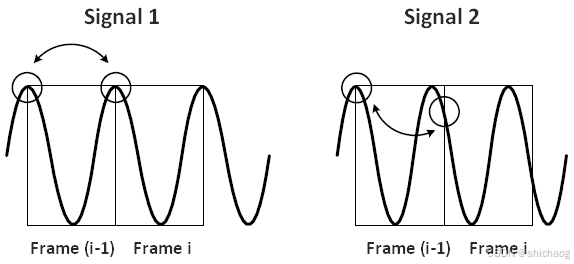
锁相
在相位校正过程中,可能会存在一些彼此接近的频率,因此它们之间的频率点将受到这些频率的影响。在这种情况下,对真实频率的估计可能不准确。相位锁定是一种用来减少由此产生的失真的技术。首先,通过检测局部最大值来定位突出的峰值(最接近真实频率的峰值),并定义影响区域。对于区域内的所有频率点区间,其相位变化与峰值的相位变化相同。
经典的PV代码
# define the window size, synthesis hop size, and analysis hop size
window_size = 2048
synthesis_hopsize = window_size/4
analysis_hopsize = int(synthesis_hopsize/pitch_ratio)
# signal blocks for procesynthesis_hopsizeing and output
delta_phase = np.zeros(window_size/2+1) # delta phase
syn_phase = np.zeros(window_size/2+1, dtype=complex) # synthesis phase angle
k = np.linspace(0, window_size/2, window_size/2+1) # ramp
last_phase = np.zeros(window_size/2+1) # last frame phase
accum_phase = np.zeros(window_size/2+1) # accumulated phase
current_frame = np.zeros(window_size/2+1)
# 信号的固有属性是它的频率和相位在自然状态下是连续变化的,因而假设相位的变化是线性的,完美地模拟复杂的相位变化是非常困难的。
# 通过假设一个基于无处理情况下的预期相位变化的线性相位模型 ,可以简化算法的实现。这种简化允许快速有效地对相位进行调整,
# 而无需进行过于复杂的计算,特别是在实时处理中十分重要。
expected_phase = k*2*np.pi*analysis_hopsize/window_size # expected phase
# 计算从音频信号的开始到结束,可以进行多少次完整的分析-处理-合成周期。
#analysis_hopsize*4 表示在信号中处理一个更大的块(四倍于分析步长),这是为了在每个处理块之间有重叠,确保连续性和减少伪影。
for i in range(int((signal_length-window_size)/(analysis_hopsize*4))):
# initialize the pointers
read_pt = 0
write_pt = 0
# 循环内部的处理步骤包括:
# 使用窗函数处理当前音频窗口数据。
# 进行快速傅里叶变换(FFT)并计算当前帧的频率幅度和相位。
# 计算相位差并进行解包。
# 累计相位差并根据分析和合成的步长比进行调整。
while read_pt <= 4*analysis_hopsize:
# analysis
# take the spectra of the current window
current_frame = np.fft.rfft(win*indata[read_pt:read_pt+window_size])
# take the phase difference of two consecutive window
current_phase = np.angle(current_frame)
current_magn = abs(current_frame)
delta_phase = current_phase - last_phase
last_phase = np.copy(current_phase)
# subtract expected phase to get delta phase
delta_phase -= expected_phase
delta_phase = np.unwrap(delta_phase)
# accumulate delta phase,见公式1
accum_phase[pk_indices] = accum_phase[pk_indices] + (delta_phase[pk_indices] + expected_phase[pk_indices])*synthesis_hopsize/analysis_hopsize
# define the region of influence
rotation_angle = accum_phase[pk_indices] - current_phase[pk_indices]
start_point = 0
for k2 in range(len(pk_indices)-1):
peak = pk_indices[k2]
next_peak = pk_indices[k2+1]
end_point = int((peak + next_peak)/2)+1
ri_indices = range(start_point,peak)+ range(peak+1,end_point)
accum_phase[ri_indices] = rotation_angle[k2] + current_phase[ri_indices]
start_point = end_point
# last peak
ri_indices = range(start_point,next_peak)
accum_phase[ri_indices] = rotation_angle[len(pk_indices)-1] + current_phase[ri_indices]
# peak detect
pk_indices = locate_peaks(current_magn)
if len(pk_indices) == 0:
pk_indices = [1]
# synthesis
syn_phase.real, syn_phase.imag = np.cos(accum_phase), np.sin(accum_phase)
dout[write_pt:write_pt+window_size] += win*np.fft.irfft(current_magn*syn_phase)
read_pt += analysis_hopsize
write_pt += synthesis_hopsize
开篇问题的解释
(个人观点),时间轴的连续性、频率分布的合理性以及不同频率成份相位的一致性三方面决定了合成信号的质量,人声和乐器都不是单一频率的振动,而是存在主频率(若干其他频率,能量占比不同),振动又存在谐波特性,所以有共振峰、谐波概念,每个频率成份又存在相位,而随着时间的推移,能量占比、相位又是变化的,
“假声”的产生主要是1. 不同频率成份、相位随时间变化的连续性;2.各频率成份的占比和相位连续性(音色、“电音”也可以看成音色的一种)。
参考文献
[1] J. Laroche, M. Dolson, “Improved Phase Vocoder Time-Scale Modification of Audio”, IEEE Transactions on Speech and Audio Processing, Vol. 7, No. 3, May 1999.
[2] Zdeneˇk Pru ̊ša, Nicki Holighaus, Vienna, Phase Vocoder Done Right, arXiv:2202.07382v1 [cs.SD]
[3] J. Laroche and Mark Dolson. Phase-vocoder: about this phasiness business. In Proc. WASPAA, page 4 pp., 11 1997. ISBN 0-7803-3908-8. doi: 10.1109/ASPAA.1997.625603.

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)